Command Palette
Search for a command to run...
既快又准!Cohere 发布开源转录模型;复杂场景精准解析:Chandra-ocr-2 视觉语言模型实现精准 OCR

在当前全球数字化转型加速的浪潮下,语音数据已成为企业挖掘商业价值的新矿藏,但如何在保证转录高精度的同时,突破推理成本与处理速度的瓶颈,一直是一道悬而未决的难题。 Cohere 公司于 2026 年 3 月发布了一款开源语音识别模型 Cohere-transcribe-03-2026 。这款拥有 20 亿参数规模的专用转录模型,其轻量级、高产出、高准确率的特性,为大模型时代下的「精准语音处理」定义了新的技术标准。
Cohere-transcribe 最显著的特点是极致的推理效率与精准度。研发团队采用了非对称的编码器-解码器架构,将超过 90% 的算力集中于 Fast-Conformer 编码器,通过极简的解码器大幅削减了自回归推理的计算开销,解决了传统 ASR 模型部署成本高、响应慢的难题。
在数据工程上,它依托 50 万小时精选语音转录对,结合专有的清洗管线、多轮错误分析下的合成数据增强,让模型练就了一副「金耳朵」,即便在环境很乱的情况下也能精准听清;该模型配合可灵活定制标点的提示词机制,能根据使用者需求自动加标点或调整格式,不仅解决了许多原始资料没标点的难题,也让最后生成的文字读起来顺畅自然,真正做到了既快又准。
目前,HyperAI 超神经官网已上线了「Cohere Transcribe 开源轻量化语音模型」,快来试试吧~
在线使用:https://go.hyper.ai/DonpU
4 月 06 日-4 月 12 日,hyper.ai 官网更新速览:
* 优质公共数据集:4 个
* 优质教程精选:9 个
* 社区文章解读:2 篇
* 热门百科词条:5 条
* 4 月截稿顶会:3 个
访问官网:hyper.ai
公共数据集精选
1. ToolACE 复杂工具学习对话数据集
ToolACE 是一个用于工具学习任务的自动化代理流水线数据集,由上海交通大学联合中国科学技术大学、华为诺亚方舟实验室等机构于 2024 年发布。该数据集旨在生成准确、复杂且多样化的工具学习数据,专门解决工具学习中数据质量不足和场景多样性有限等实际挑战。
直接使用:https://go.hyper.ai/RDx6d
2. CHOCLO 拉丁美州文化基准数据集
CHOCLO 数据集是一个基准数据集,旨在评估语言模型在涉及拉丁美洲文化知识的任务上的性能。它旨在评估语言模型表征拉丁美洲文化的准确性,尤其关注模型训练和输出中存在的实际问题,例如该地区文化代表性不足、遗漏和偏见等。
直接使用:https://go.hyper.ai/dnYtT
3. DRACO 跨领域深度研究基准数据集
DRACO(跨领域深度研究准确性、完整性和客观性基准数据集)是由 Perplexity 团队发布的数据集,旨在评估复杂的研究任务。该数据集包含 100 项复杂的研究任务,涵盖五大洲 40 个国家和地区。这些任务涉及 10 个主要应用领域,包括金融、购物/产品比较、学术界和技术。每项任务都是一个多步骤、多来源的信息检索和分析问题,并配有由 26 位领域专家设计和验证的评估标准。
直接使用:https://go.hyper.ai/SdAUn
4. COCO-2017-Vietnamese 越南语图像检测数据集
COCO-2017-Vietnamese 是一个基于 Microsoft Common Objects in Context (COCO) 2017 数据集的越南语本地化扩展数据集,由 AI Enthusiasm 社区精心维护并发布。该数据集为原始英文图像描述提供了高质量的越南语翻译,提供了一个全面的双语基准数据集,适用于图像描述和多模态学习等任务。
直接使用:https://go.hyper.ai/KSv2V
公共教程精选
1. Cohere Transcribe 开源轻量化语音模型
Cohere Transcribe 是由 Cohere 公司于 2026 年 3 月开源的轻量化语音模型,这款模型拥有 20 亿参数,专为边缘设备设计,旨在打破以往语音模型因体积过大而导致的延迟瓶颈。 Cohere Transcribe 在训练中涵盖了包括中文、日语、法语和希伯来语在内的 14 种语言。
在线运行:https://go.hyper.ai/DonpU
2. LTX-2.3-turbo 视频生成器
LTX-2.3-turbo 是 Lightricks 于 2026 年 3 月发布的一款开源视频生成基础模型,旨在突破开源视频生成能力的极限。该模型采用先进的扩散变换器架构,并结合多模态理解能力,实现了高质量、多分辨率的视频内容生成。
在线运行:https://go.hyper.ai/tkiw4
3. 一键部署 Gemma-4-31B-it
Gemma 4 31B IT 由 Google DeepMind 于 2026 年 4 月 2 日发布,是 Gemma 4 系列中一款 31 亿位密集指令优化模型。它支持文本和图像输入以及文本输出,提供高达 256K 个词元的上下文窗口,并原生支持推理、函数调用和系统提示,使其非常适合高质量的问答、编码辅助和智能体服务。它支持超过 140 种编程语言,主要面向推理、编程、智能体工作流和多模态理解任务。
在线运行:https://go.hyper.ai/RLgK9
4. 一键部署 gemma-4-26B-A4B-it
Gemma 4 26B A4B IT 由 Google DeepMind 于 2026 年 4 月 2 日发布。它支持文本和图像输入以及文本输出,上下文窗口最大可达 256K 个词元,并原生支持推理、函数调用和系统提示,因此非常适合高质量的问答、编码辅助和智能体服务。它支持超过 140 种语言,主要面向推理、编程、智能体工作流和多模态理解任务。
在线运行:https://go.hyper.ai/blUyh
5. OmniCoder-9B:面向智能体编码任务
OmniCoder-9B 由 Tesslate 于 2025 年 9 月发布。它是一个基于混合 Qwen3.5-9B 架构的 9B 参数编码代理模型,定位为可部署在单个 GPU 上的开源编码助手。 OmniCoder-9B 针对实际软件工程工作流程进行了专门优化,重点关注连贯的多步骤推理、终端操作、工具使用和代码修改流程。它尤其适用于需要先理解、再修改、最后验证的编码任务,而不是仅返回一次性答案的任务。
在线运行:https://go.hyper.ai/LfNz9
6. Fish Audio S2-Pro 自然语言控制语音情感
Fish Audio 于 2026 年 3 月发布了 FishAudio-S2-Pro,这是一款拥有 50 亿参数的端到端双自回归(Dual-AR)文本转语音(TTS)模型(40 亿慢速自回归+4 亿快速自回归)。它针对多语言语音合成、个性化语音克隆、情感语音生成等场景进行了深度优化,专为高自然度和高可控性的语音合成任务而设计。
在线运行:https://go.hyper.ai/QEAJZ
7. Chandra-ocr-2 数学/表格/手写精准转结构化内容
Chandra-ocr-2 是由 Datalab 团队于 2026 年 3 月推出的新一代光学字符识别系统,专注于复杂场景下的文字识别与结构化输出。该模型基于先进的视觉语言预训练技术进行微调,能够对上传的图像内容进行智能识别并返回格式化的文本结果。
在线运行:https://go.hyper.ai/3KobP
8. Crow-9B-HERETIC-4.6:可本地调用的对话模型
Crow-9B-HERETIC-4.6 由 Crownelius 于 2025 年发布。该模型基于 Qwen 3.5 架构体系构建,参数规模为 9B,并以 Distilled LLM 的形式发布,整体面向高质量通用对话、逻辑推理、长文本写作、代码辅助以及多轮交互等任务场景进行了优化。作为一款强调回答直接性、完整性与结构化表达能力的本地大语言模型,Crow-9B-HERETIC-4.6 适合作为通用智能助手、学习辅助模型和文本生成模型使用。
在线运行:https://go.hyper.ai/DrpSp

9. Granite 4.0 1B Speech:离线语音识别与翻译部署
IBM Granite 于 2026 年 3 月发布了 Granite 4.0 1B Speech 。它是一款参数量约为 10 亿的紧凑型语音模型,专为多语言自动语音识别和双向语音翻译而设计,支持英语、法语、德语、西班牙语、葡萄牙语和日语等多种语言。该模型强调在资源受限设备上的部署,非常适合基于本地权重目录和标准化服务接口构建的离线服务工作流程。
在线运行:https://go.hyper.ai/kzFhl
我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD 教程】,入群探讨各类技术问题、分享应用效果~

社区文章解读
1. 康奈尔大学开发多智能体平台 EMSeek,仅需 2-5 分钟即可将电子显微镜图像转化为材料学见解
来自康奈尔大学的研究团队提出了一个模块化且具备溯源追踪能力的多智能体平台 EMSeek,在 20 种材料体系和五类任务上的评测结果表明,其在分割任务上实现了约两倍于 Segment Anything 的速度并具备更高精度,并且在仅约 2% 标注数据进行校准的情况下,在 3 个分布外性质预测基准上达到或超过强单一专家模型的表现。完整查询在每张图像上仅需 2 至 5 分钟,速度约为专家流程的 50 倍。
查看完整报道:https://go.hyper.ai/1OlNI
2. 实现 1.4—3.7 倍推理加速,MIT 提出 DRiffusion 破解扩散模型采样延迟瓶颈
麻省理工学院的研究人员提出了 DRiffusion 草稿-精炼扩散模型,融合系统级方法与数学方法的优势,在不牺牲生成质量的前提下实现了显著加速,为兼顾扩散模型的高保真度与采样效率提供了全新的解决方案。
查看完整报道:https://go.hyper.ai/lbzzK
热门百科词条精选
1. 技能 Skills
2. Underfitting
3. 故障词元 Glitch Token
4. 地面真实值 Ground Truth
5. 倒数排序融合 Reciprocal Rank Fusion
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
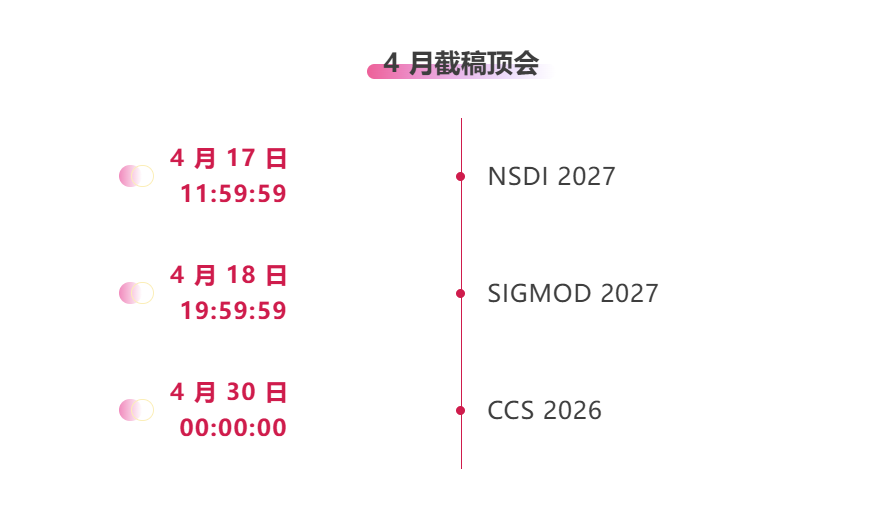
一站式追踪人工智能学术顶会:
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!








