Command Palette
Search for a command to run...
用于高效语音识别的快速Conformer与线性可扩展注意力机制
用于高效语音识别的快速Conformer与线性可扩展注意力机制
摘要
基于Conformer的模型已成为语音处理任务中主流的端到端架构。为提升Conformer架构在训练与推理过程中的效率,我们对其进行了精心重构,提出了一种新颖的下采样策略。所提出的模型名为Fast Conformer(FC),其推理速度相比原始Conformer提升2.8倍,可在不改变核心架构的前提下轻松扩展至数十亿参数规模,并在自动语音识别(ASR)基准测试中达到当前最优的准确率。为实现长达11小时的长语音转录,我们在模型训练完成后,将全局注意力机制替换为受限上下文注意力机制,同时通过引入全局标记(global token)并进行微调,进一步提升了模型精度。当与Transformer解码器结合使用时,Fast Conformer在语音翻译(Speech Translation)和口语语言理解(Spoken Language Understanding)任务中,不仅在准确率上优于原始Conformer,同时在推理速度方面也表现出显著优势。
一句话总结
NVIDIA 和 UCLA 的研究人员提出了 Fast Conformer,一种重新设计的 Conformer 架构,采用新颖的下采样方案,实现 2.8 倍更快的训练与推理速度,可扩展至十亿参数规模,并在语音识别、语音翻译和口语理解任务中达到最先进性能,通过有限上下文注意力机制和全局 token 支持长达 11 小时的长语音处理。
主要贡献
- 本文通过重新设计下采样方案,解决了 Conformer 模型计算成本高、可扩展性有限的问题,通过三个深度可分离卷积层实现 8 倍下采样,降低序列长度并使全局注意力计算减少 2.9 倍,从而在不改变核心架构的前提下实现 2.8 倍更快的推理速度。
- 为支持长达 11 小时的长语音,作者在训练后将全局注意力替换为有限上下文注意力,并引入全局 token 用于微调,在保持序列长度线性可扩展性的同时提升准确率。
- Fast Conformer 在自动语音识别基准测试中达到最先进水平,并在语音翻译和口语理解任务中同时优于原始 Conformer 模型的速度与准确率,相关模型与训练方案已通过 NVIDIA NeMo 开源发布。
引言
作者针对大规模应用中高效语音识别的挑战展开研究,传统 Conformer 模型因自注意力机制具有二次复杂度,导致计算成本高昂,限制了其在实时或资源受限环境中的部署,尽管其准确率表现优异。为克服这一问题,作者提出 FAST Conformer 架构,用线性可扩展的注意力机制替代标准注意力,显著降低内存占用与推理时间,同时保持识别准确率。其核心贡献在于一种新颖的注意力设计,在多种语音数据集上维持模型性能的同时,实现硬件资源受限环境下的可扩展部署。
数据集
- 数据集包含来自三个主要来源的音频与文本数据:多语言 LibriSpeech(MLS)、Mozilla Common Voice(MCV)和 Wall Street Journal(WSJ)。
- 作者首先在 LibriSpeech 上单独训练基线模型与 Fast Conformer 模型,使用 SentencePiece unigram 分词器,CTC 模型采用 128 个词元,RNNT 模型采用 1024 个词元。
- 训练采用 AdamW 优化器与 Noam 学习率调度器,基线模型的峰值学习率分别为 0.0025(RNNT)和 0.001(CTC),线性预热 15,000 步。Fast Conformer 模型使用余弦学习率调度器,峰值学习率分别为 0.005(RNNT)和 0.001(CTC)。
- 基线 Conformer-RNNT 与 -CTC 模型训练 80,000 步,CTC 模型训练 380,000 步。所有模型均在 32 个 GPU 上训练,全局批量大小为 2048。
- 最终模型权重通过取最后五个检查点的平均值获得,以提升稳定性和性能。
- 模型效率使用 DeepSpeed 分析器评估,估算单个 30 秒音频片段的乘加操作(MACs)数量,结果汇总于表 4。
- Fast Conformer 模型在准确率上略高于标准 Conformer 模型,计算效率提升 3 倍,同时在速度上优于 EfficientConformer 与 SqueezeFormer。
- 表 3 报告了在 A100 GPU 上单批次可转录的最大音频时长(单位:分钟),揭示了其实时推理能力。
方法
作者采用重新设计的 Conformer 架构,称为 Fast Conformer(FC),在保持语音处理任务竞争力准确率的同时,显著提升推理速度与可扩展性。其核心在于一种新颖的下采样方案,将整体下采样率从 4 倍提升至 8 倍,从而减少编码器输出的序列长度。这一改进通过一系列对初始子采样模块的修改实现。原始 Conformer 采用 4 倍下采样模块,将帧率从 10 ms 提升至 40 ms。相比之下,Fast Conformer 引入三个深度可分离卷积子采样层,实现 8 倍下采样,将帧率提升至 80 ms。这一变化使后续注意力层的计算与内存负担降低 4 倍,因为其处理的序列长度缩短为原来的 1/4。子采样模块进一步通过将标准卷积层替换为深度可分离卷积,将通道数从 512 降至 256,核大小从 31 缩小至 9。这些修改共同实现了相比原始 Conformer 编码器推理速度提升 2.8 倍。下采样过程的整体框架如图所示,对比了不同模型的采样率。
为解决标准自注意力在长语音转录中的可扩展性限制,作者借鉴 LongFormer 的思想,实现了一种有限上下文注意力机制。该方法将全局注意力层替换为局部注意力与单个全局上下文 token 的组合。在此设计中,每个 token 仅关注固定大小的邻近 token 窗口,将计算复杂度从二次方降低至与序列长度呈线性关系。引入一个全局 token,通过独立的线性投影,使其能够同时关注所有其他 token 并被所有其他 token 关注,从而捕捉长程依赖。这种混合注意力机制使模型能够处理更长的音频序列,单个 A100 GPU 上的最大处理时长从 15 分钟扩展至 675 分钟。完整上下文、有限上下文以及带全局 token 的有限上下文注意力模式如图所示。
实验
- Fast Conformer 在 LibriSpeech 和大规模 25k 小时英语 ASR 数据集上进行评估,相比 Conformer 实现 2.9 倍更低的计算量,同时获得具有竞争力的 WER 结果;在 LibriSpeech test-other 上,其多数基准测试表现超越 Conformer。
- 在 25k 小时 ASR 数据集上,Fast Conformer-Large 在多个测试集(包括 MLS、MCV 和 WSJ-93)上均优于 Conformer,RNNT 与 CTC 解码器均表现出色。
- 在语音翻译(英译德)任务中,Fast Conformer-RNNT 在 MUST-C V2 上取得 27.89 的 BLEU 分数,推理速度比 Conformer 最快提升 1.84 倍,尽管 RNNT 存在单调对齐限制。
- 在口语理解任务(SLURP 数据集)中,Fast Conformer 模型在意图准确率与 SLURP-F1 上接近 Conformer 水平,推理速度提升 10%,优于在 60k 小时语音上预训练的 HuBERT 基线模型。
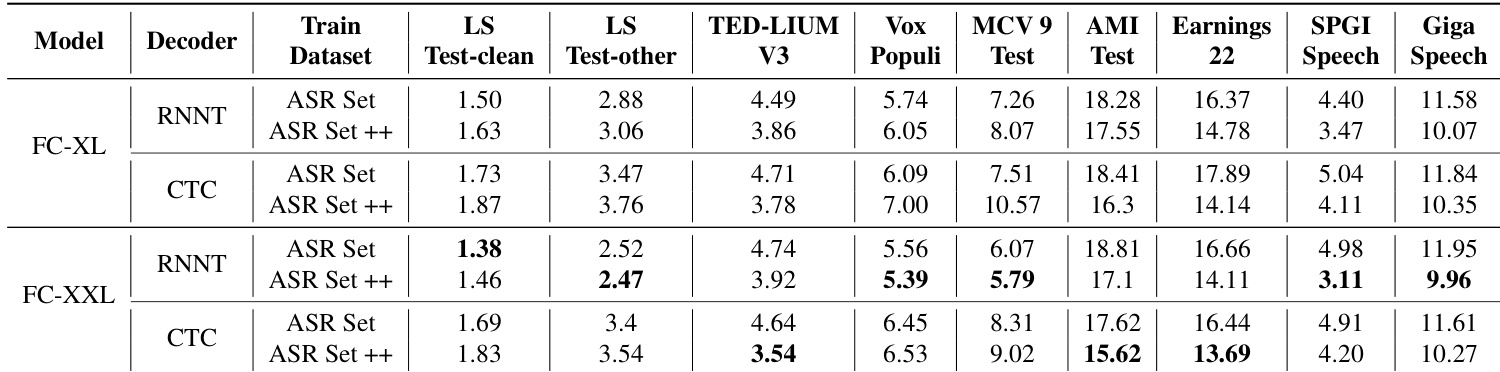
- 扩展实验表明,Fast Conformer-XL 与 Fast Conformer-XXL 模型在 25k 小时数据上训练,并进一步通过 40k 小时数据(ASR Set++)增强,达到 HF-Leaderboard 上的最先进性能,FC-XXL 在不同信噪比(SNR)水平下表现出更强的抗噪鲁棒性。
- 在 65k 小时数据(25k + 40k)上训练的 Fast Conformer-XXL 模型实现更优的准确率与鲁棒性,证明了模型规模与数据规模的双重有效扩展。
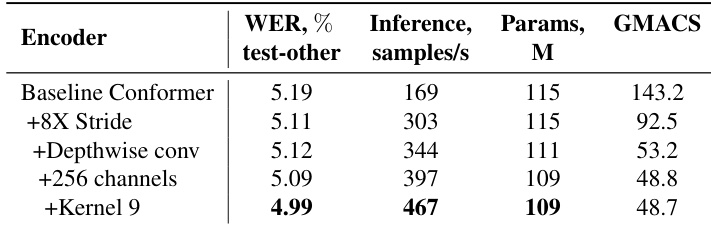
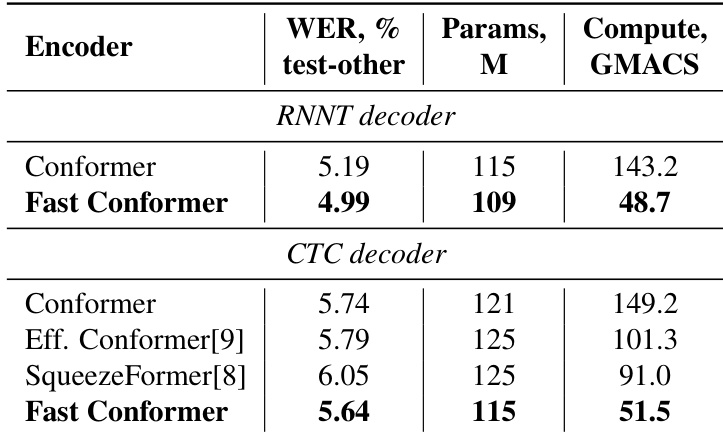
作者基于子采样方案与计算效率对比了不同 Conformer 变体。结果表明,Fast Conformer 在 K=9 时相比 Conformer 与 Squeezeformer 的 K=31 实现显著的计算量降低,同时采用深度可分离卷积结构。

作者在 LibriSpeech test-other 集上使用 Fast Conformer 实现了比 Conformer 更低的 WER,同时显著减少计算量。结果表明,Fast Conformer 在 RNNT 与 CTC 解码器上分别减少 66% 的编码器计算量与 5% 的参数量,同时保持具有竞争力的准确率。
作者在 SLURP 数据集上将 Fast Conformer 与 ESPNet-SLU 和 SpeechBrain-SLU 进行口语理解任务对比。结果表明,Fast Conformer 在意图准确率与 SLURP-F1 上均更高,且推理速度比 Conformer 快 10%,尽管其预训练编码器规模更小。

作者在多个 ASR 基准测试中评估 Fast Conformer 模型 FC-XL 与 FC-XXL,结果显示 FC-XXL 在大多数数据集上 WER 低于 FC-XL,尤其在 LS Test-other 与 MCV 9 Test 上表现更优。在 ASR Set++ 增强数据上训练后,FC-XXL 在多个基准上进一步降低 WER,展现出更高的准确率与抗噪鲁棒性。
作者评估了架构修改对 Conformer 编码器的影响,结果显示,将核大小从 31 改为 9 后,LibriSpeech test-other 的 WER 从 5.19% 降至 4.99%,推理速度从 169 提升至 467 样本/秒。相比基线 Conformer,该改进在参数更少、计算需求更低的前提下实现性能提升。