Command Palette
Search for a command to run...
VideoAuto-R1:通过一次思考,两次作答实现视频自动推理
VideoAuto-R1:通过一次思考,两次作答实现视频自动推理
摘要
思维链(Chain-of-Thought, CoT)推理已成为多模态大语言模型在视频理解任务中的一项有力工具。然而,其相对于直接作答的必要性与优势尚未得到充分探讨。本文首先表明,对于经过强化学习(RL)训练的视频模型而言,尽管CoT推理在计算成本上更高,且能够生成逐步分析过程,但直接作答往往能达到甚至超越CoT的性能表现。受此启发,我们提出VideoAuto-R1——一种基于“按需推理”策略的视频理解框架。在训练阶段,该方法采用“一次思考,两次作答”的范式:模型首先生成初始答案,随后进行推理过程,最终输出经过审校的修订答案。两个答案均通过可验证的奖励信号进行监督。在推理阶段,模型根据初始答案的置信度分数,自动判断是否需要启动推理流程。在多个视频问答(Video QA)与视频定位(grounding)基准测试中,VideoAuto-R1实现了当前最优的准确率,同时显著提升了运行效率,平均响应长度减少约3.3倍(例如,从149个token降至仅44个token)。此外,我们观察到:在以感知为主的任务中,模型激活“推理模式”的频率较低;而在需要深度推理的任务中,该模式的使用率则明显提高。这一现象表明,显式的语言化推理在大多数情况下具有实际益处,但并非在所有场景下都为必要。
一句话总结
Meta AI、KAUST 和普林斯顿大学提出 VideoAuto-R1,一种视频理解框架,采用“思考一次,回答两次”的范式,模型先生成初始答案,再进行有依据的复核,两者均通过可验证奖励进行监督。推理时,基于置信度的早期退出机制动态激活推理,仅在必要时进行,使平均响应长度减少 3.3 倍,同时在视频问答和定位基准测试中达到最先进准确率,表明显式推理虽有益,但并非总是必需。
主要贡献
- 现有的视频理解链式思维(CoT)方法通常带来高昂的计算成本,且并未持续提升准确率,因为强化学习训练的模型在感知导向任务中常能通过直接回答达到相当或更优性能。
- 本文提出 VideoAuto-R1,一种“思考一次,回答两次”的框架,训练模型先生成初始答案,再进行推理并输出修正答案,两者均通过可验证奖励监督,实现高效、自适应推理,无需显式“思考/不思考”标签。
- 在视频问答和定位基准测试中,VideoAuto-R1 达到最先进准确率,同时平均响应长度减少约 3.3 倍(从 149 降至 44 个 token),推理时基于置信度的早期退出机制可动态决定是否仅输出直接答案,仅在必要时激活推理。
引言
作者利用多模态大语言模型在视频理解中链式思维(CoT)推理的最新进展,其中显式分步推理已成为标准。然而,他们识别出一个关键局限:对于许多视频任务——尤其是感知导向任务——CoT 推理带来的准确率提升微乎其微,却显著增加计算成本和响应长度,因冗长重复的解释。分析表明,直接回答常能匹配甚至超越 CoT 性能,挑战了“扩展推理普遍有益”的假设。为解决此问题,作者提出 VideoAuto-R1,采用“思考一次,回答两次”的训练范式:模型先生成初始答案,再进行推理,最后输出优化答案,两者均通过可验证奖励监督。推理时,基于置信度的早期退出机制动态决定是否提前终止(直接输出答案)或继续推理,实现自适应、高效的推理。该方法在视频问答和定位基准测试中均达到最先进准确率,同时平均响应长度减少约 3.3 倍,证明推理应仅在必要时应用。
数据集

- 数据集包含文本、图像和视频模态,来自多个来源,以支持多模态推理。
- 文本推理基于 DAPO-Math(Yu 等,2025),图像推理基于 ViRL(Wang 等,2025a)和 ThinkLite-Hard(Wang 等,2025c),视频问答基于 Video-R1(Feng 等,2025)、TVBench(Cores 等,2024)、STI-Bench(Li 等,2025c)和 MMR-VBench(Zhu 等,2025)。
- 为强化时序定位和基于定位的问答,作者引入 Charades-STA(Gao 等,2017)、ActivityNet(Fabian 等,2015)、Time-R1(Wang 等,2025d)和 NExT-GQA(Xiao 等,2024)。
- 所有评估基准的测试样本均手动排除,以防止数据泄露,初始样本池约 137K。
- 应用过滤流水线精炼数据集:使用数学验证(math-verify)去除数学问题的无效真实标签,使用基于规则的检查去除问答的无效样本。
- 对每个剩余的问答样本,使用基础模型 Qwen2.5-VL-7B-Instruct 以高温度生成 8 个响应。
- 使用较小的 LLM Qwen3-30B-A3B-Instruct 评估每个响应并标记为正确或错误。
- 所有 8 个响应均正确(太简单)或均错误(太难)的样本被丢弃,因其对基于 GRPO 的强化学习价值有限。
- 此难度过滤仅应用于问答任务;时序定位样本全部保留,以应对基础模型的定位能力不足。
- 过滤后,最终训练集包含 83K 样本,详见表 10。
- 数据在训练中以多模态和多任务混合方式使用,过滤后的 83K 样本构成核心训练集。
- 图像和视频未进行裁剪;元数据基于任务类型、模态和来源构建,以支持训练与评估。
方法
作者提出一种新颖框架 VideoAuto-R1,旨在使视频推理模型仅在必要时进行推理,从而提升效率与训练稳定性。整体架构如框架图所示,包含一个根据问题生成响应的策略模型,随后是强化学习(RL)训练循环,以及推理时的基于置信度的早期退出机制。该框架遵循“推理应为事后验证过程,而非强制初始步骤”的原则。
训练阶段,模型采用组相对策略优化(GRPO),一种近期的强化学习方法,用组归一化的规则奖励替代学习的评判器。如框架图所示,策略模型为给定提示 q 采样 G 个候选输出。每个输出 oi 由奖励函数评估,计算可验证奖励 ri,如答案准确率或格式正确性。这些奖励随后通过组内均值 μ 和标准差 σ 归一化,得到相对优势 Ai。训练目标为一个裁剪目标函数,最大化期望优势,同时通过 KL 惩罚对策略进行正则化,防止其偏离参考策略。该训练过程应用于双答案输出格式,每个响应包含初始答案、推理理由和复核答案。
训练数据经过精心筛选,以增强长链推理能力。数据涵盖高质量的文本与图像来源,覆盖数学与科学问题,以及视频问答和时序定位数据。值得注意的是,训练过程直接采用强化学习,跳过通常昂贵且可能降低性能的冷启动监督微调(SFT)阶段。模型在 83K 样本数据集上训练,主要目标是学习生成简洁的初始答案和更准确的复核答案。
训练输出格式严格定义为 \boxed{a_1} \text{ </tool_call> } r \text{ </tool_call> } \boxed{a_2},其中 a1 和 a2 为简短、可验证的答案,r 为自由格式的理由。该格式通过精心设计的系统提示强制执行,使模型能在单次生成中输出直接答案与 CoT 答案,无需冷启动 SFT。对于初始答案不可行的复杂问题,提供备用字符串“Let's analyze the problem step by step”。当模型输出该字符串时,强制其继续生成推理与最终答案。
奖励函数设计用于监督初始答案与复核答案。总奖励为第一答案的任务奖励 Rtask(1)(a1)、第二答案的任务奖励 Rtask(2)(a2)、格式正确性奖励 Rfmt 与备用奖励 Rfallback 的加权和。权重 w1 与 w2 设置为 w2>w1,优先保证复核答案的正确性。备用奖励为二元奖励,仅当模型正确使用备用字符串并生成正确最终答案时给予,鼓励在难题中诚实放弃。
推理阶段,模型采用基于置信度的早期退出机制,决定是否继续推理。生成初始答案 a1 后,模型基于 a1 中 token 的对数概率计算长度归一化的置信度分数 s(a1)。若该分数超过预设阈值 τ,模型终止解码并返回 a1;否则继续生成理由与复核答案 a2。该机制可实现准确率与效率之间的可控权衡,阈值 τ 可调节以平衡两者。推理策略总结于算法 1,概述了生成初始答案、计算置信度、决定是否提前退出或继续推理的步骤。框架图展示了该过程:模型先生成初始答案,计算其置信度,最终决定是否提前退出或继续进入思考与复核答案阶段。
实验
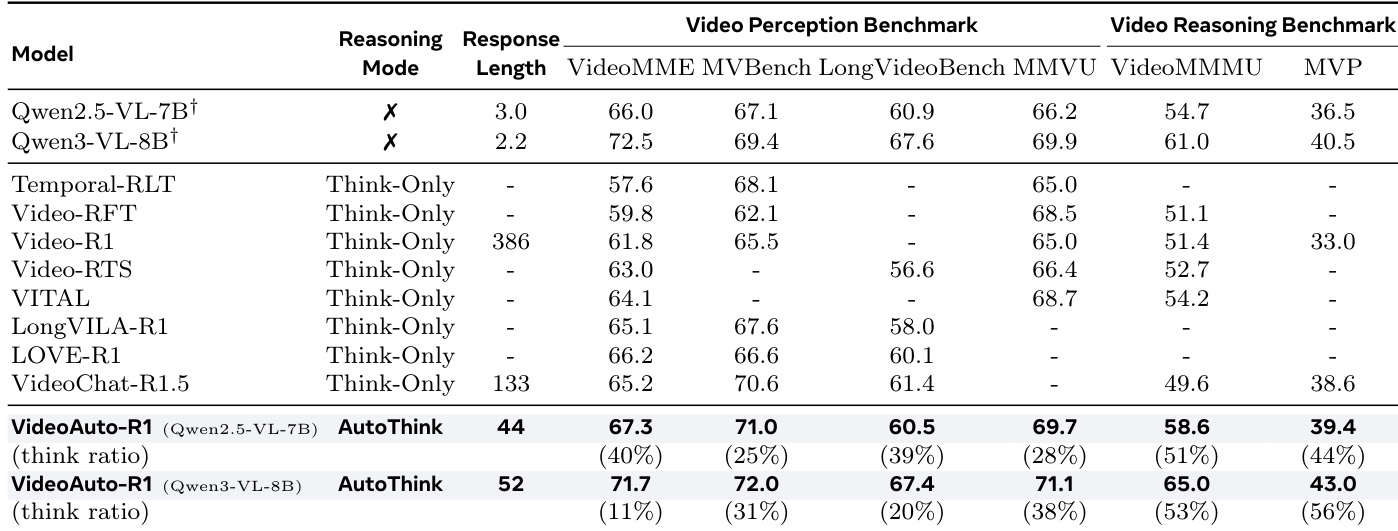
- VideoAuto-R1 在视频问答基准测试中达到最先进结果:在 VideoMME(Qwen2.5-VL)上准确率达 67.3%,分别超越 Video-R1、VITAL 和 VideoChat-R1.5 5.5%、3.2% 和 2.1%;在 Video-MMMU 上达 58.6%(较基线提升 3.9%),在 MVP 上达 39.4% 成对准确率(较先前模型提升 2.9%)。
- 在推理密集型基准测试中,VideoAuto-R1 提升准确率的同时,平均响应长度从 149 token(带思考的 RL)降至 44 token,Video-MMMU 上思考比例为 51%,感知任务如 MVBench 上仅为 25%。
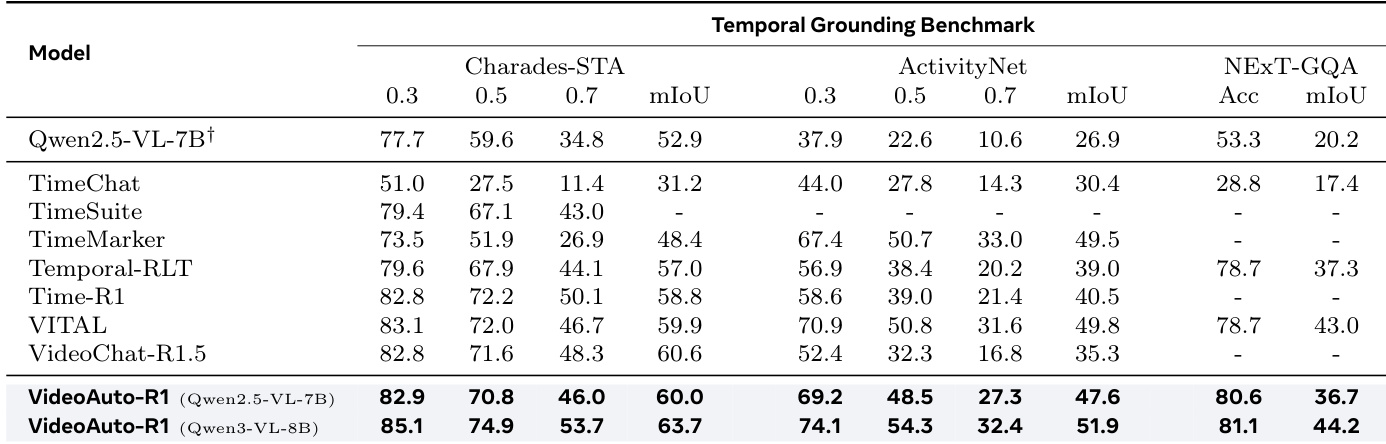
- 在时序定位任务中,初始答案已足够实现准确定位;无需进一步推理的早期退出保持性能不变(如 ActivityNet 和 NExT-GQA 上 mIoU 未变),显著提升推理效率。
- 消融实验确认,双答案奖励设计(w₂ > w₁)与备用奖励(α)提升准确率,基于置信度的早期退出有效将推理导向困难任务,在 Video-MMMU 上带来 4.0% 的准确率提升。
- 数据过滤提升性能与训练效率,文本、图像与视频数据的综合使用效果最佳,去除过于简单或困难的样本始终提升性能。
- 无 CoT SFT 的冷启动 RL 优于 SFT 训练,因低质量 CoT 监督会降低模型性能,验证了直接强化学习的有效性。
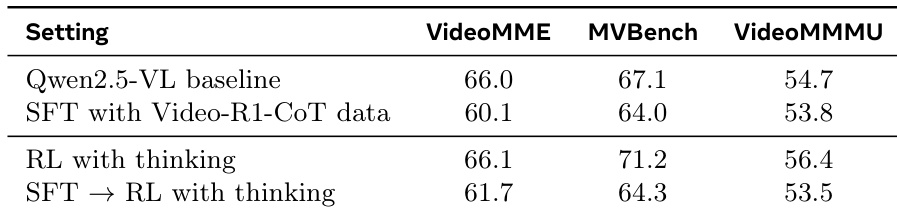
作者在 Qwen2.5-VL 基线模型上比较不同训练策略,显示使用 Video-R1-CoT 数据进行直接 SFT 会降低所有基准测试的性能。带思考的 RL 在感知与推理任务上优于基线,而 SFT → 带思考的 RL 方法在 VideoMME 与 MVBench 上表现最佳,但在 VideoMMMU 上表现较差。
作者使用基于 Qwen2.5-VL-7B 的 VideoAuto-R1 模型,在图像推理基准测试中评估其性能。结果表明,VideoAuto-R1 在所有测试基准上均优于 Qwen2.5-VL-7B 基线,准确率提升范围从 MathVista 的 4.3% 到 MM-Vet 的 10.9%,证明其自动推理机制在推理任务中的有效性。

结果表明,VideoAuto-R1 在时序定位基准测试中对不同推理策略表现出一致性能,第一答案与第二答案在 mIoU 或准确率上无显著差异。模型的基于置信度的早期退出机制能有效选择初始答案而无需进一步推理,在保持高准确率的同时提升推理效率。

作者使用 VideoAuto-R1 模型,该模型基于置信度自适应触发推理,实现了在感知与推理类视频问答基准测试中的最先进结果。结果表明,VideoAuto-R1 在推理密集型任务(如 VideoMMMU 和 MVP)上显著优于现有仅思考模型,同时保持更短的平均响应长度,证明其高效性与有效性。
结果表明,VideoAuto-R1 在时序定位基准测试中达到最先进性能,超越 Time-R1 和 VITAL 等先前模型,在多个指标上表现更优。模型的初始框式预测已足够实现准确定位,进一步推理仅提供解释性价值,未提升性能,支持使用早期退出以增强推理效率。