HyperAI
Command Palette
Search for a command to run...
LLM4Mat-Bench 晶体结构数据集
LLM4Mat-Bench 是由普林斯顿大学、 多伦多大学等机构联合创建的一个用于材料属性预测的多模态语言模型评估数据集,相关论文成果为「LLM4Mat-Bench: Benchmarking Large Language Models for Materials Property Prediction」, 旨在评估大型语言模型 (LLMs) 在材料属性预测与材料发现任务中的性能。该数据集收录了约 197 万条晶体结构样本,来自 10 个公开材料数据库,涵盖 45 种不同的材料物理与化学属性,是迄今为止用于评估大型语言模型 (LLM) 用于材料性能预测的性能的最大基准。
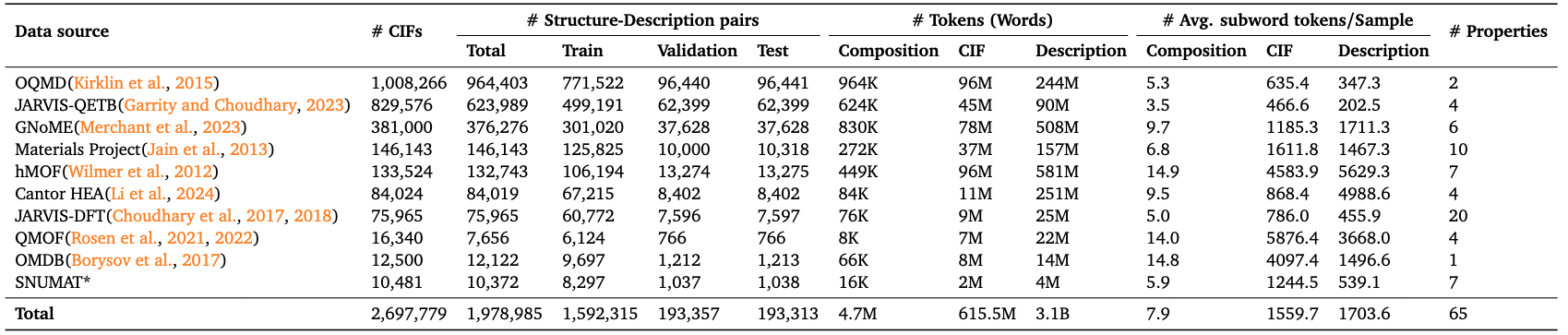
数据总量:
- 晶体组成模态 (Composition):约 4.7M tokens
- 晶体结构模态 (CIF):约 615.5M tokens
- 文本描述模态 (Text Descriptions):约 3.1B tokens 该数据集的构建流程包括从多个主流材料数据库中采集原始 CIF 文件与材料属性,并基于晶体结构自动生成结构语言描述,从而形成多模态、统一结构的数据样本。每个样本记录均包含对应的材料 ID 、化学式、属性值(如带隙、形成能、密度、弹性模量等)等信息。 LLM4Mat-Bench 的核心目标是推动材料科学与自然语言处理的交叉融合,促进任务特定模型评估、属性预测、指令微调等方向的研究与应用发展。其多源、多模态、大规模的特点,使其成为材料语言模型研究中的重要参考基准。
Citation
“`bib @article{rubungo2025llm4mat, title={LLM4Mat-bench: benchmarking large language models for materials property prediction}, author={Rubungo, Andre Niyongabo and Li, Kangming and Hattrick-Simpers, Jason and Dieng, Adji Bousso}, journal={Machine Learning: Science and Technology}, volume={6}, number={2}, pages={020501}, year={2025}, publisher={IOP Publishing} }
此数据集由社区用户贡献,仅用于教育和信息目的。如有任何内容涉及版权侵权,请通过 support@hyper.ai 联系我们,我们将及时审核并删除。