Command Palette
Search for a command to run...
PaddleOCR-VL:通过 0.9B 超紧凑视觉 - 语言模型增强多语言文档解析能力
PaddleOCR-VL:通过 0.9B 超紧凑视觉 - 语言模型增强多语言文档解析能力
摘要
在本报告中,我们提出 PaddleOCR-VL,这是一款专为文档解析任务设计的、具备 SOTA 性能且资源高效的模型。其核心组件为 PaddleOCR-VL-0.9B,这是一个紧凑而强大的 vision-language model (VLM)。该模型将 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型深度融合,从而实现高精度的元素识别。这一创新架构不仅高效支持 109 种语言,更在识别文本、表格、公式及图表等复杂元素方面表现卓越,同时保持极低的资源消耗。通过在广泛使用的公共 benchmark 及内部 benchmark 上的全面评估,PaddleOCR-VL 在页面级文档解析和元素级识别任务中均取得了 SOTA 性能。其表现显著优于现有解决方案,在与顶尖 VLM 的对比中展现出强劲竞争力,并具备快速的推理速度。这些优势使其成为现实应用场景中部署的理想选择。
一句话总结
本报告提出了 PaddleOCR-VL,这是一款 0.9B 超紧凑视觉语言模型,它集成了 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型,旨在以最小的资源消耗,在公共和内部基准测试中,针对 109 种语言的多语言文档解析和复杂元素识别实现最先进的性能。
核心贡献
- 本工作介绍了 PaddleOCR-VL,这是一款资源高效的视觉语言模型,其核心拥有紧凑的 0.9B 参数,结合了 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型。该模型高效支持 109 种语言,并能在保持最小资源消耗的同时,准确识别文本、表格、公式和图表等复杂文档元素。
- 在广泛使用的公共和内部基准测试上的全面评估表明,该模型在页面级文档解析和元素级识别方面均实现了最先进的性能。结果显示,其表现显著优于现有解决方案,并与具有快速推理速度的顶级视觉语言模型具有强大的竞争力。
- 我们推出了 PaddleOCR 3.0,这是一个旨在增强现代 AI 应用文本识别准确性和文档解析能力的主要版本。此更新包括高精度的 PP-OCRv5 文本识别流水线,它利用先进的模型架构和训练策略来交付最先进的结果。
引言
文档解析对于将结构化信息输入大型语言模型和检索系统至关重要,然而现代文档呈现出复杂的布局,这对现有技术构成了挑战。先前的流水线方法存在集成复杂性和累积误差传播的问题,而端到端多模态模型往往会产生幻觉或产生巨大的计算开销。作者通过 PaddleOCR-VL 解决了这些限制,这是一种专为高性能文档分析设计的资源高效视觉语言模型。他们利用紧凑的 0.9B 架构,结合动态高分辨率视觉编码器与轻量级语言模型,在不牺牲推理速度的情况下,在 109 种语言上实现了最先进的准确性。
数据集
-
数据集构成与来源 作者使用四个主要来源构建训练集以确保广度。这些来源包括成熟的开源仓库、用于纠正分布不平衡的合成数据、可访问网络的网页文档(如学术论文和报纸),以及专有的内部收集数据。
-
每个子集的关键细节
- 文本: 2000 万图像 - 文本对,涵盖 109 种语言,具有行、块和页面级别的注释。
- 表格: 超过 500 万图像 - 表格对,使用 OTSL 格式,源自挖掘和合成工具,每小时生成 10,000 个样本。
- 公式: 包含中文和英文的打印和手写表达式,源自 UniMER-1M 和 MathWriting,并通过 LaTeX 渲染引擎验证。
- 图表: 超过 80 万图像 - 图表对,结合了 22 万个清洗后的公共样本与基于角色的合成渲染。
-
模型使用与训练划分 团队在隔离的元素图像和完整文档页面上进行训练,以提高解析性能。挑战性示例被集成以增强鲁棒性并防止在干净的标准数据集上过拟合。
-
处理与元数据构建
- 注释: 两阶段流水线使用 PP-StructureV3 生成伪标签,并使用大型多模态模型进行细化。
- 质量控制: 幻觉过滤移除不正确内容,而基于规则的检查验证 n-gram 一致性和 HTML 有效性。
- 裁剪: 公式区域在识别前根据布局分析边界框进行裁剪。
- 图表逻辑: 注释将数据检索视为涉及轴刻度标签和数据点的查询任务。
方法
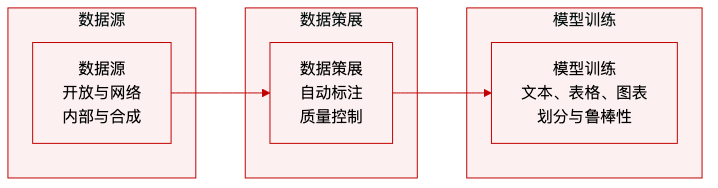
提出的 PaddleOCR-VL 框架将复杂的文档解析任务分解为两阶段流水线,以平衡准确性和效率。第一阶段专注于布局分析以定位语义区域并确定阅读顺序,而第二阶段执行多样化内容元素的细粒度识别。整体架构如下所示。
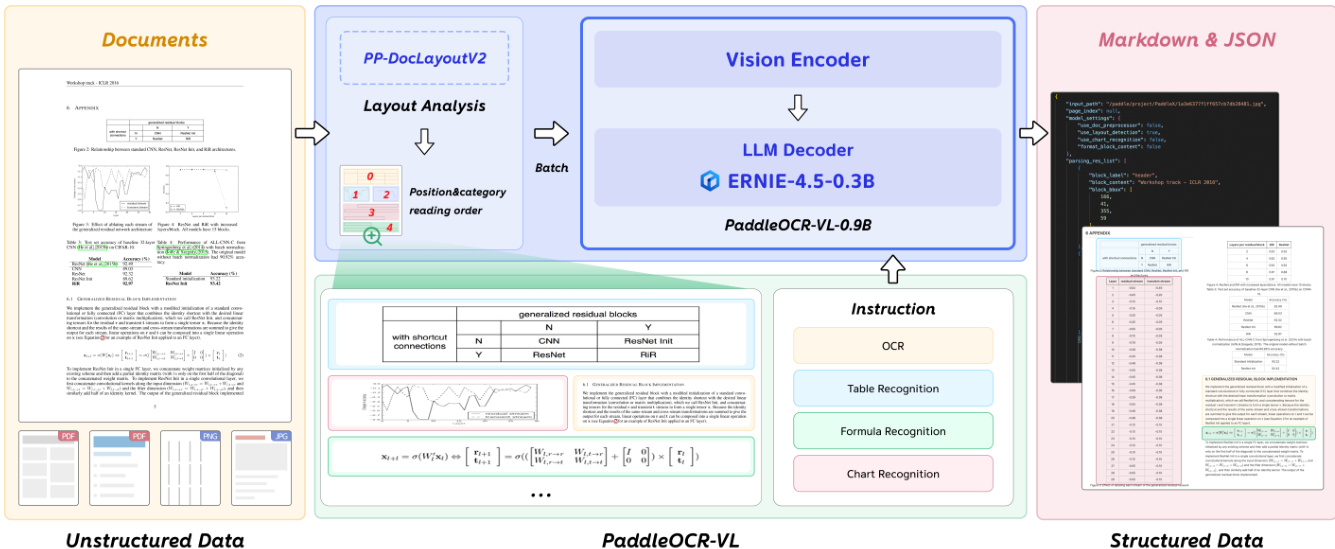
布局分析 为了解决端到端视觉语言模型在布局任务中固有的延迟和不稳定问题,作者采用了一个名为 PP-DocLayoutV2 的专用轻量级模型。该模块负责元素检测、分类和阅读顺序预测。如下图所示,该架构由一个基于 RT-DETR 的检测模型用于定位,以及随后的指针网络用于排序。检测模型输出边界框和类别标签,然后使用绝对 2D 位置编码和类别标签嵌入进行嵌入。几何偏差机制被纳入编码器注意力中以建模成对几何关系。成对关系头将元素表示投影到查询和键向量中以计算双线性相似度,从而生成表示相对顺序的 N×N 矩阵。最后,确定性胜者累积解码算法恢复拓扑一致的阅读顺序。
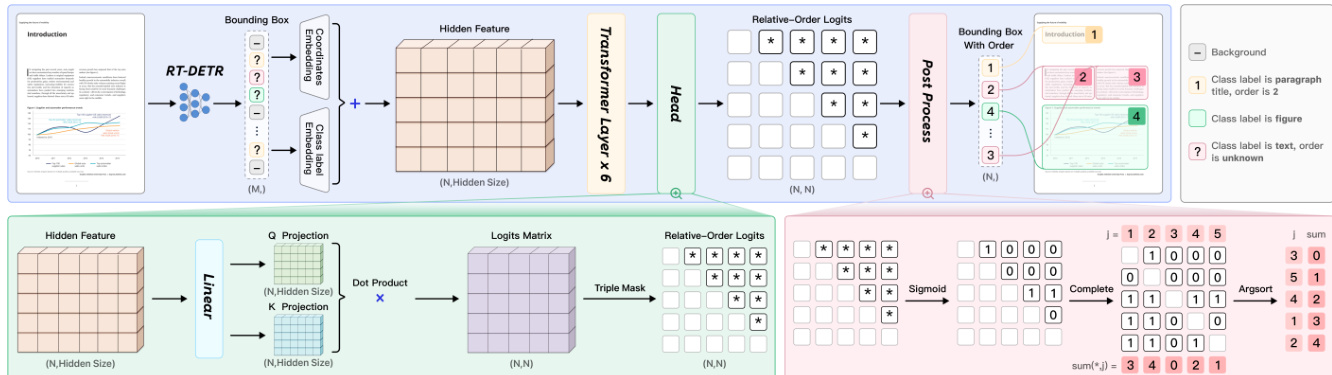
元素级识别 对于识别阶段,作者提出了 PaddleOCR-VL-0.9B,它将动态分辨率视觉编码器与紧凑的语言模型集成。该架构遵循受 LLaVA 启发的风格,通过投影器将预训练视觉编码器连接到大型语言模型。有关详细的模块设计,请参阅下面的架构图。
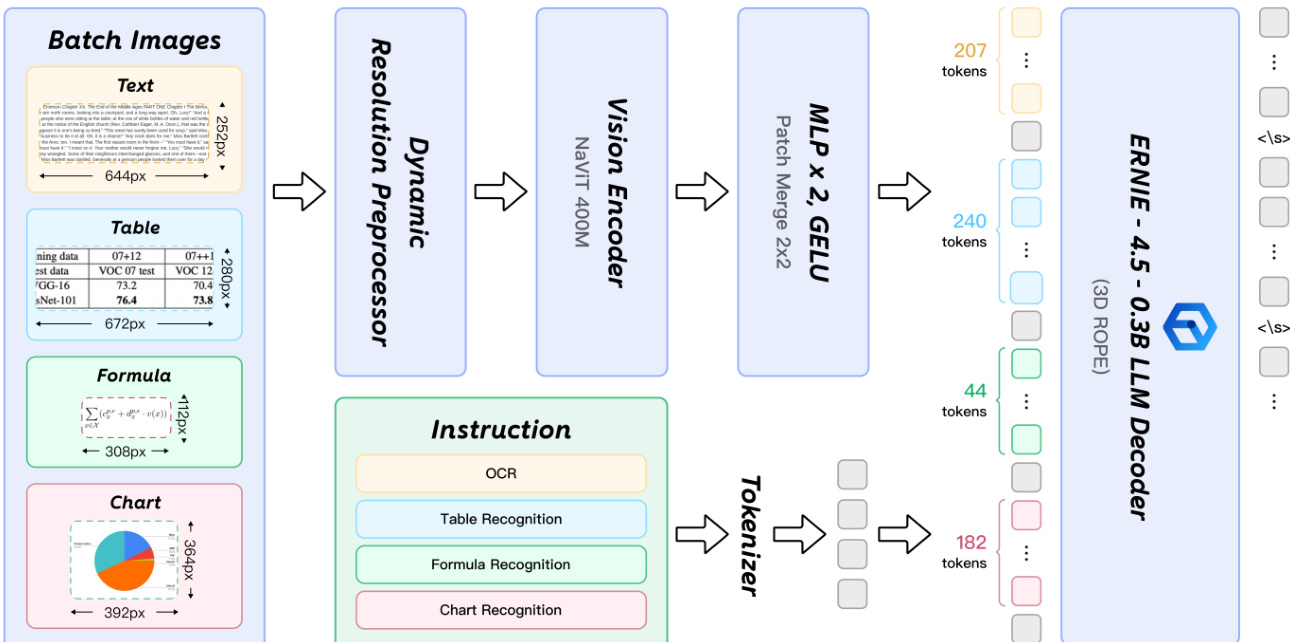
视觉编码器利用从 Keye-VL 初始化的 NaViT 风格设计,支持原生分辨率输入而无失真。这使模型能够处理任意分辨率的图像。一个随机初始化的 2 层 MLP,带有 GELU 激活和 2 的合并大小,将视觉特征桥接到语言模型的嵌入空间。对于语言解码器,选择 ERNIE-4.5-0.3B 模型以平衡参数数量与推理效率。实现还通过结合 3D-RoPE 增强了位置表示。该模型经过训练,可处理针对 OCR、表格识别、公式识别和图表识别的特定指令。
训练方案与数据构建 训练过程依赖于通过自动注释和合成构建的多样化且高质量的数据集。数据流水线包括开源数据集、合成数据集、可访问网络的数据集和内部数据集。如下图所示,系统采用 EVAL 引擎进行困难案例挖掘,以识别特定场景中的性能瓶颈。
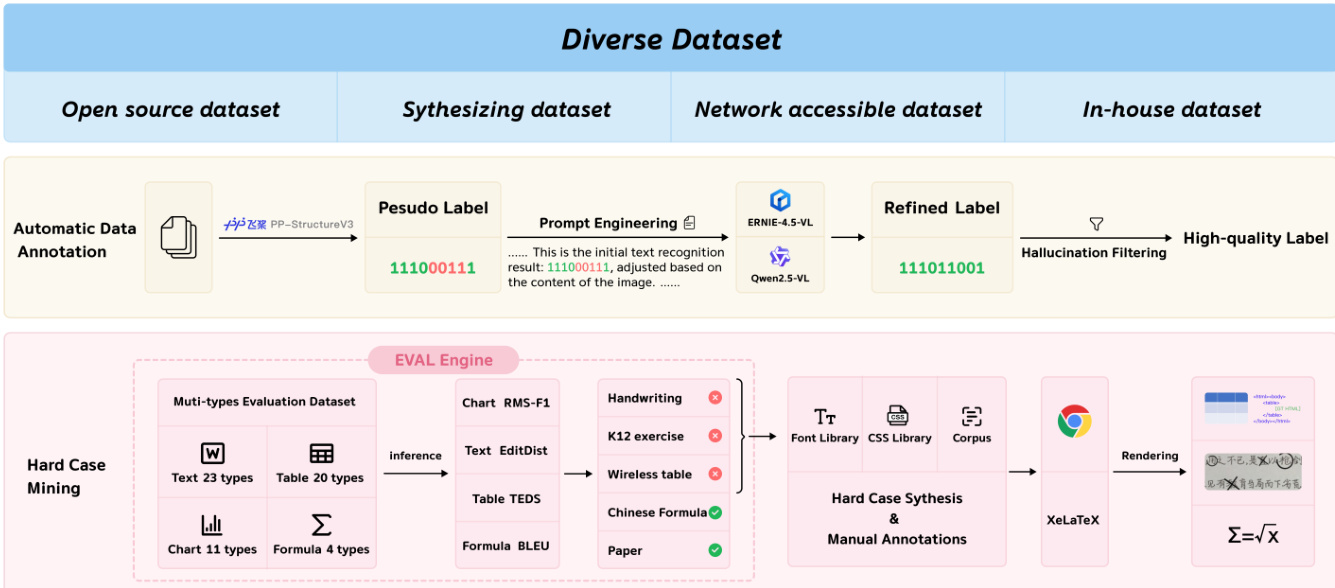
为了确保鲁棒性,作者生成了 2000 万高质量图像 - 文本对。这涉及使用 PP-StructureV3 进行自动数据注释以创建伪标签,然后由视觉语言模型进行细化。此外,使用语料库、字体库和 CSS 库合成高质量 OCR 数据,随后进行随机增强。这种多样化数据涵盖 109 种语言和多种书写系统,包括打印、手写和扫描文本。

识别模型的训练策略分为两个阶段。第一阶段专注于使用 2900 万图像 - 文本对进行预训练对齐,以将视觉信息与文本表示关联起来。第二阶段涉及在 270 万样本的精选数据集上进行指令微调,以使模型适应特定的下游任务,如表格结构识别和公式转换。
实验
评估框架使用多个公共和内部基准测试,针对领先的通用视觉语言模型和专用文档解析工具评估了 PaddleOCR-VL,旨在测量页面级文档结构和元素级识别能力。实验验证了该模型在解析文本、表格、公式和图表方面的最先进的准确性,同时通过优化的异步执行工作流展示了卓越的推理效率。定性发现进一步突出了该系统在管理复杂布局、多样化语言和具有挑战性的手写场景方面与现有解决方案相比的鲁棒性。
该表格比较了 PaddleOCR-VL 与几种领先模型的表格识别能力。结果显示,所提出的模型在整体准确性、结构分析和错误指标方面均实现了最佳性能。PaddleOCR-VL 在整体表格结构相似性方面获得了最高分。该模型在所有比较方法中展示了最低的错误率。结构解析能力超过了最接近的竞争对手。
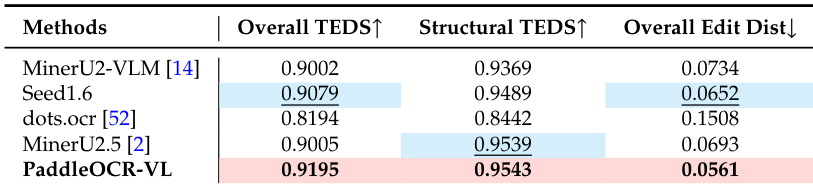
该实验通过记录不同深度和方向的压力计高度差来研究液体压力。结果显示,在固定深度下,压力在所有方向上是一致的,但随着深度增加而增加。在同一深度,液体压力在所有方向上是相等的。随着液体深度增加,压力增加。压力计高度差反映了压力的大小。
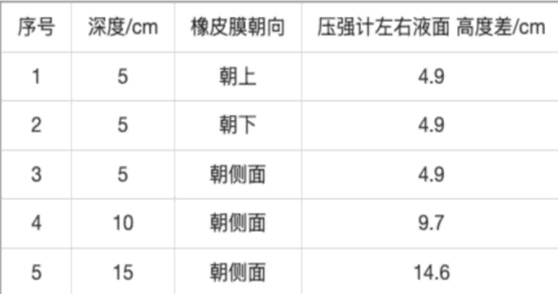
作者在 OmniDocBench v1.0 基准测试上评估了 PaddleOCR-VL 与各种流水线工具和视觉语言模型。结果表明,PaddleOCR-VL 实现了最先进的性能,平均整体编辑距离最低,在文本、公式和表格识别任务中优于竞争对手。与其他方法相比,PaddleOCR-VL 实现了最低的平均整体编辑距离。该模型在中文文本和表格识别指标方面展示了卓越的准确性。PaddleOCR-VL 保持了最佳的阅读顺序保留,特别是对于中文文档。
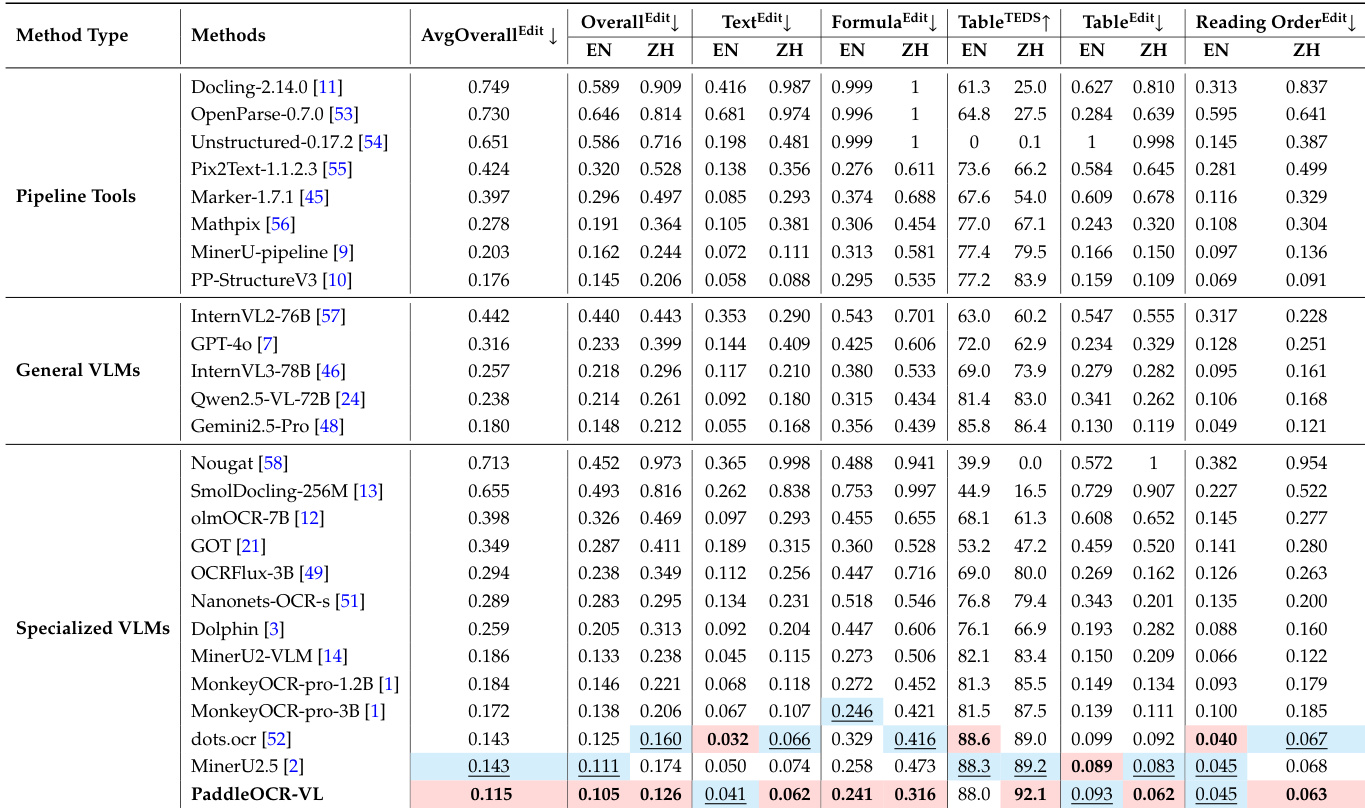
该表格比较了 PaddleOCR-VL 与各种通用和专用模型在十种不同语言上的编辑距离性能。结果表明,PaddleOCR-VL 始终实现了最低的错误率,在多语言文本识别任务中展示了卓越的准确性。PaddleOCR-VL 在所有评估语言中实现了最低的编辑距离。该模型优于通用的视觉语言模型,如 Qwen2.5-VL-72B。与专用文档解析工具相比,观察到显著的准确性提升。

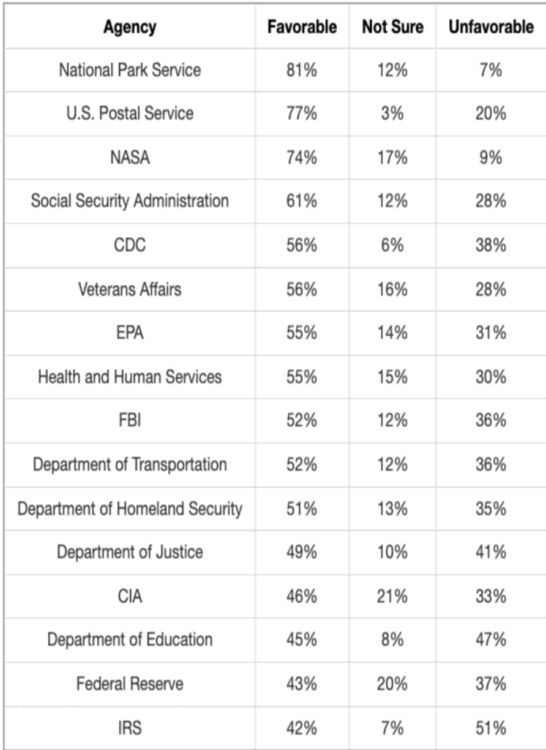
该表格展示了关于各种美国政府机构的公众舆论数据,分为有利、不确定和不利的回应。国家公园管理局获得最积极的反响,而国税局面临最高级别的不认可。国家公园管理局在有利评级中领先。国税局的不利百分比最高。NASA 和邮政服务也显示出强烈的有利情绪。
所描述的实验包括对 PaddleOCR-VL 模型的评估,以及关于流体力学和公众情绪的分立研究。与领先的视觉语言模型和专用工具相比,PaddleOCR-VL 在表格识别、文档解析和多语言文本准确性方面展示了最先进的性能。额外的实验验证了液体压力随深度增加,同时也分析了各种美国政府机构的喜好评级。