Command Palette
Search for a command to run...
基于地图的思维:用于地理定位的强化并行地图增强型Agent
基于地图的思维:用于地理定位的强化并行地图增强型Agent
Yuxiang Ji Yong Wang Ziyu Ma Yiming Hu Hailang Huang Xuecai Hu Guanhua Chen Liaoni Wu Xiangxiang Chu
摘要
图像地理定位任务旨在仅通过视觉线索,预测一张图像在地球上的拍摄位置。现有的大型视觉-语言模型(LVLM)方法虽利用了世界知识、链式思维推理以及代理(agentic)能力,但忽略了人类在实际中常用的一种策略——使用地图。在本研究中,我们首次为模型引入“地图思维”能力,并将其建模为“地图中的代理”(agent-in-the-map)循环。为此,我们设计了一种两阶段优化方案,包括基于代理的强化学习(agentic reinforcement learning, RL)以及并行测试时扩展(parallel test-time scaling, TTS)。其中,强化学习增强了模型的代理能力,从而提升采样效率;而并行TTS则使模型能够在最终预测前探索多个候选路径,这对地理定位任务至关重要。为在最新且真实场景的图像上评估所提方法,我们进一步构建了MAPBench——一个完全由真实世界图像构成的综合性地理定位训练与评估基准。实验结果表明,我们的方法在多数指标上均优于现有的开源与闭源模型。具体而言,与使用Google搜索/地图信息增强模式的Gemini-3-Pro相比,我们的方法将Acc@500m(500米内准确率)从8.0%显著提升至22.1%。
一句话总结
厦门大学、AMAP(阿里巴巴集团)和南方科技大学的研究人员提出了一种地图感知推理框架——Thinking with Map,该框架将代理强化学习与并行测试时扩展整合到一个循环的“地图中的代理”架构中,以提升图像地理定位性能。通过利用真实世界地图API和多路径探索,该方法显著提高了定位精度——在500米范围内的准确率(Acc@500m)达到22.1%,相比使用地面搜索的Gemini-3-Pro有显著提升,通过新的MAPBench基准在真实场景图像上验证了其有效性。
主要贡献
-
本文针对图像地理定位挑战,提出了一种新颖的“Thinking with Map”框架,使大型视觉语言模型具备利用真实世界地图工具迭代生成并验证位置假设的能力,模拟人类依赖地图验证而非纯内部推理的地理定位策略。
-
提出一种两阶段优化方法:结合代理强化学习以提升采样效率,并采用带有验证器的并行测试时扩展方法,利用地图API输出的自验证特性,同时探索多条推理路径并选择因果一致性最强的一条。
-
该方法在MAPBench上进行评估,这是一个全新的真实世界中国城市街景图像基准,优于现有开源与闭源模型,在500米范围内的准确率(Acc@500m)从Gemini-3-Pro的8.0%提升至22.1%。
引言
图像地理定位——确定图像精确地理位置的任务——已从传统的分类与检索方法演进为利用具备推理能力的大型视觉语言模型(LVLMs)。然而,现有基于LVLM的方法严重依赖内部知识和思维链推理,往往忽视了人类实际使用的策略:通过与地图交互来验证视觉线索。这一差距限制了其在模糊或真实场景图像上的准确性和鲁棒性。本文作者提出一种新框架——Thinking with Map,通过使LVLM能够迭代地利用POI搜索、静态地图查询和空间验证等地图工具生成并验证位置假设,赋予其地图增强的代理能力。为提升性能,作者提出两阶段优化:首先使用代理强化学习优化假设生成,随后采用带有验证器的并行测试时扩展方法,从多条探索路径中选择最一致的轨迹。该方法在MAPBench——一个全新的真实世界中国城市图像基准——上进行评估,优于所有开源与闭源模型,尤其在500米范围内的准确率从8.0%提升至22.1%。
数据集

- 数据集包含MAPBench,一个为解决现有数据集局限性而设计的新地理定位基准,以及两个补充的全球数据集:IMAGEO-2和GeoBench。
- MAPBench包含5,000张以独特兴趣点(POI)为中心的街景或店面图像,均匀采样自中国20个城市,确保广泛地理覆盖和最新内容。
- 每张图像均来自街景或店面照片,按POI随机选取,确保图像新鲜度,避免旧基准中常见的过时或失效POI。
- 数据集划分为2,500个训练样本和2,500个测试样本,测试集进一步根据三个基础模型(GPT-5、GPT-o3、Qwen3-VL-235B-A22B)的零样本预测结果分为易与难两个子集。
- 若至少两个模型预测位置在真实坐标10公里范围内,则该测试样本标记为“易”;否则标记为“难”。最终得到599个易样本和1,901个难样本。
- 易子集用于评估基础模型的记忆能力与预训练世界知识,而难子集则专门测试代理推理能力与使用外部知识的能力。
- IMAGEO-2源自众包的Google地图POI图像,包含2,929张筛选后的图像;其中2,027张用于训练,902张用于测试。
- GeoBench包含512张普通照片(来自互联网)、512张全景图(通过Mapillary API获取)和108张卫星图像(来自Sentinel-2 Level-2A,通过Microsoft Planetary Computer获取),全部仅用于测试。
- 论文以MAPBench为主要训练与评估数据集,IMAGEO-2和GeoBench作为额外测试集,用于评估在多样化图像类型与全球覆盖下的泛化能力。
- 未对图像进行裁剪,所有图像均以原始分辨率使用。真实坐标与类别标签等元数据均来自官方POI数据库与地图API,确保准确性。
方法
作者采用一种地图增强的代理框架——Thinking with Map,以提升大型视觉语言模型(LVLMs)的地理定位性能。核心方法围绕一个迭代的“地图中的代理”循环构建,模型在此过程中执行假设生成、地图检索、交叉验证与决策收敛。该框架被形式化为策略模型 πθ 与结构化地图环境 Penv 之间的交互。给定地理定位查询 qimage,text,在每个迭代步骤 t,策略模型可选择提出新的位置假设 τt,或通过工具调用动作 αt 验证已有假设 τ<t,以从地图环境中获取信息。生成的地图工具响应 ot 被视为观测值,结合先前交互的历史,构成证据链 st。该证据链用于结构化信息的交叉验证,并用于更新一个隐式候选池 Ct,该池在交互过程中持续维护,直至收敛或预算耗尽。最终,策略模型从该候选池中选择答案。
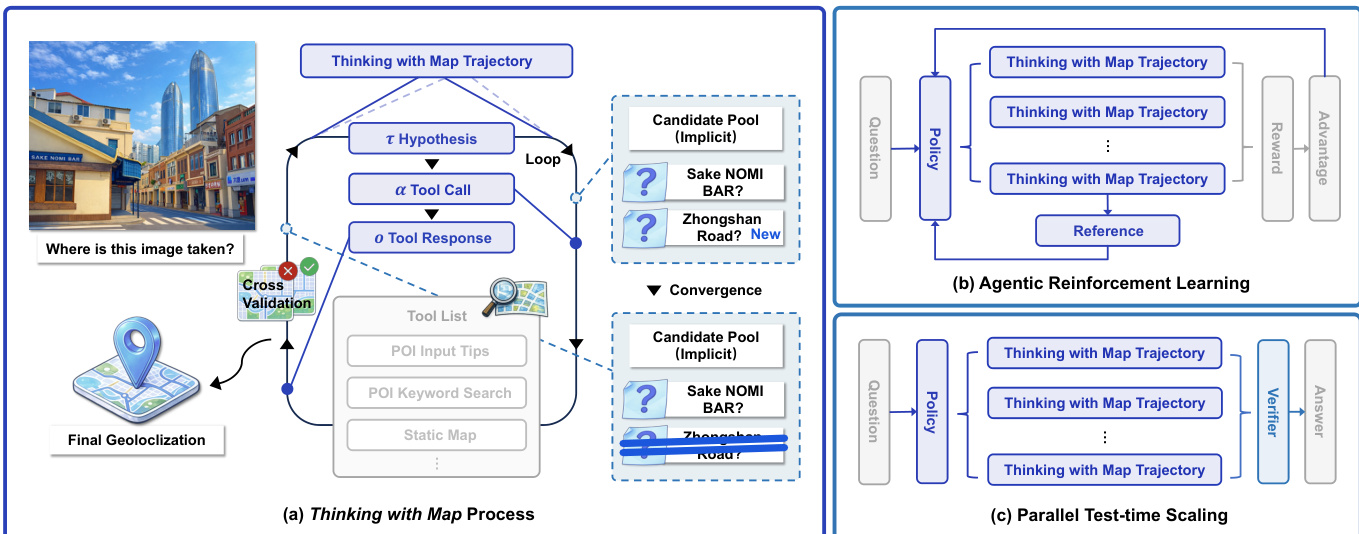
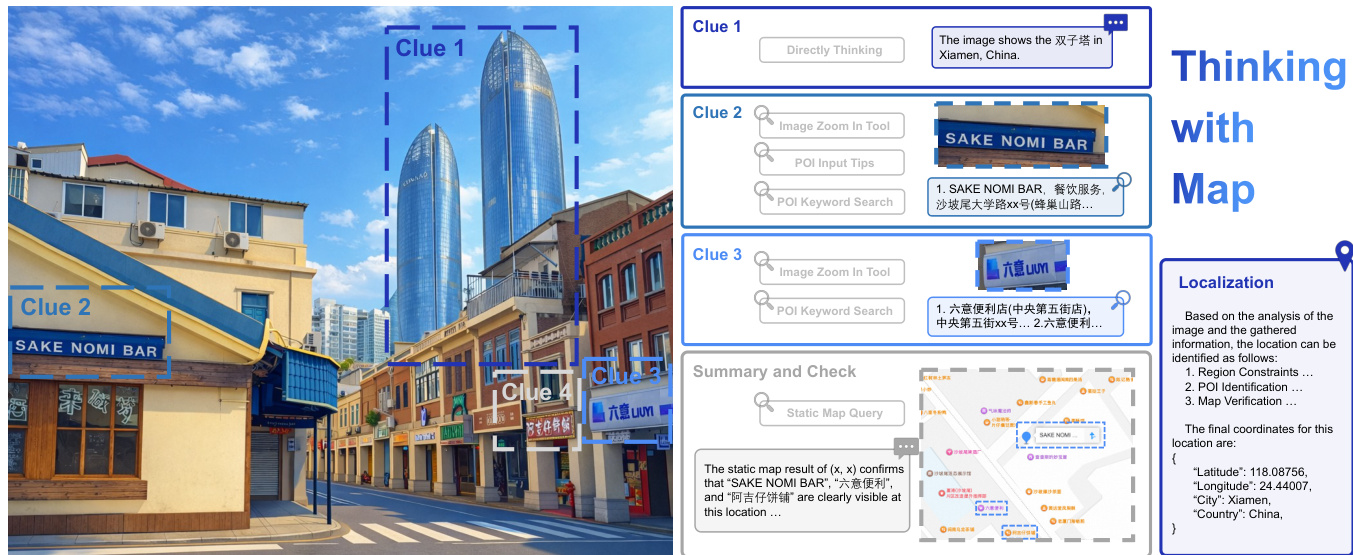
该框架集成了多种地图工具,以模拟人类推理过程,包括POI搜索以获取位置详情、静态与卫星地图用于场景验证,以及图像缩放工具用于检查视觉线索。为确保全球适用性,系统采用两种类型的地图API提供商。整体流程如框架图所示,展示了代理的迭代循环:提出假设、调用工具、接收响应、更新候选池,最终完成地理定位。

为将代理性能从 pass@N 提升至 pass@K,作者对基础模型应用代理强化学习(RL)。采用组相对策略优化(GRPO)算法,通过最大化为每个查询生成的一组代理轨迹的优势来优化策略。策略基于这些轨迹的相对表现进行更新,并引入KL散度惩罚以防止偏离参考策略过大。奖励函数设计用于连续距离评估,采用分段离散方案,对更精确的预测赋予更高奖励,反映不同定位粒度。模型被提示以固定JSON格式输出答案,便于奖励函数进行结构化解析。
为进一步提升性能并实现 pass@1,作者实施了一种并行测试时扩展(TTS)方法。该方法利用代理轨迹中包含的自验证信息。给定查询与强化后的策略,模型并行采样 N 条独立的 Thinking with Map 轨迹。这些轨迹随后输入一个独立的基于LVLM的验证器,该验证器汇总证据并选择最合理的预测作为最终答案。该验证器流水线聚合多条并行推理路径的结果,有效将 pass@K 的性能增益转化为 pass@1。
实验
- 在MAPBench、GeoBench和IMAGEO-2-test上,将Thinking with Map与闭源模型(GPT-o3、GPT-5、Gemini-3-Pro)及开源模型(Qwen3-VL-235B-A22B、GLOBE、GeoVista)进行对比评估。
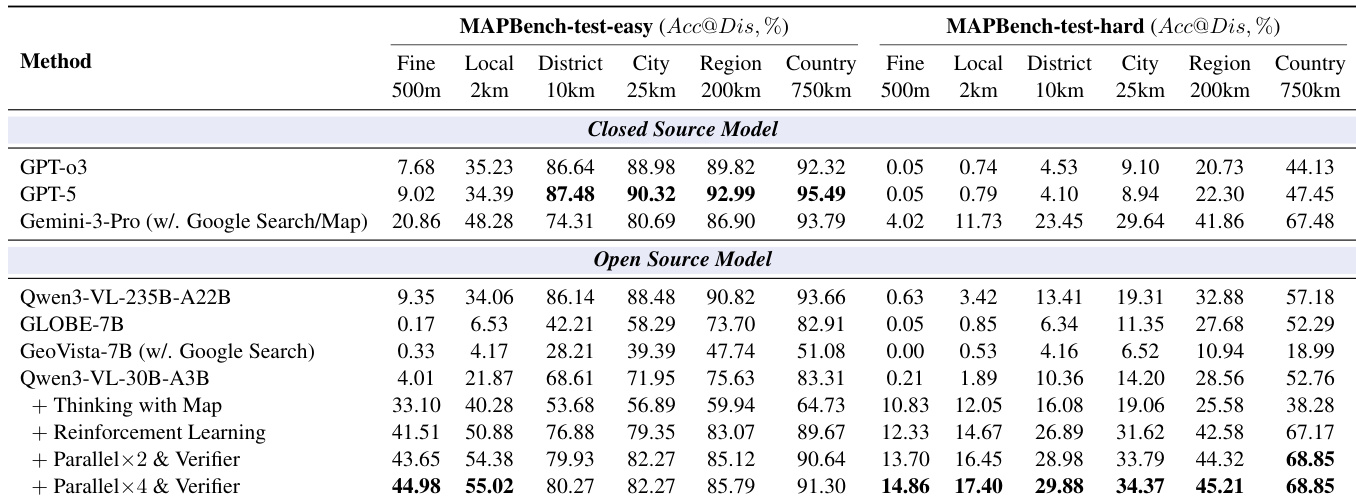
- 实现了最先进性能,在MAPBench-test-hard上达到14.86%的Acc@500m,超越Gemini-3-Pro(4.02%);在GeoBench上达到57.94%,在IMAGEO-2-test上达到20.53%,优于先前方法。
- 证明地图工具显著提升细粒度定位(Acc@500m从1.12%提升至16.16%),但可能因噪声输入而损害粗粒度准确性。
- 强化学习训练在所有粒度上均提升pass@K准确率,降低方差,并实现从pass@N到pass@K的更好提升,尽管Best@500m提升有限。
- 并行TTS结合30B验证器时,性能随并行样本数增加而提升,且在高并行度下验证器模型容量成为关键因素。
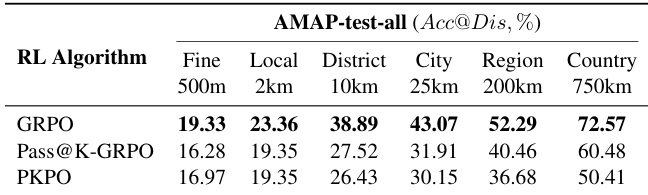
- GRPO在RL训练中优于Pass@K-GRPO与PKPO,证实其在代理地理定位中的有效性。
作者采用全面的评估框架,将Thinking with Map方法与闭源及开源模型在地理定位任务上进行对比。结果表明,Thinking with Map在多个粒度上均达到最高准确率,尤其在细粒度定位方面表现突出:在IMAGEO-2-test上500米准确率达57.94%,在GeoBench上同样达到57.94%,全面超越所有其他模型,包括最佳闭源模型Gemini-3-Pro。
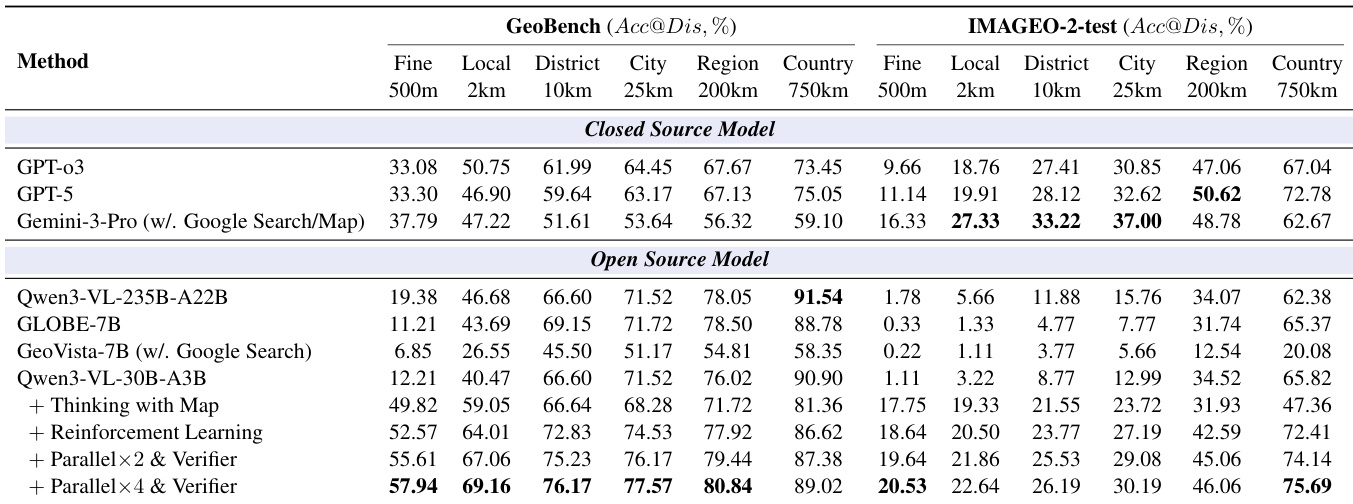
作者在多个基准(包括GeoBench和IMAGEO-Bench)上将Thinking with Map方法与多种开源及闭源模型进行对比,以不同距离粒度的准确率为评估指标。结果表明,Thinking with Map在大多数指标上均达到最高性能,尤其在细粒度定位(Acc@500m)方面全面优于所有其他模型。

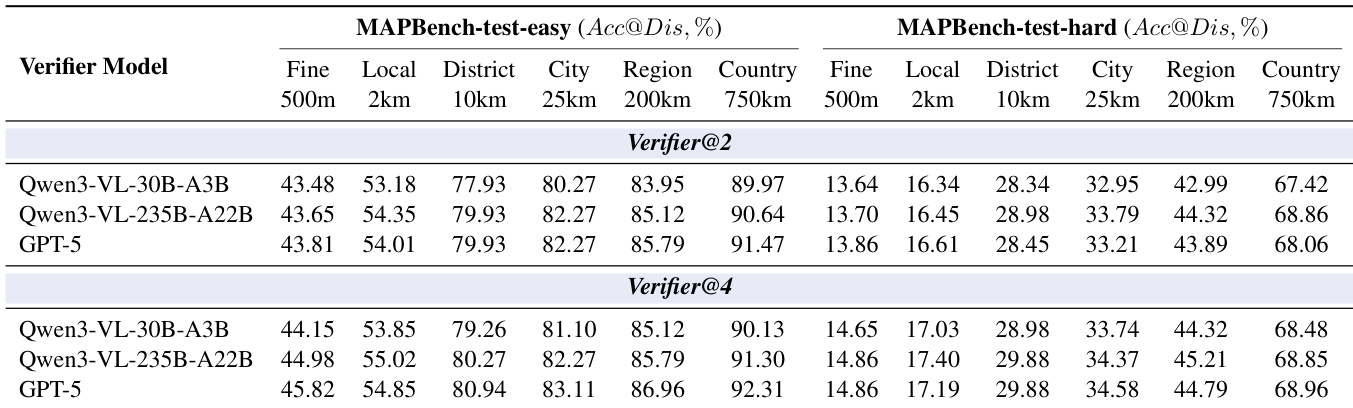
作者使用表8评估不同验证器模型对地理定位准确率的影响,比较Qwen3-VL-30B-A3B、Qwen3-VL-235B-A22B和GPT-5作为验证器在2和4个并行样本下的表现。结果表明,增加并行样本数可提升大多数粒度下的准确率,且GPT-5在所有情况下均优于Qwen3-VL模型,尤其在高并行度下优势更明显。
作者采用全面评估框架,将Thinking with Map方法与闭源及开源模型在地理定位任务上进行对比,结果显示该方法在多个粒度上均达到最高准确率,尤其在MAPBench-test-easy和MAPBench-test-hard上表现卓越。结果表明,该方法不仅超越了最佳闭源模型(如Gemini-3-Pro),尤其在500米级别表现突出,且强化学习与并行验证显著提升性能,最佳结果在4×并行采样策略下取得。
作者对比了不同RL算法在Thinking with Map方法中的表现,评估其在AMAP-test-all基准上多个定位粒度下的性能。结果表明,GRPO在所有层级均达到最高准确率,尤其在细粒度定位(500米处达19.33%)表现最佳,并持续优于Pass@K-GRPO与PKPO。