Command Palette
Search for a command to run...
LightOnOCR-2-1B:基于 RLVR 训练实现高精度端到端 OCR;Google Streetview 国家街景图像:基于世界级地理映射技术的全景图像开源库

当前,OCR 技术依赖于复杂的串联式流水线:先检测文本区域,再进行识别,最后进行后处理。这种模式在面对版面复杂、格式多变的文档时,流程繁琐脆弱,任一环节出错都会导致整体结果不佳,且难以端到端优化,维护与适配成本高昂。
在此背景下,LightOn 公司开源发布 LightOnOCR-2-1B 模型。这个仅 10 亿参数的端到端视觉-语言模型,在权威基准 OlmOCR-Bench 上实现了新的 SOTA,性能超越此前最佳的 90 亿参数模型,同时体积缩小 9 倍、推理速度提升数倍。 LightOnOCR-2-1B 用一个统一模型直接从像素生成结构化的有序文本和图像边界框,通过集成预训练组件、高质量的蒸馏数据以及 RLVR 等策略,在简化流程的同时,显著提升了处理复杂文档的效率。
目前,HyperAI 超神经官网已上线了「LightOnOCR-2-1B 轻量级高性能端到端 OCR 模型」,快来试试吧~
在线使用:https://go.hyper.ai/8zlVw
2 月 2 日-2 月 6 日,hyper.ai 官网更新速览:
* 优质公共数据集:6 个
* 优质教程精选:9 个
* 本周论文推荐:5 篇
* 社区文章解读:4 篇
* 热门百科词条:5 条
* 2 月截稿顶会:4 个
访问官网:hyper.ai
公共数据集精选
1. RubricHub 多领域生成任务数据集
RubricHub 是由理想汽车联合浙江大学发布的一个大规模、多领域生成任务的数据集,该数据集提供基于评分标准的高质量监督,用于开放式生成任务。数据集通过自动化的粗到细评分标准生成框架构建,整合了原则引导合成、多模型聚合和难度演变等策略,以产生全面且高度区分的评价标准。
直接使用:https://go.hyper.ai/g3Htm
2. Nemotron-Personas-Brazil 巴西合成角色数据集
Nemotron-Personas-Brazil 是由 NVIDIA 联合 WideLabs 发布的巴西合成角色数据集,旨在展现巴西人口的多样性和丰富性,以更全面地反映多维度的潜在人口分布,包括区域多样性、种族背景、教育水平及职业分布。
直接使用:https://go.hyper.ai/7xKKH
3. CL-bench 上下文学习评估基准
CL-bench 是由腾讯混元团队联合复旦大学发布的一个大语言模型上下文学习(Context Learning)能力评估基准数据集,旨在测试模型是否能够在不依赖预训练知识的情况下,仅通过给定上下文学习新的规则、概念或领域知识,并将其应用于后续任务。
直接使用:https://go.hyper.ai/w2MG3
4. RoVid-X 机器人视频生成数据集
RoVid-X 是由北京大学联合 ByteDance Seed 发布的机器人视频生成数据集,旨在解决视频生成模型在生成机器人视频时面临的物理挑战。
直接使用:https://go.hyper.ai/4P9hI
5. Google Streetview 国家街景图像数据集
Google Streetview 是一个涵盖多个国家的街景图像数据集,图像文件名中包含创建日期和地图名称,每个国家的图像都单独放置在相应的文件夹中。
直接使用:https://go.hyper.ai/tZRlI

6. DeepPlanning 长期规划能力评估数据集
DeepPlanning 是由 Qwen 团队发布的一个智能体规划能力评估数据集,旨在评估智能体在复杂、长程规划任务中推理与决策能力。
直接使用:https://go.hyper.ai/yywsb
公共教程精选
1. 使用 vLLM-Omni 部署 Qwen-Image-Edit
Qwen-Image-Edit 是由阿里巴巴通义千问团队发布的多功能图像编辑模型。该模型具备语义与外观双重编辑能力,既能实现低层视觉外观编辑如元素的添加、移除或修改,也能完成高层视觉语义编辑例如 IP 创作、物体旋转、风格迁移等。模型支持中英文双语文本的精准编辑,可在保留原字体、大小及风格的前提下,直接修改图像中的文字内容。
在线运行:https://go.hyper.ai/DowYs
2. 使用 vLLM-Omni 部署 Qwen-Image-2512
Qwen-Image-2512 是 Qwen-Image 系列的基础文生图模型,相较于先前版本,Qwen-Image-2512 在多个关键维度进行了系统性优化,重点提升了生成图像的整体真实感与实用性。人像生成的自然度显著增强,面部结构、皮肤纹理及光影关系更趋近于真实摄影效果。在自然场景中,模型能生成更精细的地形纹理、植被细节和动物毛发等高频信息。同时,其文本生成与版式能力得到改善,能够更稳定地呈现可读文本与复杂排版。
在线运行:https://go.hyper.ai/Xk93p
3.Step3-VL-10B:多模态视觉理解与图文对话
STEP3-VL-10B 是由阶跃星辰团队开源的视觉语言大模型,专为多模态理解与复杂推理任务设计。该模型旨在有限的百亿参数规模(10B)内,重新定义效率、推理能力与视觉理解质量间的平衡。其视觉感知、复杂推理及人类指令对齐能力表现优异,在多项基准测试中持续超越同规模模型,并在部分任务上可与参数规模大 10-20 倍的模型相媲美。
在线运行:https://go.hyper.ai/ZvOV0
4.vLLM+Open WebUI 部署 GLM-4.7-Flash
GLM-4.7-Flash 是智谱 AI 推出的轻量级 MoE 推理模型,旨在实现高性能与高吞吐量的平衡,原生支持思维链、工具调用与智能体能力。它采用混合专家架构,利用稀疏激活机制显著降低单次推理的计算开销,同时保持大模型的表现力。
在线运行:https://go.hyper.ai/bIopo

5.LightOnOCR-2-1B 轻量级高性能端到端 OCR 模型
LightOnOCR-2-1B 是光年无限(LightOn AI)发布的最新一代端到端视觉语言模型(OCR)。作为 LightOnOCR 系列中的旗舰版本,它将文档理解与文本生成功能统一于一个紧凑的架构中,模型参数量为 10 亿,且能够在消费级显卡上运行(约需 6GB 显存)。该模型采用视觉语言 Transformer 架构,并引入了 RLVR 训练技术,实现了极高的识别准确率与推理速度。它专为需要处理复杂文档、手写体及 LaTeX 公式的应用场景而设计。
在线运行:https://go.hyper.ai/8zlVw
6.vLLM+Open WebUI 部署 LFM2.5-1.2B-Thinking
LFM2.5-1.2B-Thinking 是由 Liquid AI 发布的最新边缘优化混合架构模型。作为 LFM2.5 系列中专门针对逻辑推理优化的版本,它在紧凑的架构中统一了长序列处理与高效推理能力。模型参数量为 12 亿,可在消费级显卡乃至边缘设备上流畅运行。它采用创新的混合架构,实现了极致的记忆效率与吞吐量,专为需要在设备端进行实时推理且不牺牲智能水平的场景而设计。
在线运行:https://go.hyper.ai/PACIr
7.TurboDiffusion:图像与文本驱动视频生成系统
TurboDiffusion 是由清华大学团队开发的高效视频扩散生成系统。该项目基于万 2.1 架构进行高阶蒸馏,旨在解决大规模视频模型推理速度慢、计算资源消耗高的痛点,以极少的步数实现高质量视频生成。
在线运行:https://go.hyper.ai/YjCht
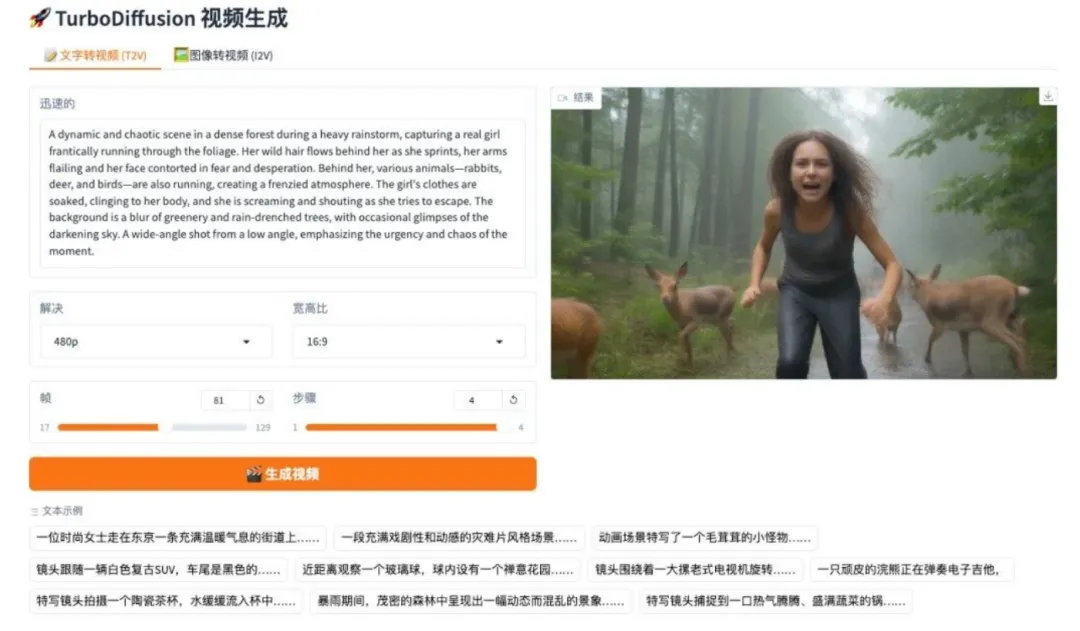
8.DeepSeek-OCR 2 视觉因果流
DeepSeek-OCR 2 是深度求索团队发布的第二代 OCR 模型。通过引入 DeepEncoder V2 架构,它实现了从固定扫描到语义推理的范式转变。模型采用因果流查询与双流注意力机制,对视觉令牌进行动态重排序,更准确地重构复杂文档的自然阅读逻辑。在 OmniDocBench v1.5 评估中,模型综合得分达 91.09%,相较前代显著提升,同时大幅降低了 OCR 结果的重复率,为未来构建全模态编码器提供了新路径。
在线运行:https://go.hyper.ai/ITInm
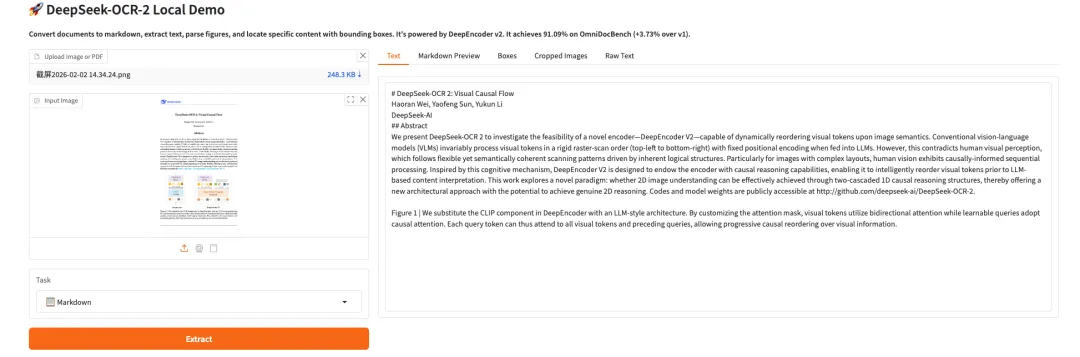
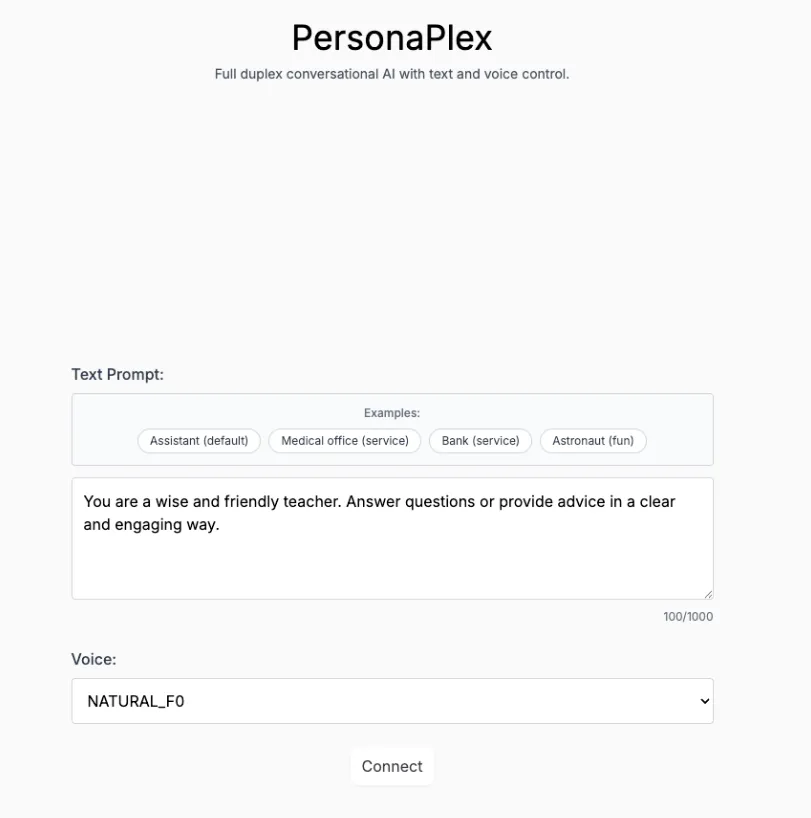
9.Personaplex-7B-v1:实时对话与角色定制语音接口
PersonaPlex-7B-v1 是英伟达发布的 70 亿参数多模态个性化对话模型。它专为实时语音/文本交互、长程人设一致性模拟及多模态感知任务而设计,旨在提供一个具有毫秒级响应速度的沉浸式角色扮演与多模态交互演示系统。
在线运行:https://go.hyper.ai/ndoj0
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD 教程】,入群探讨各类技术问题、分享应用效果~

本周论文推荐
1. Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning
本文提出 MATTRL,一种测试时强化学习框架,通过在推理过程中注入结构化文本经验来增强多智能体推理,利用多专家团队协作与逐轮信用分配实现共识,在无需重新训练的情况下,于医疗、数学和教育基准上均取得稳健的性能提升。
论文链接:https://go.hyper.ai/ENmkT
2. A^3-Bench: Benchmarking Memory-Driven Scientific Reasoning via Anchor and Attractor Activation
本文提出 A³-Bench,一个基于双尺度记忆驱动的科学推理基准,通过 SAPM 注释框架和 AAUI 指标评估锚点与吸引子的激活情况,揭示了记忆利用如何在标准连贯性或答案准确率之外提升推理一致性。
论文链接:https://go.hyper.ai/Ao5t9
3. PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
本文提出了 PaCoRe,一种并行协同推理框架,通过多轮并行推理轨迹间的消息传递实现测试时计算(TTC)的海量扩展,在 HMMT 2025 上以 94.5% 的准确率超越 GPT-5(93.2%),在固定上下文限制内高效融合数百万 token 的推理过程,同时开源模型与数据以推动可扩展推理系统的发展。
论文链接:https://go.hyper.ai/fQrnt
4. Motion Attribution for Video Generation
本文提出了 Motive,一种以运动为中心的基于梯度的数据归因框架,通过运动加权损失掩码将时序动态与静态外观分离,实现了对影响微调片段的可扩展识别,从而提升文本到视频生成中的运动平滑性和物理合理性,在 VBench 上取得了 74.1% 的人类偏好胜率。
论文链接:https://go.hyper.ai/2pU21
5. VIBE: Visual Instruction Based Editor
本文提出 VIBE,一种基于指令的紧凑型图像编辑流程,采用 20 亿参数的 Qwen3-VL 模型进行引导,16 亿参数的扩散模型 Sana1.5 进行生成,在计算成本极低的情况下实现高质量、严格保持源图像一致性的编辑——在 24GB GPU 内存下高效运行,于 H100 上生成 2K 图像仅需约 4 秒,性能达到或超越更庞大的基线模型。
论文链接:https://go.hyper.ai/8YMEO
社区文章解读
1. 3 天遍历 1 亿哈勃档案数据,欧洲航天局提出 AnomalyMatch,发现千余个异常天体
当前,多波段、大视场、高深度的大规模巡天正在将天文学推向一个前所未有的数据密集型时代,其核心科学潜力之一,即在于系统性地发现与鉴定其中那些稀有的、具有特殊天体物理价值的天体,然而,它们的发现长期高度依赖于研究人员的偶然性目视识别或公民科学项目的人工筛选。这类方法不仅主观性强、效率低下,也难以适应即将到来的海量数据规模。为弥补这一不足,欧洲航天局(ESA)下属欧洲空间天文中心(ESAC)的研究团队,提出并应用了一种名为 AnomalyMatch 的新方法。
查看完整报道:https://go.hyper.ai/Jm3aq
2. 数据集汇总丨 16 个具身智能数据集,覆盖抓握/问答/逻辑推理/轨迹推理等领域
如果说过去十年人工智能的主战场在「看懂世界」和「生成内容」,那么下一阶段的核心问题正在转向一个更具挑战性的命题:AI 如何真正进入物理世界,并在其中行动、学习与进化。在与此相关的研究与讨论声中,具身智能一词频繁出现。顾名思义,具身智能并非传统的机器人,而是强调 Agent 与环境交互在感知—决策—行动的闭环中形成智能。本文将系统整理并推荐目前所有与具身智能相关的高质量数据集,为进一步学习和研究提供参考。
查看完整报道:https://go.hyper.ai/lsCyF
3. 在线教程|DeepSeek-OCR 2 公式/表格解析同步改善,以低视觉 token 成本实现近 4% 的性能跃迁
在视觉语言模型(VLMs)的发展进程中,文档 OCR 始终面临着布局解析复杂、语义逻辑对齐等核心挑战。如何让模型像人类一样「读懂」视觉逻辑,成为提升文档理解能力的关键突破口。近期,DeepSeek-AI 推出的 DeepSeek-OCR 2 给出了最新答案。其核心是采用全新 DeepEncoder V2 架构:模型摒弃传统 CLIP 视觉编码器,引入 LLM 风格的视觉编码范式,通过双向注意力与因果注意力的融合,实现视觉 token 的语义驱动式重排,为 2D 图像理解构建出一条「双阶段 1D 因果推理」的新路径。
查看完整报道:https://go.hyper.ai/nMH13
4. 覆盖天体物理/地球科学/流变学/声学等 19 种场景,Polymathic AI 构建 1.3B 模型实现精确连续介质仿真
在科学计算和工程模拟领域,如何高效、精确地预测复杂物理系统的演化,一直是学术界和工业界的核心难题。与此同时,深度学习在自然语言处理和计算机视觉领域的突破,引发了研究者们探索「基础模型」在物理模拟中的应用可能性。然而,物理系统往往跨越多个时间尺度和空间尺度演化,而多数学习模型通常仅在短期动力学上进行训练,一旦被用于长时间尺度预测,误差便会在复杂系统中不断累积,导致模型不稳定。以此为基础,来自 Polymathic AI 协作组的研究团队提出了一个拥有 13 亿参数、以 Transformer 为核心架构、主要面向类流体连续介质动力学的基础模型 Walrus 。
查看完整报道:https://go.hyper.ai/MJrny
热门百科词条精选
1. 倒数排序融合 RRF
2. Kolmogorov-Arnold 表示定理
3. 大规模多任务语言理解 MMLU
4. 黑盒优化 BlackBox Optimizers
5. 类条件概率 Class-conditional Probability
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:

一站式追踪人工智能学术顶会:https://go.hyper.ai/event
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!








