Command Palette
Search for a command to run...
KV-Edit:无需训练的图像编辑以实现精确的背景保留
KV-Edit:无需训练的图像编辑以实现精确的背景保留
Tianrui Zhu Shiyi Zhang Jiawei Shao Yansong Tang
摘要
背景一致性仍是图像编辑任务中的一项重大挑战。尽管已有大量研究进展,现有方法在保持与原始图像的相似性与生成符合目标语义内容之间仍面临权衡。为此,我们提出KV-Edit,一种无需训练的方法,利用扩散模型中的键值缓存(KV cache)机制在DiT(Diffusion Transformers)架构中实现背景一致性。该方法通过保留背景区域的token而不重新生成,避免了复杂的机制设计与高昂的训练成本,从而在用户指定区域内生成与背景自然融合的新内容。此外,我们进一步分析了编辑过程中KV缓存的内存消耗,并提出一种无需反演(inversion-free)的方法,将空间复杂度优化至O(1)。该方法可兼容任意基于DiT的生成模型,无需额外训练。实验结果表明,KV-Edit在背景一致性和图像质量方面显著优于现有方法,甚至超越部分基于训练的方法。项目主页详见:https://xilluill.github.io/projectpages/KV-Edit
一句话总结
清华大学与中国电信的作者提出KV-Edit,一种无需训练的一致性图像编辑方法,通过在基于DiT的模型中保留背景的键值对,实现无需复杂机制或重新训练的无缝内容融合,以O(1)内存复杂度达到卓越的背景保真度和效率。
主要贡献
- 图像编辑中的背景一致性具有挑战性,因为保留原始内容与匹配新提示之间存在权衡,现有无需训练的方法往往无法在不引入复杂机制或大量调参的情况下解决此问题。
- KV-Edit提出一种无需训练的方法,利用DiT架构中的键值缓存机制,在反演和去噪过程中保留背景标记,通过仅重建被掩码的前景区域并无缝整合新内容,确保完美的背景一致性。
- 该方法在基准数据集上达到最先进性能,无论在背景保真度还是图像质量方面均优于无需训练和需训练的方法;其无需反演的变体将内存复杂度降至O(1),适用于实际部署。
引言
作者利用Transformer架构中的键值(KV)缓存机制,实现无需训练的图像编辑并精确保留背景。在文本到图像生成中,尤其是基于DiT的流模型,编辑过程中保持背景一致性始终是一个难题。以往的无需训练方法依赖注意力修改或反演采样器,往往无法完全保留原始背景内容;而需训练的方法则带来高昂的计算成本。KV-Edit的关键创新在于:在反演过程中缓存背景标记的键值对,并在去噪阶段复用这些缓存,从而确保背景保持不变,仅根据新提示重新生成前景。该方法无需额外训练、极少超参数调优,且兼容任意DiT架构模型。作者进一步通过引入无需反演的策略优化内存使用,将空间复杂度降至O(1),并提出掩码引导的反演与重初始化技术,以提升在移除类任务中与编辑指令的对齐效果。实验表明,KV-Edit在背景保真度和整体图像质量方面均优于无需训练和需训练的方法。
方法
作者采用基于扩散的框架,解决图像编辑中背景区域保留的挑战。核心方法称为KV-Edit,运行于确定性扩散模型框架(如修正流)中,该框架将从噪声到真实图像的变换建模为由常微分方程(ODE)控制的连续路径。该ODE描述了一个可逆过程,模型学习预测引导去噪轨迹的速度向量。该框架基于DiT(扩散Transformer)架构,其高度依赖注意力机制,从而为解耦前景与背景处理提供了新途径。
整体框架始于反演过程,输入图像在一系列时间步中逐步转化为噪声。在此过程中,作者引入关键创新:注意力解耦机制。该机制通过仅使用前景标记作为查询,而键和值则来自完整图像(包含前景与背景),从而修改标准自注意力计算。该设计使模型能够独立生成前景内容,确保背景信息在生成阶段保持隔离且不变。该过程在框架图中展示,输入图像根据提供的掩码被划分为前景与背景两部分。

反演完成后,该方法采用KV缓存,存储每个时间步和模型层中背景区域对应的键值对。这些缓存随后在去噪阶段用于重建背景。去噪过程从新的前景输入开始,通常为噪声向量或原始前景的修改版本。模型通过将再生的前景与保留的背景结合,生成最终图像,利用缓存的键值对确保一致性。该方法有效规避了传统反演-去噪范式中导致背景不一致的三大因素:误差累积、新条件的影响以及新前景内容的干扰。
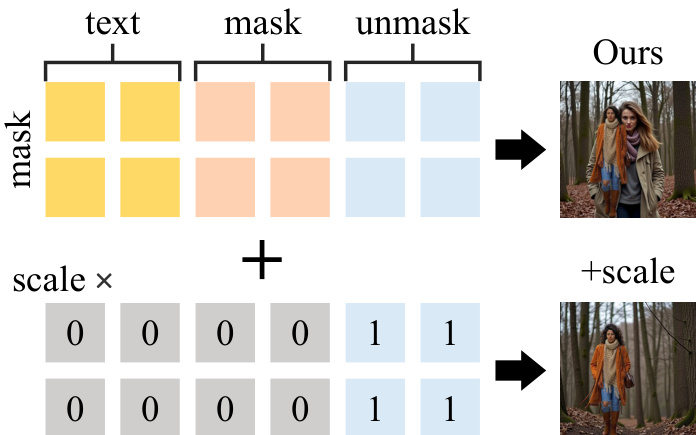
为进一步提升方法能力,作者提出两种可选技术。第一种是重初始化步骤,将最终反演时间步的噪声替换为融合噪声向量,以破坏原始对象的残余信息,特别适用于对象移除任务。第二种技术是在反演过程中使用注意力掩码,防止前景内容被纳入键值对,从而减少原始内容信息的传播。这些增强措施旨在提升方法在多样化编辑场景中的表现。
实验
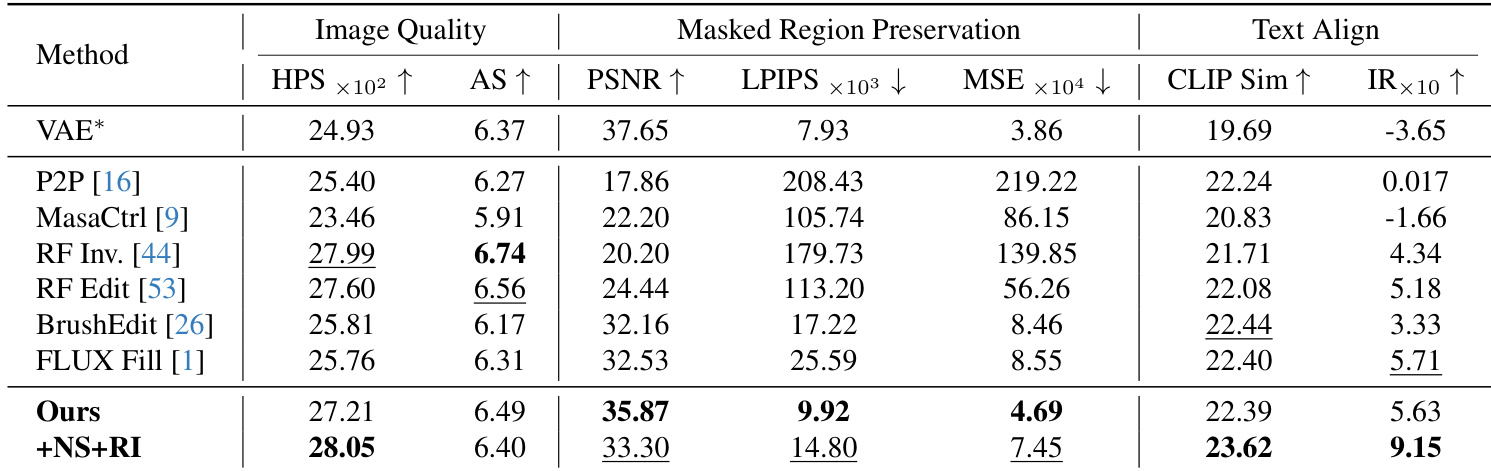
- 在PIE-Bench上与六种基线方法对比,包括无需训练(P2P、MasaCtrl、RF-Edit、RF-Inversion)和需训练方法(BrushEdit、FLUX-Fill),使用620张图像中的九项任务。
- 在背景保留方面表现最佳(PSNR、LPIPS、MSE),PSNR值始终高于30,确保背景保真度一致。
- 在文本-图像对齐方面超越所有基线,获得最高CLIP分数和图像奖励,尤其在采用重初始化策略时表现突出。
- 在PIE-Bench上,本方法图像质量位列第三(HPSv2、审美得分),同时在背景保留和整体满意度方面优于需训练方法。
- 20+参与者的用户研究显示,本方法在图像质量、背景保留、文本对齐和整体满意度方面显著优于基线,甚至超越FLUX-Fill。
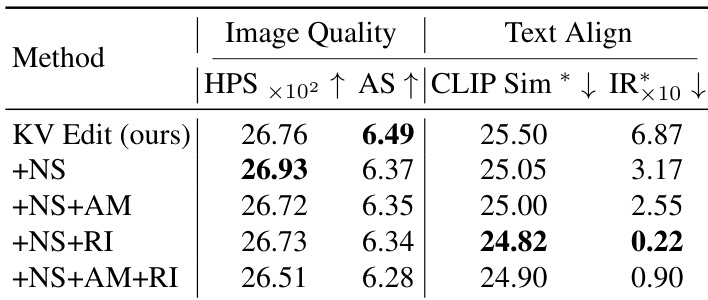
- 消融实验确认重初始化和无跳过步骤可提升文本对齐,尽管在大掩码情况下轻微降低图像质量;注意力掩码在特定场景中提升性能。
- 在对象移除、颜色更改和修复任务中表现出灵活性,重初始化技术使修复场景下的编辑也有效。
- 提出注意力尺度机制以缓解大掩码带来的生成偏差,提升背景编辑的内容连贯性。
- 基于反演的KV-Edit支持单次反演后多次编辑,相比无需反演的替代方案具有更高的工作流效率和更低的伪影风险。
结果表明,所提出的KV-Edit方法在所有变体中取得最佳图像质量和文本对齐得分。加入重初始化(RI)显著提升文本对齐,+NS+RI变体达到最高CLIP Sim和最低IR得分,表明强提示遵循性;而+NS+AM+RI组合进一步提升性能,尽管图像质量略有下降。
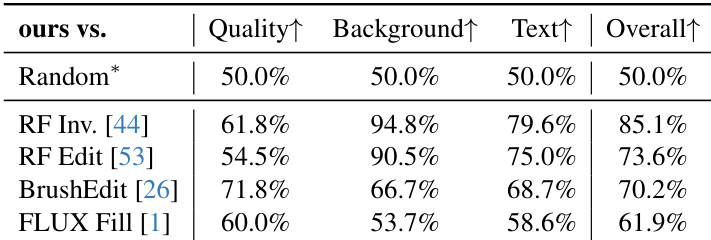
作者在用户研究中将本方法与四种基线方法进行对比,评估图像质量、背景保留、文本对齐和整体满意度。结果表明,本方法在所有指标上均显著优于所有基线,各类别中均取得最高胜率。
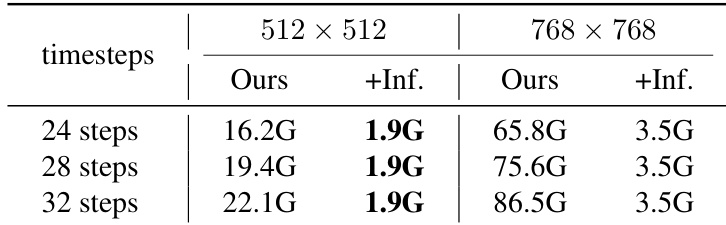
结果表明,基于反演的方法内存使用随时间步数和图像分辨率增加而上升,而无需反演的方法保持恒定内存占用。无需反演方法显著降低内存消耗,在24步、512×512下仅需1.9G,768×768下为3.5G,而基于反演的方法在相同条件下分别需16.2G和65.8G。
作者在PIE-Bench上进行综合评估,将本方法与六种基线方法在图像质量、背景保留和文本对齐方面进行对比。结果表明,本方法在掩码区域保留和文本对齐方面表现最佳,优于无需训练和需训练方法,同时保持高图像质量。