Command Palette
Search for a command to run...
MMGR:多模态生成推理
MMGR:多模态生成推理
摘要
视频基础模型能够生成视觉上逼真且时间上连贯的内容,但其作为世界模拟器的可靠性,取决于模型是否准确捕捉了物理、逻辑与空间约束。现有评估指标(如弗雷歇视频距离,FVD)侧重于感知质量,却忽视了推理层面的失败,包括因果关系违背、物理规律违反以及全局一致性缺失等问题。为此,我们提出MMGR(多模态生成推理评估与基准测试框架),这是一个基于五种推理能力的系统性评估框架:物理推理、逻辑推理、三维空间推理、二维空间推理和时间推理。MMGR在三个核心领域对生成式推理能力进行评估:抽象推理(ARC-AGI、数独)、具身导航(真实世界三维导航与定位)以及物理常识理解(体育场景与组合式交互)。MMGR采用细粒度评估指标,要求视频与图像生成在整体上均达到正确性,强调跨模态、跨时间的全局一致性。我们对当前领先的视频模型(Veo-3、Sora-2、Wan-2.2)和图像模型(Nano-banana、Nano-banana Pro、GPT-4o-image、Qwen-image)进行了全面基准测试,结果揭示了各模型在不同任务中存在显著性能差距。具体而言,模型在物理常识任务中表现中等,但在抽象推理任务中表现不佳(在ARC-AGI任务中准确率低于10%),且在具身场景下的长时程空间规划任务中面临严重挑战。我们的分析指出当前模型存在若干关键局限:过度依赖感知信息、全局状态一致性较弱,以及训练目标更倾向于奖励视觉合理性而非因果正确性。MMGR提供了一个统一的诊断性基准,为构建具备推理能力的生成式世界模型指明了方向,推动生成模型从“视觉逼真”迈向“逻辑可信”的新阶段。
一句话总结
威斯康星大学麦迪逊分校、加州大学洛杉矶分校、密歇根州立大学等机构的研究人员推出MMGR基准测试,评估模型在抽象推理、具身导航和物理常识三大领域中的五种推理能力(物理、逻辑、3D/2D空间、时间)。与以往侧重感知保真度的指标不同,MMGR揭示当前Veo-3和Sora-2等视频模型虽在物理常识方面表现中等,但在抽象推理(ARC-AGI得分低于10%)和具身导航任务上灾难性失败。
核心贡献
- 当前视频生成模型虽具有高感知质量,但缺乏对逻辑和物理推理能力的评估——传统指标(如FVD和Inception Score)优先考虑外观保真度,而非语义一致性和长时序连贯性。
- MMGR基准测试提出生成式推理框架,在三大领域设计新型任务:2D迷宫测试空间/逻辑/时间推理,数独测试约束满足能力,全景视图导航测试具身决策能力,并将ARC-AGI等严格测试适配为世界建模探针。
- 对Veo-3等最先进模型的评估表明:在3D现实世界导航和同步定位生成等任务中表现成功,使用Matterport3D和Habitat数据集验证了语义接地、轨迹规划和连贯心智映射能力。
引言
视频生成模型已从GAN演进至扩散模型和Transformer架构,在Sora和Veo等系统中实现高视觉保真度。然而,现有评估指标优先关注感知质量和文本对齐,未能检验模型是否内化物理规律或执行时序一致的推理。先前基准测试也聚焦判别式理解而非生成式推理能力。作者通过引入MMGR基准测试填补这一空白,该测试通过2D迷宫、数独、全景导航和基于物理的视频合成等任务,全面评估抽象推理、具身导航和物理常识三大领域的五种核心推理能力。此框架严格检验模型生成逻辑严谨、物理合理的视频内容的能力,超越表面真实感。
数据集
作者构建包含1,853个评估样本的基准测试,覆盖三大领域十项任务,支持细粒度能力分析。核心组件包括:
-
抽象推理(1,323个样本)
- 迷宫:240个程序化生成的迷宫(3×3至13×13网格),采用DFS和Wilson算法生成。按生成器分为简单(40)、中等(40)、困难(40)三组,每组四种起点-终点配置。强制最小路径距离,每个迷宫有唯一解。
- 数独:300道谜题(每难度/网格尺寸50道),含4×4和9×9网格,覆盖简单(大量提示)、中等、困难(少量提示)级别,确保唯一解。
- ARC-AGI:456项任务(v1版381项,v2版75项),按形状一致性(匹配/不匹配)和难度分类,经人工筛选确保变换规则无歧义。
- 视觉数学:327道问题,整合自GSM8K、MATH500、AIME 2024/2025和Omni-MATH,涵盖小学至奥赛级数学。
-
具身导航(480个样本)
- 四项任务(每项120个样本):3D现实世界导航(Matterport3D/HM3D)、最后一英里导航(360°全景)、俯视图导航和SLAG(跨视图对齐)。
- 按环境复杂度(单层/多层)、视图保真度(质量3-5级)、轨迹距离(短/长)和目标描述(视觉标记或语言)分层24种配置。
-
物理常识(50个样本)
- 物理概念:25个样本取自VideoPhy/VideoPhy v2,覆盖固体-固体(143条描述)、固体-流体(146条)和流体-流体(55条)交互,涉及静力学/动力学。
- 运动:25个来自芭蕾、滑雪、跳水和游泳的多样化示例,测试动量、平衡和流体动力学。
- 按交互类型、场景背景(受控环境vs运动)和复杂度(简单/复杂/链式反应)分层平衡。
该数据集严格用于评估,具备严谨难度分层和人工验证。处理流程包括:
- 迷宫/数独:通过控制参数(网格尺寸、提示数)算法生成,并验证解的唯一性。
- 具身导航:场景取自Matterport3D、HM3D和Habitat;目标描述使用红色覆盖层或消歧义语言说明。
- 物理常识:从源语料库随机采样以确保类别/领域多样性。
无训练集划分或混合比例,因基准测试专注结构化测试。
方法
作者采用三分支流程——基准测试、生成与评估——系统化检验抽象、具身和物理领域的生成式推理能力。框架始于基准测试模块,该模块将任务组织为三大领域:抽象推理(如迷宫、数独、ARC-AGI)、具身导航(如3D现实世界导航、最后一英里导航)和物理常识(如运动、物理概念场景)。各领域参数化设计以实现粒度和难度控制,支持在不同结构和语义约束下细粒度分析模型能力。
参考框架图了解端到端工作流概览。生成模块接收输入图像和自然语言提示,调用视频生成模型(Veo-3、Sora-2、Wan-2.2)生成多帧轨迹或图像生成模型(Nano-Banana/Pro、GPT-4o-Image、Qwen-Image)输出单帧结果。例如在迷宫任务中,提供7x7网格及起点终点标记,模型需生成解谜2D动画,输出为从起点到终点的连续帧序列。
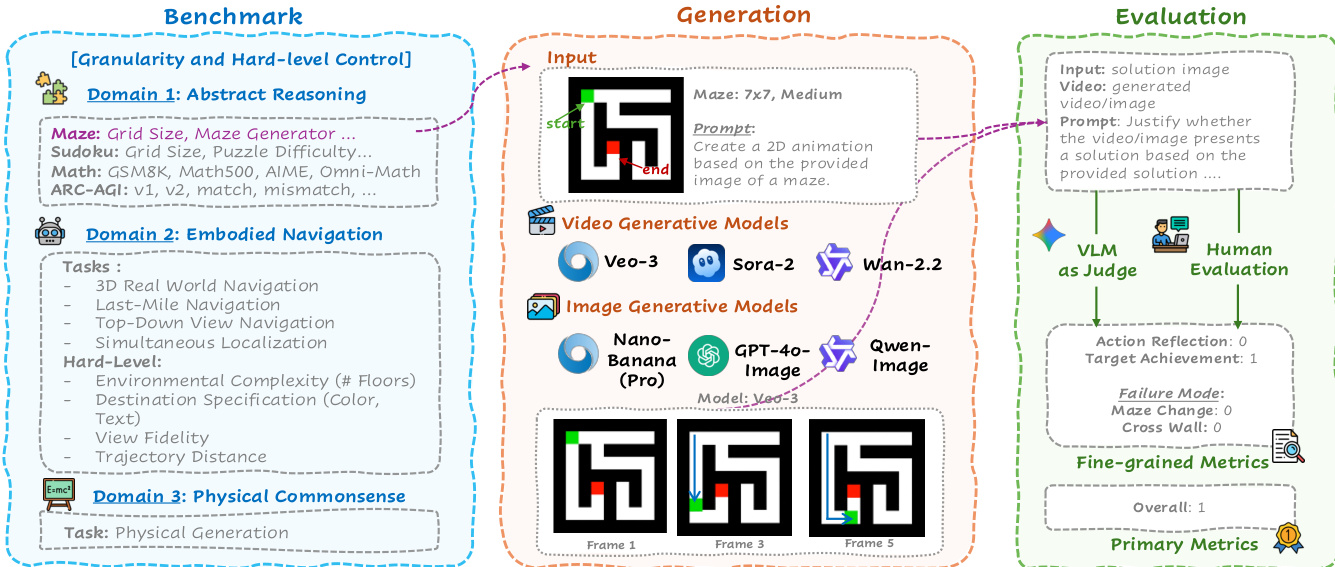
评估模块采用双路径评估:基于VLM的自动评分(Gemini-2.5-Pro)及针对精选子集的人工评估。VLM依据结构化标准(行动反思[0/1]、目标达成[0/1]、失败模式标记[如迷宫修改、穿墙])将生成视频/图像与解图像对比,聚合为细粒度指标和主指标(全局得分),后者反映整体成功度。该评估不仅检验感知保真度,更探查输出是否符合提示和输入隐含的逻辑、空间及物理约束,从而在物理、逻辑、3D空间、2D空间和时间推理五大核心支柱上进行领域敏感的优劣势诊断。
实验
- 在抽象推理、具身导航和物理常识三大领域评估MMGR基准测试,检验五种核心推理能力
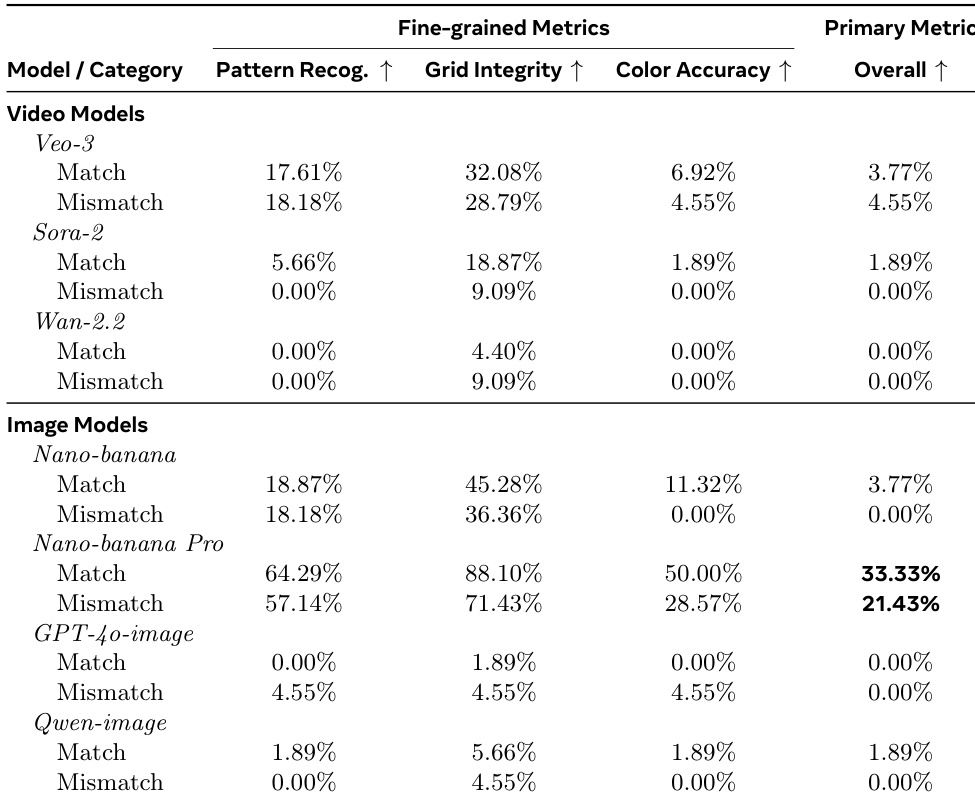
- ARC-AGI v1测试中,Nano-banana Pro准确率达30.54%,超越Sora-2(20.18%),揭示视频模型在保持静态演示时存在时序不一致性
- 数独任务中,图像模型显著优于视频模型:Nano-banana Pro在4x4简单题准确率达39.28%,Veo-3仅11.38%;人工评估显示Veo-3成功率为0%
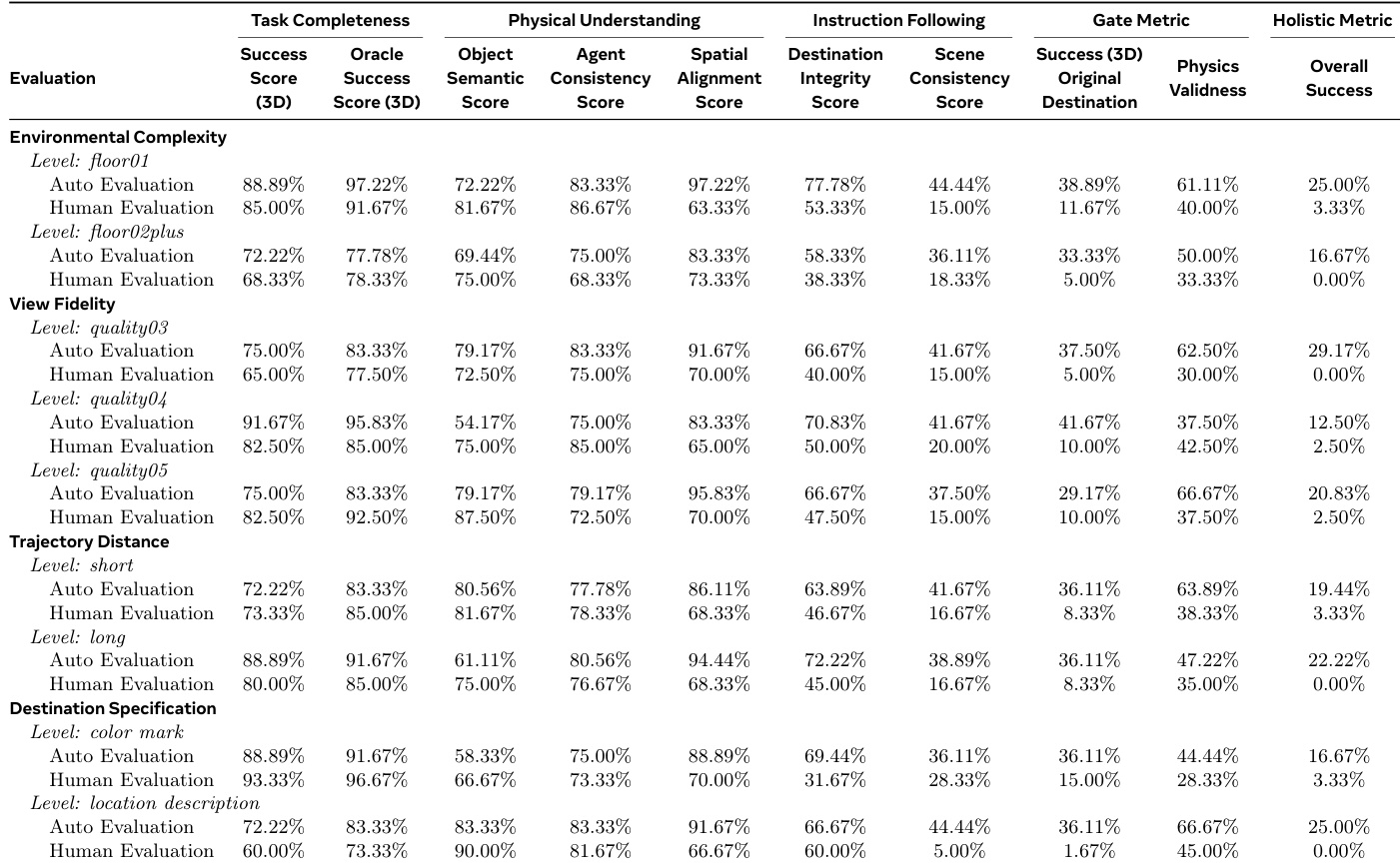
- 具身导航方面,Nano-banana在3D现实世界导航中全局准确率达79.2%;Veo-3在全景视图导航的自动评估成功率为73.33%,但人工评估骤降至25.00%
- 物理常识测试中,Sora-2全局成功率达70.00%,大幅优于Veo-3(51.02%)和Wan-2.2(24.00%),结果表明视觉逼真度不保证物理正确性
- 人工评估持续揭示自动化指标的关键缺陷,暴露普遍存在的"能力幻觉"现象——模型通过无效推理路径得出正确答案
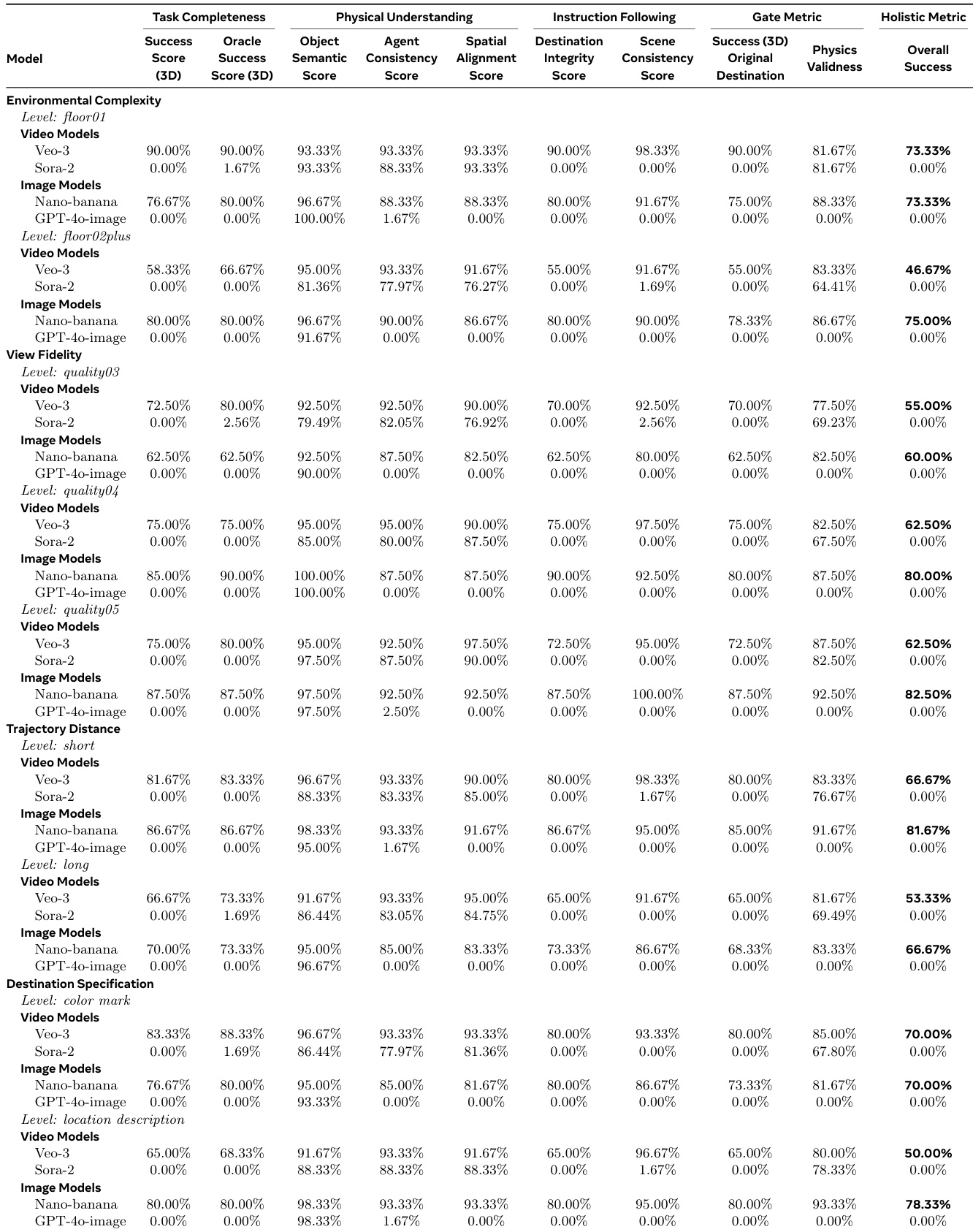
作者采用多指标框架评估具身导航任务,发现视频模型(如Veo-3)虽在物理理解和任务完成组件上得分高,但始终无法满足需同时满足所有条件的严格全局成功指标。图像模型(尤其是Nano-banana)在多数条件下全局准确率更高,尤其在复杂环境和文本目标描述下,表明其多模态接地和一致性更优。结果显示视频模型在视觉合理性与严格遵守物理/指令约束间存在明显权衡,自动化指标常高估实际性能。
作者使用ARC-AGI基准测试评估抽象视觉推理,在匹配和不匹配任务类型上对比视频与图像生成模型。结果表明图像模型(尤其是Nano-banana Pro)整体准确率显著领先:匹配任务33.33%,不匹配任务21.43%;而Veo-3和Sora-2等视频模型整体得分低于5%。此性能差距揭示当前视频模型难以维持抽象模式补全所需的结构和色彩一致性,即使其具备中等模式识别或网格完整性能力。
作者通过人工与自动化评估检验Veo-3在3D导航任务的表现,发现感知成功与实际成功存在显著差距。自动化指标报告中等全局得分(最高25.00%),但人工评估始终接近零分,暴露自动化系统忽略的频繁物理违规和场景不稳定。此差异表明当前视频模型在复杂或长时序条件下优先视觉合理性而非物理逻辑一致性。
作者采用多任务数学推理基准测试评估模型,揭示图像模型在整体成功率上持续领先。结果显示Veo-3等视频模型常获正确终解(结果成功率高)但中间推理错误(过程成功率低),表明其依赖模式匹配而非因果推导。图像模型(尤其是Nano-Banana Pro)在所有难度级别保持过程与结果近乎完美对齐,展现稳健的分步逻辑推理能力。
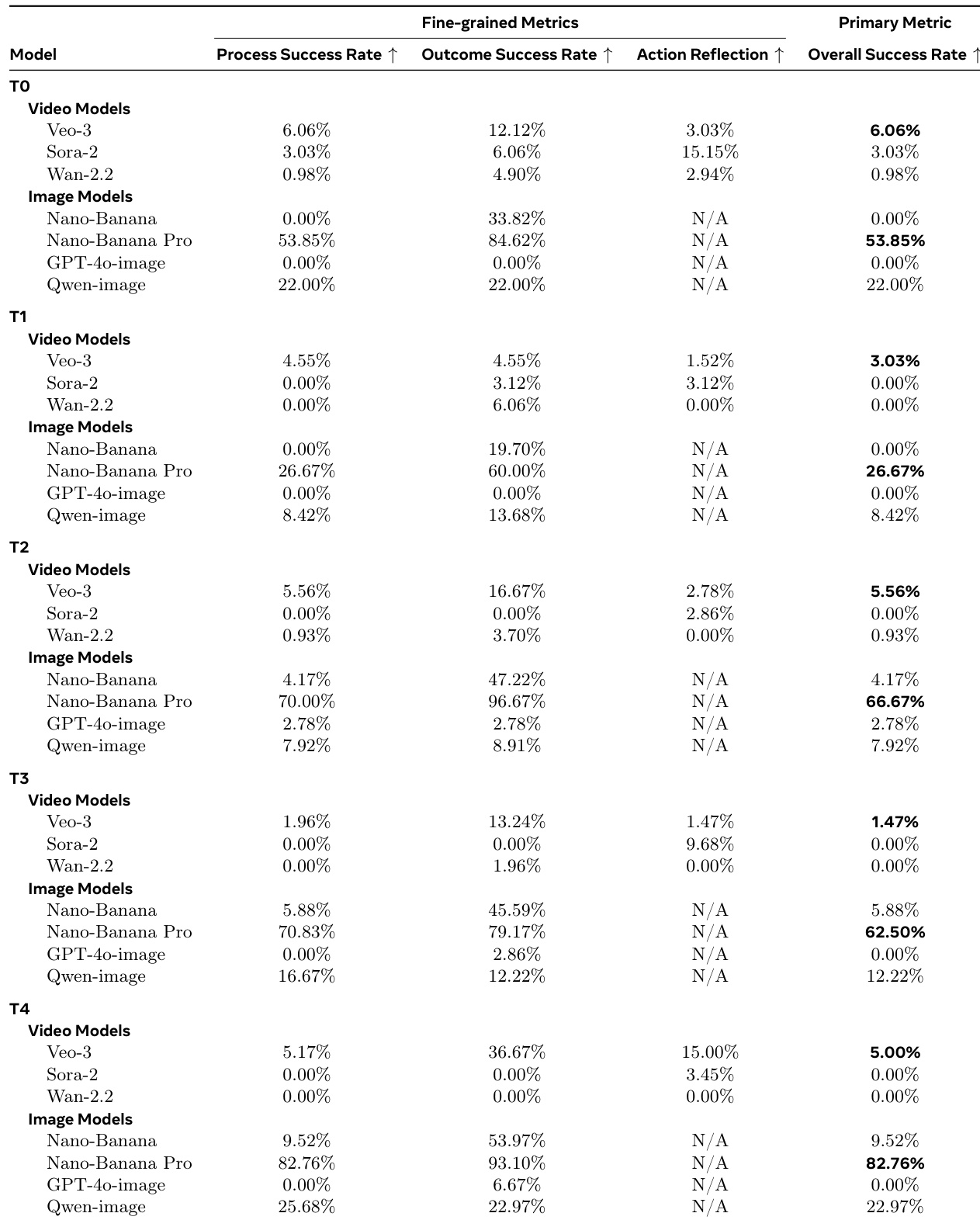
作者采用严格全局指标评估数独求解性能:零提示修改、零约束违反、100%完成准确率。结果表明Nano-banana Pro等图像模型在所有网格尺寸和难度级别持续优于视频模型;视频模型虽行动反思率高,但频繁提示修改和约束违反导致全局失败。人工评估进一步证实视频模型全局成功率接近零,揭示其分步视觉编辑与实际逻辑正确性的根本差距。