Command Palette
Search for a command to run...
EnvScaler:通过程序化合成实现LLM Agent的工具交互环境扩展
EnvScaler:通过程序化合成实现LLM Agent的工具交互环境扩展
Xiaoshuai Song Haofei Chang Guanting Dong Yutao Zhu Zhicheng Dou Ji-Rong Wen
摘要
大型语言模型(LLMs)有望被训练为在各类真实环境中充当智能代理,但这一过程依赖于丰富且多样化的工具交互沙箱环境。然而,实际系统往往难以获得访问权限;由LLM模拟的环境容易产生幻觉和不一致性;而人工构建的沙箱则难以实现规模化扩展。为此,本文提出EnvScaler——一种基于程序化合成的可扩展工具交互环境自动化构建框架。EnvScaler包含两个核心组件:首先,SkelBuilder通过主题挖掘、逻辑建模与质量评估,构建出多样化环境骨架;随后,ScenGenerator为每个环境生成多种任务场景,并配套生成基于规则的轨迹验证函数。借助EnvScaler,我们成功合成191个环境及约7000个任务场景,并将其应用于Qwen3系列模型的监督微调(SFT)与强化学习(RL)训练。在三个基准测试上的实验结果表明,EnvScaler显著提升了LLM在涉及多轮、多工具交互的复杂环境中的任务求解能力。相关代码与数据已开源,地址为:https://github.com/RUC-NLPIR/EnvScaler。
一句话总结
中国人民大学的作者提出 EnvScaler,一个程序化框架,通过骨架构建与场景生成实现多样化工具交互环境的可扩展合成,使 Qwen3 等大语言模型能够有效完成复杂、多轮、多工具任务的监督微调(SFT)与强化学习(RL)训练,在基准评估中显著优于先前方法。
主要贡献
- 现有训练大语言模型(LLM)智能体的方法受限于真实环境访问受限、LLM模拟环境中的幻觉问题,以及人工构建沙箱的可扩展性挑战,凸显了自动化、大规模环境合成的必要性。
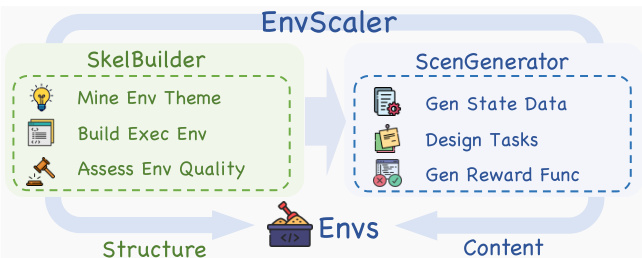
- EnvScaler 引入 SkelBuilder,通过主题挖掘、逻辑建模与迭代质量评估,实现多样化可执行环境骨架的自动化构建;同时引入 ScenGenerator,基于规则的轨迹验证生成具有挑战性与正确性的任务场景。
- 在三个基准上评估,EnvScaler 生成的环境显著提升了 Qwen3 系列模型在多轮、多工具任务中的表现,通过监督微调与强化学习展现出更强的泛化能力与鲁棒性。
引言
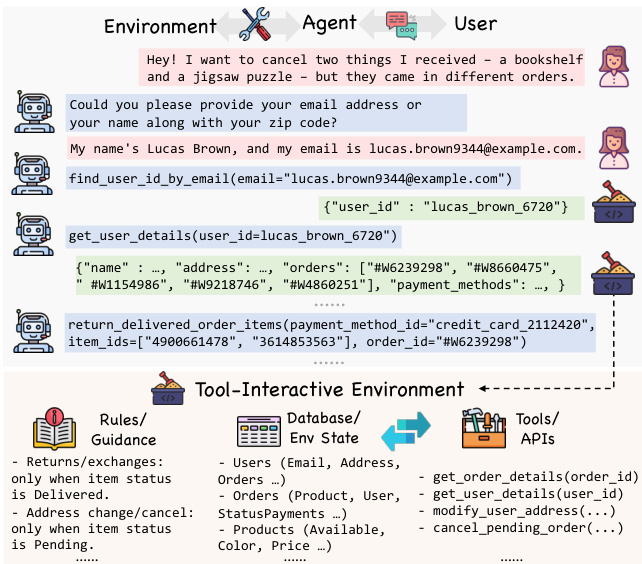
作者利用程序化合成方法,解决训练 LLM 智能体所需工具交互环境规模化这一关键挑战,此类环境对电商订单管理、航班改签等真实应用场景至关重要。现有方法存在局限:真实系统难以访问,LLM 模拟环境存在幻觉,人工构建沙箱缺乏可扩展性与多样性。现有自动化方法或依赖预设数据,或无法建模有状态交互,或缺乏严格的质量评估。为克服上述问题,作者提出 EnvScaler,一个两阶段框架。首先,SkelBuilder 通过主题挖掘、逻辑建模与测试检查代理的迭代质量评估,自动化生成多样化、可执行的环境骨架。其次,ScenGenerator 生成包含初始状态、挑战性任务与基于规则的轨迹验证函数的真实任务场景,以支持准确的奖励计算。该框架生成了 191 个环境与 7,000 个场景,在监督微调与强化学习中显著提升了 LLM 在多轮、多工具任务上的性能。
数据集

- 数据集由使用 API-Bank(Li 等,2023)和 ToolACE(Liu 等,2025b)作为初始任务来源生成的合成环境构成,因其在 LLM 上具有高任务保留率而被选中。
- 共生成 191 个合成环境,每个环境平均包含 18.58 个工具与 21.38 个状态类别,体现显著的复杂性与多样性。
- 环境生成过程涉及多个 LLM:GPT-4.1 与 Qwen3-235B-Instruct-2507 用于环境发现与编程,GPT-4.1-mini 与 Qwen3-30B-A3B-Instruct-2507 用于环境评估。
- 每个环境经过 100 次测试轮次,过滤阈值为 0.85,最终保留 191 个验证通过的环境。
- 合成环境包含详细的状态空间定义,明确指定环境中的实体、其属性与角色。
- 示例环境通过初始状态配置(图 25)、任务场景(图 26)与状态检查函数(图 11)进行展示,用于计算轨迹的奖励分数。
- 这些环境用于在多个基准上训练与评估模型:BFCL-v3 Multi-Turn、Tau-Bench 与 ACEBench-Agent,分别测试工具使用与推理的不同方面。
- 训练采用这些基准中的任务混合,特定子集用于评估鲁棒性,如缺失参数、缺失函数、长上下文、多轮与多步场景。
- 评估采用双重标准:状态检查与响应检查,确保动作正确性与任务目标对齐。
- 每个环境的元数据基于结构化工具接口(表 10)与状态定义构建,支持一致解释与自动化验证。
方法
作者采用模块化框架 EnvScaler,自动化合成多样化、可执行的工具交互环境,用于训练大语言模型(LLM)智能体。整体架构包含两个核心组件:SkelBuilder 与 ScenGenerator,按序协同构建环境及其关联场景。如框架图所示,SkelBuilder 首先通过挖掘现有任务的主题,构建可执行程序逻辑,并评估生成环境的质量,从而生成环境骨架。该过程输出一组环境 E={Fexec,Edoc,Σtool},其中 Fexec 为可执行程序文件,Edoc 为文档,Σtool 为工具接口集合。SkelBuilder 的输出——环境结构,随后输入 ScenGenerator,后者合成场景内容,包括初始状态、挑战性任务与验证函数,最终形成完整的训练数据集。
第一阶段:任务引导的环境发现。以一组现有任务 Texist 为起点,LLM 执行二元过滤,识别位于特定领域、有状态环境中的任务,仅保留需与持久状态交互的任务。对每个保留任务,LLM 推断对应环境描述。这些描述通过基于嵌入的聚类进行聚合与去重,得到多样化且无冗余的环境主题集 {Edes}。

第二阶段:自动化可执行环境构建。将环境描述转化为程序化建模的环境,采用三阶段流水线。第一阶段:逻辑规划。LLM 扩展环境描述 Edes,推断环境状态定义 Estate、领域规则 Erule 与工具操作列表 {Etooli}。规则与描述拼接形成环境文档 Edoc。第二阶段:程序建模。LLM 将规划好的状态空间转换为类属性定义 Fattr。对每个工具操作,在给定环境规则与类属性的前提下,生成对应的类方法实现 Fmethi,确保与规则一致并实现正确状态转移。第三阶段:程序组装。将生成的代码片段自动合并为完整的 Python 类文件 Fexec,实现所有沙箱逻辑。通过抽象语法树(AST)验证语法有效性,AST 与正则提取共同生成所有方法签名,构成工具接口集 Σtool。
第三阶段:双代理环境评估。评估所构建环境的实际工具执行性能。前端测试代理 Mtest 实例化时无内部实现访问权限。每轮接收当前环境状态 Sj,随机生成调用请求(可能为正例或负例)。后端检查代理 Mcheck 随后检查工具源码 Fmeth、返回结果 Rj 以及执行前后的状态变化,判断行为是否符合预期。测试与检查代理构成闭环,迭代 N 轮。平均判断通过率作为环境质量的量化指标,低于预设阈值的环境被剔除。

ScenGenerator 组件通过以下方式合成场景:首先使用 LLM 生成环境的初始状态数据 Sinit;然后基于初始状态、工具集与规则推导出挑战性任务。为实现基于规则的轨迹验证,将任务分解为可验证条件清单。对每个检查点,LLM 生成一个终端状态验证函数,输入环境的最终状态 Sfinal,返回布尔值表示条件是否满足。通过函数的比例作为轨迹的奖励分数。

最后,将智能体-环境交互建模为部分可观测马尔可夫决策过程(POMDP)。考虑两种交互设置:非对话(Non-Conv.),环境一次性提供完整任务信息;对话(Conv.),环境包含 LLM 模拟用户,要求智能体通过对话获取信息。监督微调(SFT)使用教师 LLM 的轨迹作为学习目标。强化学习(RL)则通过验证函数将轨迹转换为奖励,用于策略优化。
实验
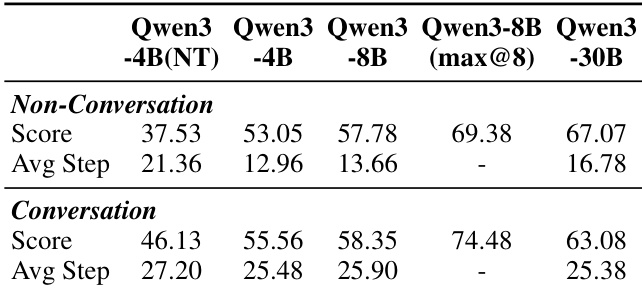
- 50 个合成场景的初步研究显示,Qwen3-8B(Thinking)得分为 57.78,而 Qwen3-4B(Non-Think)仅为 37.53,轨迹长度从约 15 步(Non-Conv)增至超过 25 步(Conv),验证了合成任务在促进长周期、复杂推理方面的难度与有效性。
- 在 140 个合成环境上进行 SFT,随后使用 Reinforce++ 进行 RL,显著提升 BFCL-MT、Tau-Bench 与 ACEBench-Agent 上的性能,Qwen3-8B 在 BFCL-MT 与 Tau-Bench 上分别提升 4.88 与 3.46 分,证明合成环境与状态检查奖励的有效性。
- 增加训练环境数量在 BFCL-MT 与 ACEBench-Agent 上带来稳定性能提升,从 0 到 20 个环境的提升最为显著,表明合成环境的多样性与数量增强了模型适应能力。
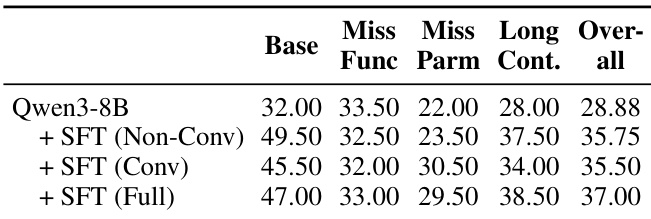
- 在非对话与对话交互模式下联合训练(Full setting)表现最佳,表明学习处理完整与不完整信息对跨多样化场景的鲁棒工具使用至关重要。
- EnvScaler 的性能提升在与测试集相似度不同的环境中均保持一致,表明模型学习的是可迁移的问题求解模式,而非依赖环境相似性。
- 无 SFT 的直接 RL 训练收益有限,尤其对 Qwen3-1.7B 等小模型,而 Qwen3-8B 仍取得显著提升,凸显 SFT 初始化对高质量策略学习的重要性。
- 在非思考模式下使用 EnvScaler 训练,虽提升 BFCL-MT 与 ACEBench-Agent 表现,但导致 Tau-Bench 结果下降,凸显模型在复杂推理任务中对推理链的依赖。
结果表明,Qwen3 模型在对话设置下相比非对话设置获得更高得分与更长平均轨迹。性能随模型规模提升,Qwen3-30B 在两种设置下均取得最高分,表明大模型更能从对话交互中获益。
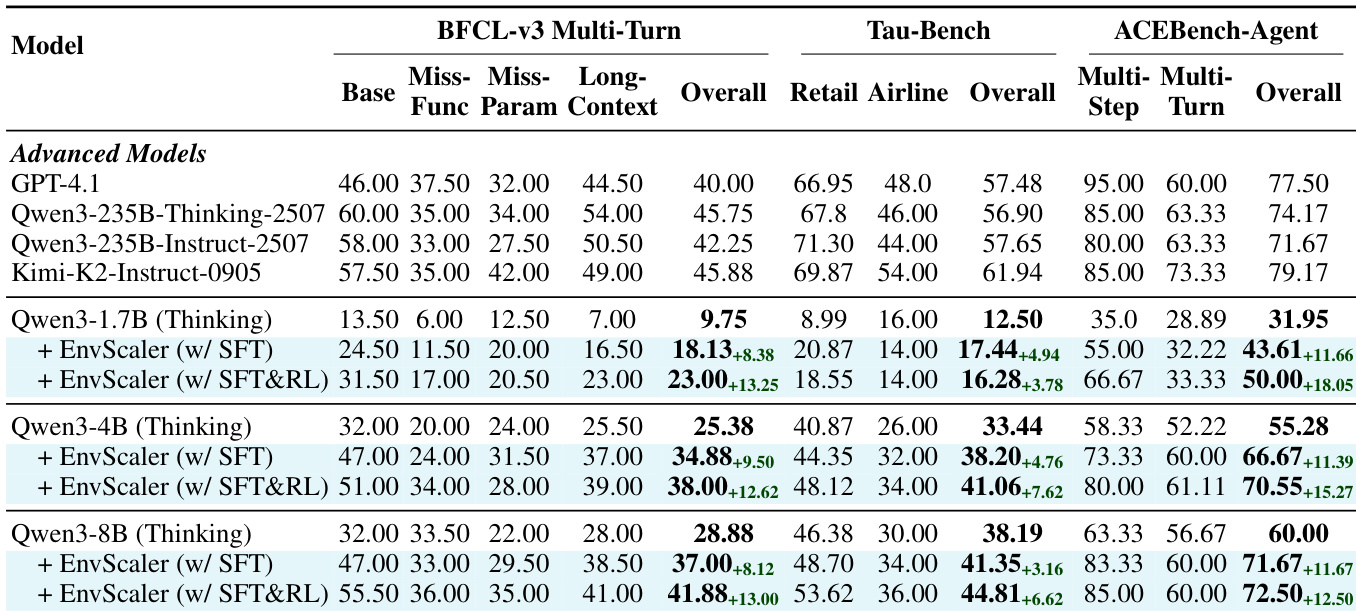
结果表明,使用 EnvScaler 训练显著提升模型在所有基准上的性能,SFT 提供显著增益,RL 进一步提升。提升在 BFCL-MT 与 ACEBench-Agent 上最为明显,而 Tau-Bench 提升有限,表明合成环境更有效增强多轮、多工具协作与领域适应能力,而非深度推理任务。
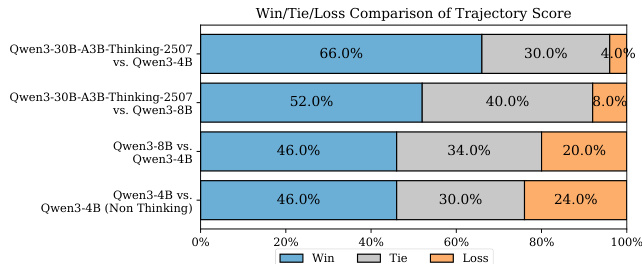
结果表明,Qwen3-30B-A3B-Thinking-2507 在所有对比对中胜率均高于 Qwen3-4B,尤其在非思考模式对比中差距最大。在 Qwen3-30B-A3B-Thinking-2507 与 Qwen3-4B(Non-Thinking)的对比中,胜率为 46.0%,败率为 24.0%,表明该设置下大模型具有显著优势。
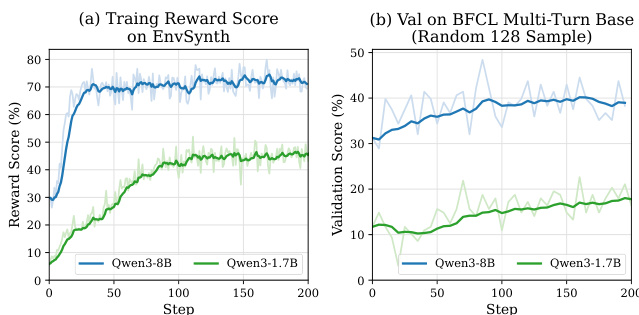
作者使用 Reinforce++ 算法在合成环境中训练 Qwen3-8B 与 Qwen3-1.7B 模型,结果显示 Qwen3-8B 在 BFCL-MT 上的训练奖励得分与验证性能均高于 Qwen3-1.7B。结果表明,大模型在合成环境中更受益于强化学习,Qwen3-8B 展现出稳定提升与更高最终性能,而 Qwen3-1.7B 学习较慢且整体增益较低。
结果表明,在 SFT 中结合非对话与对话交互模式显著提升 Qwen3-8B 在所有评估指标上的表现。包含两种交互类型的 Full SFT 设置取得最高总分,表明在多样化交互模式下训练能增强模型在完整与不完整信息场景中的适应能力。