Command Palette
Search for a command to run...
FlowBlending:面向快速高保真视频生成的阶段感知多模型采样
FlowBlending:面向快速高保真视频生成的阶段感知多模型采样
Jibin Song Mingi Kwon Jaeseok Jeong Youngjung Uh
摘要
在本工作中,我们发现模型容量的影响随时间步的不同而变化:在早期和晚期阶段至关重要,而在中间阶段则影响甚微。基于此,我们提出FlowBlending,一种具有阶段感知能力的多模型采样策略。该策略在容量敏感阶段(即早期和晚期)使用大模型,在中间阶段则使用小模型。我们进一步引入了简单的判别准则以确定阶段边界,并提出速度-发散性分析(velocity-divergence analysis)作为识别容量敏感区域的有效代理指标。在LTX-Video(2B/13B)和WAN 2.1(1.3B/14B)两个基准上,FlowBlending在保持大模型的视觉保真度、时序连贯性和语义一致性的同时,实现了最高达1.65倍的推理加速,并减少了57.35%的浮点运算量(FLOPs)。此外,FlowBlending与现有采样加速技术具有良好的兼容性,可进一步带来最高达2倍的性能提升。项目主页详见:https://jibin86.github.io/flowblending_project_page。
一句话总结
延世大学的研究者提出FlowBlending,一种阶段感知的多模型采样策略,将大模型分配给早期和晚期去噪阶段以保证结构和细节保真度,将小模型用于中间阶段(此时模型容量差异影响较小),在不牺牲视觉质量且兼容现有加速方法的前提下,将FLOPs降低57.35%,推理速度提升最高达1.65倍。
主要贡献
- 视频扩散模型中,不同时间步的模型容量重要性并非均匀:早期阶段需要大模型建立全局结构与语义对齐,晚期阶段则受益于大模型对高频细节的精细化处理,而中间阶段大模型与小模型之间的性能差异极小。
- FlowBlending引入一种阶段感知的多模型采样策略,动态地将大模型分配给对容量敏感的早期和晚期阶段,小模型用于中间阶段,利用语义相似性和速度发散作为实际标准识别最优阶段边界,无需重新训练。
- 在LTX-Video(2B/13B)和WAN 2.1(1.3B/14B)上评估,FlowBlending实现最高1.65倍的推理加速和57.35%的FLOPs减少,同时保持与大模型相当的视觉保真度、时间连贯性和语义对齐性,并与现有加速技术兼容,可进一步提升效率。
引言
研究者基于一个观察:视频扩散模型中的所有去噪阶段并不要求同等的模型容量,从而挑战了时间步上统一使用模型的常见假设。在基于扩散的视频生成中,大模型能提供更优的视觉保真度和时间连贯性,但计算成本高昂;小模型虽高效,却难以保证语义准确性和细节保留。以往的加速方法或减少采样步数,或进行模型蒸馏,但均对所有时间步一视同仁,且常需重新训练。本文主要贡献为FlowBlending,一种阶段感知的多模型采样策略:仅在早期和晚期去噪阶段使用大模型(用于建立全局结构和精细细节),而在中间阶段使用小模型(此时模型间速度发散最小)。该方法无需重新训练、蒸馏或架构改动,即可实现最高1.65倍的推理加速和57.35%的FLOPs减少,同时保持与大模型几乎相同的质量。该方法辅以基于语义相似性和细节质量的实用启发式规则指导模型分配,且与现有加速技术正交,可进一步提升效率。
方法
研究者提出一种阶段感知的多模型采样策略,称为FlowBlending,以在保持高质量输出的同时优化视频生成的计算效率。该方法基于一个核心观察:模型容量在去噪过程的不同阶段具有不同的重要性。具体而言,早期阶段对建立全局结构至关重要,晚期阶段则对精细细节的优化尤为关键,而中间阶段对模型容量的降低具有较强容忍度。
该框架通过动态分配计算资源实现优化:在对容量敏感的早期和晚期阶段使用大模型,在中间阶段使用小模型。这种调度策略在显著降低计算开销的同时,实现了与大模型近乎等效的性能。如图所示,该方法在质量与效率之间实现了良好平衡,大模型用于去噪轨迹的起始和末端,小模型负责中间阶段。

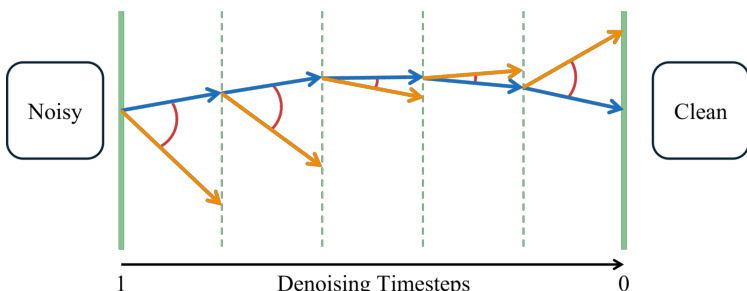
FlowBlending的设计进一步受到速度发散分析的启发,该分析可有效作为识别去噪过程中容量敏感区域的代理指标。该分析有助于确定早期、中间和晚期阶段之间的最优边界。研究者利用此标准定义阶段转换,确保模型切换发生在去噪过程动态最受益于容量变化的时刻。
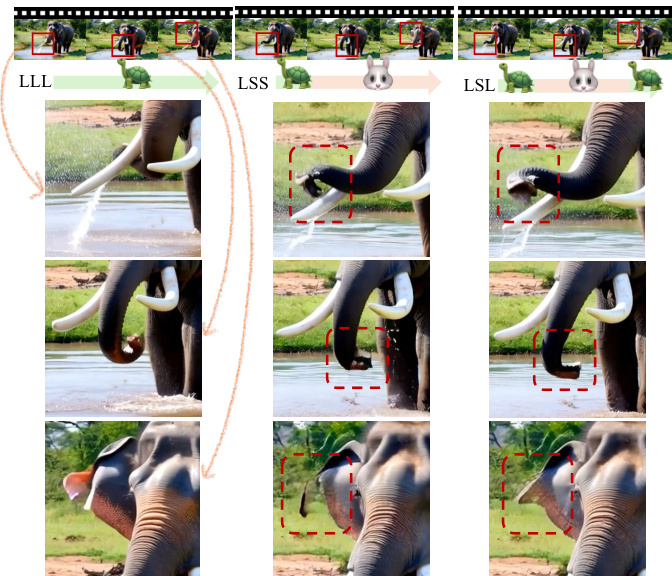
该方法在多种模型配置下进行了评估,包括LTX-Video(2B/13B)和WAN 2.1(1.3B/14B),显著提升了推理速度和FLOP效率。结果表明,FlowBlending在保持与大模型相当的视觉保真度、时间连贯性和语义对齐性的同时,实现了最高1.65倍的推理加速和57.35%的FLOPs减少。该方法还与现有采样加速技术兼容,可进一步提升速度。

其内在机制通过轨迹分析得以说明:去噪过程被表示为从噪声输入到干净输出的路径。速度发散分析识别出大模型与小模型轨迹显著发散的区域,表明这些阶段对模型容量敏感。这些区域被用于定义模型切换的边界。
实验
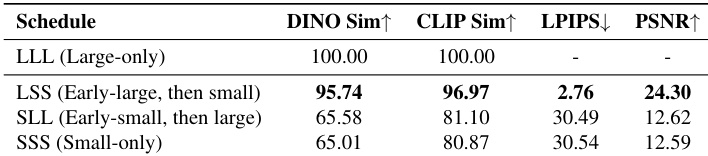
- 早期结构形成:仅在早期去噪步骤使用大模型(LSS)可保持与大模型全用(LLL)相当的全局结构、运动连贯性和语义对齐性,而仅用小模型(SSS)或早期使用小模型(SLL)的方案均失败,表明早期阶段对建立高层属性至关重要。在PVD和VBench上,LSS的DINO和CLIP相似度达到LLL的96%以内,证实了语义保真度。
- 晚期精细化:在最后几步重新引入大模型(LSL)可有效减少高频伪影并提升细节质量,FID得分显著低于LSS。在LTX-Video和WAN 2.1上,LSL的FID和FVD得分几乎与LLL无法区分,表明晚期阶段对伪影抑制和细粒度优化具有容量敏感性。
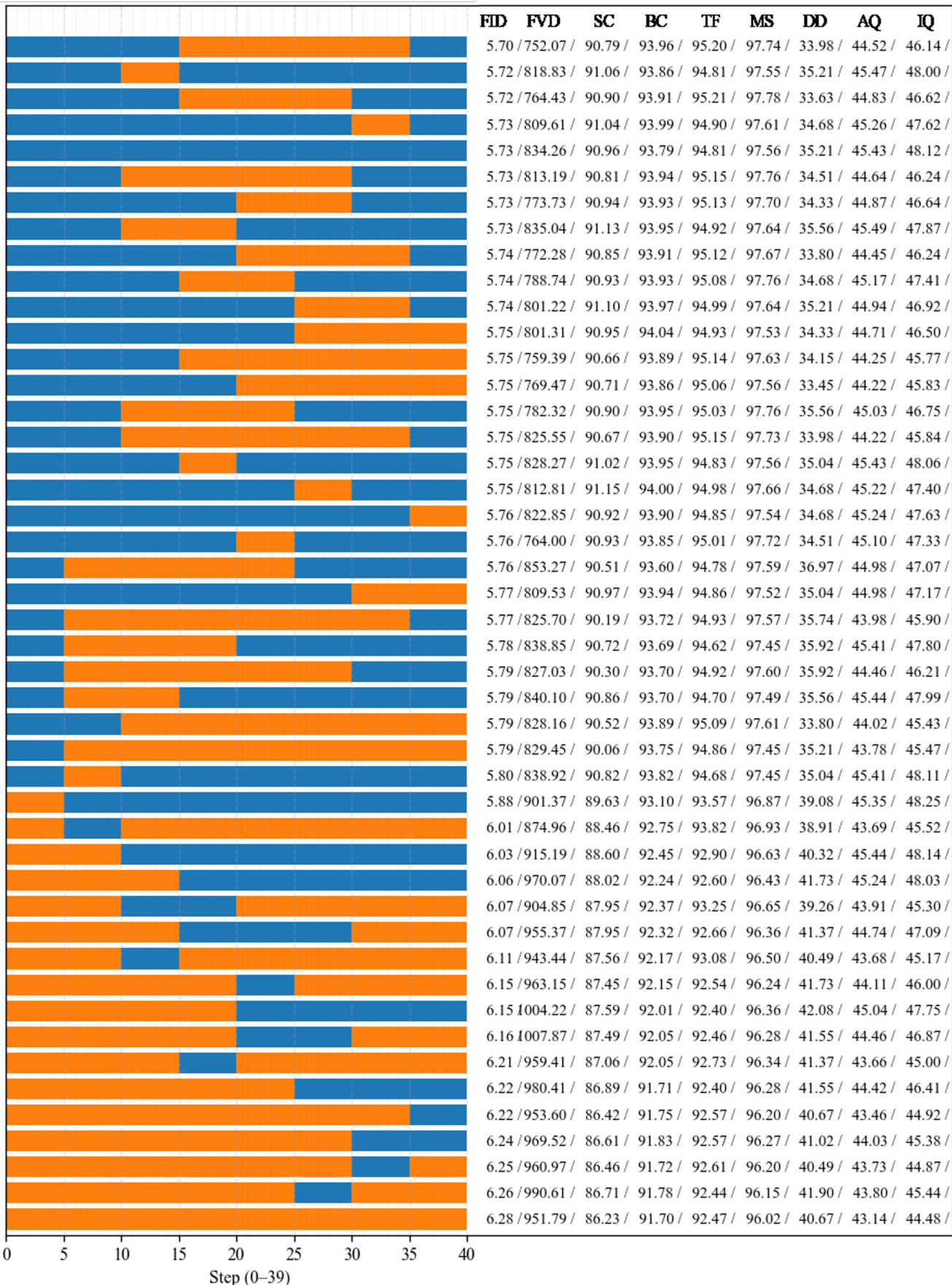
- 核心结果:所提出的LSL方案相比LLL实现最高1.65倍的推理加速和57.35%的FLOPs减少,同时在FID、FVD及VBench指标(美学质量、主体一致性、运动平滑性)上保持与大模型几乎相同的质量,优于LSS(保留结构但引入伪影)和SSS(所有指标均下降)。
结果表明,LSL方案(在早期和晚期使用大模型,中间阶段使用小模型)在所有指标上实现的视频质量几乎与大模型全用基线(LLL)无法区分,同时显著降低计算成本。相比之下,LSS方案虽保留全局结构,但无法消除晚期伪影;SSS方案在质量和一致性上均出现显著退化。

研究者采用一种阶段感知的采样策略,仅在早期和晚期去噪阶段使用大模型,中间步骤使用小模型,以平衡计算效率与视频质量。结果表明,该方法(尤其是LSL方案)在多个指标上性能几乎与大模型全用基线无异,同时显著降低运行时间和FLOPs。
研究者采用一种阶段感知的采样策略,在早期和晚期去噪阶段使用大模型,中间阶段使用小模型,实现的视频质量几乎与大模型全用基线无异,同时显著降低计算成本。结果表明,早期阶段对建立全局结构和语义对齐至关重要,晚期阶段对细节优化和伪影抑制不可或缺,两个阶段均对模型容量敏感。
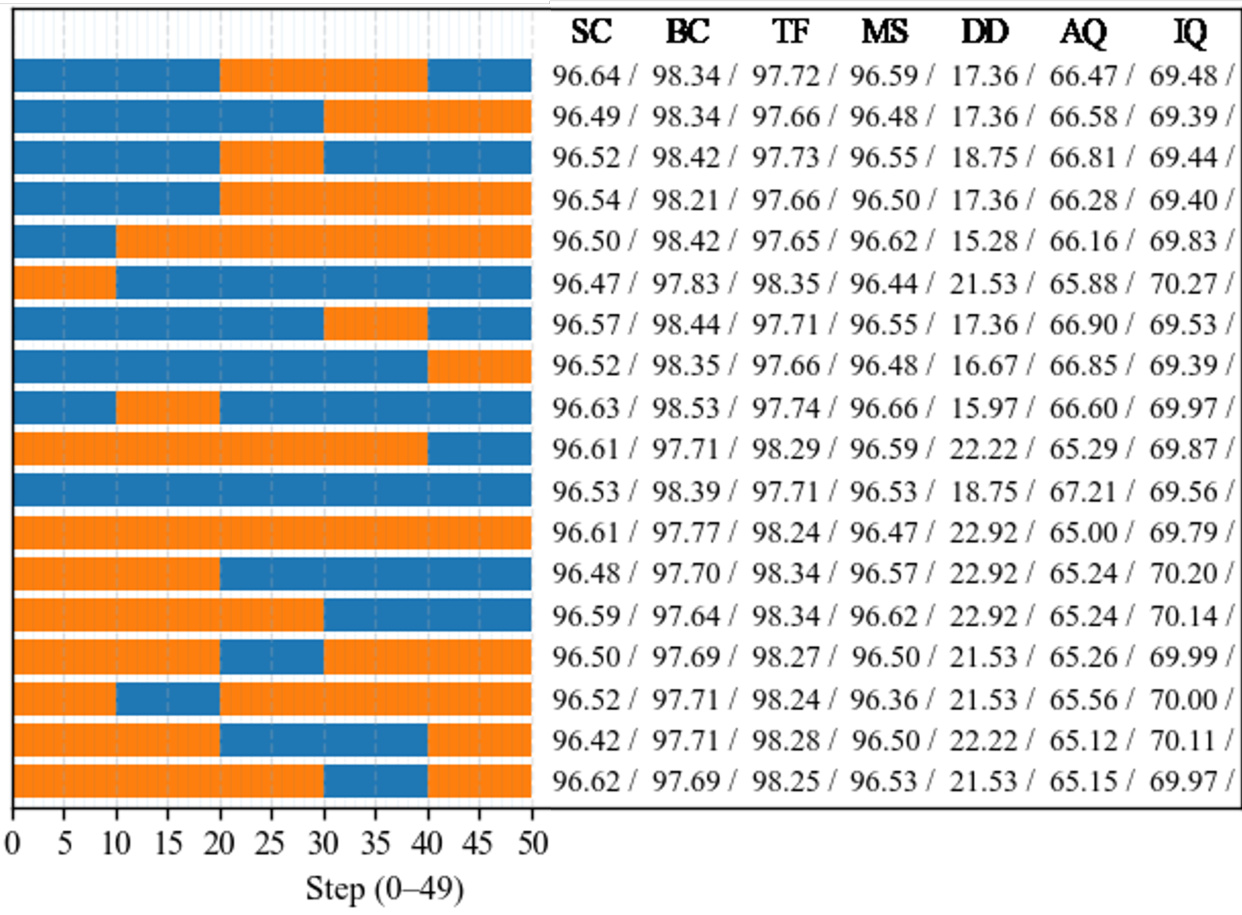
结果表明,LSL(阶段感知,本文方法)方案在所有指标(包括FID、FVD和感知质量)上均与大模型全用基线(LLL)几乎完全一致,同时显著降低运行时间和计算成本。相比之下,SSS(仅小模型)方案在质量上出现显著退化,尤其在FVD和运动连贯性方面,凸显大模型在早期和晚期阶段对维持结构与语义保真度的关键作用。

结果表明,LSS方案(仅在早期去噪步骤使用大模型)在语义和低层指标上与大模型全用基线(LLL)保持高度相似,表明早期阶段的模型容量对建立全局结构和运动特性至关重要。相比之下,SSS和SLL方案(在早期阶段延迟或省略大模型使用)相似度显著降低,表明早期结构错位无法在后期恢复。