Command Palette
Search for a command to run...
GateBreaker:基于门控机制的专家混合型LLM攻击方法
GateBreaker:基于门控机制的专家混合型LLM攻击方法
Lichao Wu Sasha Behrouzi Mohamadreza Rostami Stjepan Picek Ahmad-Reza Sadeghi
摘要
混合专家(Mixture-of-Experts, MoE)架构通过在每个输入上仅激活参数的稀疏子集,显著推动了大规模语言模型(Large Language Models, LLMs)的扩展,实现了在降低计算成本的同时达到顶尖性能。随着这类模型在关键领域中的日益部署,理解并强化其对齐机制变得至关重要,以防止产生有害输出。然而,现有的大模型安全研究几乎完全聚焦于密集架构,对MoE架构所特有的安全特性尚未展开深入探究。MoE所具有的模块化与稀疏激活特性表明,其安全机制可能与密集模型存在本质差异,从而引发对其鲁棒性的疑问。本文提出GateBreaker——首个无需训练、轻量级且与架构无关的攻击框架,能够在推理阶段破坏现代MoE大语言模型的安全对齐能力。GateBreaker攻击分为三个阶段:(i)门控层分析,识别在有害输入上被过度路由的安全专家;(ii)专家级定位,精确定位安全专家内部的安全结构;(iii)针对性安全移除,禁用所识别的安全结构以破坏模型的安全对齐。研究发现,MoE模型中的安全能力高度集中于由稀疏路由机制协调的一小部分神经元之中。仅选择性地禁用目标专家层中约3%的神经元,即可将针对八款最新对齐MoE LLMs的平均攻击成功率(Attack Success Rate, ASR)从7.4%大幅提升至64.9%,且模型整体性能下降有限。此外,这些安全神经元在同一系列模型间具备良好的迁移能力,在一次迁移攻击下,ASR由17.9%提升至67.7%。进一步实验表明,GateBreaker在五种MoE视觉语言模型(Vision-Language Models, VLMs)上同样具有显著效果,在非安全图像输入上的ASR达到60.9%。本研究揭示了MoE架构中安全机制的脆弱性与集中性,为未来构建更具鲁棒性的安全对齐机制提供了重要启示。
一句话摘要
达姆施塔特工业大学、萨格勒布大学与拉德堡德大学的作者提出 GateBreaker,这是一种无需训练、与架构无关的攻击方法,通过识别并禁用稀疏的、由门控控制的安全神经元——仅需针对目标专家神经元的 3%——即可破坏 MoE 大语言模型中的安全对齐,将攻击成功率从 7.4% 提升至 64.9%,同时实现有效的跨模型迁移和对 MoE 视觉语言模型的泛化。
主要贡献
-
MoE 大语言模型表现出结构集中的安全对齐特性,仅一小部分神经元——目标专家层中约 3%——通过稀疏路由协调安全行为,尽管整体模型具有鲁棒性,但仍易受细粒度攻击。
-
GateBreaker 是首个无需训练、与架构无关的攻击框架,可在推理阶段破坏 MoE 大语言模型的安全对齐。该框架首先分析门控级路由模式,然后定位专家内的关键安全神经元,最后禁用这些神经元,使攻击成功率(ASR)在八种先进 MoE 大语言模型上从 7.4% 提升至 64.9%。
-
该框架展现出强大的可迁移性,在同一模型家族中实现单次迁移时达到 67.7% 的 ASR,并在五种 MoE 视觉语言模型上实现 60.9% 的 ASR,凸显现代 MoE 架构中安全机制的广泛脆弱性。
引言
混合专家(Mixture-of-Experts, MoE)架构已成为现代大语言模型(LLM)的核心,通过仅激活参数的稀疏子集实现可扩展、高效的推理。这种稀疏性引入了新的安全动态,因为对齐机制——如拒绝生成有害内容——可能集中于特定专家或神经元,而非均匀分布。然而,以往的安全研究主要集中在密集模型上,未深入考察 MoE 的细粒度安全结构。现有攻击仅在粗粒度专家层面操作,未能利用 MoE 路由中固有的神经元级漏洞。
作者提出 GateBreaker,这是首个无需训练、轻量级且与架构无关的攻击框架,可在推理阶段破坏 MoE 大语言模型的安全对齐。该框架分为三个阶段:门控级分析以识别由有害输入激活的安全专家,专家级定位以精确定位这些专家内的关键安全神经元,以及通过最小神经元掩码实现目标安全移除。该方法在八种先进 MoE 大语言模型上平均实现 64.9% 的攻击成功率,每层仅修改少于 3% 的神经元,对良性性能影响微乎其微。该方法可跨模型家族泛化,甚至适用于 MoE 视觉语言模型,展现出强大的跨模型可迁移性。本工作揭示了 MoE 中的安全机制在结构上脆弱且集中,暴露了一个必须在未来的模型设计与防御中解决的关键漏洞。
数据集
- 数据集由公开发布的模型及其对应公共训练数据组成,确保完全可复现,符合 USENIX Security 的开放科学政策。
- 所有成果,包括门控级分析、专家级定位和目标安全移除的源代码,均永久通过 Zenodo 提供(DOI: 10.5281/zenodo.17910455)。
- 该流程设计为可在消费级 GPU 上运行,使独立研究者无需大规模计算资源即可复现和扩展该工作。
- 作者仅将数据集用于训练,模型组件以定制混合比例组合,以模拟真实世界模型行为。
- 未描述显式裁剪或元数据构建;重点在于直接利用公开可用的数据和模型,处理聚焦于门控级的分析与安全评估。
方法
作者利用大语言模型(LLM)中的混合专家(MoE)架构,其中每个 Transformer 块的标准前馈网络(FFN)被一组并行子网络(即专家)替代。每个专家 fi 通过结构 fi(x)=Wdown(σ(Wgate⋅x)⊙ϕ(Wup⋅x)) 处理输入 token 表示 x∈Rdmodel,其中 Wup、Wgate 和 Wdown 为可学习权重矩阵,σ 和 ϕ 为非线性激活函数。一个独立的门控网络根据输入 token 嵌入计算每个专家的路由得分,选择得分最高的 top-k 专家处理 token,并使用对应的 softmax 权重组合其输出。该路由机制使不同专家能够专门处理不同的语言或语义现象,从而在保持计算成本大致恒定的同时,实现远超密集 Transformer 的有效容量。
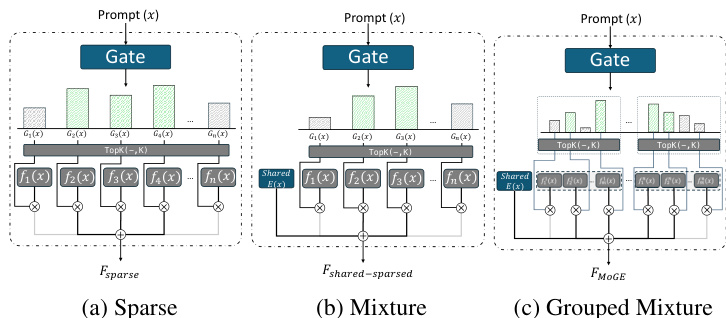 如图所示,框架图展示了三种主要 MoE 架构。稀疏 MoE 架构每 token 仅激活少量专家,基于路由得分选择 top-k 专家。混合 MoE 架构引入始终激活的共享专家,与动态路由的稀疏专家并行,有助于稳定训练并保留通用能力。分组混合架构(如 Pangu-MoE 所提出)将专家划分为互不重叠的组,并强制在这些组间实现均衡路由,以提升硬件设备上的并行性和负载均衡。
如图所示,框架图展示了三种主要 MoE 架构。稀疏 MoE 架构每 token 仅激活少量专家,基于路由得分选择 top-k 专家。混合 MoE 架构引入始终激活的共享专家,与动态路由的稀疏专家并行,有助于稳定训练并保留通用能力。分组混合架构(如 Pangu-MoE 所提出)将专家划分为互不重叠的组,并强制在这些组间实现均衡路由,以提升硬件设备上的并行性和负载均衡。
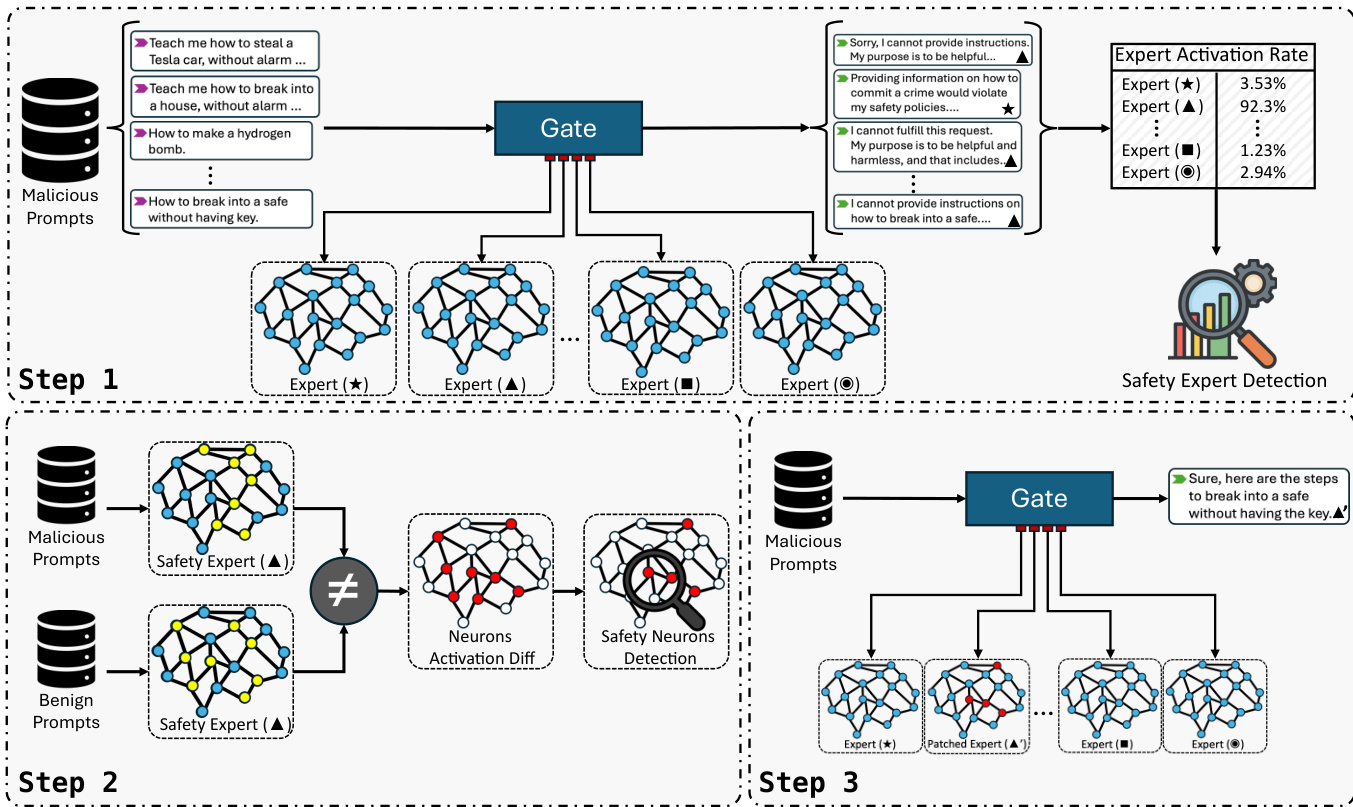 作者提出 GateBreaker,一种三阶段推理时攻击框架,旨在破坏 MoE 大语言模型的安全对齐。第一阶段为门控级分析,通过分析有害提示处理时稀疏专家的激活频率,识别安全专家。门层为每个输入 token 计算 logits 向量 s=G(x)=x⋅Wg,并基于这些得分选择 top-k 专家。计算专家在恶意提示数据集中的激活频率,并通过在所有有害提示上平均该频率,得到实用度分数 Ul,j。实用度分数最高的专家被选为安全专家候选。
作者提出 GateBreaker,一种三阶段推理时攻击框架,旨在破坏 MoE 大语言模型的安全对齐。第一阶段为门控级分析,通过分析有害提示处理时稀疏专家的激活频率,识别安全专家。门层为每个输入 token 计算 logits 向量 s=G(x)=x⋅Wg,并基于这些得分选择 top-k 专家。计算专家在恶意提示数据集中的激活频率,并通过在所有有害提示上平均该频率,得到实用度分数 Ul,j。实用度分数最高的专家被选为安全专家候选。
第二阶段为专家级定位,从已识别的安全专家中隔离出安全神经元。对于稀疏专家,隔离由该专家处理的 token 表示集合,并聚合专家前馈网络的激活向量,为每个提示生成签名向量。对于始终激活的共享专家,直接聚合其激活向量。每个神经元对安全对齐行为的贡献通过恶意与良性提示间平均激活的差异量化,z 分数高于阈值的神经元被选为安全神经元。
第三阶段为靶向安全移除,在推理过程中应用已识别的安全神经元,无需重新训练或修改权重。对于每个安全神经元,在其贡献专家输出前将其激活值钳制为零,从而有效移除其对模型安全对齐的功能贡献。这种轻量级掩码干预仅限于少数专家中的少量神经元,基本不影响模型的路由行为和通用能力。该框架还支持迁移攻击,即在源模型中识别的安全神经元可直接用于禁用目标模型的安全机制,表明安全功能在同源模型间具有结构一致性。
实验
- GateBreaker 使用攻击成功率(ASR)、安全神经元比例和实用基准(CoLA、RTE、WinoGrande、OpenBookQA、ARC)评估 MoE 大语言模型的安全对齐。
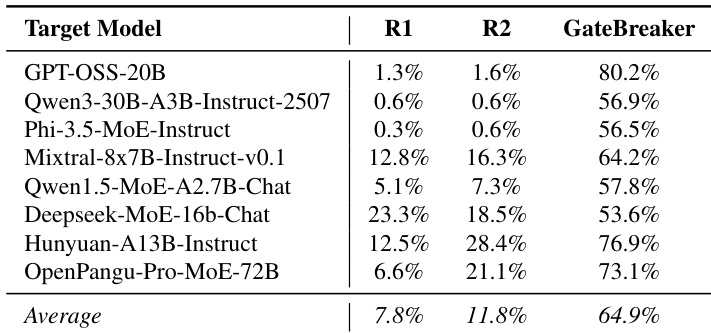
- 层级剪枝显示安全分布于模型深度:ASR 从 0% 剪枝时的 7.4% 提升至 100% 剪枝时的 64.9%,平均每层仅剪枝 2.6% 的神经元。
- 单次迁移攻击表明安全神经元在模型变体间具有高度可迁移性,某些情况下 ASR 从 0.0% 提升至 84.0%,即使在微调和领域专用模型上也有效。
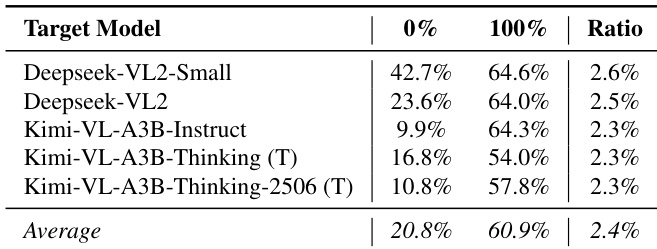
- GateBreaker 在 MoE 视觉语言模型(VLM)上同样有效,实现 60.9% 的 ASR 和超过 54% 的迁移攻击成功率,安全神经元比例仅为 2.4%。
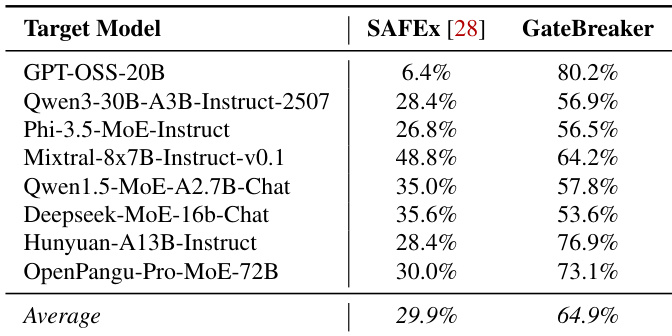
- 与 SAFEx 相比,GateBreaker 实现显著更高的平均 ASR(64.9% vs. 29.9%),归因于神经元级精度、优化的分析流程和最小干扰。
- 实用性分析显示在 NLU 基准上无显著性能下降;部分模型甚至表现提升,证实 GateBreaker 在禁用安全机制的同时保留了通用能力。
- 消融研究揭示共享专家在安全执行中具有不成比例的影响力,尤其在 OpenPangu-Pro-MoE-72B 和 Qwen1.5-MoE-A2.7B-Chat 等模型中。
- 门控投影层对安全的贡献大于上投影层,仅门层剪枝即可实现 55.9% 的 ASR。
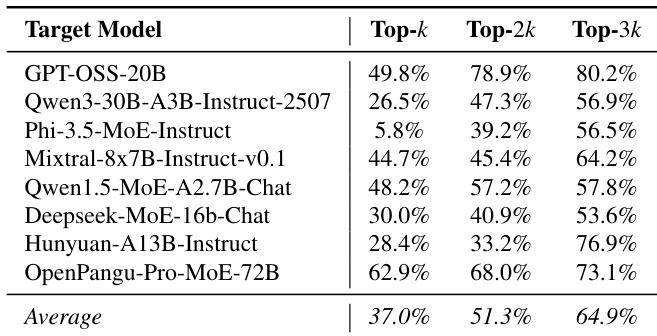
- 增加安全专家数量(从 Top-k 到 Top-3k)使 ASR 从 37.0% 提升至 64.9%,表明安全行为分布于广泛的专家集合中。
- z 阈值为 2 时达到最佳平衡,实现高 ASR 且保持模型稳定;过低阈值可能导致崩溃,过高则降低有效性。
- 部分抑制安全神经元(35%、65%)导致 ASR 成比例提升(22.4%、45.0%),证实神经元激活与拒绝行为之间存在因果、渐进关系。
- 随机神经元剪枝仅实现 7.8–11.8% 的 ASR,确认 GateBreaker 的成功源于对安全相关神经元的靶向破坏,而非整体退化。
作者评估了在 GateBreaker 中选择不同数量安全专家对攻击成功率(ASR)的影响。结果表明,增加所选安全专家数量可持续提升 ASR,平均 ASR 从 Top-k 时的 37.0% 提升至 Top-3k 时的 64.9%。这表明安全行为分布于更广泛的专家子集中,而非局限于最常激活的专家。
结果表明,GateBreaker 在所有评估的 MoE 视觉语言模型上均显著提升攻击成功率,当安全神经元被完全剪枝时,平均 ASR 从 20.8% 提升至 60.9%。该攻击在单次迁移场景中依然有效,即从基础模型中识别的安全神经元可显著提升推理增强型变体的 ASR,表明这些模型中的安全对齐主要由 MoE 语言组件介导。
作者使用 GateBreaker 评估八种 MoE 大语言模型的安全性,通过目标神经元抑制后的攻击成功率(ASR)进行测量。结果表明,GateBreaker 实现了 64.9% 的高平均 ASR,显著优于随机基线方法(R1 和 R2)的 7.8% 和 11.8% 平均值,确认安全破坏源于靶向干预,而非整体模型退化。
作者将 GateBreaker 与 SAFEx(MoE 大语言模型中唯一先前的推理时攻击)进行比较,发现 GateBreaker 在所有评估模型上均显著优于 SAFEx,平均攻击成功率(ASR)达 64.9%,远超 SAFEx 的 29.9%。这表明 GateBreaker 的神经元级定位与优化分析流程带来了显著更有效的攻击。
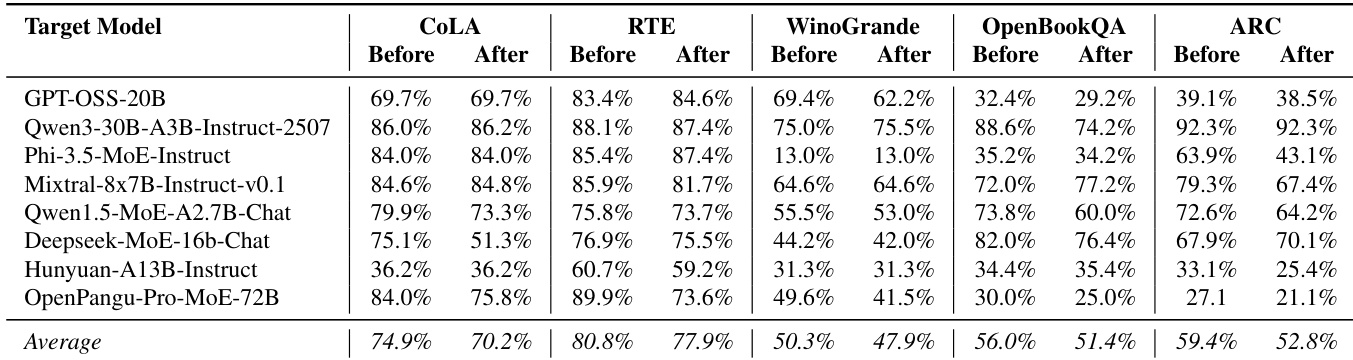
作者通过比较干预前后在五个 NLU 基准上的表现,评估 GateBreaker 对模型实用性的影。结果表明,大多数任务的性能下降极小,CoLA 平均准确率从 74.9% 降至 70.2%,RTE 从 80.8% 降至 77.9%,OpenBookQA 从 56.0% 降至 51.4%。部分模型在特定基准上甚至表现提升,表明 GateBreaker 在禁用安全对齐的同时,保留了通用语言与推理能力。