Command Palette
Search for a command to run...
HY-Motion 1.0:面向文本到动作生成的流匹配模型扩展
HY-Motion 1.0:面向文本到动作生成的流匹配模型扩展
摘要
我们提出 HY-Motion 1.0,这是一系列处于前沿水平、大规模的三维人体动作生成模型,能够根据文本描述生成高质量的3D人体动作。HY-Motion 1.0 是首个成功将基于扩散变换器(Diffusion Transformer, DiT)的流匹配模型扩展至十亿参数规模的人体动作生成范例,在指令遵循能力方面显著超越当前开源基准。独特之处在于,我们引入了一套全面的全流程训练范式——涵盖在超过3000小时动作数据上的大规模预训练、在400小时精选高质量数据上的精细化微调,以及结合人类反馈与奖励模型的强化学习训练——以确保生成动作与文本指令的高度对齐,并保障卓越的动作质量。该框架依托我们精心设计的数据处理流程,实现了严格的动作数据清洗与精准标注。由此,我们的模型实现了最广泛的动作类别覆盖,涵盖六大主要类别下的200余种动作类型。我们已将 HY-Motion 1.0 开源发布,旨在推动后续研究发展,并加速三维人体动作生成模型向商业化成熟阶段的迈进。
一句话摘要
腾讯混元3D数字人团队推出HY-Motion 1.0,这是一个基于扩散Transformer(DiT)的百亿参数流匹配模型,通过结合大规模预训练、精选微调和强化学习的全流程训练管道,实现从文本生成高保真3D动作,覆盖200多个动作类别,具备卓越的指令对齐与覆盖能力,并开源发布以推动数字人应用的商业化落地。
主要贡献
- HY-Motion 1.0是首个将基于扩散Transformer(DiT)的流匹配模型扩展至超过百亿参数规模的文本到动作生成模型,实现了显著超越现有开源模型的最先进指令遵循能力。
- 该模型采用全面的三阶段训练范式——在3000小时以上的动作数据上进行大规模预训练,使用400小时精心筛选的文本-动作配对数据进行高质量微调,并结合人类反馈与奖励模型的强化学习,联合优化动作质量与语义对齐。
- 通过结合自动化清洗与大量人工精修的精心设计数据筛选流程,构建了一个涵盖六大主要类别、超过200个动作类别的大规模数据集,使模型能够生成多样、真实且指令精准的3D人类动作。
引言
作者利用扩散模型与流匹配技术推进文本到动作生成,这是在虚拟现实、数字人和机器人等应用中创建逼真3D人类动画的关键能力。以往工作面临关键局限:小型模型缺乏复杂性与语义理解能力,而基于大语言模型(LLM)使用离散动作标记的方法则因量化导致动作质量下降。此外,该领域缺乏大规模、高质量的数据集以及有效的扩散基动作模型扩展策略。为应对这些挑战,作者提出HY-Motion 1.0,首个用于文本到动作生成的百亿参数DiT基流匹配模型。其核心贡献在于一个全流程训练范式,结合3000小时以上多样化动作数据的大规模预训练、400小时精心筛选的文本-动作对的高质量微调,以及基于人类与奖励模型反馈的强化学习。该方法实现了卓越的动作保真度、自然性与指令遵循准确性。同时,作者发布了一个新的开源数据集,包含超过200个动作类别,通过混合自动化与人工筛选流程构建,为该领域设立了数据质量与规模的新基准。
数据集
- 数据集由三大主要来源构成:野外人类动作视频(来自HunyuanVideo的1200万段视频)、动作捕捉数据(约500小时)以及游戏制作中的3D动画资产。
- 视频数据经过镜头边界检测与人体检测,以提取相关片段,随后使用GVHMR进行3D人体动作重建,提取SMPL-X参数。
- 所有动作数据通过重定向标准化为SMPL-H骨架(22个关节,无手部),非SMPL-H格式的数据通过网格拟合或骨骼映射处理。
- 采用全面的过滤流程,移除重复项、异常姿态、关节速度异常值、静态动作、异常位移以及如脚滑等伪影。
- 过滤后,动作被规范化:重采样至30 fps,拆分为不超过12秒的片段,并对齐至标准坐标系(Y轴向上,原点居中,地面齐平,面向正Z轴)。
- 最终数据集包含超过3000小时的动作数据,其中400小时为高质量动作,每个动作以201维向量序列表示(包含平移、全局朝向、局部旋转与关节位置),采用6D旋转表示法。
- 采用三级分层动作分类体系,将数据组织为六大顶层类别——行走与移动、体育与竞技、健身与户外活动、日常活动、社交互动与休闲、游戏角色动作,扩展至200多个细粒度动作类别。
- 全数据集 Dall 在大规模预训练中用于流匹配目标,利用高质量与噪声数据共同建立广泛的语义与运动先验。
- 文本描述涵盖人工标注至VLM生成的标题,支持预训练阶段的语义泛化。
- 模型以恒定学习率训练,快速学习多样化的动作模式,形成高熵、语义丰富的初始化,捕捉一般运动动态,但因噪声输入引入伪影。
- 此预训练阶段为后续微调奠定基础,在此阶段提升动作质量的同时保持语义保真度。
方法
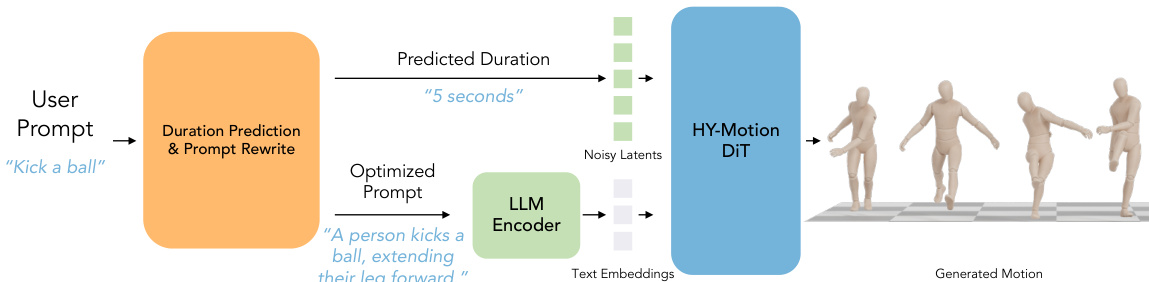
作者采用一种混合Transformer架构,称为HY-Motion DiT,作为从文本生成3D人类动作的核心模型。整体框架如图所示,从用户提示开始,由专用LLM模块处理时长预测与提示重写。该模块输出优化后的提示与预测时长,用于条件化HY-Motion DiT模型。模型接收噪声动作隐变量、优化后的文本提示与时间步作为输入,输出3D人类动作序列。该框架由全面的数据处理流程支持,确保高质量训练数据。
HY-Motion DiT模型采用混合架构,结合双流与单流处理,以建模动作与文本的联合分布。网络从双流模块开始,动作隐变量与文本标记分别通过独立的QKV投影与MLP处理。两流通过联合注意力机制交互,使动作特征能够查询文本中的语义线索,同时保留各自模态特有的表示。随后在单流模块中,动作与文本标记被拼接为统一序列,通过并行的空间与通道注意力模块实现深度多模态融合与信息交换。
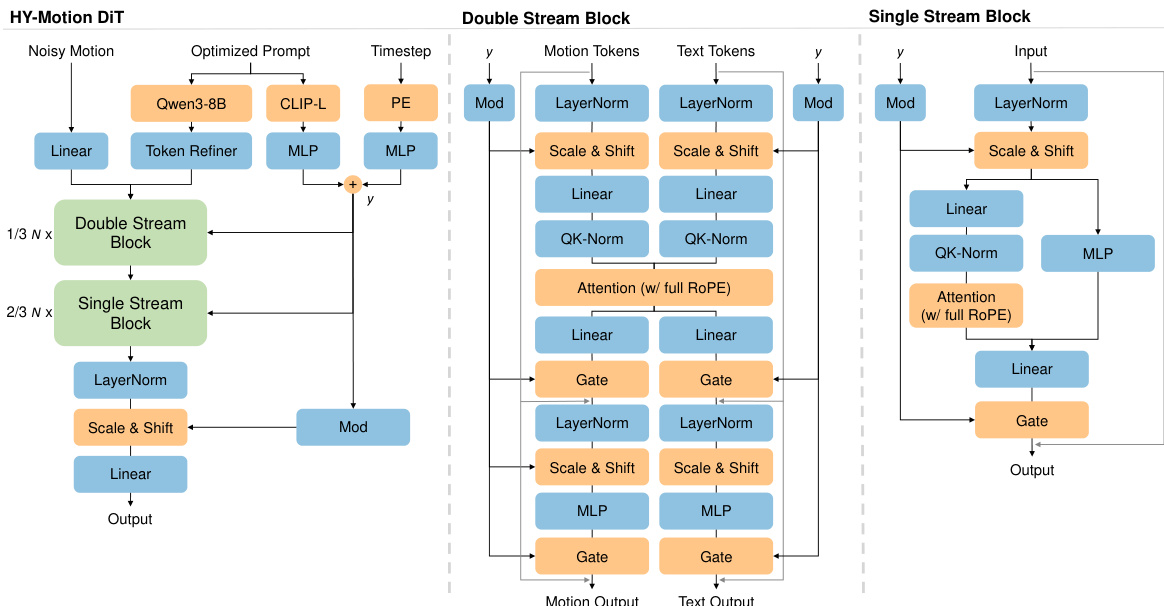
文本编码器采用分层双条件策略,整合细粒度与全局文本引导。作者使用Qwen3-8B提取丰富的逐标记语义嵌入。为克服LLM中因果注意力的局限,采用双向标记精修器(Bidirectional Token Refiner),在注入双流模块前将因果LLM特征转换为双向表示。同时,使用CLIP-L提取全局文本嵌入,与时间步嵌入拼接后,通过独立的AdaLN机制注入,以自适应调节网络中各层的特征统计。
注意力机制在跨模态交互与时间建模中采用特定掩码策略。采用非对称注意力掩码以调控多模态信息流:动作标记全局关注文本序列以提取语义线索,而文本标记则显式屏蔽动作隐变量,防止扩散噪声回传至文本嵌入。在动作分支的时间建模中,采用窄带掩码策略,将注意力限制在30 fps下121帧的滑动窗口内,以施加局部性归纳偏置。为在空间上定位这些注意力交互,模型使用完整的旋转位置编码(RoPE),应用于拼接后的文本与动作嵌入统一序列,建立连续的相对坐标系统。
训练目标基于流匹配(Flow Matching),在标准高斯噪声分布与复杂动作数据分布之间构建连续概率路径。作者采用最优传输路径,定义为线性插值 xt=(1−t)x0+tx1,意味着目标速度恒定。训练目标是最小化预测速度与真实速度之间的均方误差(MSE):
LFM=Et,x0,x1[∣∣vθ(xt,c,t)−vt∣∣D2],其中 x1 表示干净动作数据,x0∼N(0,I) 为初始噪声,目标速度为 vt=x1−x0。推理阶段,生成过程被表述为常微分方程(ODE):dx/dt=vθ(xt,c,t)。从随机噪声 x0 出发,模型通过ODE求解器数值积分该ODE,恢复出干净动作 x1。
实验
- 高质量微调:切换至精选数据集 DHQ,并降低学习率(ηfit=0.1×ηpre),在不牺牲多样性的前提下显著提升动作质量与语义精确度,大幅减少噪声、抖动与脚滑现象,同时增强解剖一致性与细粒度指令遵循能力。
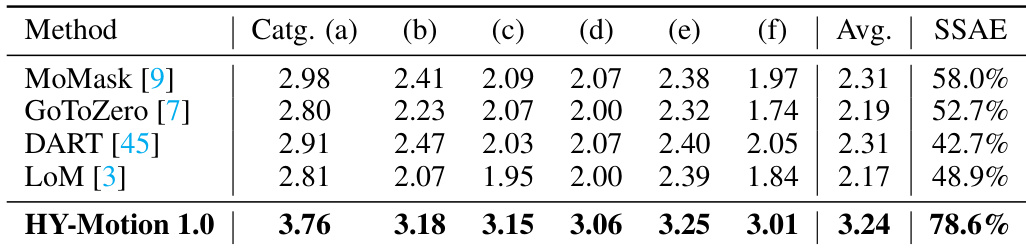
- 最先进模型对比:在涵盖六个动作类别的2000+个提示的测试集上,HY-Motion 1.0在指令遵循能力与动作质量方面均优于DART、LoM、GoToZero与MoMask,通过基于视频-VLM的评估获得更高人类评分与更优的SSAE分数。
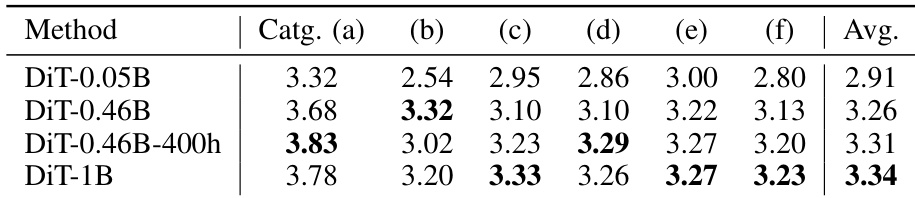
- 扩展性实验:模型规模增大可提升指令遵循能力,但动作质量在超过0.46B参数后趋于饱和;3000小时预训练数据对指令准确性至关重要,因此发布DiT-1B作为主模型,DiT-0.46B作为轻量级变体。
结果表明,增大模型规模可提升指令遵循能力,DiT-1B模型在所有动作类别上取得最高平均分。然而,动作质量在0.46B参数规模后趋于平稳,如表中各类别表现一致所示。
结果表明,HY-Motion 1.0在所有动作类别上均显著优于对比模型的指令遵循能力,平均分达到最高值3.43。模型在区分细粒度动作方面表现出色,同时在多种动作类型上保持强劲性能。
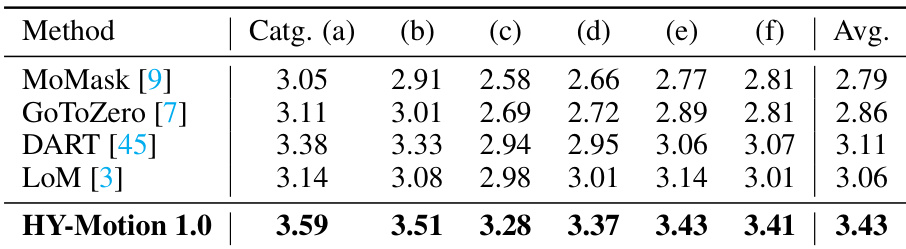
结果表明,HY-Motion 1.0在所有动作类别上显著优于现有模型的指令遵循能力,平均分高达3.24,远超其他方法的2.17–2.31。模型还取得最佳SSAE分数78.6%,表明生成动作与文本指令之间具有更优的对齐性。
结果表明,增大模型规模可提升指令遵循能力,DiT-1B模型在所有动作类别上取得最高平均分。相比之下,仅在较小数据集上训练的DiT-0.46B-400h模型表现较差,表明数据量对指令遵循能力具有显著影响。