Command Palette
Search for a command to run...
小样本生物医学研究新突破,德国团队基于生成式 AI 模型实现数据增强,或减少 30-50% 实验动物用量

动物实验中验证的「有效疗效」,进入临床阶段后却屡屡难以复现,样本量不足是核心根源之一。受伦理规范、实验成本与研究条件的多重限制,生物医学临床前研究往往难以开展大样本动物实验,这直接导致统计检验效力不足,研究者既无法稳定提取真实的生物学信号,又极易陷入假阳性结果的陷阱,严重阻碍基础研究向临床应用的转化。
为破解这一难题,学界曾尝试荟萃分析、数据合并等方法整合研究数据,但这类方法高度依赖不同研究间的实验设计、检测指标与操作流程的可比性,实际应用范围极为有限。
近年来,生成式人工智能为小样本研究提供了全新思路 —— 通过学习原始数据的内在分布结构,生成合成数据以扩充样本规模。然而,通用生成式模型存在明显短板:若原始数据自带随机误差,模型会进一步放大噪声、催生大量假阳性结果,反而降低研究结论的可信度。如何在生成数据的同时抑制误差传播,成为生成式 AI 落地生物医学领域的核心瓶颈。
针对这一关键痛点,德国法兰克福大学与弗劳恩霍夫 ITMP 研究所的联合研究团队研发出 genESOM——基于涌现自组织映射的生成式 AI 模型,专为小样本生物医学数据设计。该模型的核心创新是将结构学习与数据生成过程解耦,通过维度调节阻断误差传播,并引入阴性对照变量实时监控数据生成质量。研究团队以多发性硬化临床前脂质组数据为研究对象,先将样本量人为缩减至统计失效临界点,再用 genESOM 开展数据增强。
结果证实,该方法可有效恢复小样本数据中丢失的关键生物学信号,同时严格控制假阳性,为小样本生物医学研究提供了可靠的新方案。同时,在探索性研究场景中,该模型有望将所需实验动物数量减少约 30%–50%,同时仍然保持结果的可重复性与科学有效性。
相关研究成果以「Self-organizing neural network-based generative AI with embedded error inflation control enhances effective knowledge extraction from preclinical studies with reduced sample size」为题,已发表于 Pharmacological Research 。
研究亮点:
* 内置数据驱动的误差控制机制,有效抑制假阳性膨胀,区别于缺乏约束的 GAN 等方法。
* 在样本量缩减后成功恢复关键脂质信号(如溶血磷脂酸),且不增加假阳性率。
* 可减少 30–50% 的动物用量,作为补充分析工具,兼顾研究稳健性与 3R 伦理原则。

查看论文:
https://www.sciencedirect.com/science/article/pii/S1043661826000745
数据集:从完整实验到小样本统计失效
该研究数据源自一项已公开发表的多发性硬化临床前动物实验,研究采用 SJL/J 小鼠构建复发缓解型实验性自身免疫性脑脊髓炎(EAE)模型,旨在解析神经炎症机制,并验证获批药物芬戈莫德的治疗效果。
注:芬戈莫德是鞘氨醇-1-磷酸受体调节剂,可通过调控鞘脂代谢干扰免疫信号通路,是临床治疗多发性硬化的常用药物。
实验纳入 26 只 8 周龄雌性小鼠,随机分为 3 组:空白对照组、 EAE 模型组、 EAE + 芬戈莫德治疗组;治疗组于免疫诱导第 18 天起,以 0.5mg/kg/d 的剂量通过饮水给药。
研究团队同步采集行为学与分子层面数据:行为学指标涵盖运动能力、身体协调性与社交行为;分子层面采用 LC-MS/MS 靶向定量技术,检测血浆、小脑、海马、前额叶皮层 4 种组织中 62 种脂质介质的浓度,涵盖溶血磷脂酸、神经酰胺、鞘脂、内源性大麻素四大类,最终构建出「小鼠个体 × 脂质特征」的标准数据矩阵。
数据分析前,研究团队对脂质浓度数据进行对数变换,使其符合统计分析的分布假设。针对原始数据 5.3% 的缺失值,经多方法比对后,采用随机森林算法(missForest)完成缺失值填补。随后,研究对 62 种脂质指标开展单因素方差分析,并用 Šidák 校正控制多重检验误差;同时引入随机森林、支持向量机、 k 近邻 3 种机器学习模型,从组间差异显著性与分类预测能力双维度,交叉验证数据中生物学信号的稳定性。
完成基础分析后,研究开展核心验证实验:系统性缩减样本量,定位小样本统计失效的临界值。研究者逐步降低每组小鼠数量,每次缩减后重复全套分析流程。结果表明,当每组样本量降至 6 只时,原始数据中所有显著的统计结果完全消失,这一临界条件成为检验 genESOM 数据增强能力的基准——在统计完全失效的小样本场景下,验证 AI 能否找回被噪声淹没的生物学信号。
专为小样本生物医学数据打造的生成式 AI
传统生成式模型处理小样本数据时,始终面临两难困境:生成数据要么信息匮乏,无法恢复原始生物学信号;要么噪声过载,产生大量假阳性。 genESOM 的设计核心,正是在二者之间建立严谨的平衡机制,实现安全、可解释的小样本数据增强。
genESOM 以涌现自组织映射(ESOM)神经网络为基础,相较经典自组织映射(SOM)实现两大关键升级:其一,将神经元排布为二维环形网格,最大程度保留高维数据的邻域结构关系;其二,新增第三维度编码数据子群间距与投影误差,大幅提升潜在聚类结构的识别精度。
数据经标准化、缺失值处理后,投影至 ESOM 网络完成训练。模型持续匹配每个样本的最优匹配神经元,动态调整神经元权重,并逐步降低学习率以保障训练稳定性。训练完成后,模型输出两个核心矩阵:U 矩阵用于刻画神经元间距、识别聚类边界;P 矩阵用于统计局部数据密度,为合成数据生成提供依据;而控制合成数据生成范围的半径参数,通过高斯混合模型拟合距离分布自动确定,无需人工干预。
genESOM 最具突破性的设计是完全分离结构学习与数据生成两个环节,模型先独立完成数据内在结构的表征学习,再基于稳定的结构生成合成数据,从流程上避免两步过程的误差叠加。更关键的是,模型可引入置换变量作为阴性对照,实时监测特征重要性是否异常放大;一旦检测到误差累积,立即自动停止数据增强,从机制上规避过拟合与假阳性风险。
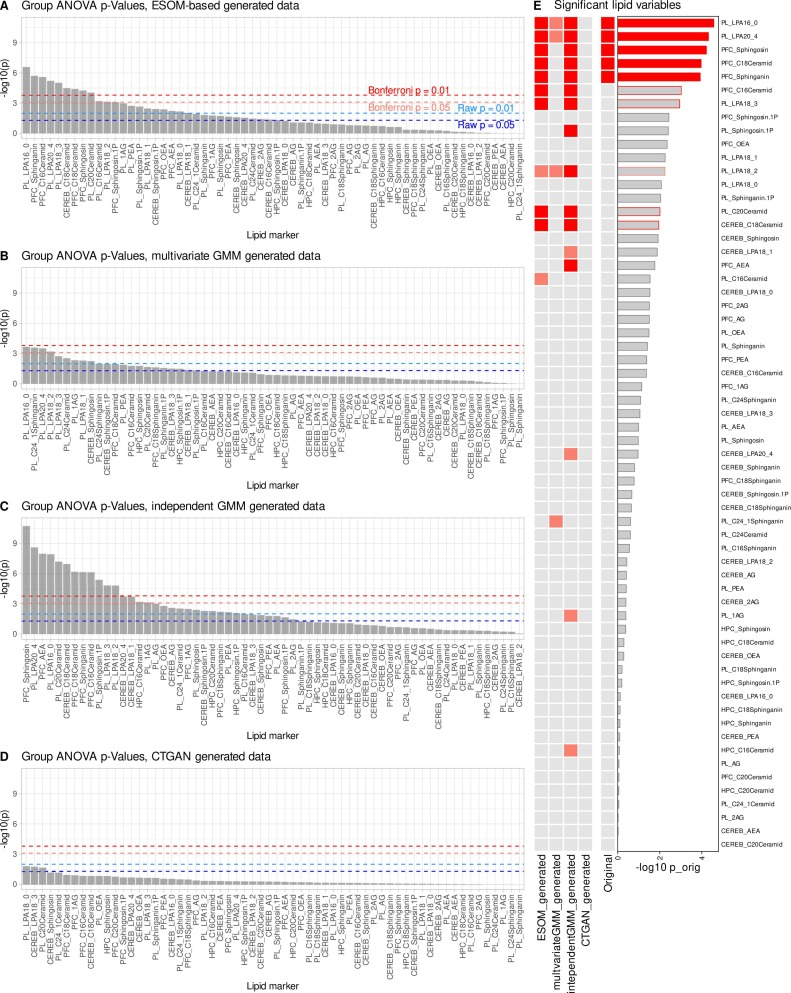
在本研究中,研究团队采用 1:1 安全增强比例(每个原始样本生成 1 个合成样本),将每组样本量从 6 只扩充至 12 只。增强完成后,重复原始数据的全套统计与机器学习分析,量化评估信号恢复效果。同时,研究将 genESOM 与两种主流生成方法开展头对头对比:高斯混合模型(GMM)、条件表格生成对抗网络(CT-GAN),以假阳性率、假阴性率、原始信号恢复率为核心指标,验证模型优势。
在小样本场景下显著优于传统生成方法
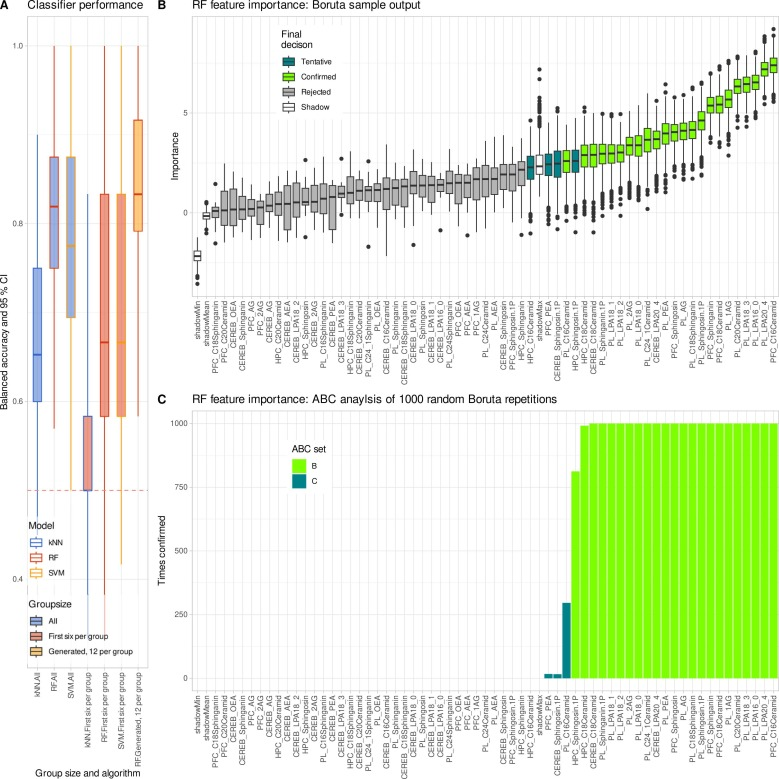
如下图所示,对完整原始数据集的分析显示,62 种脂质变量中有 27 种存在显著组间差异,其中溶血磷脂酸类脂质的变化最为显著,这一结果与多发性硬化既往研究结论高度吻合;同时,随机森林模型以远超随机概率的准确率完成样本分类,两项结果相互印证,证实原始数据中存在稳定、可靠的生物学信号。
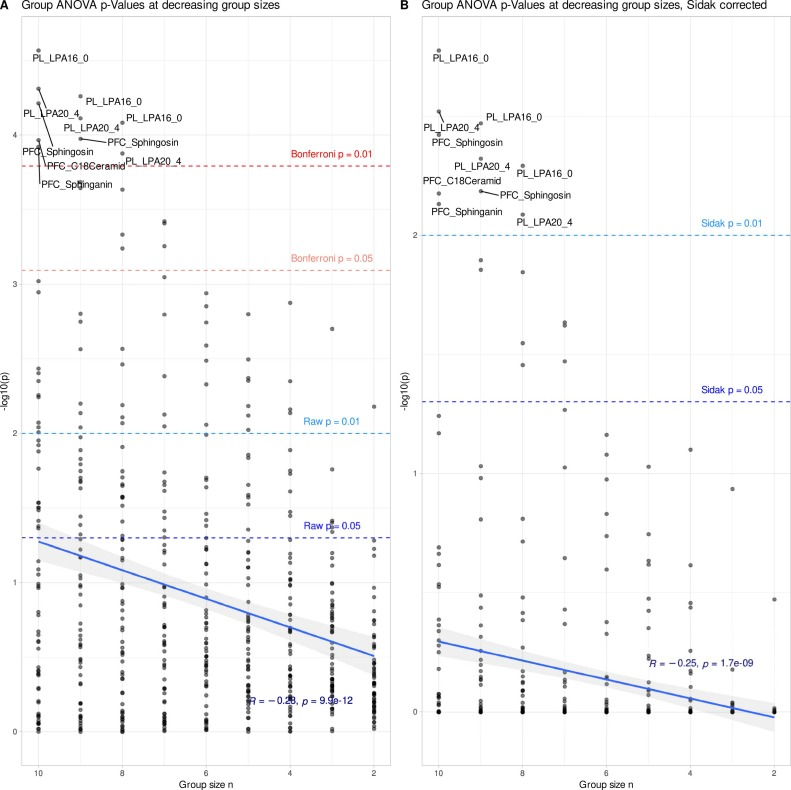
但当每组样本量缩减至 6 只后,如下图所示,数据特征发生颠覆性改变:经多重检验校正后,所有脂质指标的统计显著性完全消失,随机森林的分类效能也显著下降。需要强调的是,这并非生物学效应真实消失,而是小样本导致统计检测效力不足,真实信号被噪声淹没。
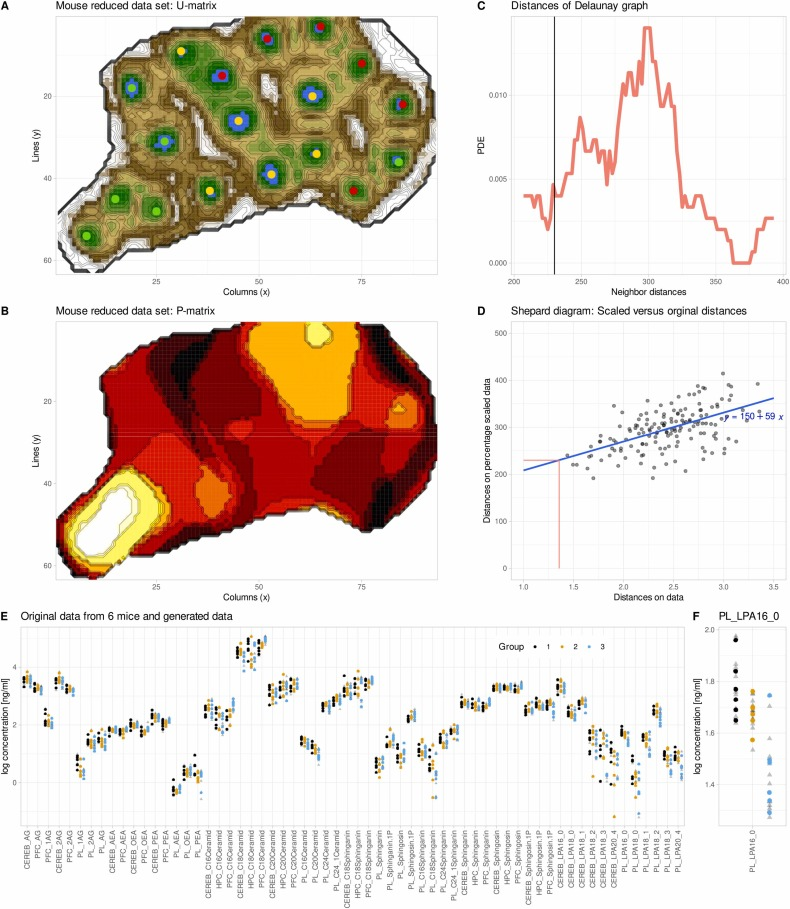
随后,研究团队用 genESOM 对缩减后的数据进行增强。模型经 20 轮训练后,仍能在 ESOM 空间中识别出三组样本的部分分离趋势,证实即便统计显著性消失,数据内部仍保留潜在的生物学结构信息。
数据增强后,血浆中溶血磷脂酸、前额叶皮层鞘脂类等关键脂质指标重新呈现显著组间差异,这些指标在小样本数据中已完全失效,却通过 AI 增强成功恢复;同时,模型未引入大量不合理的新特征,仅出现少量接近显著水平的附加指标。这表明 genESOM 并非凭空制造新信号,而是强化原本存在、但因样本量不足无法检出的真实生物学信号。
在同等小样本条件下,如下图所示,两种对照生成方法表现欠佳:多元高斯混合模型仅能恢复部分原始信号;独立高斯混合模型虽恢复部分显著性指标,但伴随明显假阳性;条件表格 GAN 则无法有效复原核心结果,假阴性率偏高。综合来看,genESOM 在小样本场景下的稳定性、可靠性显著优于传统生成方法,既能精准恢复关键生物学信号,又能严格管控误差扩张与虚假发现。
如下图所示,机器学习分析进一步验证了这一结论:增强后的数据恢复了随机森林的分类能力,筛选出的关键特征与原始研究高度一致。
写在最后
小样本是生物医学研究的长期困境:成本高、伦理严、样本难获取,导致统计效力不足。传统数据增强受限于可比性,通用生成式 AI 易在小样本下产生假阳性。 genESOM 的突破在于不「制造」数据,而是从有限数据中稳定恢复已有的生物学信号。
其核心设计将结构学习与数据生成分离,通过维度调节抑制误差,并引入阴性对照实时监测,形成了「只增强已有的,不创造没有的」克制框架。需要清醒的是,增强不能替代真实实验,该方法仍处探索阶段,适用性需更多验证。但这项研究传递了一个重要信号:在严格控制误差与假阳性的前提下,生成式 AI 有望成为小样本研究的有效辅助工具,帮助更可靠地挖掘有限数据中的真实结论。








