Command Palette
Search for a command to run...
ICLR 2026 丨英伟达/牛津大学等提出原子级蛋白质结合剂生成方法,性能达 SOTA 级别

在计算生物学领域,设计能够与特定靶点精准结合的蛋白质,是最核心也最具挑战的问题之一。它不仅直接关系到药物研发、生物治疗与酶工程等关键方向,也决定了人类在复杂疾病干预与生物制造效率上的上限。
从分子层面来看,蛋白质与靶点的结合本质上是一个三维结构问题:界面的氨基酸组成、空间构象以及分子间相互作用共同塑造了结合的亲和力与特异性。因此,几乎所有结合剂设计方法,最终都要回到「结构」这一核心变量,通过解析或预测结构来指导分子构建。
近年来,机器学习的引入正在重塑这一范式。随着结构预测与结构生成模型的突破,研究逐渐摆脱对实验结构的强依赖,从「解析结构」走向「生成结构」,使从头设计结合剂成为可能,显著压缩研发成本与周期。
然而,在方法路径上,当前 AI 驱动的结合剂设计仍呈现出明显分裂:一类是以 RFDiffusion 为代表的生成式方法,依赖大规模训练直接生成候选结构,但推理阶段缺乏灵活调整能力;另一类是以 BindCraft 为代表的幻觉式方法,通过结构预测器的评分进行梯度优化,具备灵活性却缺乏生成先验,难以探索全新结构空间。这种「生成与优化分离」的格局,与自然语言和图像领域已形成的「预训练模型 + 推理时计算扩展」的统一范式形成对比。
正是在这一背景下,英伟达、牛津大学、魁北克人工智能研究所等机构的联合研究团队提出了 Proteína-Complexa(以下简称 Complexa)框架,旨在弥合生成式与幻觉式方法之间的断层,将基础生成模型与推理时优化机制统一于同一体系之中。基于 Teddymer 预训练,Complexa 能够实现 SOTA 级的从头结合剂设计,且无需额外的序列重新设计步骤。通过将扩散模型中的测试时缩放技术适配至该框架,生成与优化得以直接统一,从而在性能上超越了传统的幻觉式方法。
相关研究成果以「Scaling Atomistic Protein Binder Design with Generative Pretraining and Test-Time Compute」为题,已入选 ICLR 2026 。
研究亮点:
* 该研究提出了 Complexa,将 La-Proteina 扩展到结合剂设计,利用 Teddymer,并实现了由生成先验加速的高效推理时优化
* 在蛋白质和小分子靶点以及酶设计基准测试中都达到了最先进的计算机模拟成功率,而无需进行序列再设计
论文地址:
https://openreview.net/forum?id=qmCpJtFZra
关注公众号,后台回复「Complexa」获取完整 PDF
数据集:从「单体富集」到「复合体重构」
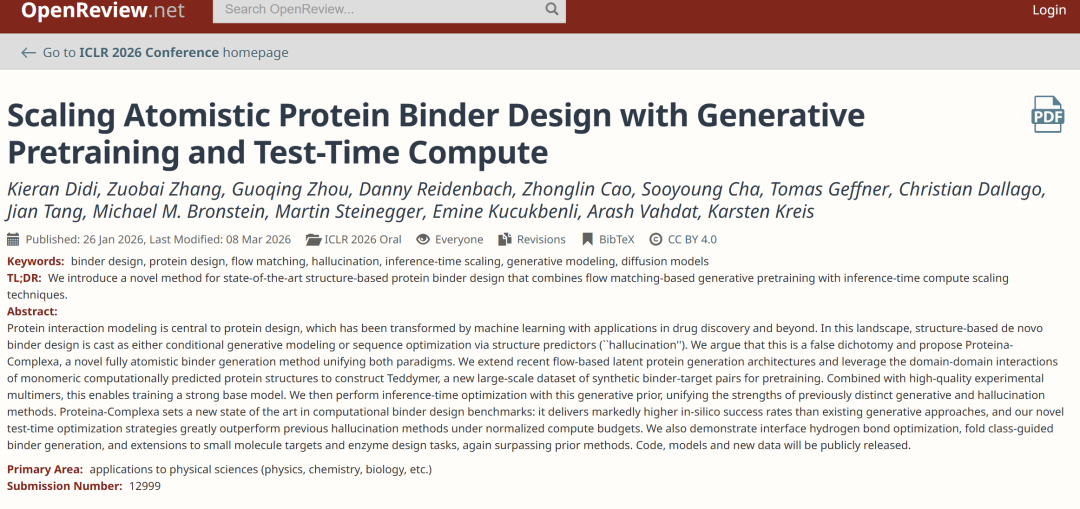
结合剂生成模型的一个根本限制在于数据。理想情况下,模型需要大量「结合剂—靶点复合体」数据进行训练,但现实是,这类数据主要来自实验解析的蛋白质数据库(PDB),规模有限且高质量样本更为稀缺;而规模更大的 AlphaFold 数据库(AFDB)虽然提供了海量蛋白结构,却几乎全部是单体结构,缺乏复合体信息。这种「单体丰富、复合体稀缺」的结构性缺口,直接限制了模型的规模化训练能力。
该研究的关键突破来自对 AFDB 内部结构的重新理解。 AFDB 中的蛋白多数为多结构域蛋白,而结构域划分工具 TED 为其提供了精细注释。进一步分析发现,同一蛋白内部不同结构域之间的相互作用,在统计特性上与多链复合体中的相互作用高度相似。这一观察带来了一个重要转变:单体结构本身并非「无用数据」,而是可以被重新解释为潜在的复合体数据来源。
基于这一洞察,研究提出了一种「人工多聚体构建」方法,通过将多结构域蛋白拆分为独立结构域,并将其视为不同链,从而在单体内部构造出类复合体结构。具体流程从 AFDB50 出发,筛选带有 TED 注释的蛋白,随后拆分为「伪多聚体」,进一步提取二聚体并根据空间邻近性筛选,同时保留具有完整注释的样本,最终经过聚类去冗余,得到约 350 万个二聚体簇。这一数据集被命名为 Teddymer,其本质不是简单扩展数据规模,而是通过结构重组,将「单体优势」转化为「复合体供给」。
在训练过程中,如下图所示,研究并未依赖单一数据源,而是将 AFDB 单体、 Teddymer 构造数据、 PDB 实验复合体以及 PLINDER 蛋白-配体数据进行整合,使模型能够在单体结构、复合体结构与小分子相互作用之间建立统一表示,从而兼顾生成能力与泛化能力。
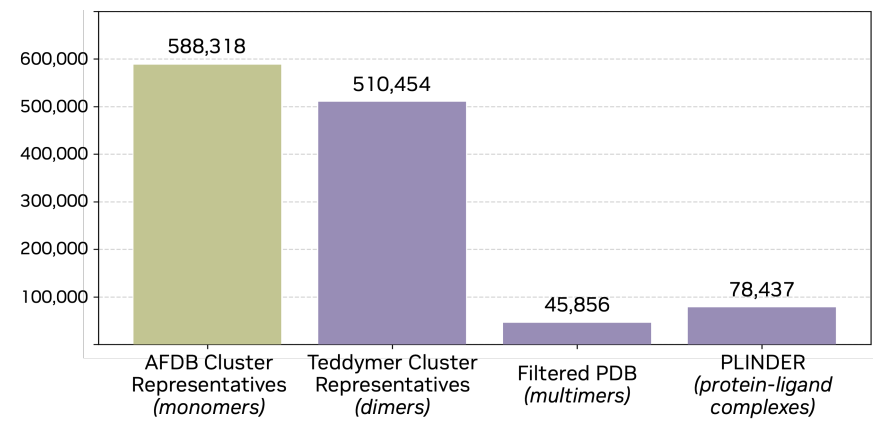
Complexa:一个用于蛋白质结合剂生成的全原子框架
在模型设计上,Complexa 的核心变化并不只是「更强的生成能力」,而是将生成目标从「完整蛋白结构」转向「特定界面上的结合剂」。该模型构建在 La-Proteína 基础之上,其优势在于具备全原子级别的生成能力,同时基于高效的 Transformer 架构,避免了传统结构模型中计算成本较高的模块,使其在大规模采样场景下具备良好的扩展性。
在此基础上,研究引入了以靶点与界面热点为条件的生成机制,使模型不再生成完整复合体,而是仅生成结合剂部分,并在生成过程中显式依赖靶点信息。具体而言,流匹配模型负责在条件约束下生成结构,而自编码器仅用于单体结合剂的编码与解码,从而在保持表达能力的同时降低建模复杂度。
为了让模型能够有效理解靶点信息,研究对输入表示进行了系统设计。蛋白质靶点通过 Atom37 方式编码,将残基级三维坐标、氨基酸类型以及界面热点信息统一输入模型,其中热点用于指示潜在结合区域。在训练阶段,这些热点由真实界面提取,在推理阶段则作为先验或通过预处理获得。对于小分子靶点,模型则在原子层面编码类型、电荷与空间坐标,并与结合剂表示一同输入 Transformer 进行联合建模。
在训练目标上,一个关键改进是对结合剂坐标引入随机全局平移噪声,从而迫使模型学习分子的空间定位能力。这一点在单体生成中并不重要,但对于需要将结合剂精确放置在靶点界面的任务而言,却是决定生成质量的关键能力。整个训练流程采用分阶段策略,从单体建模到通用结构生成,再到结合剂专项训练逐步推进,同时通过 LoRA 控制过拟合,并始终复用单体级自编码器,以保持架构简洁。
在推理阶段,Complexa 进一步引入「测试时计算扩展」机制,将生成过程与搜索优化结合起来。通过增加采样数量、引入束搜索或蒙特卡洛树搜索等方法,模型可以在更大的计算预算下持续提升生成质量。这种设计使模型能力不再完全受限于训练阶段,而可以在推理过程中动态扩展。
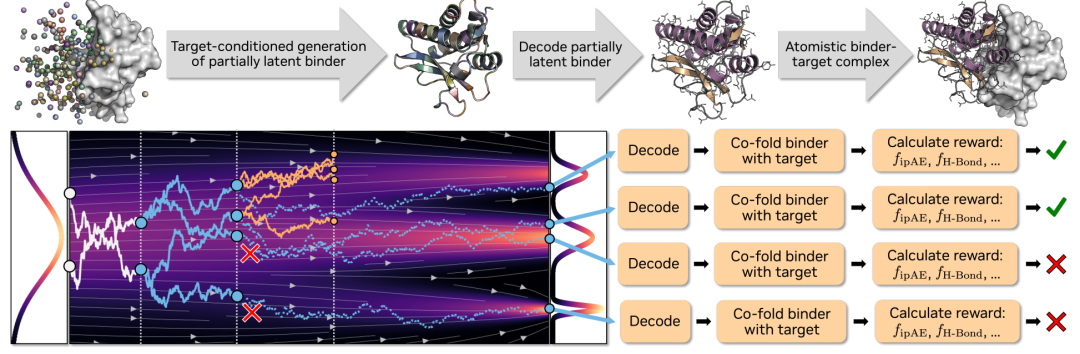
更高成功率、更快速度、更强可扩展性
围绕模型能力的验证,该研究设计了一组由浅入深的实验体系,核心问题是:Complexa 是否不仅在基础性能上更优,而且能够随着计算资源的增加持续提升表现。
在基础生成能力上,无论是蛋白质靶点还是小分子靶点任务,Complexa 均显著优于现有方法,不仅成功率更高、采样速度更快,同时生成结构的新颖性也明显提升。更重要的是,模型可以直接输出高质量序列,无需依赖 ProteinMPNN 等工具进行二次设计,从而简化了整体流程。
在结构可控性方面,研究通过引入条件标签,使模型能够显式控制生成结构的类型,例如在 α-螺旋与 β-折叠之间进行选择,从而有效缓解以往生成模型结构单一的问题,显著提升结构多样性。
在推理阶段的计算扩展实验中,结果显示,在简单任务上,仅通过增加采样数量即可超过所有基线方法,而在复杂任务中,引入更高级的搜索策略(如束搜索与蒙特卡洛树搜索)则进一步扩大优势。这表明模型性能可以随着计算预算的增加持续提升。如下图所示
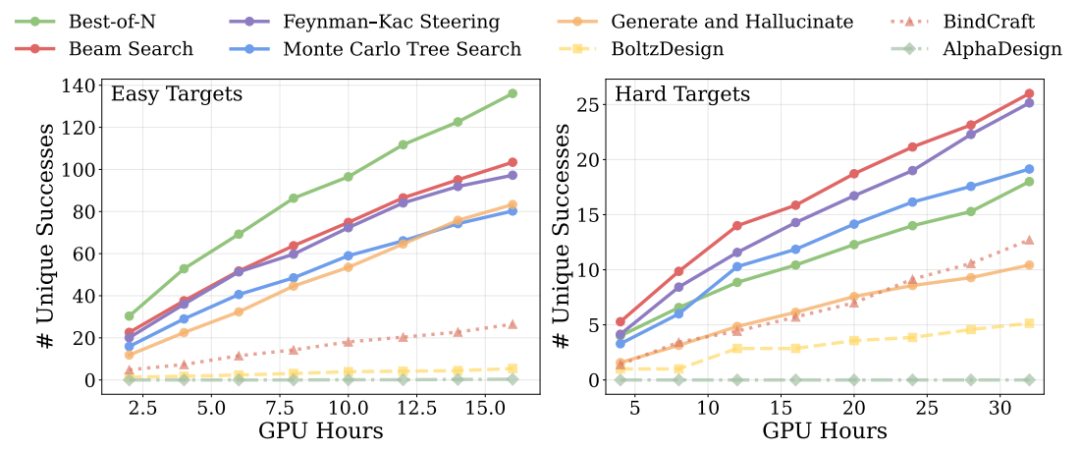
在物理合理性方面,研究进一步优化界面氢键与相关能量指标,发现模型不仅能够生成结构合理的结合剂,还能够在细粒度相互作用层面进行优化,从而提升结合稳定性。
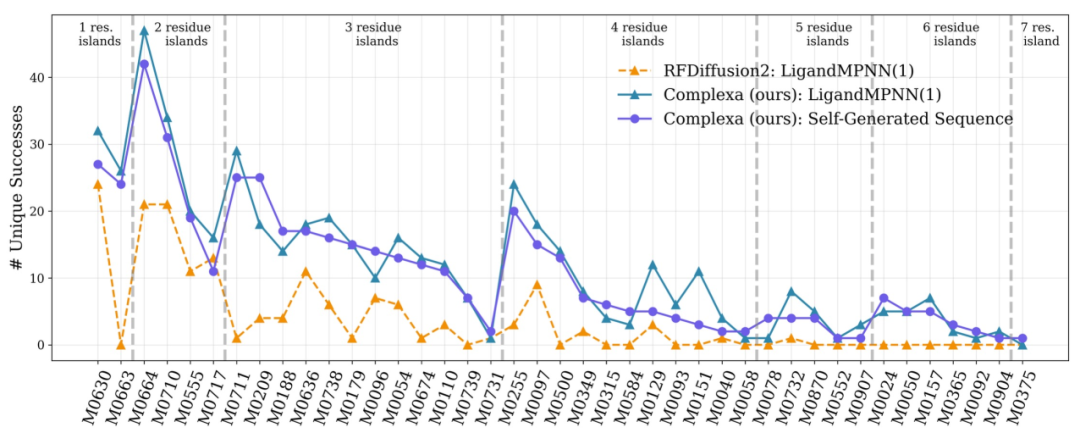
在更具挑战性的多链靶点任务中,现有方法在有限计算预算下无法获得有效解,而 Complexa 在扩展计算资源后成功生成高质量候选,体现出其在复杂问题上的可扩展性。最后,在酶设计等不同任务上的测试如下图所示,该框架具备良好的泛化能力,能够从结合剂设计扩展至更广泛的蛋白质工程问题。
AI 蛋白质设计的范式转移
近年来,AI 驱动的蛋白质结合剂设计正加速从理论走向实践,诺奖得主 David Baker 及其团队仍是该领域的重要引领者之一。 2025 年,其团队在 Science 连续发表多项研究,系统验证了基于 RFDiffusion 设计高特异性 pMHC 结合剂的可行性。相关工作针对 11 类疾病靶点,成功生成可驱动 T 细胞识别肿瘤的结合蛋白,并通过冷冻电镜在原子尺度上验证了设计精度,标志着 AI 设计开始具备可验证性。
与此同时,MIT 团队在 BoltzGen 模型中探索了更一体化的路线,将结构预测与结合体生成统一到单一全原子模型中,并采用连续几何表示替代传统离散建模。在 26 个靶标的实验中,66% 获得纳摩尔级亲和力的结合剂,并在分布外靶点上保持较高成功率,显示出一定的泛化能力。
产业界则更关注这些能力的工程化落地。 2026 年初,Bayer 与 Cradle 达成 3 年合作,将 AI 蛋白质工程平台整合进抗体研发流程。该平台已在 50 多个项目中应用,能够显著缩短研发周期,并支持「设计—测试—学习」的闭环迭代。这标志着 AI 正从辅助工具转变为研发流程中的基础能力。
整体来看,蛋白质设计的竞争正在从单一模型性能,转向系统级效率与可扩展性。学术界持续推进模型能力边界,而产业界则推动其进入稳定、可复用的研发流程。 AI 蛋白质设计也由此进入一个更实际的阶段:关键不再是「能否设计」,而是「能否持续、高效地设计」。
参考链接:
1.https://news.bioon.com/article/00bf92186439.html
2.https://mp.weixin.qq.com/s/1zKXUQtXgCJ7GA1_OUEShg
3.https://www.bayer.com/en/us/news-stories/ai-enabled-antibody-discovery-and-optimization








