Command Palette
Search for a command to run...
面向心智地图感知的检索增强生成以提升长上下文理解
面向心智地图感知的检索增强生成以提升长上下文理解
Yuqing Li Jiangnan Li Zheng Lin Ziyan Zhou Junjie Wu Weiping Wang Jie Zhou Mo Yu
摘要
人类通过依赖文本内容的整体语义表征来理解长篇且复杂的文本。这种全局视角有助于组织已有知识、解释新信息,并整合分散在文档各处的证据,这一能力在心理学中被称为“心智图景意识”(Mindscape-Aware Capability)。当前的检索增强生成(Retrieval-Augmented Generation, RAG)系统缺乏此类全局指导,因此在处理长上下文任务时表现受限。本文提出一种全新的方法——心智图景感知检索增强生成(Mindscape-Aware RAG, MiA-RAG),这是首个为基于大语言模型(LLM)的RAG系统赋予显式全局上下文感知能力的方法。MiA-RAG通过分层摘要构建全局语义表征(即“心智图景”),并以此作为检索与生成过程的共同条件。该机制使检索模块能够生成更具语境丰富性的查询嵌入,同时使生成模块能够在连贯的全局语义背景下对检索到的证据进行推理。我们在多种涵盖长上下文与双语场景的基准测试中评估了MiA-RAG在基于证据的理解与全局意义建构方面的能力。实验结果表明,MiA-RAG在各项任务中均持续优于现有基线模型。进一步分析显示,该方法能够有效将局部细节与一致的全局表征对齐,从而实现更接近人类认知模式的长上下文检索与推理能力。
一句话摘要
中国科学院信息工程研究所、中国科学院大学、腾讯微信AI、香港科技大学的研究人员提出MiA-RAG,一种新颖的RAG框架,通过分层摘要引入显式的全局上下文感知能力,以指导检索与生成,使局部证据与连贯的全局心智空间对齐,从而实现更类人的长上下文推理,在多样化的长上下文与双语基准测试中超越基线模型。
主要贡献
- 当前的检索增强生成(RAG)系统缺乏全局上下文感知能力,仅依赖局部证据信号,在长上下文理解上表现不佳;而人类自然地利用整体性的“心智空间”来组织知识、解释信息并指导复杂文本中的推理。
- MiA-RAG首次提出一种计算框架,通过构建分层摘要作为外部心智空间,赋予基于大语言模型的RAG系统显式的全局上下文感知能力,该心智空间通过增强查询嵌入来指导检索,并通过上下文感知推理来引导生成,使局部细节与连贯的全局表征对齐。
- 在涵盖政府报告、叙事文本及多种任务形式的多样化长上下文与双语基准上进行评估,MiA-RAG持续优于基线模型;消融实验与分析证实,心智空间重塑了查询嵌入并引导注意力,实现了更类人的意义建构与整合推理。
引言
长上下文理解仍是大语言模型(LLMs)面临的关键挑战,尤其是在处理证据分散的长文档时。当前的检索增强生成(RAG)系统严重依赖局部证据级信号,缺乏维持全局语义上下文的机制——类似于人类的“心智空间”——该机制可指导选择性检索、丰富信息解释并实现连贯推理。这一局限导致理解碎片化、跨主题泛化能力差,且在复杂多步任务中表现欠佳。本文提出心智空间感知的RAG(MiA-RAG),首个通过分层摘要显式建模全局语义表征的框架,作为外部心智空间。该摘要用于同时调节检索与生成:通过丰富查询嵌入实现选择性、上下文感知的检索,并引导生成器在统一的全局上下文中解释检索到的证据。在中英文多样化的长上下文基准上评估,MiA-RAG持续优于基线模型,包括更大的原始模型,并显著提升了局部细节与全局意义之间的对齐。分析证实,心智空间将查询表示重塑为连贯的语义空间,并作为注意力的支架,验证了其在实现类人推理中的关键作用。
数据集
- 数据集记为 D~emb,通过自动扩展NarrativeQA构建,提供在块级与节点级的银标准查询-证据对齐,解决了现有长叙事数据集中细粒度监督不足的问题。
- 包含27,117个问题,平均每题对应2.3个银标准块与2.9个银标准节点,数据来源于NarrativeQA与CLIPPER生成的合成数据的结合。
- 块级证据通过多步流程识别:查询增强、多数投票集成检索与基于大语言模型的过滤(算法1),确保高质量、上下文相关的证据。
- 节点级证据通过从每篇文档构建知识图谱实现:使用GPT-4o提取关键实体,并生成简洁描述以形成节点;每个查询的相关节点则通过相同的算法流程识别。
- 该数据集用于训练MiA-Emb模型,该模型通过混合银标准块与无关块生成检索上下文 C^ret,模拟真实检索噪声与不同上下文长度。
- 用于MiA-Gen模型的最终监督微调数据集 Dgen 结合了NarrativeQA与CLIPPER数据,格式包含指令、上下文、检索证据与查询,支持在真实检索条件下训练。
- 对于CLIPPER,直接使用MiA-Emb模型的检索结果构建 C^ret,确保检索与生成训练的一致性。
- MiA-Gen模型通过在 D~gen 上使用自回归交叉熵损失进行优化,完整输入上下文(包括指令、源文本、检索证据与查询)作为输入以生成答案。
方法
研究人员采用分层框架构建一个全局语义支架,称为“心智空间”(Mindscape),作为文档级抽象,用于指导长文档理解任务中的检索与生成。该心智空间通过两阶段摘要过程构建。首先,每个文档块 ci 由大语言模型独立摘要,生成一组块级摘要 {si}。随后,这些摘要被拼接并经过第二阶段摘要处理,生成单一、连贯的全局表征 S,该表征概括了文档的整体叙事与核心主题。这种分层构建方式确保了全局上下文得以保留并可供下游任务使用。
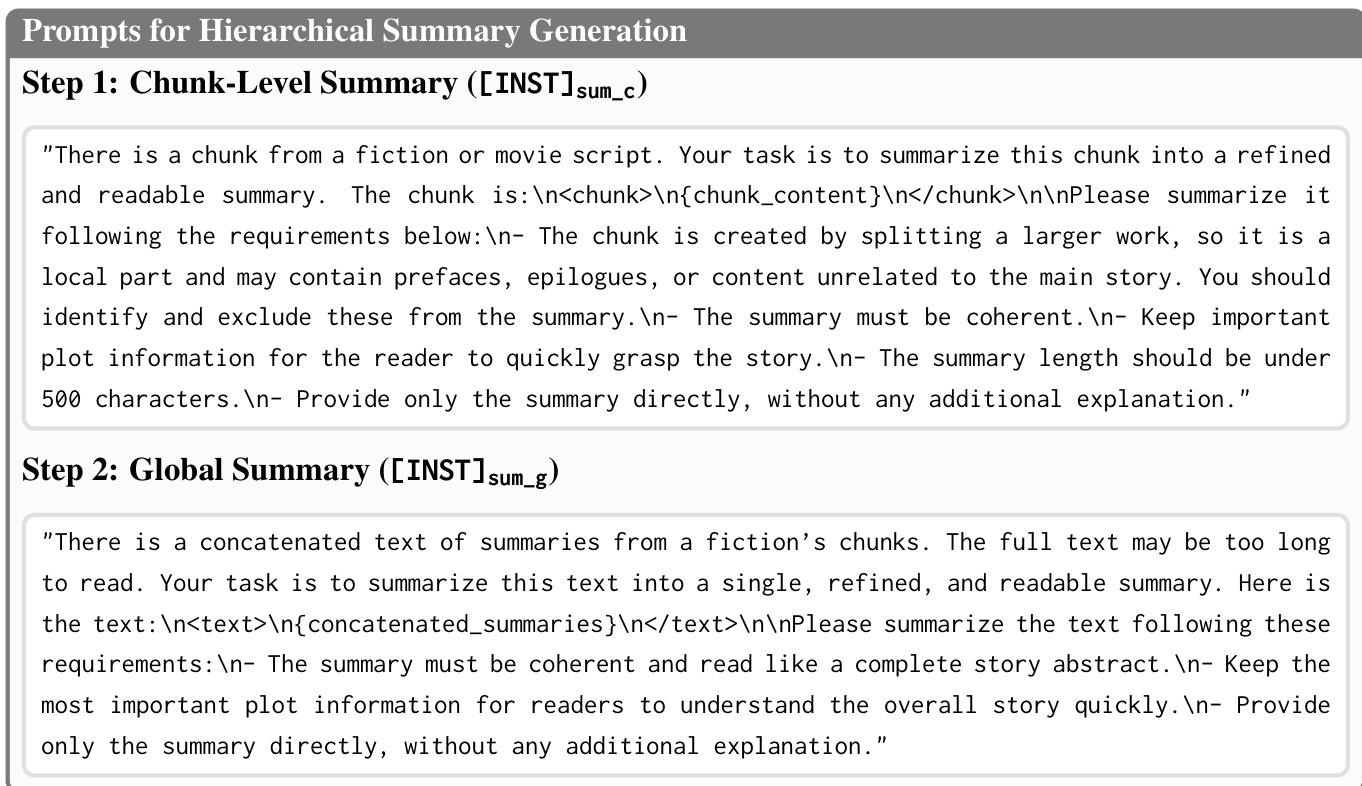
该框架命名为心智空间感知RAG(MiA-RAG),将心智空间整合进检索增强生成流程。核心创新在于心智空间感知检索器(MiA-Emb),其训练目标是基于全局上下文对查询表示进行条件化。该模型在预训练嵌入模型基础上进行微调,输入序列被显式设计为同时包含查询与心智空间。输入格式定义为 Q=[[INST]emb;qi;dq;S;dn;dc],其中 qi 为查询,S 为心智空间摘要,dq、dn 与 dc 为特殊标记,分别表示查询结束并激活节点与块检索模式。该设计使模型能够同时感知局部查询意图与全局文档上下文。

为平衡原始查询与全局引导的影响,模型采用残差融合机制。最终增强的查询表示 q~t 由查询分隔符处的隐藏状态 (hq) 与任务分隔符处的隐藏状态 (ht) 的加权组合计算得出,通过超参数 δ 控制平衡。这确保了模型的检索决策在保留查询特异性的同时,受到全局上下文的指导。训练目标为在块与节点检索任务上的联合对比损失,使用InfoNCE损失进行优化。该目标要求模型区分正样本(银标准块)与负样本,负样本由硬负样本(语义相似但无关)与简单负样本(明显无关)构成。

心智空间感知生成器(MiA-Gen)是一个完全微调的大语言模型,利用检索到的块与心智空间生成答案。其输入结构包含书籍摘要、检索到的块与查询,使模型能够基于局部证据与全局叙事进行回应。该框架在多样化的长叙事理解基准上进行评估,包括NarrativeQA、∞Bench、DetectiveQA与NoCha,展示了其在处理复杂长上下文任务方面的有效性。
实验
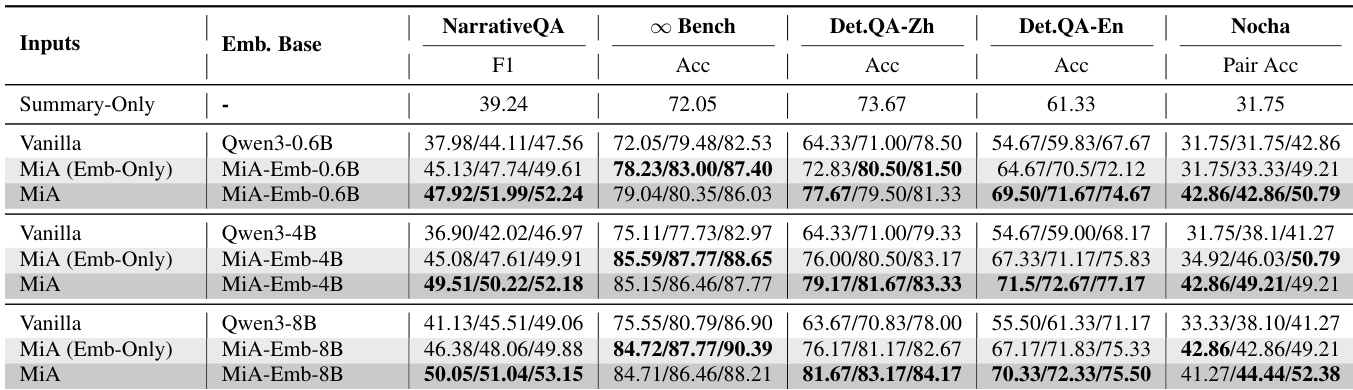
- MiA-Emb在所有检索任务中持续优于基线模型,在领域内NarrativeQA上实现更高的答案召回率,在跨领域双语DetectiveQA上表现更优,相较于最先进模型Sit-Emb(Wu et al., 2025)有显著提升,且在小模型上(如MiA-Emb-0.6B)也超越了Vanilla 8B。
- MiA-RAG在五个长上下文基准(中英文,多领域)上取得最佳整体结果,相比Vanilla 14B提升+16.18%,相比72B提升+8.63%,表明心智空间感知对齐比单纯扩大模型规模更有效。
- 消融研究证实,移除摘要(w/o Summary)导致检索与生成性能显著下降,凸显心智空间表征在引导查询语义与证据整合中的关键作用。
- 心智空间感知检索(MiA-Emb)相比原始检索器平均得分提升6.95%(72B)与7.55%(14B),而心智空间条件化生成(MiA-Gen-14B)相比原始模型提升+11.16%,表明全局上下文同时增强了检索与推理能力。
- MiA-GraphRAG在全局意义理解问答任务中取得明显优势,通过检索语义连贯的图节点实现,MiA-Emb在所有评估维度(全面性、多样性、赋能性)上均优于SFT-Emb与原始Qwen3-Embedding。
- MiA-Emb对摘要质量具有鲁棒性:即使使用较小的开源模型(Qwen2.5-7B至32B)生成的摘要,性能仍保持稳定,结果接近GPT-4o生成的摘要。
- 几何分析显示,MiA-Emb查询与文档语义子空间对齐更好(37.1° vs. 43.5°),实现更精准的检索;注意力分析确认MiA-Emb在关键层逐步整合摘要线索以丰富查询表示。
- MiA-Gen展现出更强的整合推理能力,表现为更高的心智空间一致证据对齐(MCEA)得分,注意力集中在与摘要一致的块上,尤其在中后层;对摘要扰动的敏感性进一步证实了其真实的心智空间驱动推理。
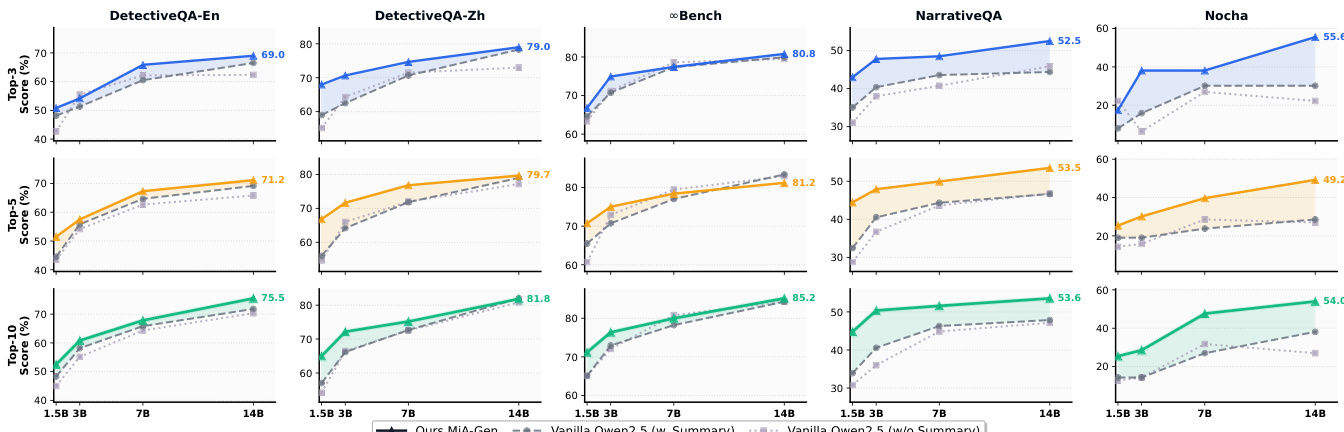
- MiA-Emb与MiA-Gen在不同模型规模下均表现出良好扩展性,MiA-Gen-14B在性能上匹配或超越72B原始模型,MiA-Emb-0.6B超越Vanilla 8B,表明全局语义比模型规模本身更具影响力。
作者在多个长上下文基准上评估了MiA-RAG框架,结果表明MiA-Gen在不同模型规模下持续优于原始生成器,14B版本在性能上匹配或超越72B模型。结果表明,整合心智空间感知的检索与生成在检索与生成任务中均带来显著提升,且随着模型规模增大,性能进一步提升,尤其当全局摘要用于引导两个阶段时。
作者使用名为MiA-Emb的检索模型,该模型结合全局摘要以引导查询表示,并与原始模型及摘要增强基线进行对比。结果表明,MiA-Emb在所有基准上均取得最高平均性能,在领域内NarrativeQA与跨领域DetectiveQA上的答案召回率均有显著提升,证明了心智空间感知检索的有效性。
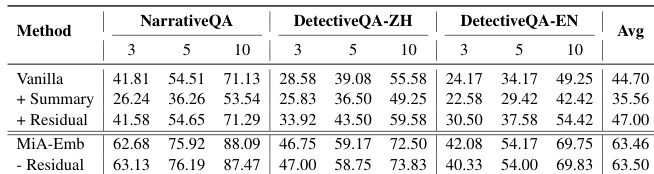
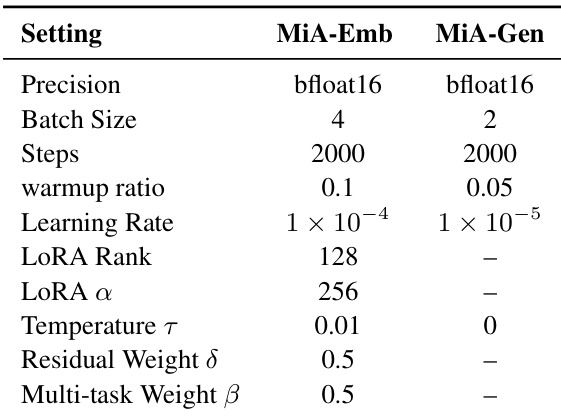
作者使用特定训练配置的MiA-Emb与MiA-Gen模型,其中MiA-Emb采用LoRA,学习率为1 × 10⁻⁴,LoRA秩为128;MiA-Gen采用更低的学习率1 × 10⁻⁵与批量大小2。结果表明,MiA-Emb在各基准上均实现优越的检索性能,MiA-Gen则在与心智空间条件化检索集成时展现出强大的生成能力。
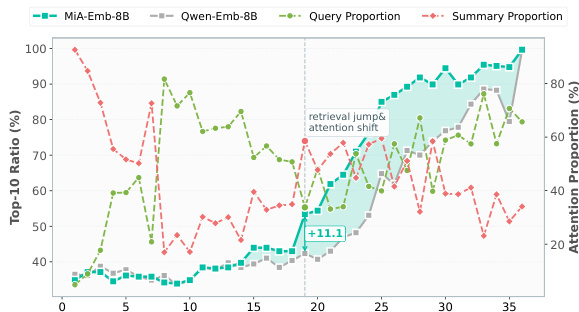
作者通过可视化分析显示,MiA-Emb-8B在Top-10检索比例上优于Qwen-Emb-8B,在第20层实现+11.1%的显著提升。结果表明,MiA-Emb-8B在查询与摘要上的注意力比例更稳定,暗示其查询表示与文档语义子空间对齐更优。
作者使用MiA-Emb——一种心智空间感知的嵌入模型——在多个长上下文基准上提升检索性能。结果表明,MiA-Emb持续优于基线模型,实现更高的召回率与更好的端到端任务表现,尤其在检索阶段引入心智空间摘要时效果最佳。