Command Palette
Search for a command to run...
多LLM主题分析结合双重可靠性度量:基于Cohen's Kappa与语义相似性的定性研究验证
多LLM主题分析结合双重可靠性度量:基于Cohen's Kappa与语义相似性的定性研究验证
Nilesh Jain Seyi Adeyinka Leor Roseman Aza Allsop
摘要
定性研究面临一个关键的信度挑战:传统的评分者间一致性评估方法依赖多名人工编码员,耗时较长,且通常只能达到中等水平的一致性。为此,本文提出一种基于大语言模型(LLM)主题分析的多视角验证框架,该框架融合集成验证机制与双重信度指标——采用Cohen’s Kappa(κ)衡量评分者间一致性,同时引入余弦相似度(cosine similarity)评估语义一致性。本框架支持可配置的分析参数(种子数1–6,温度0.0–2.0),兼容自定义提示结构并支持变量替换,可实现对任意JSON格式数据的共识主题提取。作为概念验证,我们选取三种主流大语言模型(Gemini 2.5 Pro、GPT-4o、Claude 3.5 Sonnet),在一份致幻艺术治疗访谈转录文本上进行测试,每款模型独立运行六次。结果表明,Gemini在信度表现上最优(κ = 0.907,余弦相似度 = 95.3%),其次为GPT-4o(κ = 0.853,余弦相似度 = 92.6%),Claude 3.5 Sonnet表现略低(κ = 0.842,余弦相似度 = 92.1%)。三款模型均达到较高的一致性水平(κ > 0.80),验证了多轮集成分析方法的有效性。框架成功实现了跨运行的共识主题提取:Gemini识别出6个共识主题(一致性达50%–83%),GPT-4o识别出5个,Claude识别出4个。本研究开源的实现方案为研究者提供了透明的信度评估指标、灵活的参数配置能力以及与数据结构无关的共识主题提取功能,为可靠的人工智能辅助定性研究奠定了方法学基础。
单句摘要
耶鲁医学院、埃克塞特大学和集体疗愈中心的研究人员提出了一种多视角LLM验证框架,用于主题分析。该框架通过可配置的集成运行和双重可靠性指标(Cohen's Kappa/余弦相似度)替代传统人工编码。在致幻艺术治疗转录文本上的验证表明,Gemini 2.5 Pro(κ=0.907)、GPT-4o和Claude 3.5 Sonnet均实现了高评分者间一致性(κ>0.80),并通过结构无关的参数定制实现透明的共识主题提取。
主要贡献
- 传统定性研究因耗时的人工编码和中等一致性导致评分者间可靠性不足,本工作提出采用集成运行和双重可靠性指标(Categorical一致性的Cohen's Kappa和语义一致性的余弦相似度)的多视角LLM验证框架。
- 该框架通过可调种子(1-6)和温度(0.0-2.0)实现可配置分析,支持带变量替换的自定义提示,并通过要求≥50%运行一致性的自适应算法提取任意JSON结构中的共识主题。
- 在致幻艺术治疗转录文本上对每个模型进行六次运行评估,所有三个LLM(Gemini 2.5 Pro、GPT-4o、Claude 3.5 Sonnet)均达到高可靠性(κ > 0.80),其中Gemini表现最优(κ = 0.907,余弦相似度=95.3%),在50-83%一致性下提取六个共识主题,通过开源实现验证。
引言
定性研究 increasingly 采用LLM进行主题分析以扩展劳动密集型编码,但验证仍具挑战性——传统指标如Cohen's Kappa要求精确的类别匹配而忽略语义等价性,常导致仅中等水平的人工编码者一致性。现有LLM方法或局限于主题提取、缺乏系统可靠性指标,或在无稳健验证框架的情况下模型表现不一致,凸显了捕捉潜在主题和量化分析可信度的不足。作者通过引入结合Cohen's Kappa与多LLM运行语义相似度分数的双重指标验证框架,量化主题共识与可靠性。
方法
作者利用客户端集成式验证框架确保LLM主题分析的统计稳健性和语义一致性。该系统基于Next.js 14和React完全在浏览器中运行,确保原始转录文本在分析启动前始终保留在研究者设备上,从而保护数据隐私。所有预处理、嵌入计算和共识提取均通过Transformers.js在本地完成,语义相似度计算无需外部API调用。
框架核心是集成验证机制:使用固定随机种子(42, 123, 456, 789, 1011, 1213)执行六次独立分析运行。此设计具有统计依据:六次运行产生15组两两比较,计算公式为:
Comparisons=2n(n−1)=26×5=15这提供了足够的数据点以检测有意义的一致性模式,同时避免过高计算成本。三次到六次运行的标准误差改善率约为41%,计算如下:
SEkSE3=36=2≈1.41每次运行生成JSON格式的主题输出,通过多阶段管道稳健解析:剥离markdown代码围栏、验证结构、并采用指数退避重试失败的API调用。对于自定义提示,系统接受任何有效JSON对象;对于默认提示,则强制要求majorEmotionalThemes和emotionalPatterns等字段。
为提取跨运行的共识主题,作者实现结构无关算法:动态检测公共数组字段(如core_themes, client_experiences),并在其中识别主题名称和支持引文字段。主题通过all-MiniLM-L6-v2模型生成的384维嵌入向量上的余弦相似度进行分组。主题ti与tj的相似度定义为:
其中vi,vj∈R384为嵌入向量。相似度高于0.70的主题聚为等价类。共识通过保留至少50%运行中出现的主题确定,并计算主题级一致性百分比(如5/6=83%)以区分高置信度(5–6/6次运行)与中置信度主题(3–4/6次运行)。
框架通过统一API接口支持九个LLM提供商(包括Google Gemini、Anthropic Claude、OpenAI GPT和OpenRouter接入模型),每个提供商实现标准化请求格式、响应规范化、错误处理和CORS配置。API密钥在运行时提供,且仅传输至对应提供商端点。
为实现方法灵活性,系统暴露可配置参数:研究者可调整种子数量(1–6)、温度(T∈[0.0,2.0])及带变量替换的自定义提示(如{seed}, {text_chunk})。温度控制输出随机性,较低值倾向确定性输出,较高值鼓励探索性解释。
性能针对浏览器执行优化:嵌入计算限制为每次运行10个主题,大型主题集使用轻量级字符串比较,若超过10对则抽样进行两两比较。通过setTimeout(0)让步和密集操作期间的渐进状态更新保持UI响应性。
参见框架示意图获取端到端工作流的可视化概述,从客户端预处理到集成运行、语义聚类及共识提取。
实验
- 在氯胺酮艺术治疗访谈转录文本上评估三个LLM(Gemini 2.5 Pro、GPT-4o、Claude 3.5 Sonnet),每个模型进行六次独立运行,通过双重指标验证集成框架的可靠性.
- 所有模型均达到"几乎完美"的评分者间一致性(Cohen's Kappa > 0.80):Gemini κ=0.907(余弦=95.3%)、GPT-4o κ=0.853(余弦=92.6%)、Claude κ=0.842(余弦=92.1%),证实集成方法的稳健性.
- 跨运行提取共识主题:Gemini识别6个主题(50-83%一致性)、GPT-4o识别5个、Claude识别4个,高置信度主题(如83%一致性下的"克服创作障碍")通过跨模型语义相似度(如"IFS整合"的0.88)验证.
- 通过实现更高跨运行一致性(92-95%余弦相似度)优于现有方法(先前人机比较为0.76相似度),同时实现结构无关的共识提取.
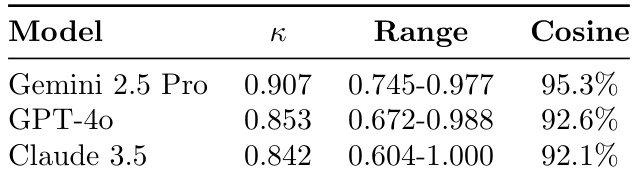
作者采用多运行集成方法评估Gemini 2.5 Pro六次独立运行的主题一致性,通过成对余弦相似度测量语义一致性.结果显示强跨运行一致性,相似度范围0.743至0.910且多数值高于0.78,表明主题稳定性稳健.对角线1.000值反映完美自相似性,高非对角线分数验证模型在不同运行中生成一致主题输出的可靠性.
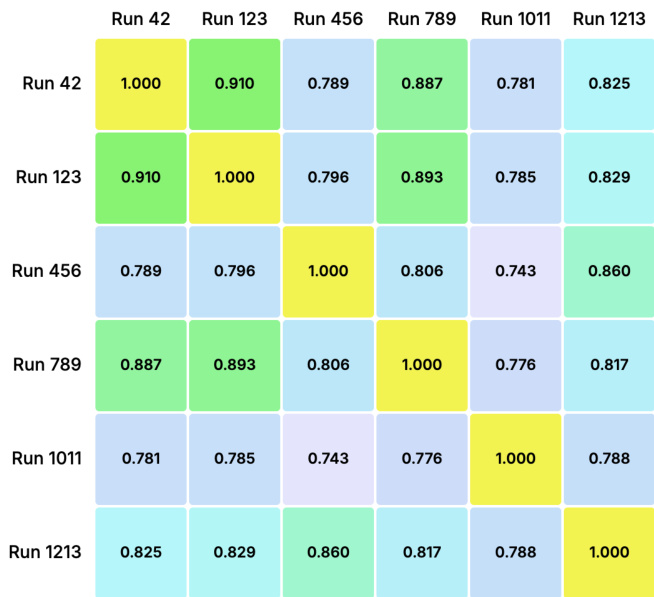
作者采用多运行集成方法评估三个LLM在氯胺酮艺术治疗转录文本上的主题一致性,统计主题总数并按共识级别分类. Gemini 2.5 Pro提取最多主题(6个),含2个高共识和4个中共识主题;GPT-4o识别5个主题(2高3中);Claude 3.5 Sonnet识别4个主题(1高3中).结果表明Gemini主题稳定性最高,其次为GPT-4o和Claude,与其可靠性得分一致.
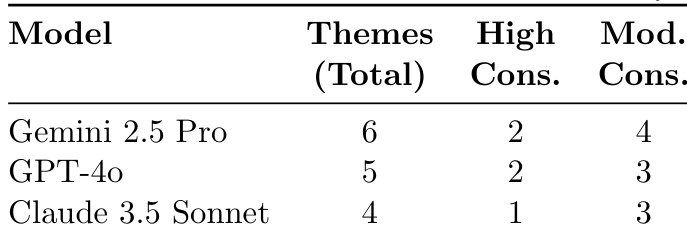
作者将多运行集成框架与传统人工、QualIT及单次LLM方法对比,显示其提供完整主题分析、双重可靠性指标(Cohen’s Kappa和余弦相似度)、自定义提示支持及基于种子的高可复现性.该方法在显著降低成本(20份文档3–6)的同时实现更高可靠性(κ=0.84–0.91)(人工编码400–800),并提供单次LLM方法缺乏的结构化验证.结果证实框架通过集成一致性平衡计算效率与严格定性标准的能力.
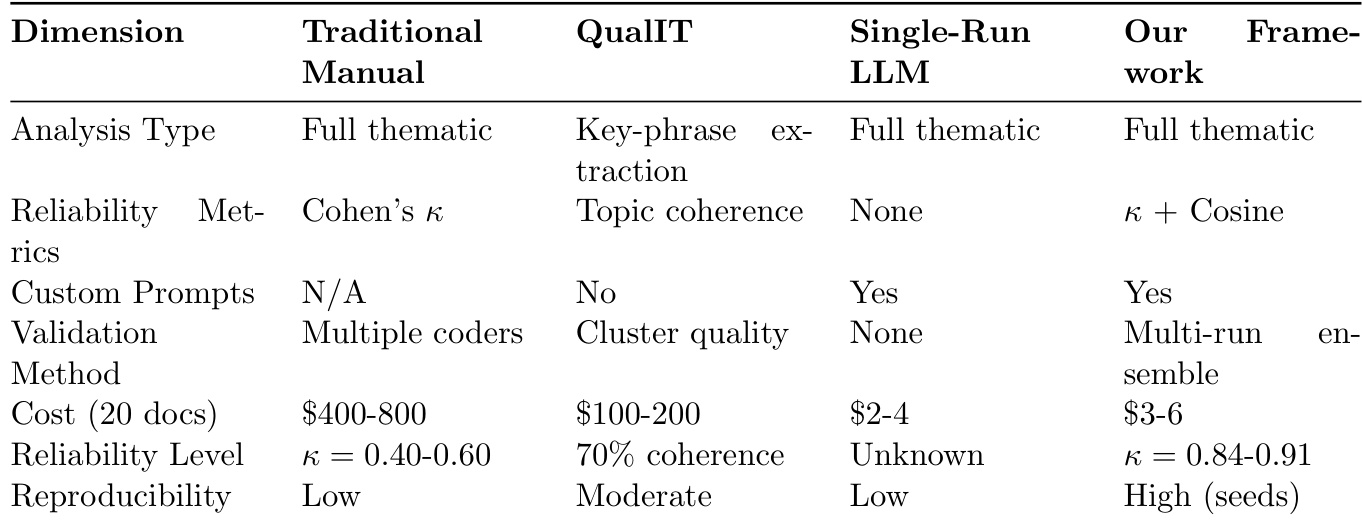
作者使用双重可靠性指标评估三个LLM的六次运行,发现Gemini 2.5 Pro取得最高Cohen’s Kappa(0.907)和余弦相似度(95.3%),且kappa范围最窄表明性能稳定. GPT-4o和Claude 3.5同样显示强一致性(κ > 0.84),但Claude的kappa范围最宽,提示跨运行变异性更大.结果验证集成方法在主题分析中实现高跨运行一致性的有效性.