Command Palette
Search for a command to run...
Dream2Flow:基于3D物体流连接视频生成与开放世界操控
Dream2Flow:基于3D物体流连接视频生成与开放世界操控
Karthik Dharmarajan Wenlong Huang Jiajun Wu Li Fei-Fei Ruohan Zhang
摘要
生成式视频建模已成为一种强有力的工具,可用于在开放世界操作任务中对合理的物理交互进行零样本推理。然而,如何将人类主导的运动行为转化为机器人系统所需的底层动作,仍是当前面临的一大挑战。我们观察到,在给定初始图像和任务指令的情况下,这类模型在合成合理物体运动方面表现出色。为此,我们提出Dream2Flow框架,通过将三维物体运动流(3D object flow)作为中间表示,实现视频生成与机器人控制之间的桥梁。我们的方法从生成的视频中重建三维物体运动,并将操作任务建模为物体轨迹跟踪问题。通过将状态变化与实现这些变化的执行器相分离,Dream2Flow有效克服了具身鸿沟(embodiment gap),从而实现了从预训练视频模型到多种类别物体(包括刚体、铰接体、可变形体及颗粒状物体)的零样本操控引导。借助轨迹优化或强化学习,Dream2Flow可将重建的三维物体运动流转化为可执行的底层控制指令,且无需针对特定任务提供示范数据。仿真与真实世界实验均表明,三维物体运动流是一种通用且可扩展的接口,能够有效将视频生成模型适配至开放世界的机器人操作任务中。相关视频与可视化结果详见:https://dream2flow.github.io/。
一句话总结
斯坦福大学的研究人员介绍了 Dream2Flow,这是一个通过从生成视频中提取 3D 物体流作为中间表示,从而连接视频生成与机器人控制的框架。与以往模仿刚性人类动作的方法不同,Dream2Flow 将期望的状态变化与机器人的特定本体解耦,利用现成的视频模型和视觉工具,实现了对刚性、铰接、可变形和颗粒状等多种物体的零样本操作,且无需特定任务的演示。
关键贡献
- 该论文解决了利用视频生成模型进行开放世界机器人操作的挑战,这些模型通常难以弥合人类动作与机器人动作空间之间的本体差距。论文提出,这些模型可用作视觉世界模型来预测物理上合理的物体交互,从而将期望的状态变化与所需的具体执行器分离开来。
- 该论文引入了 Dream2Flow,这是一种新颖的方法,使用 3D 物体流作为中间接口来连接视频生成与机器人控制。该方法利用深度估计和点跟踪从生成的视频中重建 3D 物体轨迹,提供了一个独立于机器人本体的清晰跟踪目标。
- 作者展示了一个自主流程:生成任务视频,提取 3D 物体流,并通过轨迹优化或强化学习合成机器人动作。这种方法有效利用了视频模型丰富的先验知识来指导操作,而无需直接模仿人类动作,清晰地将任务的“做什么”与“怎么做”分离开来。
引言
作者解决了指定机器人操作任务的挑战,以往的方法范围从僵化的符号形式主义到复杂的基于学习的策略。用自然语言指定任务更直观但可能有歧义,而视觉-语言-动作模型通常与特定的机器人本体绑定。为了解决这些问题,作者介绍了 Dream2Flow,一种利用视频生成模型创建视觉计划的方法。他们利用这些模型根据初始图像和语言指令生成视频,然后从该视频中提取 3D 物体流来表示期望的物体运动。这种 3D 流作为一个稳健、与本体无关的接口,用于规划精确的操作动作。然而,该方法目前受限于其刚性抓取假设、对单视角视频的依赖(在处理遮挡时很吃力)以及较长的处理时间。
数据集
数据集构成与来源
该数据集包含用于多样化操作任务的视频-语言数据,包括 "Push-T"、"Open Door" 和 "In-the-Wild" 任务,如 "Pull Out Chair" 和 "Sweep Pasta"。
- 任务提示: 任务描述以文本提示的形式提供。对于 "In-the-Wild" 任务,这些提示包含具体的成功标准,例如将椅子移动至少 5cm 或将抽屉打开到其总延伸长度的 90%。
- 数据生成: 作者使用生成式视频模型,如 Veo 3 和 Kling 2.1,根据这些提示创建视频数据。
- 稳健性与特殊措辞: 为了提高稳健性,提示包含变体,例如用 "donut" 替换 "bread"。为了引导生成模型,提示包含 "by one hand" 等短语以帮助抓取选择,以及 "the camera holds a still pose" 以最小化相机运动,这对于下游深度估计流程至关重要。
子集的关键细节
- Push-T 任务:
- 来源: 使用文本提示和显示 T 块起始和结束位置的目标图像生成。
- 筛选: Veo 3 模型因不支持端帧输入(生成此特定任务精确运动的必要条件)而被排除在此任务的实验之外。
- Open Door 任务:
- 来源: 从模拟环境的文本提示生成。
- 处理: 提示指定动作由无手执行且相机保持静止。对于 Kling 2.1,在生成过程中添加了 0.7 的相关性值和一个负向提示。
- In-the-Wild 任务:
- 来源: 此子集包含四个不同的任务:"Pull Out Chair"、"Open Drawer"、"Sweep Pasta" 和 "Recycle Can"。
- 构成: 每个任务由特定的物体和目标定义,例如用刷子将意面推入堆肥箱或将罐子放入回收箱。
数据使用与处理
作者使用这个生成的数据集来训练他们的模型 Dream2Flow。
- 训练集: 数据用于训练集。
- 混合比例: 论文未指定不同任务数据的混合比例。
- 处理: 视频数据经过处理以提取深度信息,这依赖于提示中的 "camera holds a still pose" 条件。视频中手的位置也被用来帮助选择物体上的正确抓取点。对于 "Push-T" 任务,使用了粒子动力学模型,该模型以特征增强的粒子作为输入来预测运动。
方法
作者利用一个模块化流程,将来自现成视频生成模型的高层视觉预测与低层机器人动作连接起来,实现零样本开放世界操作。核心思想是提取 3D 物体流——物体运动的中间表示——作为以人类为中心的视频模型的视觉想象与机器人物理执行之间的桥梁。这种方法将环境中的期望状态变化与机器人的特定本体和运动学约束解耦。
如下图所示,该流程始于一个文本条件的视频生成模型,该模型根据初始的 RGB-D 观察和自然语言指令,合成一个描绘人类执行请求任务的帧序列。然后对生成的视频进行处理以提取 3D 物体流。这包括使用单目视频深度估计器估计每帧深度,该估计器被校准到机器人的初始深度观察以解决尺度模糊。同时,使用一个基础模型定位任务相关的物体,并生成二值掩码。从该掩码中采样一组 2D 点,并使用点跟踪模型在视频中进行跟踪,产生 2D 轨迹和可见性标志。这些 2D 轨迹使用校准的深度和相机内参提升到 3D,最终得到一个在机器人坐标系中表示为时间序列点轨迹的 3D 物体流。
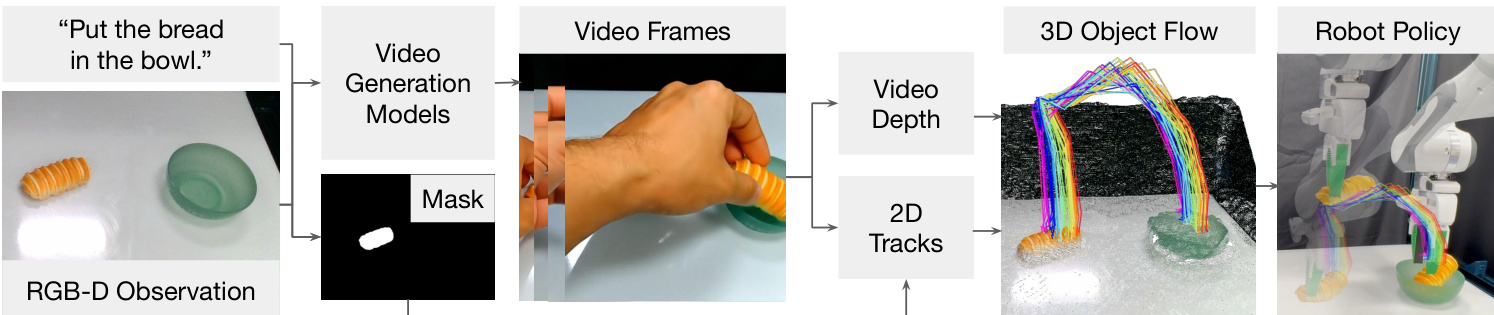
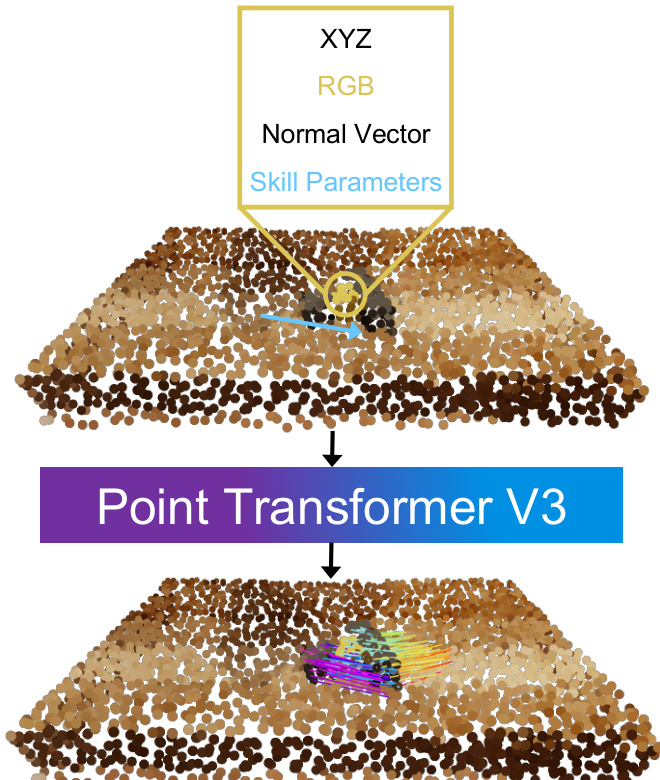
提取的 3D 物体流作为动作推理的目标。机器人的任务是操纵物体,使其 3D 点轨迹紧密跟随生成的流。这被表述为一个优化问题,其目标是最小化任务成本(衡量预测物体点与目标流之间的距离)和控制成本(惩罚不良的机器人运动,如关节极限违规或抖动运动)之和。动力学模型和动作空间根据领域而变化。在模拟的非抓取任务(如推动)中,一个学习的基于粒子的动力学模型根据接触点、方向和距离参数化的推动技能预测下一个状态。在真实世界领域,机器人使用绝对末端执行器姿态作为动作,并且一个刚性抓取动力学模型假设被抓取的部分随末端执行器移动。对于像开门这样的铰接任务,使用 3D 物体流作为奖励信号来训练强化学习策略,引导机器人在不同本体上再现期望的运动。
该框架还包括用于稳健执行的专用模块。对于抓取选择,系统使用手部检测模型来识别生成视频中拇指的位置,并选择最接近该位置的抓取点,确保机器人与视频中人类交互的是物体的同一部分。对于铰接物体,一个过滤步骤通过分析跟踪点的平均像素位移来识别物体的可移动部分,并使用来自分割模型的掩码将 2D 流约束在可移动部分上,防止在静止组件上出现跟踪错误。优化过程通过使用来自视频流的中间子目标(而不仅仅是最终状态)来进一步完善,以指导重规划并避免大的旋转误差。

在模拟的 Push-T 领域,系统采用随机射击法采样多个推动参数,使用学习的动力学模型预测 resulting 的物体运动,并选择使得到当前子目标成本最小的动作。在真实世界设置中,使用 PyRoki 执行优化,包含可达性、平滑性和可操作性成本。 resulting 的末端执行器轨迹使用 B 样条进行平滑,并通过逆运动学求解器和关节阻抗控制器执行。对于开门任务,系统使用软演员-评论家 (Soft Actor-Critic) 训练一个感知运动策略,其中奖励源自 3D 物体流,鼓励机器人在跟踪参考轨迹的同时保持在物体附近。
实验
- Dream2Flow 作为视频-控制接口:该系统在五个真实世界和模拟操作任务(例如 Push-T, Open Oven)上进行了验证。它展示了对物体实例和背景变化的鲁棒性,并且可以在同一场景中适应不同的语言目标。然而,真实世界执行失败主要由视频生成伪影和跟踪错误引起。
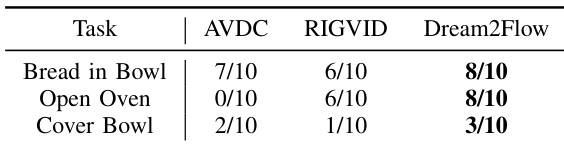
- 与替代接口的比较:在真实机器人任务上,Dream2Flow 优于 AVDC 和 RIGVID。它通过跟踪 3D 物体流而不是刚性变换,更有效地处理可变形物体和部分遮挡。
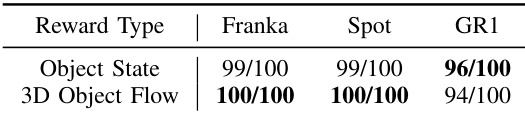
- 3D 物体流作为策略奖励:3D 物体流是训练强化学习策略的有效奖励信号。使用此奖励训练的策略在不同机器人本体(Franka Panda, Spot, GR1)上与使用手工制作的状态奖励的策略表现相当。
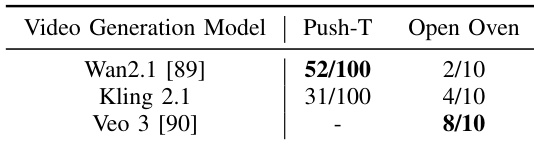
- 视频模型的影响:性能取决于领域。Wan 2.1 在模拟任务(如 Push-T)中表现出色,而 Veo 3 在真实世界任务(如 Open Oven)中表现最佳。其他模型可能会遭受物体变形或不正确的铰接。
- 动力学模型的影响:基于粒子的动力学模型对于需要旋转的任务至关重要。它显著优于基于姿态或启发式的替代模型。
作者将 Dream2Flow 与两种基于视频的替代接口 AVDC 和 RIGVID 在三个真实世界任务上进行了比较:Bread in Bowl, Open Oven, 和 Cover Bowl。结果显示 Dream2Flow 在所有任务中都优于这两种方法,在 Bread in Bowl 和 Open Oven 中达到 8/10 的成功率,在 Cover Bowl 中达到 3/10 的成功率,而 AVDC 和 RIGVID 的成功率较低,特别是在涉及可变形物体或点可见性不足的任务中。
作者在模拟的 Push-T 任务上评估了不同动力学模型的影响,比较了基于姿态的、启发式的和基于粒子的模型。结果显示,基于粒子的动力学模型实现了 52/100 的成功率,显著优于基于姿态(12/100)和启发式(17/100)的模型,证明了逐点预测对于准确捕捉物体旋转和运动的重要性。

作者评估了 3D 物体流作为训练强化学习策略的奖励的有效性,涉及三个不同的机器人本体:Franka Panda, Spot, 和 GR1。结果显示,使用 3D 物体流奖励训练的策略达到了与使用手工制作的物体状态奖励训练的策略相当的性能,Franka 和 Spot 的成功率为 100/100,GR1 为 94/100,表明 3D 物体流可以作为一种可行且可泛化的奖励信号用于学习感知运动策略。
作者评估了不同视频生成模型对 Dream2Flow 在模拟和真实世界任务中性能的影响。结果显示,Wan2.1 在模拟的 Push-T 任务中表现最好,100 次中有 52 次成功,而 Veo 3 在真实世界的 Open Oven 任务中取得了最高的成功率,10 次中有 8 次成功,表明 Veo 3 在真实世界设置中能更好地捕捉物理上合理的物体轨迹。