Command Palette
Search for a command to run...
ICLR 2026 丨单任务可训练参数减少 125 倍!新方法 Task Tokens 助力具身智能提升复杂任务能力

近年来,机器人控制领域模仿学习的进展催生了基于 Transformer 的行为基础模型(Behavior Foundation Models, BFMs),该模型能够实现类人智能体的多模态控制。这些模型在给定高级目标或提示的情况下生成解决方案,例如,在给定机器人骨盆位置的情况下,引导机器人走到某个坐标。尽管 BFM 在零样本生成稳健行为方面表现出色,但在执行特定任务时通常需要精细的提示工程(prompt engineering),这可能导致结果并非最优。
在此背景下,来自以色列理工学院的研究团队提出了一种名为 Task Tokens 的方法,该方法能够在保持 BFM 灵活性的同时,有效地将其适配到特定任务。与标准基线方法相比,新方法可以将每个任务的可训练参数减少高达 125 倍,并且收敛速度提高高达 6 倍。
同时,研究人员也在多种任务(包括分布外场景)中验证了 Task Tokens 的有效性,并展示了其与其他提示方式的兼容性。实验结果表明,Task Tokens 在保持泛化能力的同时,为将 BFM 适配到具体控制任务提供了一种具有前景的解决方案。
相关研究成果以「Task Tokens: A Flexible Approach to Adapting Behavior Foundation Models」为题,已入选 ICLR 2026 。
研究亮点:
* 任务特定适配:Task Tokens 通过 tokenized control 将 MaskedMimic(GC-BFM)适配到特定任务,无需微调基础模型,同时保留其零样本能力
* 混合控制范式: 实现用户定义的高层先验(如文本或关节目标)与基于奖励的学习优化的无缝结合
* 性能与泛化能力: 在任务性能上与完整微调方法相当,同时在应对环境动力学变化(如重力和摩擦力)的鲁棒性方面优于其他方法。

论文地址:
https://hyper.ai/papers/2503.22886
查看更多前沿 AI 论文:
任务集:测试模型在系列接近真实世界场景中的通用性
研究中设计了一组标准化任务,旨在测试模型在一系列接近真实世界场景中的通用性与适应性,每个任务都为控制问题引入了不同层级的复杂性。
Direction(方向行走)
该任务要求角色沿指定方向移动,用于测试模型在基础行走控制以及目标方向对齐方面的能力。成功标准为——在测量时间内,类人模型沿目标方向的速度偏差不超过目标速度的 20% 。
Steering(转向控制)
该任务要求类人模型在沿指定方向移动的同时,还需保持骨盆朝向某一指定方向。这测试了更精细的运动控制能力,并引入更复杂的场景。成功标准为——角色在保持目标方向速度偏差不超过 20% 的同时,其朝向偏差总和不超过 45°。
Reach(触达)
在该任务中,类人模型需要用右手触达指定坐标点。这要求动作具有较高精度。成功标准为——右手位置与目标位置之间的距离小于 20 厘米。
Strike(击打)
该任务要求角色先行走至目标附近,然后执行动作将目标击倒。这不仅测试基础行走能力,还考察复杂的任务导向行为,包括时间控制与空间感知能力。成功标准为——目标物体被击倒,并在某一姿态下倾倒,其偏离角度不超过约 78°。
Long Jump(跳远)
角色需要在一条宽 1 米的通道中助跑,在 20 米后越过一条线并起跳,在越过起跳线后不得再次接触地面。成功标准为——跳跃距离超过 1.5 米。
基于 MaskedMimic 架构的高效任务适配方案
本研究提出的方法基于一种名为 MaskedMimic 的「目标条件行为基础模型(Goal-Conditioned Behavior Foundation Models, GC-BFMs)」。不同于传统依赖奖励信号进行学习的 GCRL 方法,MaskedMimic 结合 Transformer 架构,并对作为输入 token 的未来目标进行随机掩码处理,从而能够从多种模态(如未来关节位置、文本指令以及交互对象)中学习并复现类人行为。
这种架构与控制机制的结合,使 MaskedMimic 成为 Task Tokens 方法的理想基础;在此之上,研究人员进一步通过学习任务特定的 Tokens 来优化下游任务表现,从而增强其能力。
Task Tokens
如下图,Task Tokens 融合了三类输入来源:
* 先验 Token(Prior Token):可选输入,用于通过文本提示或关节条件引入用户定义的行为先验;
* 任务 Token(Task Token):由训练的任务编码器生成,该编码器对当前目标观测进行处理;
* 状态 Token(State Token):表示当前环境状态。
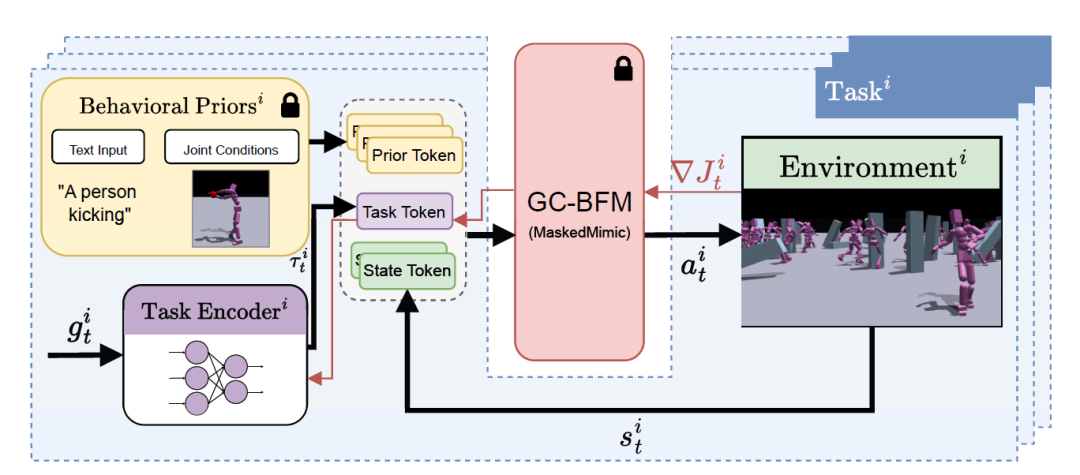
研究人员为每一个新任务训练一个专用的任务编码器,以生成对应的专属 Tokens 表示。该 Task Tokens 浓缩了目标行为的独特需求与约束,为基础模型提供简洁但信息充分的引导信号,使其在保持通用行为先验的同时,生成符合特定任务需求的输出。
任务编码器(Task Encoder)
任务编码器接收定义当前任务目标的观测,这些观测以智能体自身为参考系表示,并输出一个 Task Token 。不同任务的观测形式各不相同——例如,在转向任务中,观测包括目标运动方向、朝向方向以及期望速度。
由于 MaskedMimic 是基于未来姿态目标进行训练的,任务编码器还会接收本体感觉信息(proprioceptive information),以与预训练表示对齐,从而生成有意义的目标信号。
研究人员将任务编码器实现为一个前馈神经网络。其输出(即 Task Token)会与 BFM 输入空间中的其他编码器 token 进行拼接,形成一个 Token「句子」。在这个结构中,任务编码器输出的 Token 相当于专门的「词语」,用于在保持动作自然性的同时,引导模型完成特定任务。
训练(Training)
为了使任务编码器适配新的下游任务,研究人员采用近端策略优化(Proximal Policy Optimization,PPO)。在训练过程中,BFM 根据包含 Task Token 在内的组合输入 token 预测动作概率分布;基于任务特定奖励以及 BFM 输出的动作概率来计算 PPO 目标函数,从而获得用于更新任务编码器参数的梯度,同时保持 BFM 本身冻结不变。
高效且有效地将 BFM 适配到特定任务
研究人员通过一系列全面实验评估了 Task Tokens 方法的有效性,从四个关键方面验证其性能与适用性,并与多种具有竞争力的基线方法进行对比,包括:
Pure RL:仅使用 PPO 训练策略,不依赖任何基础模型;
* MaskedMimic Fine-Tune:使用奖励信号对整个 MaskedMimic 模型进行优化(不冻结参数);
* MaskedMimic(仅关节条件):原始 MaskedMimic,仅使用关节条件作为提示机制;
* PULSE:一种分层方法,通过复用动作捕捉数据中的潜在技能空间;
* AMP:利用判别器在优化任务性能的同时保证动作质量。
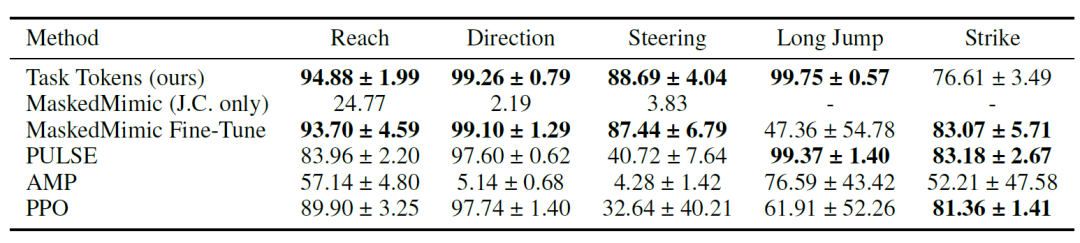
任务适配(Task Adaptation)能力
研究人员首先展示 Task Tokens 能够有效地将 MaskedMimic 适配到下游任务中,数值结果见下表。结果表明,Task Tokens 在大多数环境中都取得了较高的得分,其中在 Strike 任务上,PULSE 、 MaskedMimic Fine-Tune 以及 PureRL 获得了更高的分数。
此外,下图展示了训练过程中的成功率变化曲线,从中可以观察到,Task Tokens 大约在 5000 万(50M)步内即可收敛,而 PULSE 需要约 3 亿(300M)步才能达到相同性能。
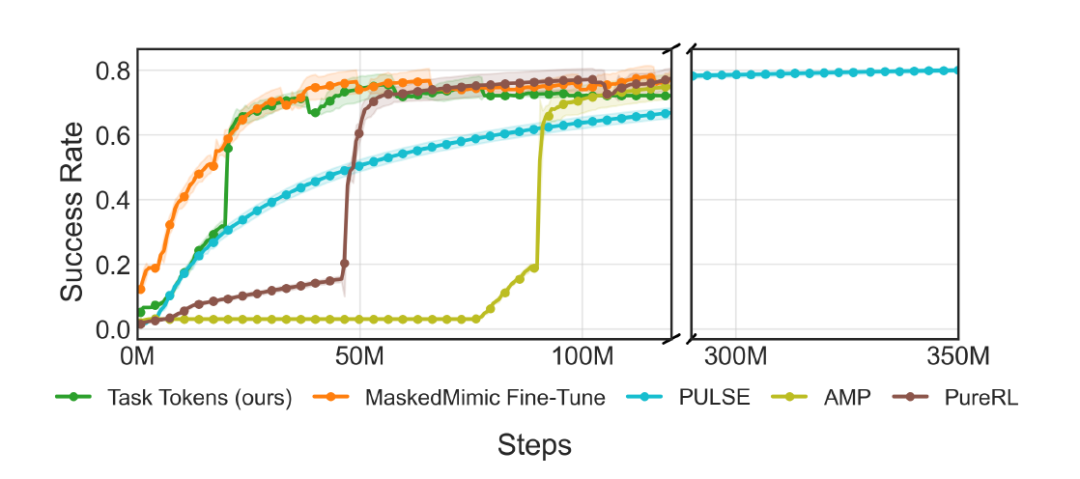
在实现上述结果时,Task Tokens 仅需训练一个约 20 万(~200K)参数的编码器,而 PULSE 和 MaskedMimic Fine-Tune 分别需要 930 万(9.3M)和 2500 万(25M)参数,分别高出约 46.5 倍和 125 倍。这种效率在真实应用场景中尤为关键,因为大规模模型训练成本极高。
这些结果表明,Task Tokens 能够高效且有效地将 MaskedMimic 等行为基础模型适配到新的、未见过的任务中。
分布外(OOD)泛化能力
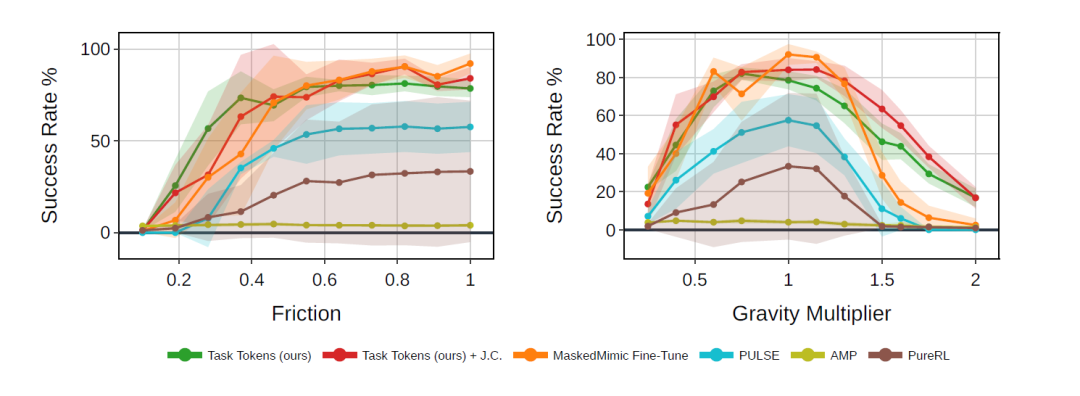
研究人员在分布外(out-of-distribution, OOD)扰动条件下进行对比实验,这些扰动在原始 BFM 和 Task Tokens 的训练过程中均未出现,主要考虑两类变化:重力(gravity)和地面摩擦系数(ground friction)。
下图结果表明,借助 BFM,Task Tokens 在新的未见场景中展现出显著增强的鲁棒性。首先,在基准任务(无扰动)下,Task Tokens 的表现几乎与对 MaskedMimic 进行完整微调相当,并且优于所有其他基线方法。随后,随着扰动强度增加,其性能相比基线方法显著更优。值得注意的是,在极低摩擦环境(例如 ×0.4)以及较大重力环境(例如 ×1.5)下,Task Tokens 依然保持明显更高的成功率。
类人研究(Human Study)
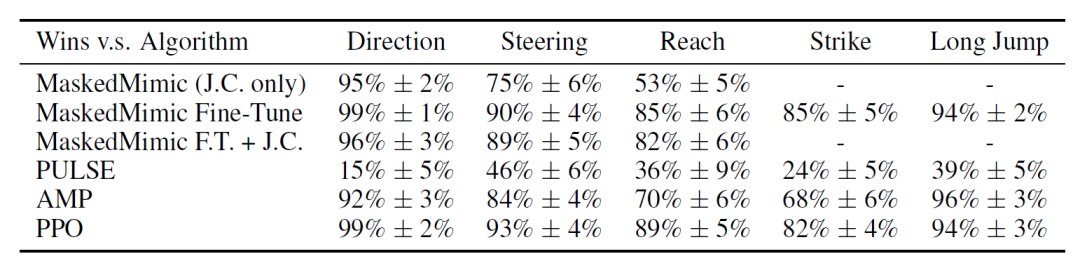
下表展示了 Task Tokens 相较于各个对比方法被选为更「人类化」动作的比例。结果表明,Task Tokens 明显优于 MaskedMimic(仅 J.C.)以及 MaskedMimic Fine-Tune 。这说明用户设计的条件对于基础 MaskedMimic 模型而言具有一定分布外特性,而相比微调,Task Tokens 在动作质量方面是一种更有效的适配方式。
此外,可以观察到尽管 Task Tokens 在收敛速度、参数规模以及任务性能方面均更优,但在「动作人类相似度」方面,PULSE 的评分更高。
综合上述结果,可以认为 Task Tokens 在效率、动作质量与鲁棒性之间实现了较好的平衡。
多模态提示(Multi-Modal Prompting)效果
最后,研究人员探讨了 Task Tokens 与其他提示方式的协同效果,展示其良好的兼容性与灵活性。
在 Direction 任务中,奖励函数仅鼓励智能体朝正确方向移动,但并未考虑类人的身体朝向。因此,策略可能会收敛到「倒退行走」的行为。尽管这种行为能够获得较高的奖励与成功率,但显然并不符合期望。
下图展示了通过引入人为设计的先验(例如对头部目标高度与朝向的约束),训练过程能够收敛到一种「直立向前行走」的运动方式。

在 Strike 任务中,智能体需要击中目标——一种常见的涌现行为是:智能体倒退接近目标,然后执行一种「旋风式(whirlwind)」动作,通过原地旋转来用手击中目标。下图展示了两种先验模态的结合方式。
首先,通过类似 Direction 任务的朝向条件,使智能体在移动过程中始终面向目标;随后,当接近目标后,引入文本目标「一个人执行踢击动作」,引导智能体使用脚完成击打动作。

值得注意的是,研究人员观察到对整个模型进行微调会导致众所周知的灾难性遗忘问题,从而削弱模型对多模态提示的保留与融合能力。相比之下,Task Tokens 通过冻结基础模型,保留了其预训练的提示能力,使得学习到的行为与人为指定的行为能够更一致地融合。
结语
当前实验主要基于 MaskedMimic 架构,未来需在更广泛的 GC-BFM 架构中验证方法的通用性。尽管任务相关奖励与观测设计仍依赖专家经验,未来可探索(半)自动化设计以降低使用门槛。一个关键方向是将 Task Tokens 适配的策略迁移到真实机器人系统,解决仿真到现实问题,并扩展到需要高层决策的复杂真实任务,而不仅限于动画模拟。
最后,探索更复杂的任务编码器结构(超越当前的前馈网络架构)也可能带来进一步性能提升。解决上述问题将进一步完善 Task Tokens 框架,并推动更具多样性、适应性与能力的类人智能体的发展。
参考文献:
https://openreview.net/forum?id=6T3wJQhvc3
https://arxiv.org/pdf/2503.22886