Command Palette
Search for a command to run...
OpenDataArena:用于评估后训练数据集价值的公平开放平台
OpenDataArena:用于评估后训练数据集价值的公平开放平台
摘要
大型语言模型(LLMs)的快速演进依赖于后训练数据集的质量与多样性。然而,一个关键矛盾依然存在:尽管模型本身受到严格的基准测试,支撑其训练的数据却仍处于“黑箱”状态——其构成不透明、来源不明,且缺乏系统性评估。这种信息不透明性严重阻碍了研究的可复现性,并模糊了数据特性与模型行为之间的因果关系。为弥合这一鸿沟,我们提出 OpenDataArena(ODA),一个全面且开放的平台,旨在对后训练数据的内在价值进行系统性评估。ODA 构建了一个由四大核心支柱组成的综合性生态系统:(i)统一的训练-评估流水线,确保在不同模型(如 Llama、Qwen)与多个领域之间实现公平、开放的对比;(ii)多维度评分框架,从数十个不同维度对数据质量进行精细刻画;(iii)交互式数据溯源探索工具,用于可视化数据集的演化谱系,并深入剖析各组件来源;(iv)完全开源的工具包,涵盖训练、评估与评分全流程,以推动数据研究的开放协作。在 ODA 上开展的广泛实验覆盖了跨多个领域的120余个训练数据集,在22个基准测试上完成了超过600次训练运行,处理数据点逾4000万条。实验揭示了若干具有重要意义的发现:我们的分析揭示了数据复杂性与任务性能之间的内在权衡关系;通过谱系追踪识别出主流基准测试中的冗余问题;并构建了数据集之间的基因谱系图谱,揭示其演化与关联路径。我们已将所有实验结果、工具与配置全部开源,以实现高质量数据评估的普惠化。ODA 的愿景并不仅限于扩展排行榜,更致力于推动从试错式数据构建向以数据为中心的系统性科学范式转变,为数据混合规律的严谨研究以及基础模型的战略性数据构成提供坚实基础,开启数据驱动人工智能研究的新篇章。
一句话总结
上海人工智能实验室与OpenDataLab等机构的研究人员推出OpenDataArena(ODA),这是一个综合性平台,通过统一的评估流程、多维评分框架、交互式谱系探索器及开源工具包,对后训练数据价值进行基准测试,使数据评估从试错式整理转变为以数据为中心的AI科学化实践。
核心贡献
- 大语言模型的后训练数据仍是一个"黑箱",其构成不透明且来源不确定,阻碍了可复现性,并模糊了数据特征如何影响模型行为。这一关键缺口导致尽管模型基准测试严谨,却无法系统评估数据质量。
- OpenDataArena引入了一个整体平台,包含统一的训练-评估流程、涵盖数十个质量维度的多维评分框架以及交互式数据谱系探索器,可透明地基准测试数据价值并追溯数据集谱系。其开源工具包支持跨模型和领域的公平比较,同时规范了以数据为中心的评估标准。
- 基于120个数据集在22个基准上的实验,经600余次训练运行和4000万数据点验证,揭示了数据复杂性与任务性能间的固有取舍,并通过谱系分析发现流行基准中的冗余。这些结果实证表明:精心整理的高信息密度数据集可优于大规模非结构化集合,并指出响应质量是比提示复杂度更强的下游性能预测指标。
引言
作者针对大语言模型开发中的关键缺口展开研究:后训练数据质量直接影响模型性能,却未被测量且不透明。当前实践虽严格基准测试模型,却将训练数据集视为构成与来源不明的黑箱,阻碍了可复现性并模糊了特定数据特征如何影响模型行为。为此,他们推出OpenDataArena——一个包含统一训练-评估流程、数十个质量维度的多维评分、交互式数据谱系追踪及完全开源工具的整体开放平台。该系统经120个数据集和22个基准验证,支持公平的数据比较,揭示数据复杂性取舍与基准冗余等非平凡洞见,将数据整理从试错转变为以数据为中心的AI科学化实践。
数据集
作者构建了OpenDataArena(ODA)——一个包含120个公开可用的监督微调(SFT)数据集的仓库,总计超4000万样本。这些数据源自Hugging Face等社区资源,按影响力(最低下载量/点赞数)、时效性(2023年后)、领域相关性及计算可行性进行筛选。所有数据均经过安全审查和格式标准化。
关键子集包括:
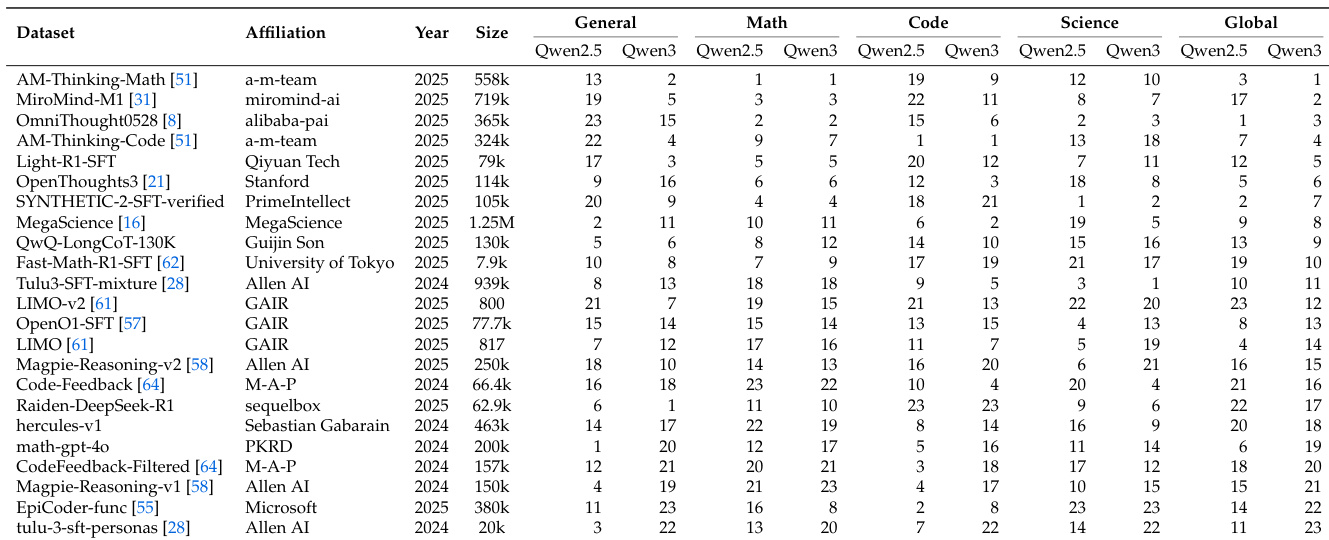
- 训练数据:涵盖通用对话(20.8%)、数学(34.3%)、代码(30.6%)和科学(14.4%)。单个数据集规模从数千到10万+样本不等(如0penThoughts3、LIM0、Tulu3-SFT)。
- 基准测试集:22+个评估套件覆盖:
- 通用领域:DROP、MMLU-PRO
- 数学领域:GSM8K、OlympiadBenchMath
- 代码领域:HumanEval+、LiveCodeBench
- 推理领域:ARC_c、GPQA diamond
本文仅使用这些数据集进行评估而非训练,以全面评估模型跨领域能力。不涉及混合比例或训练划分。处理流程包括:
- 标准化指令-响应格式
- 执行"数据谱系"分析以映射数据集派生关系与冗余
- 应用多维质量评分(如安全性、连贯性)评估指令(Q)及完整问答对(QA)
- 通过交互式谱系图和对比评分界面可视化关系。
方法
作者将OpenDataArena(ODA)作为统一的以数据为中心评估基础设施,系统化基准测试大语言模型后训练数据集的内在价值。平台架构围绕四个核心组件设计,共同实现公平、可复现且多维度的评估。参考框架图示,这些组件——数据价值排行榜、多维数据评分器、数据分析平台及开源评估工具包——通过中央评估引擎交互,形成连贯的数据集评估系统。
在操作层面,ODA实施四阶段评估流程。始于数据输入层:从多元来源收集数据集,标准化为统一格式并按领域分类。随后进入数据评估层(计算核心):在固定基础模型(如Qwen或Llama)上,使用标准化超参数和训练协议进行微调,再通过通用对话、科学推理及代码生成等下游基准测试评估模型。此标准化训练-评估循环将数据集质量隔离为唯一变量,实现公平比较。
如下图所示,数据评估层还集成多维评分系统,沿数十个维度分别评估指令(Q)和指令-响应对(Q&A)。该框架采用三类方法:基于模型的评估(如预测指令难度)、LLM-as-Judge(如GPT-4进行连贯性评估)及启发式规则(如token长度或响应清晰度)。这些指标共同生成数据集的诊断"指纹",捕获复杂性、正确性及语言质量等维度。
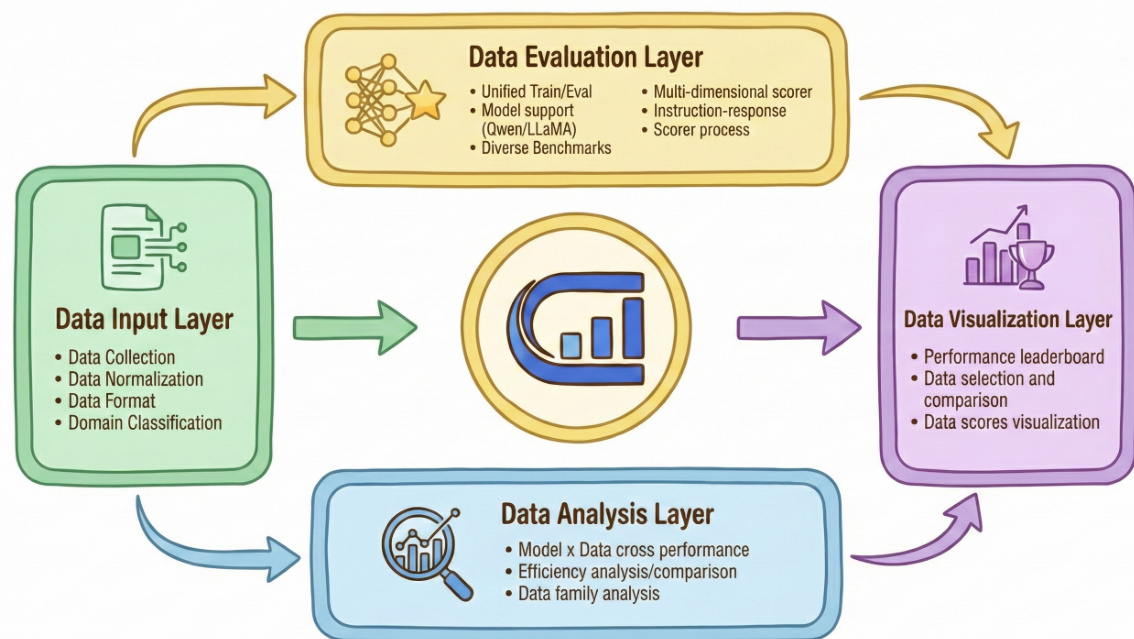
数据分析层整合评估输出,执行跨模型/跨域性能比较、效率分析及数据家族关系映射,帮助研究者识别高价值数据集并理解领域/模型特异性偏好。最终,数据可视化层将洞见转化为交互式排行榜和对比图表,直观展示数据集排名与质量特征。整个流程由开源工具包支持,提供全部配置、脚本及原始结果,确保完全可复现与社区可扩展性。
为增强透明度,ODA整合自动化数据谱系框架,将数据集依赖关系建模为有向图 G=(V,E)(节点代表数据集,边编码派生关系)。该框架通过多智能体协作流程,从Hugging Face、GitHub及学术论文文档递归追溯上游来源。借助语义推理、置信度评分及人工验证,系统构建基于事实的谱系图,揭示数据集生态中的冗余、来源及组成演变。
实验
- 600余次训练运行的标准化流程验证确认数据是唯一性能变量,使用一致的Llama3.1-8B/Qwen模型和OpenCompass评估。
- 70个种子数据集的谱系分析揭示941条边的全局图;AM-Thinking-v1-Distilled在Llama3.1-8B上实现数学性能+58.5提升,而基准污染通过SynthLabsAI/Big-Math-RL-Verified等数据集传播。
- 时序分析显示数学数据集质量从35升至56(Qwen2.5,2023-2025Q3),代码领域性能波动较大,通用领域趋于饱和。
- 数学数据集排名在Qwen模型间高度一致(Spearman 0.902),通用领域排名则反转(-0.323相关性)。
- 响应长度与数学性能强相关(0.81),但代码领域呈逆向趋势(如响应长度-0.29)。
作者使用Spearman秩相关系数测量Qwen2.5与Qwen3模型跨领域数据集排名的一致性。结果显示:数学数据集高度一致(0.902),通用数据集呈负相关(-0.323),表明模型进阶时通用指令遵循出现饱和效应。科学与代码领域呈弱正相关,说明其专业知识价值仍在但跨代稳定性较低。
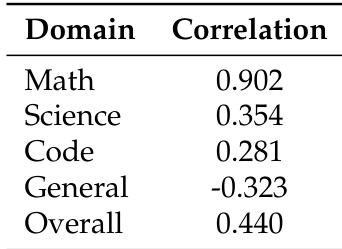
作者使用标准化微调与评估协议,在Qwen2.5和Qwen3模型上比较数据集性能排名。结果显示:数学领域排名高度一致(Spearman相关系数0.902),通用领域排名呈负相关(-0.323),表明强模型在指令遵循任务中出现饱和。代码与科学领域呈弱正相关,说明基础模型能力进阶时数据集价值动态演变。