Command Palette
Search for a command to run...
动态大概念模型:自适应语义空间中的潜在推理
动态大概念模型:自适应语义空间中的潜在推理
摘要
大型语言模型(LLMs)对所有词元(tokens)采用统一的计算方式,然而语言本身具有高度非均匀的信息密度。这种“词元均匀”的计算范式在局部可预测的文本片段上浪费了计算资源,同时在语义关键转换处又计算分配不足。为此,我们提出动态大概念模型(Dynamic Large Concept Models, DLCM),这是一种分层语言建模框架,能够从潜在表示中学习语义边界,并将计算从词元层面迁移至一个压缩后的概念空间,在该空间中推理效率更高。DLCM能够端到端地发现变长的概念,无需依赖预定义的语言单元。分层压缩从根本上改变了模型的扩展规律。我们首次提出压缩感知扩展定律(compression-aware scaling law),该定律解耦了词元级容量、概念级推理容量与压缩比三个核心维度,从而在固定浮点运算量(FLOPs)约束下实现有原则的计算资源分配。为稳定训练这一异构架构,我们进一步开发了解耦的μP参数化方法(decoupled μP parametrization),支持在不同模型宽度和压缩率之间实现零样本超参数迁移。在实际设置下(压缩比 R=4,即每个概念平均对应4个词元),DLCM将约三分之一的推理计算重新分配至更高容量的推理主干网络,在与基线模型匹配的推理FLOPs条件下,于12个零样本基准测试上实现了平均提升+2.69%的显著性能增益。
一句话总结
字节跳动Seed、曼彻斯特大学、Mila、清华大学和M-A-P推出了动态大概念模型(DLCM),这是一个将计算转移到压缩语义空间的分层框架。它具有端到端的可变长度概念和感知压缩的缩放定律,在匹配推理FLOPs的情况下,在12个基准测试中平均提升了+2.69%。
关键贡献
- 标准LLM在可预测的token上浪费计算,而对语义关键的过渡分配不足。DLCM引入了一个分层框架,该框架端到端地学习语义边界,并将推理转移到压缩的概念空间,将概念形成与token级解码解耦。
- 该方法使用一个四阶段管道,通过学习的边界检测器将token分割成可变长度的概念,并使用大容量Transformer进行概念级推理。解耦的μP参数化实现了跨宽度和压缩机制的稳定训练和零样本超参数迁移。
- 作者提出了首个感知压缩的缩放定律,该定律解耦了token级容量、概念级推理容量和压缩比,以实现原则性的计算分配。在R=4时,DLCM将约三分之一的推理FLOPs重新分配给推理主干,在匹配推理FLOPs的情况下,在12个零样本基准测试中平均提升了+2.69%。
引言
LLM用相等的计算处理每个token,这是低效的,因为自然语言具有不同的信息密度,且推理本质上是分层的。作者提出了动态大概念模型(DLCM),一个学习语义边界并将繁重计算转移到压缩概念空间的框架。这种方法通过端到端地发现可变长度概念,而不是依赖固定的语言单位,克服了先前工作的局限性。他们的关键贡献是一个将概念形成与推理分离的分层架构,以及一个新的缩放定律,在匹配推理成本的情况下实现了更好的性能。
数据集
-
数据集构成与来源
- 作者完全使用开源数据构建预训练语料库,使用DeepSeek-v3 tokenizer。
- 该数据集涵盖多个领域,包括中英文网络文本、数学和代码。
- 这种混合旨在提供广泛的语言覆盖并增强结构化推理。
- 从冗长的散文到结构化代码的数据多样性,对于训练模型的动态分割能力至关重要。
- 中英文网络文本被赋予更高的权重以实现多语言对齐,同时包含MegaMath-Web和OpenCoder-Pretrain等专业数据集,以改善对高熵过渡的处理。
-
子集详情与过滤
- 作者没有应用激进的过滤,以避免从数据整理中获益,确保任何性能提升都归因于DLCM的架构优势。
- 数据质量符合标准开源语料库。
- 预训练数据的具体统计信息总结在表1中。
-
数据使用与处理
- 整个语料库使用DeepSeek-v3 [14] tokenizer进行token化。
- 该数据用于预训练模型,其领域混合服务于两个关键目标:平衡广度和专业性,以及实现稳健的动态分割。
- 作者有意让模型接触不同信息密度的领域,以迫使学习的边界预测器发现内容自适应的分割策略。
方法
作者利用一个名为动态大概念模型(DLCM)的分层next-token预测架构,以实现具有学习边界的概念级潜在推理。整体框架如下图所示,包括四个顺序阶段:编码、动态分割、概念级推理和token级解码。编码器是一个标准的因果Transformer,处理输入token序列以生成细粒度表示。这些表示随后被送入动态分割模块,该模块通过测量相邻token嵌入之间的局部不相似性来检测语义边界,使用基于余弦相似度的边界概率。检测到的边界将序列分割成可变长度的段,这些段通过均值池化和投影到概念维度被压缩成单个概念表示。这个压缩序列随后由概念级Transformer处理,该Transformer在语义对齐的空间中进行深度推理,显著降低了注意力复杂度。最后,解码器通过因果交叉注意力机制关注推理后的概念来重建token级预测,其中每个token只能关注到其对应边界索引之前形成的概
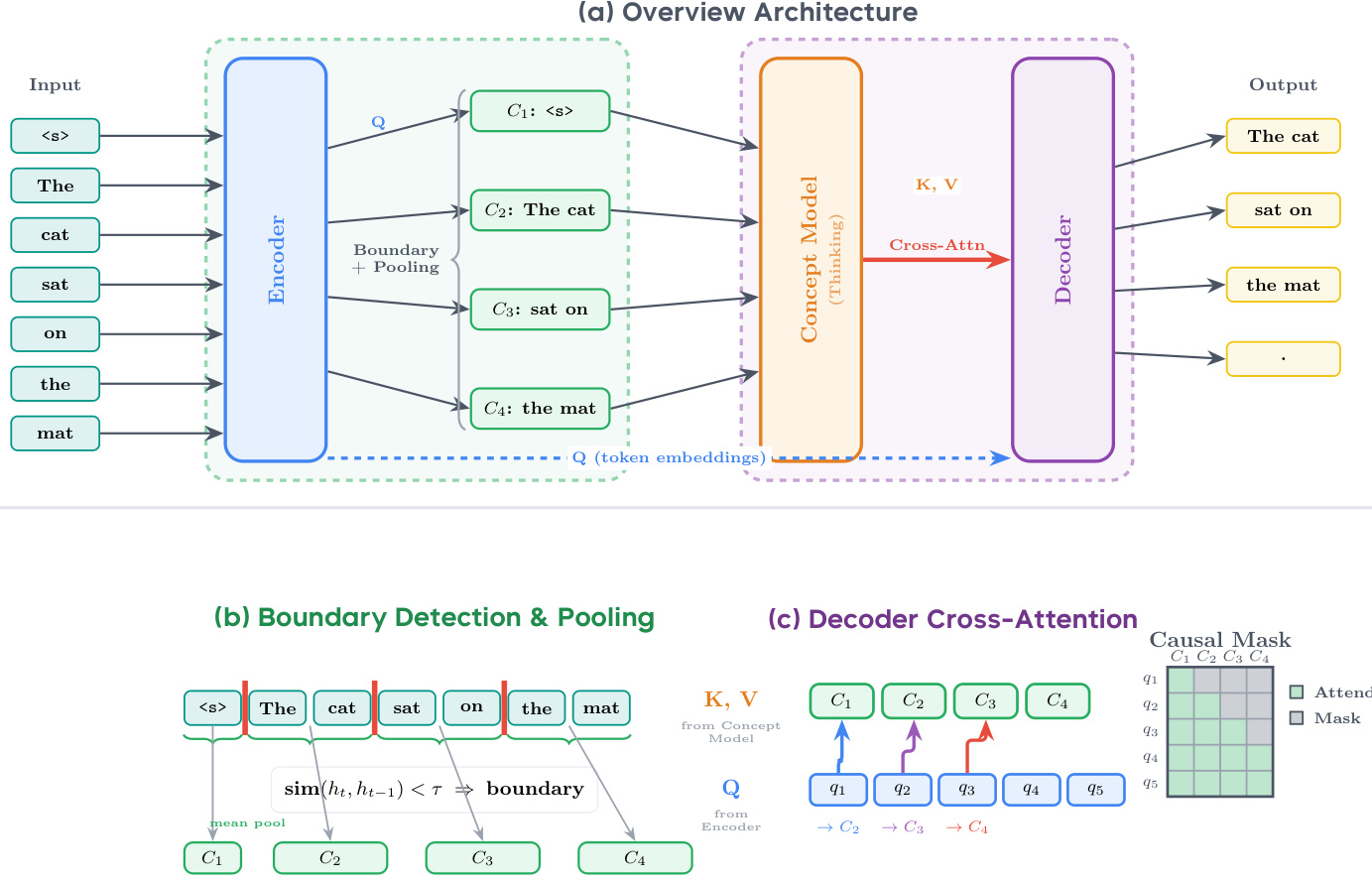
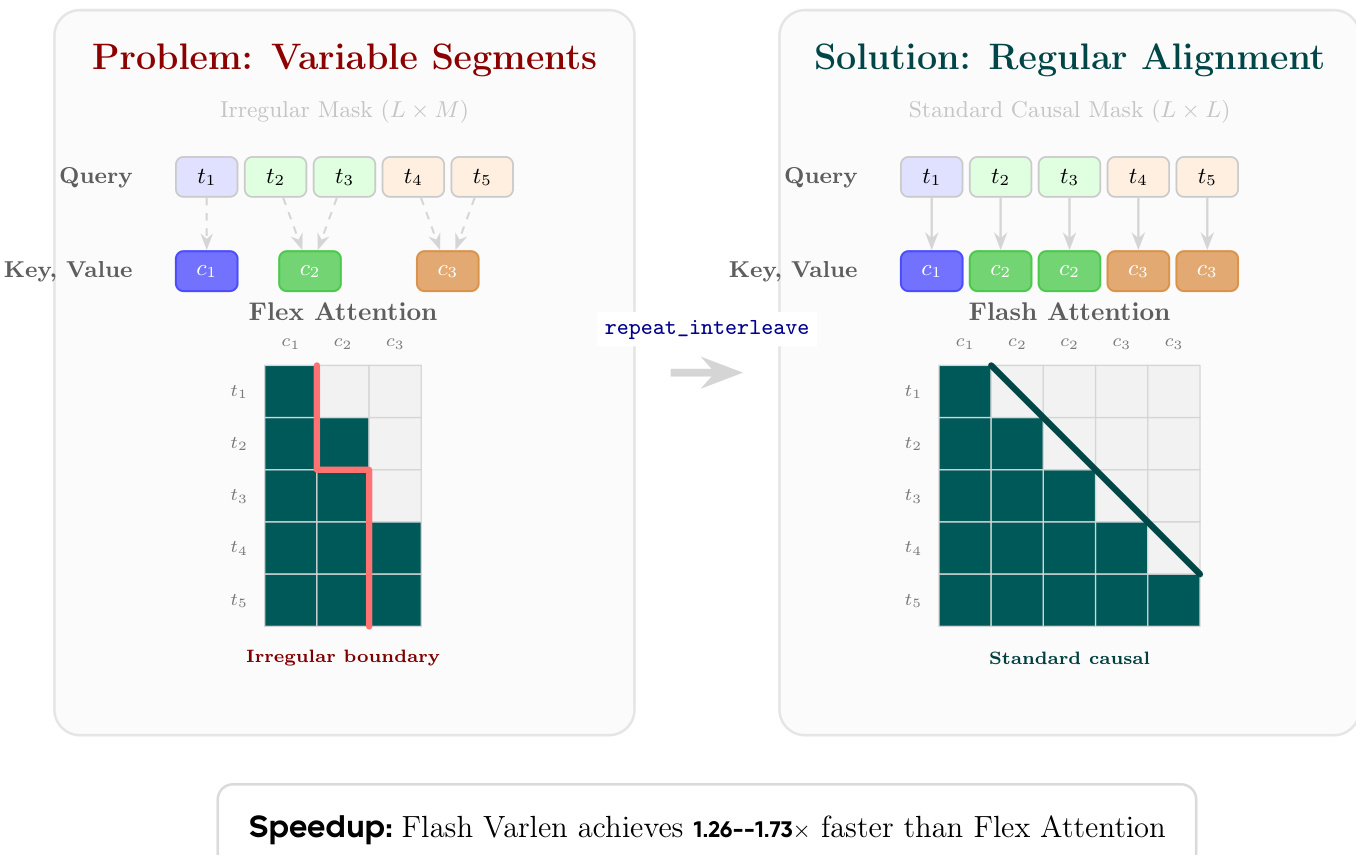
解码器的交叉注意力机制中出现了一个关键的实现挑战,即token必须关注具有可变长度映射的概念,这会导致不规则的注意力模式。如下图所示,这导致了一个不规则的掩码,对硬件加速效率低下。为了解决这个问题,作者采用了一种概念复制策略,通过repeat_interleave扩展概念特征以匹配token序列长度。这种转换使键和值序列与查询序列对齐,从而能够使用高度优化的Flash Attention with Variable Length (Varlen)内核,该内核将问题视为一种特殊形式的自注意力,其中每个概念段内的键和值是局部恒定的。这种方法比直接使用Flex Attention实现显著提速。
训练目标结合了next-token预测损失和用于全局负载平衡的辅助损失,该辅助损失在整个分布式批次上强制执行目标压缩比。为了确保大规模下的稳定训练和最佳性能,作者将最大更新参数化(μP)适配到其异构架构中,根据各自的宽度解耦token级组件和概念级主干的学习率和初始化方差。这种解耦的μP使得超参数可以从一个小的代理模型零样本迁移到更大的规模,证实了其在稳定不等宽模型训练方面的有效性。
实验
- 性能基准验证了概念复制策略的效率,表明其始终优于Flex Attention,速度提升从1.26x到1.73x不等。性能优势随序列长度增加而扩大,在16K序列时高达1.73x,而对隐藏层维度大小不敏感。
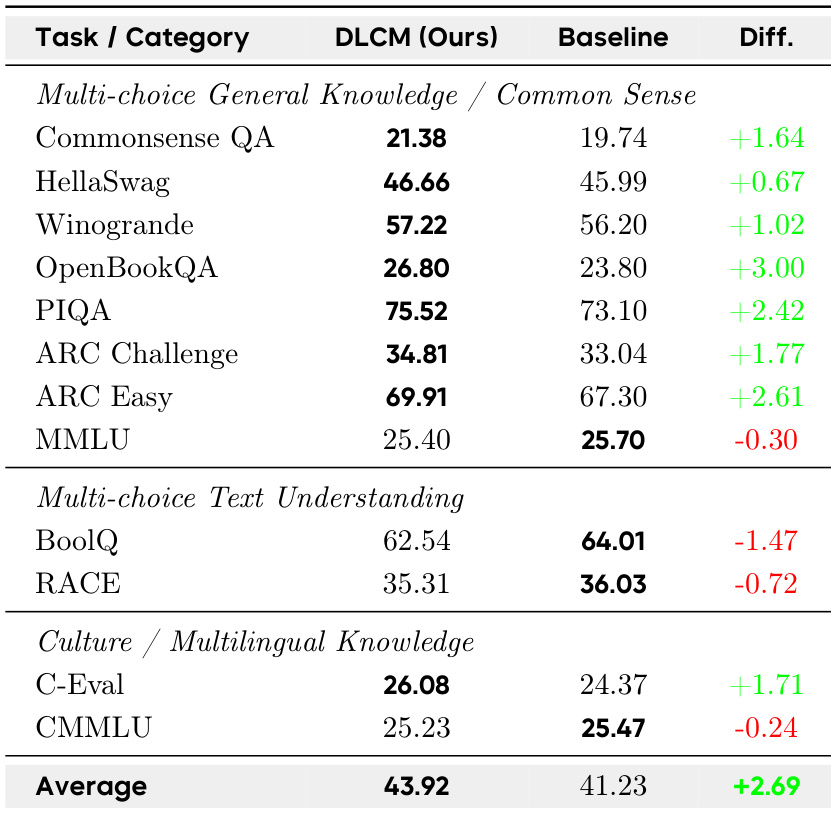
- 主要结果将DLCM与参数匹配的LLaMA基线进行比较。在12个零样本基准测试中,DLCM的平均准确率达到43.92%,比基线高出+2.69%。增益集中在推理主导的任务上,而在细粒度理解基准上出现轻微回退。尽管参数量几乎是基线的两倍,DLCM的推理FLOPs与较小的基线相当。
- 架构效率分析验证了选择压缩比R=4,提供了训练稳定性和计算效率之间的最佳平衡。
- 损失分布分析揭示了一种“U形”模式,其中概念模型在语义边界表现出色,但在内部位置牺牲了一些细粒度精度,验证了将计算重新分配到结构上显著区域的策略。
- 边界学习分析比较了学习的神经预测器和基于规则的预测器。基于规则的预测器表现出 superior 的稳定性,收敛到目标压缩比,而学习的预测器由于冲突的优化目标而遭受不稳定性。
- 内容自适应压缩分析证实,模型将分割粒度适应于语义密度,将代码压缩成更短的单元,同时为密集的散文保留更长的块,从而在全局预算内最大化信息保留。
作者在12个零样本基准测试上将DLCM与参数匹配的LLaMA基线进行比较,显示DLCM的平均准确率为43.92%,而基线为41.23%,提升了+2.69%。性能提升在推理主导的任务上最为明显,如OpenBookQA (+3.00%) 和ARC Easy (+2.61%),而在细粒度文本理解任务如BoolQ (-1.47%) 和RACE (-0.72%) 上出现轻微回退,反映了模型在全局连贯性和token级精度之间的权衡。
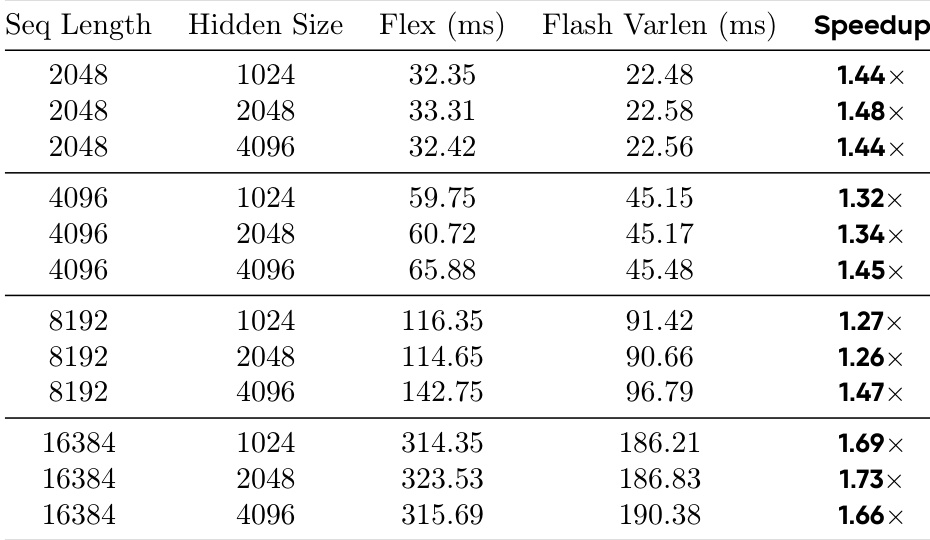
作者使用表5分析了其模型在不同内容类型上的自适应压缩行为,该表显示了在2×、4×和8×目标压缩比下每个概念的平均token数。结果表明,模型根据语义密度动态调整分割粒度,技术英语在每个概念中保留更多token(在8×时为10.58),而代码或技术中文(分别为6.14和6.09),这证明了内容自适应压缩在密集散文中能更有效地保留信息,同时在结构化内容中实现更紧凑的压缩。
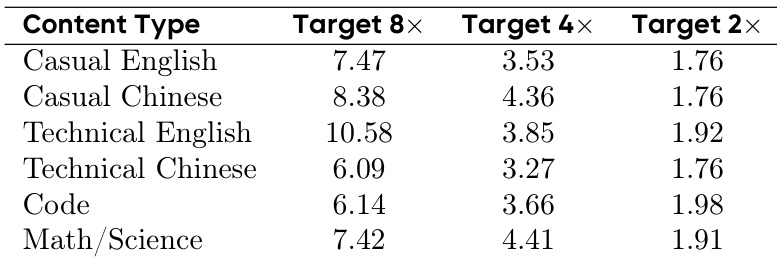
作者使用独立的内核分析,对不同序列长度和隐藏大小下,使用概念复制的Flash Attention Varlen与Flex Attention的效率进行了基准测试。结果表明,Flash Varlen始终优于Flex Attention,速度提升范围从1.26×到1.73×,并且性能优势随序列长度增加而增加,在序列长度为16K、隐藏大小为2048时达到峰值1.73×。速度提升在很大程度上对隐藏大小不敏感,表明内存访问模式而非计算复杂度主导了性能瓶颈。
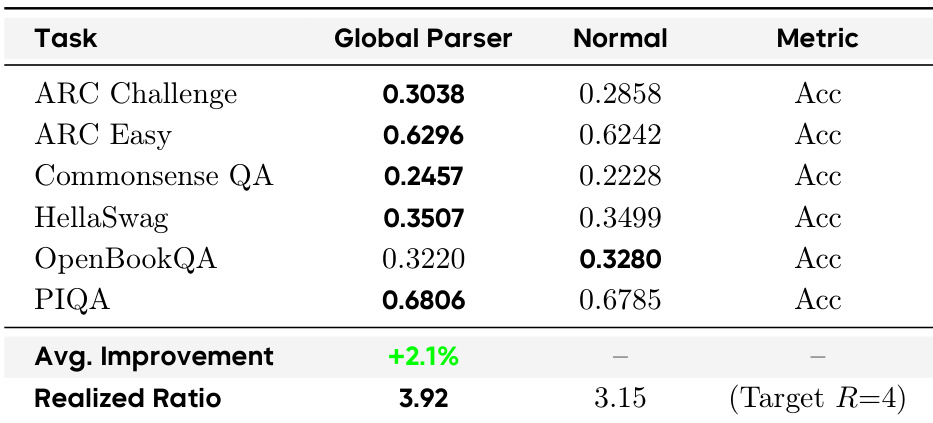
作者比较了DLCM中的两种边界预测机制:Global Parser和Normal(学习的)预测器,两者都以R=4为目标压缩比。结果显示,Global Parser实现的压缩比为3.92,更接近目标,并在推理主导的基准测试中平均准确率提升+2.1%,优于Normal预测器,后者的实现压缩比为3.15,并且在大多数任务上准确率较低。