Command Palette
Search for a command to run...
基于FusionRoute的Token级LLM协作
基于FusionRoute的Token级LLM协作
Nuoya Xiong Yuhang Zhou Hanqing Zeng Zhaorun Chen Furong Huang Shuchao Bi Lizhu Zhang Zhuokai Zhao
摘要
大型语言模型(LLMs)在多个领域展现出强大的能力。然而,要使单一通用模型在这些领域均达到优异性能,通常需要将其规模扩展至训练和部署成本极高的程度。相比之下,虽然小型领域专用模型具有更高的效率,但其泛化能力往往受限于训练数据分布,难以超越其训练范围。为解决这一困境,我们提出FusionRoute——一种稳健且高效的基于标记(token-level)的多LLM协作框架。该框架采用轻量级路由机制,在每个解码步骤中同时实现两个功能:(i)选择最合适的专家模型;(ii)生成一个互补的logit(对数几率),通过logit相加的方式对所选专家的下一个标记分布进行精细化修正。与现有仅依赖固定专家输出的token级协作方法不同,我们提供了理论分析,表明纯粹依赖专家输出的路由机制在本质上存在局限:除非满足强全局覆盖假设,否则一般无法实现最优解码策略。通过引入可训练的互补生成器以增强专家选择过程,FusionRoute显著扩展了有效策略的表达能力,并在较弱条件下即可恢复最优价值函数。在实证方面,FusionRoute在Llama-3与Gemma-2两大模型系列上,于涵盖数学推理、代码生成和指令遵循等多样化的基准测试中,均显著优于现有的序列级与token级协作方法、模型融合技术以及直接微调方法。同时,其在各任务上的表现仍能与领域专家模型相媲美,展现出卓越的综合性能与泛化能力。
一句话总结
Meta AI、卡内基梅隆大学、芝加哥大学和马里兰大学的作者提出了FusionRoute,这是一种基于标记级别的多大语言模型协作框架,能够在训练轻量级路由器的同时动态选择领域特定专家,并提供互补的logits以进行优化。与以往仅依赖专家输出的方法不同,FusionRoute通过可训练的修正机制扩展了策略类别,理论上克服了纯专家路由的根本局限性,在数学、编程和指令遵循等任务上实现了稳健、高效且通用的性能,而无需联合训练或架构兼容性。
主要贡献
- 现有的标记级别多大语言模型协作方法受限于对固定专家输出的依赖,通常无法在缺乏强全局覆盖假设的情况下实现最优解码策略,导致在多样化任务上表现欠佳。
- FusionRoute引入了一种新颖的标记级别协作框架,其中轻量级路由器不仅在每一步选择最合适的专家,还生成可训练的互补logits,通过logits相加方式对专家输出进行优化,扩展了有效策略类别,并在温和条件下实现最优价值函数的恢复。
- 实证结果表明,FusionRoute在Llama-3和Gemma-2系列模型上,于数学推理、代码生成和指令遵循等基准测试中,优于序列级别和标记级别协作方法、模型融合以及直接微调方法,同时在各自任务上达到与领域专用专家相当的性能。
引言
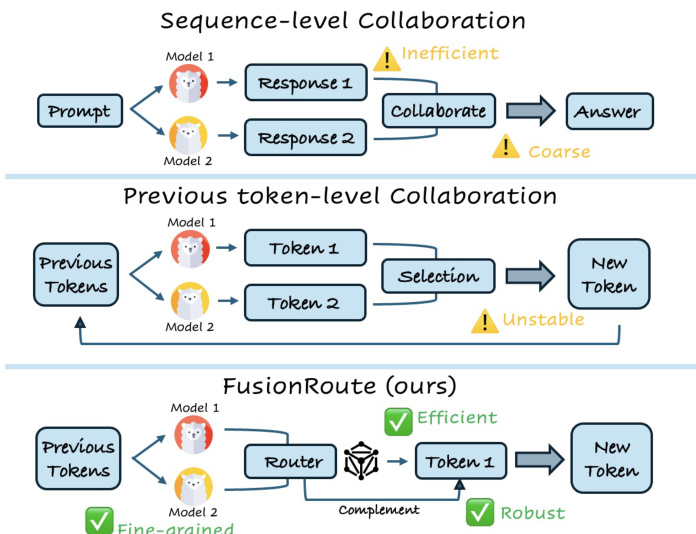
大语言模型(LLMs)在特定领域表现出色,但面临泛化能力与效率之间的权衡——大型通用模型训练和部署成本高昂,而小型专用模型在训练分布之外缺乏鲁棒性。以往方法如专家混合(MoE)和模型融合需要联合训练、架构兼容性或梯度访问,限制了灵活性;多智能体系统通常在粗粒度序列层面运行,导致效率低下和性能下降。标记级别协作方法提供了更精细的控制,但其脆弱性在于完全依赖专家输出,缺乏纠正或优化决策的机制。作者提出FUSIONROUTE,一种轻量级、标记级别的多大语言模型协作框架,利用可训练的路由器在每一步同时选择最合适的专家并生成互补logits以优化下一个标记的分布。这一双重机制将策略空间扩展至固定专家输出之外,使在温和条件下恢复最优行为成为可能。实证结果表明,FUSIONROUTE在多种基准测试中优于现有序列级和标记级方法、模型融合及微调方法,同时在各自任务上达到领域专家水平——实现高性能而无需训练或架构约束。
方法
作者提出了FusionRoute,一种旨在实现多个专用语言模型之间稳健高效协作的标记级别协作框架。其核心架构围绕一个轻量级路由器模型展开,该模型从基础语言模型后训练而来,以标记级别运行,为每个生成步骤选择最合适的专家,同时提供互补的logits信号。这种双重功能使FusionRoute既能利用专家模型的领域专长,又能在专家输出不确定或不可靠时进行纠正或优化。
参考框架图。整个流程从一个提示和一系列已生成的标记开始。路由器模型处理此上下文并生成两个输出:一个路由权重向量,用于从一组专用模型中确定首选专家;以及一组作为互补修正信号的logits。路由权重通过在基础模型最终隐藏状态上应用轻量级线性投影生成。推理过程中,路由器选择路由权重最高的专家,并通过logits相加将该专家的logits与路由器的互补logits结合,形成最终的下一个标记分布。该组合分布随后被贪婪地用于生成下一个标记,确保最终输出既受益于专家的专业知识,也受益于路由器的自适应优化。
FusionRoute路由器的训练采用分阶段且解耦的过程,包括监督微调(SFT)阶段和偏好优化阶段。SFT阶段旨在建立两个基础属性:准确的下一个标记预测和可靠的标记级别专家选择。该阶段联合优化基础模型参数和路由投影,使用标准语言建模损失与路由损失的组合。路由损失特别设计用于关注专家意见分歧的有意义标记位置,从而防止路由器被平凡的一致性模式主导。最终的SFT目标是语言建模损失与路由损失的加权和。
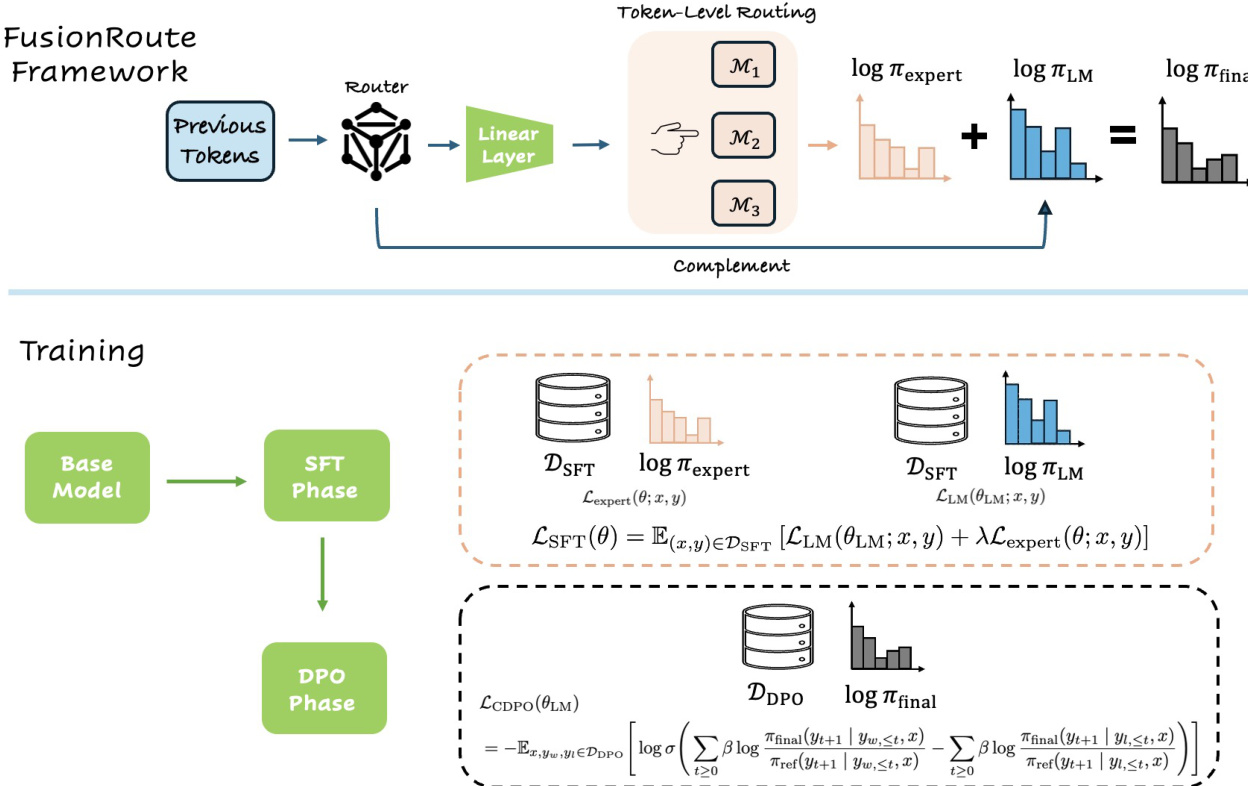
偏好优化阶段采用修改后的DPO目标,仅作用于基础模型参数以优化最终策略。为保留SFT阶段学习到的专家选择能力,路由投影在此优化中被排除。这种解耦策略可防止路由层过度拟合偏好对齐信号,从而丧失正确选择专家的能力。训练过程进一步通过混合训练方案增强,将偏好优化数据与监督SFT数据联合混合,确保基础模型与路由层之间的一致性。这种两阶段训练策略使路由器在保持可靠专家选择的同时,获得有效的互补logits贡献。
实验
- 在Llama-3和Gemma-2系列模型上,将FUSIONROUTE与序列级别协作、标记级别协作、模型融合及微调单模型进行对比评估。
- 在跨领域基准测试(GSM8K、MATH500、MBPP、HumanEval、IfEval)中,FUSIONROUTE在两个模型系列上均取得最高平均性能,超越所有基线方法,并在单个任务上达到或超过领域专用专家水平。
- 在保留的通用数据集上,FUSIONROUTE的GPT-4o胜率显著高于微调基线,表明其在流畅性、对齐性和格式化方面具有更优的整体响应质量。
- 在更大的8B模型上,FUSIONROUTE与基线之间的性能差距进一步扩大,表明互补路由在模型规模增大时愈发有益,而仅依赖专家的协作则性能下降。
- 消融研究证实,路由器的互补logits贡献至关重要:移除该机制导致性能显著下降,尤其在编程和指令遵循任务中。
- CDPO训练阶段至关重要——采用CDPO的FUSIONROUTE显著优于仅SFT的变体,表明偏好优化能有效纠正专家失败并提升整体响应质量。
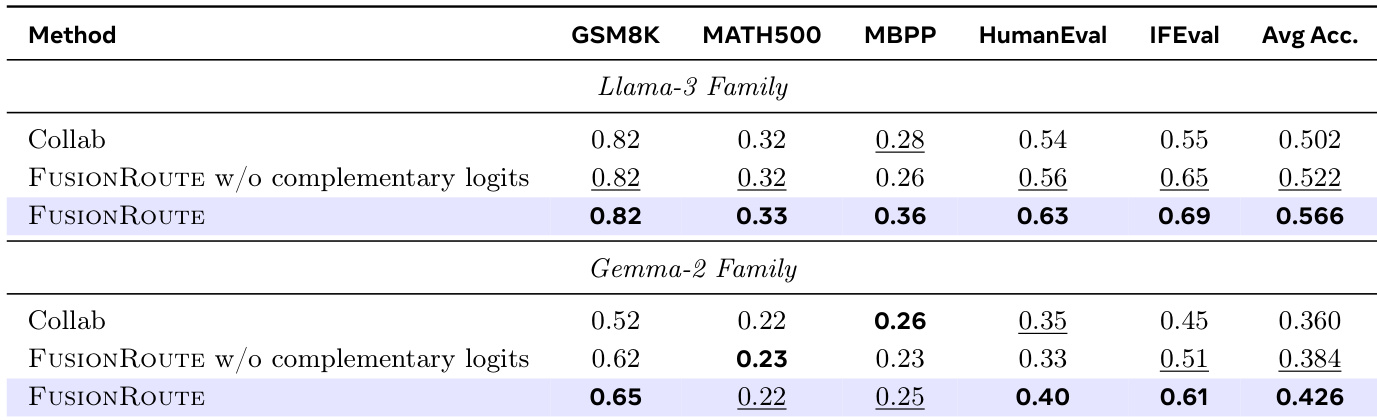
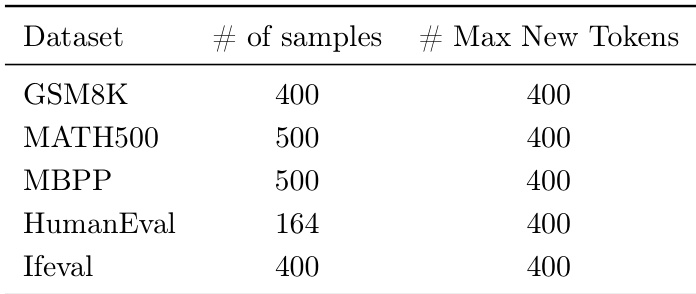
作者在五个跨领域基准测试(GSM8K、MATH500、MBPP、HumanEval和IfEval)上评估FUSIONROUTE,每个数据集选取子集样本,每轮生成最多400个新标记。结果表明,FUSIONROUTE在Llama-3和Gemma-2系列模型的所有领域中均取得最高平均性能,持续优于依赖序列级协作、标记级协作、模型融合和微调模型的基线方法。
作者使用FUSIONROUTE评估多个模型和协作方法的跨领域性能,结果显示其在Llama-3和Gemma-2系列模型上始终取得最高平均准确率。结果表明,FUSIONROUTE优于序列级协作、标记级协作、模型融合及微调基线,证明其在选择领域适配专家的同时,仍能保持在通用任务上的强性能。
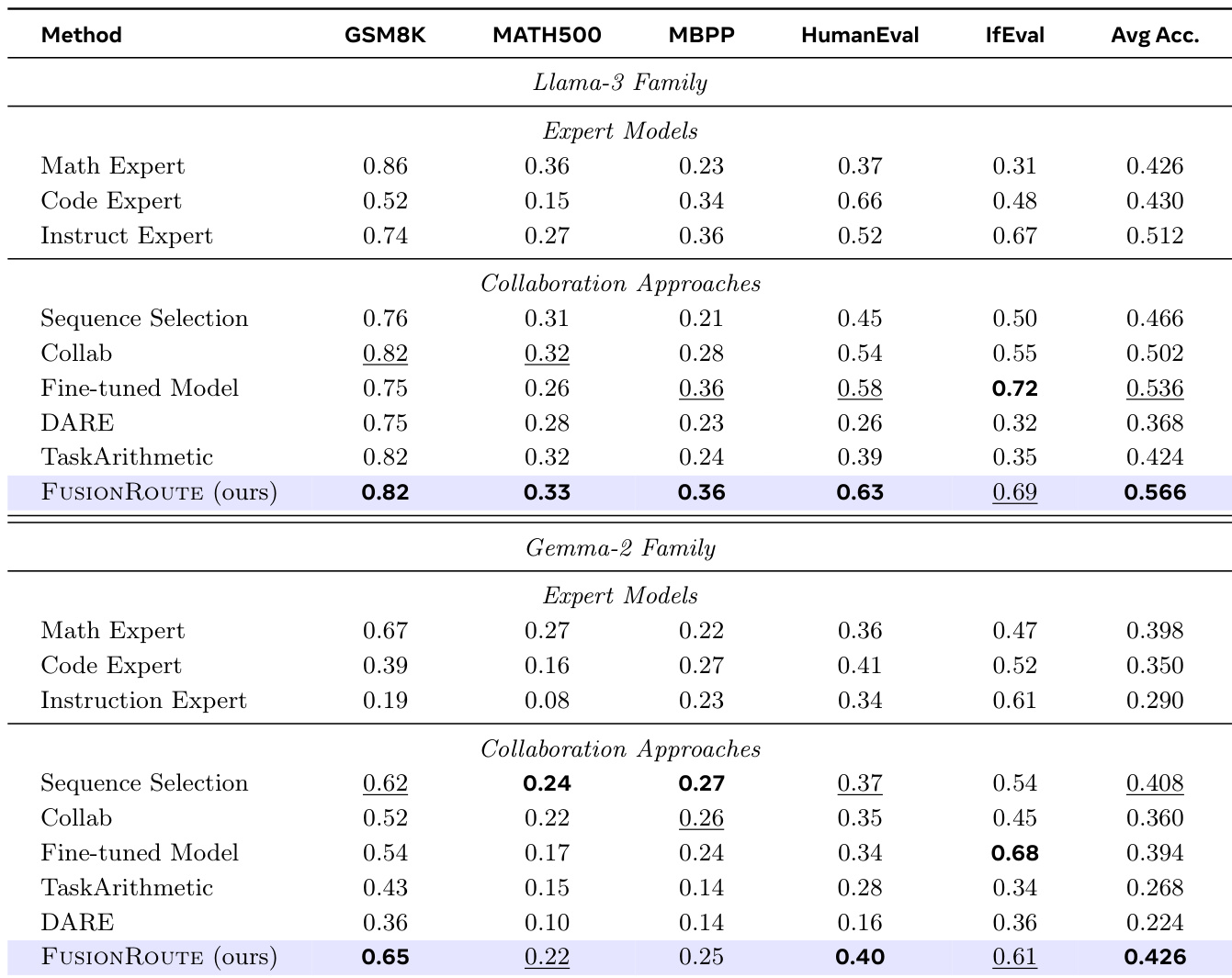
作者通过跨领域评估将FUSIONROUTE与基线方法在Llama-3和Gemma-2系列模型上进行对比,结果显示FUSIONROUTE在所有任务上均取得最高平均准确率。结果表明,FUSIONROUTE持续优于其他方法,包括标记级协作和模型融合,并在单个基准测试上达到或超过专家模型水平。