Command Palette
Search for a command to run...
证据链构建:基于引用感知评分奖励的深度搜索Agent鲁棒强化学习
证据链构建:基于引用感知评分奖励的深度搜索Agent鲁棒强化学习
Jiajie Zhang Xin Lv Ling Feng Lei Hou Juanzi Li
摘要
强化学习(Reinforcement Learning, RL)已成为提升基于大语言模型(LLM)的深度搜索智能体性能的关键技术。然而,现有方法主要依赖二元结果奖励(binary outcome rewards),难以捕捉智能体推理过程中的全面性与事实准确性,常导致诸如捷径利用(shortcut exploitation)和幻觉(hallucinations)等不良行为。为解决上述局限,我们提出一种细粒度奖励框架——引文感知评分奖励(Citation-aware Rubric Rewards, CaRR),该框架聚焦于推理的全面性、事实依据性以及证据之间的逻辑连贯性。CaRR 将复杂问题分解为可验证的单跳评分标准(single-hop rubrics),要求智能体通过显式识别隐含实体、提供正确引文支持,并构建完整的证据链,最终与预测答案形成有效关联。为进一步优化训练过程,我们引入引文感知组相对策略优化(Citation-aware Group Relative Policy Optimization, C-GRPO),该方法融合 CaRR 与传统结果奖励,用于训练更具鲁棒性的深度搜索智能体。实验结果表明,C-GRPO 在多个深度搜索基准测试中均显著优于标准结果驱动的强化学习基线方法。进一步分析验证,C-GRPO 能有效抑制捷径利用行为,促进全面且基于证据的推理,并在开放式深度研究任务中展现出优异的泛化能力。相关代码与数据已开源,访问地址为:https://github.com/THUDM/CaRR。
一句话总结
清华大学与智谱AI的作者提出CaRR,一种引用感知的奖励框架,通过可验证的评分标准和证据链,强制深度搜索代理进行全面且基于事实的推理,并结合C-GRPO进行训练,显著减少幻觉和捷径利用,同时在多个基准测试中提升性能。
主要贡献
- 现有的深度搜索代理强化学习方法仅依赖二元结果奖励,无法惩罚捷径利用和幻觉,导致尽管最终答案正确,推理过程仍脆弱且缺乏事实依据。
- 作者提出引用感知评分奖励(CaRR),一种细粒度奖励框架,将复杂问题分解为可验证的单跳评分标准,要求代理识别隐藏实体、用正确引用支持主张,并构建完整连接至最终答案的证据链。
- 他们的方法——引用感知组相对策略优化(C-GRPO),结合CaRR与结果奖励,在多个深度搜索基准测试中持续优于基线强化学习方法,减少捷径行为,提升对开放式研究任务的泛化能力。
引言
作者利用强化学习(RL)改进基于大语言模型的深度搜索代理,使其能够通过网络导航解决复杂且知识密集型问题。尽管先前工作依赖二元结果奖励——仅指示最终答案是否正确——但这种方法无法评估推理质量,导致代理可无惩罚地利用捷径或产生幻觉。为解决此问题,作者引入引用感知评分奖励(CaRR),一种细粒度奖励框架,基于三项标准评估代理:隐藏实体的识别、通过引用进行的事实支持,以及连接至答案的完整证据链构建。他们进一步提出引用感知组相对策略优化(C-GRPO),将CaRR与结果奖励结合,训练出既准确又鲁棒的代理。实验表明,C-GRPO在多个基准测试中优于仅使用结果奖励的基线,减少捷径利用,并在开放式研究任务中表现出良好泛化能力。
数据集

- 数据集包含公开可用、开放许可的模型与数据源,确保透明性并符合伦理规范。
- 包含多个来自不同领域的子集,每个子集均根据相关性与质量进行筛选,并提供清晰的来源与许可信息。
- 每个子集具有明确的规模、来源及特定过滤规则——如语言限制、内容质量阈值、去重处理——以保障数据完整性。
- 作者使用该数据集训练模型,通过精心设计的混合比例组合子集,平衡覆盖范围、多样性与任务相关性。
- 数据经过标准化分词与清洗处理,采用裁剪策略限制序列长度,同时保持上下文连贯性。
- 构建元数据以追踪来源、分布与过滤步骤,支持可复现性与可审计性。
方法
作者采用ReAct范式构建深度搜索代理,其中基于大语言模型的代理通过迭代执行思考、动作与观察步骤来解答问题。一个完整的轨迹 H 由这些步骤的序列构成,最终动作 aT 为代理的回答,包含带引用的解释与最终答案。代理可执行三种动作:使用搜索工具获取相关网页、使用开放工具访问特定URL、使用查找工具从已打开页面中提取匹配关键词的内容。轨迹格式通过特定标签定义用户输入、助手思考、工具调用及最终响应,最终响应必须包含带引用的解释与确切答案。
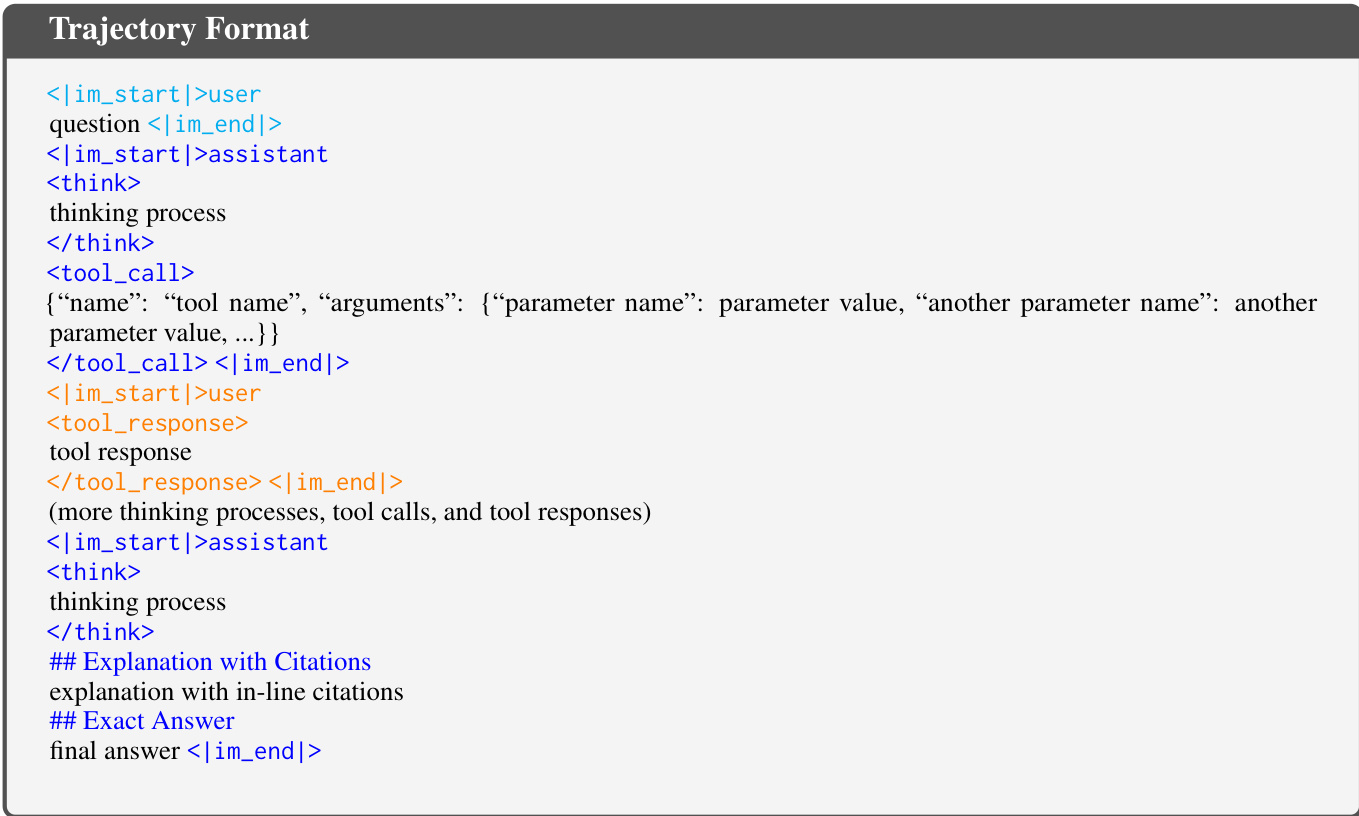
所提方法的核心是引用感知评分奖励(CaRR)框架,该框架基于推理的全面性、事实依据与证据连通性提供细粒度奖励。该框架分为三个主要阶段。第一阶段为评分初始化,通过大语言模型(LLM)提示将复杂多跳问题分解为一系列原子事实陈述,每个陈述涉及需被发现的隐藏实体。这些陈述作为可验证的评分标准。隐藏实体以占位符如表示,最终答案为。此过程如图所示,一个问题被分解为一组评分,每项代表必须发现的必要事实。
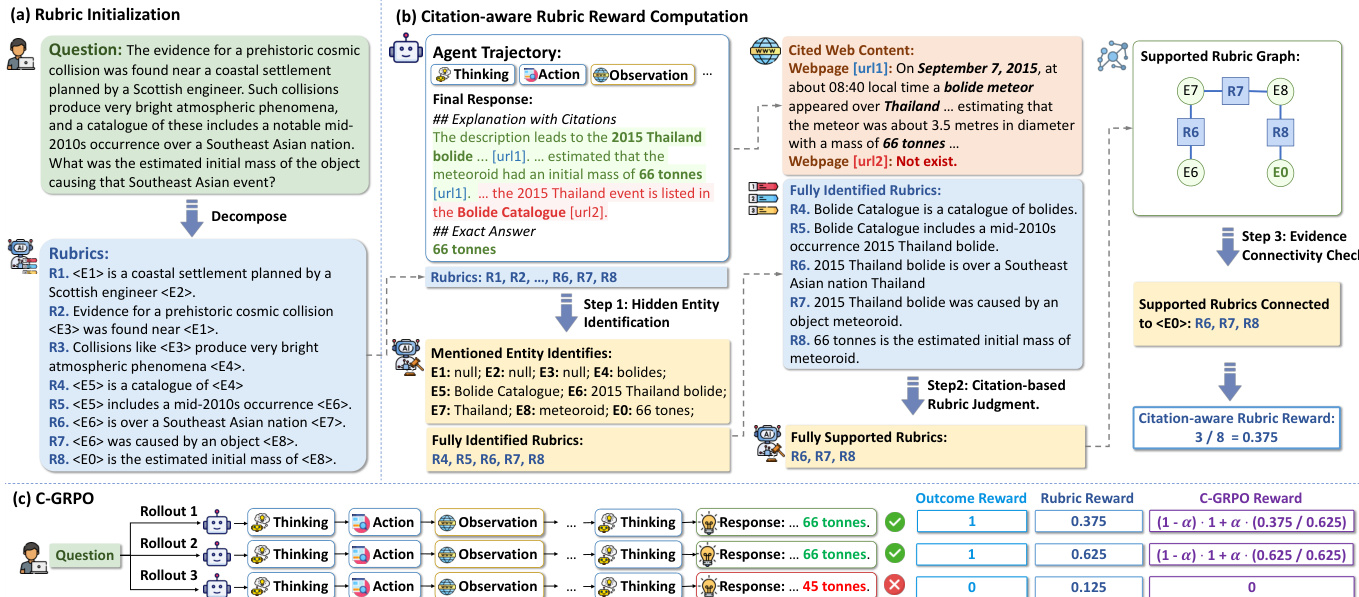
第二阶段为奖励计算过程,评估代理轨迹与预定义评分的一致性。该过程使用裁判大语言模型(judge LLM)分三步进行。第一步:隐藏实体识别,检查代理最终回答是否明确指出每个隐藏实体的名称。第二步:基于引用的评分判断,验证每个识别出的评分是否由轨迹中提取的引用网页内容支持。第三步:证据连通性检查,确保被支持的评分构成一个连通的证据链,逻辑上连接至预测的答案实体。这通过构建已识别实体与支持评分之间的二分图,并从答案实体出发执行广度优先搜索,判断哪些评分可达来实现。最终评分奖励为完全识别、支持且连通的评分比例。

最后,作者提出引用感知组相对策略优化(C-GRPO)算法,将CaRR框架与结果奖励结合。C-GRPO为每条轨迹使用混合奖励,即结果奖励(答案正确则为1,否则为0)与归一化评分奖励的加权和。该方法在保持寻找正确答案主目标的同时,鼓励代理生成更全面且基于证据的推理。代理策略通过最大化包含词元级损失、重要性采样比率及由混合奖励计算的优势的多轮GRPO目标进行优化。
实验
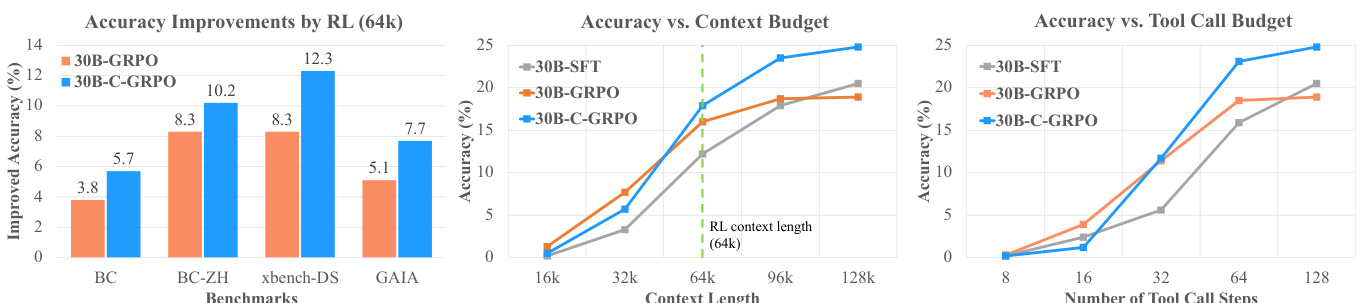
- 在所有基准测试中,使用上下文感知评分奖励的C-GRPO显著优于GRPO与E-GRPO基线,在64k/128k上下文预算下平均提升分别为5.1/8.0(4B)与2.6/6.0(30B)。
- 在BrowseComp上,C-GRPO相比SFT与GRPO增加了引用网页数量与评分满足度,表明推理更具全面性与事实性。
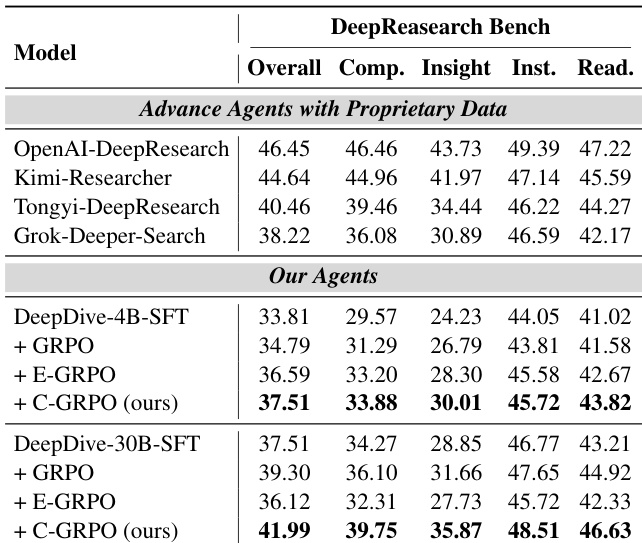
- C-GRPO在DeepResearch Bench上达到开源代理的最先进性能,超越SFT模型,并在全面性、洞察力、指令遵循与可读性方面超过多个使用专有数据的代理。
- 训练动态显示,GRPO的工具调用步骤下降,表明存在捷径利用;而C-GRPO保持工具调用增加,反映更彻底的证据收集。
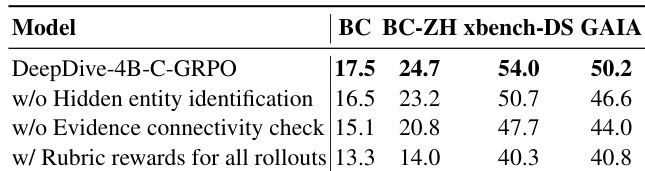
- 消融研究证实,隐藏实体识别、证据连通性检查以及仅对正确轨迹应用评分奖励对最优性能至关重要。
- CaRR中的裁判LLM表现出高可靠性,隐藏实体识别准确率达97.7%,评分评估准确率达95.1%,经人工验证确认。
作者通过消融研究评估C-GRPO框架中关键组件的影响。结果表明,移除隐藏实体识别或证据连通性检查会显著降低所有基准测试的性能,表明二者在确保稳健准确推理中的重要性。此外,若对所有轨迹而非仅正确轨迹应用评分奖励,性能显著下降,表明此类调整在训练中引入了误导性信号。
作者使用C-GRPO训练深度搜索代理,结果显示其在所有基准测试中显著优于GRPO与E-GRPO基线。结果表明,C-GRPO在所有评估维度均取得最高得分,30B模型超越多个使用专有数据的先进代理。
作者使用表格比较不同模型在评分满足度指标上的表现,显示C-GRPO在识别与支持评分方面优于SFT基线。结果表明,C-GRPO在评分识别与支持方面得分更高,同时保持连通性表现,表明证据收集与验证更彻底。

作者使用C-GRPO——一种融合上下文感知评分奖励的奖励机制——训练深度搜索代理,结果显示其在所有基准测试中显著优于GRPO与E-GRPO基线。结果表明,C-GRPO在64k与128k上下文长度下均高于GRPO的准确率,且随着上下文与工具调用预算增加,准确率持续提升,表明其具备更好的可扩展性与鲁棒性。
作者使用不同评分奖励权重训练4B模型,结果显示性能随权重从0增至0.3而提升,于0.3处达到峰值,但在0.5时下降,表明结果奖励与评分奖励之间需适度平衡。结果表明,α=0.3的C-GRPO在所有基准测试中表现最佳,优于SFT基线及其他C-GRPO变体。