Command Palette
Search for a command to run...
MemoryLLM:即插即用的可解释前馈记忆机制用于Transformer
MemoryLLM:即插即用的可解释前馈记忆机制用于Transformer
Ajay Jaiswal Lauren Hannah Han-Byul Kim Duc Hoang Arnav Kundu Mehrdad Farajtabar Minsik Cho
摘要
理解Transformer组件在大语言模型(LLMs)中的运作机制至关重要,因为这正是近年来人工智能技术进步的核心所在。在本研究中,我们重新审视了前馈模块(Feed-Forward Networks, FFNs)可解释性所面临的挑战,并提出MemoryLLM,旨在将FFNs与自注意力机制解耦,从而将解耦后的FFNs视为无上下文依赖的、按标记(token-wise)的神经检索记忆。具体而言,我们探究了输入标记如何访问FFN参数中的记忆位置,以及FFN记忆在不同下游任务中的重要性。MemoryLLM通过在不依赖自注意力机制的情况下,直接使用标记嵌入(token embeddings)对FFNs进行独立训练,实现了无上下文依赖的FFNs。该方法使得FFNs可预先计算为按标记的查找表(Token-wise Lookups, ToLs),从而支持显存(VRAM)与存储之间的按需数据迁移,显著提升推理效率。此外,我们还提出了Flex-MemoryLLM,该架构介于传统Transformer设计与MemoryLLM之间,通过在训练中使用无上下文的标记级嵌入来桥接因FFNs解耦而产生的性能差距。
一句话总结
苹果研究人员提出了 MemoryLLM,一种将前馈网络(FFN)与自注意力机制解耦的 Transformer 架构,将其视为上下文无关、按词元索引的神经记忆,从而实现可解释性分析和预计算查找,在保持性能的同时降低显存占用,通过 Flex-MemoryLLM 变体进一步优化。
主要贡献
- MemoryLLM 通过在无上下文的词元嵌入上独立训练 FFN,将其与自注意力机制解耦,实现可解释的词元级神经检索记忆,无需依赖残差流交互。
- 该架构支持 FFN 的预计算词元查找表(ToLs),允许即插即用的内存卸载至存储设备,提升推理效率,并在 250M、750M 和 1B 参数规模上得到验证。
- Flex-MemoryLLM 通过将 FFN 参数拆分为上下文相关与上下文无关两部分,弥合性能差距,在保持可解释性和效率优势的同时,与传统 Transformer 保持竞争力。
引言
作者利用一个观察:尽管 Transformer 中的前馈网络(FFN)参数量庞大,但由于其与自注意力模块紧密耦合,其功能作为可解释记忆系统的本质被掩盖。先前工作尝试将 FFN 逆向工程为键值记忆,但依赖于预训练模型的后验分析,需校准数据集,且仅提供间接、非离散的查询映射。MemoryLLM 通过在训练期间将 FFN 完全与自注意力解耦,将其视为上下文无关、按词元索引的神经检索记忆,可预先计算并存储。这既实现了可解释的词元级内存访问,又通过即插即用的内存卸载提升了推理效率。为缓解完全解耦导致的性能损失,作者还引入 Flex-MemoryLLM,将上下文无关与上下文相关的 FFN 混合,弥合与传统 Transformer 的差距。
方法
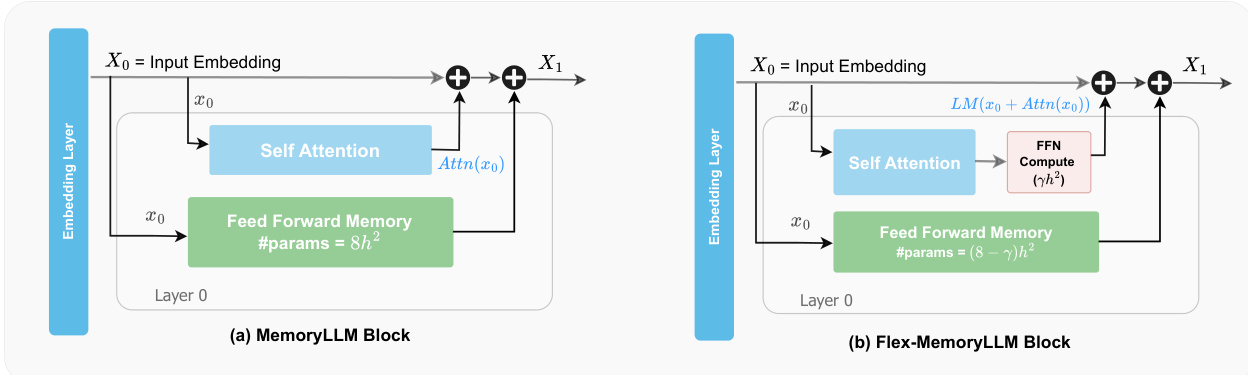
作者采用一种名为 MemoryLLM 的新型 Transformer 架构,将前馈网络(FFN)从残差流和自注意力模块中解耦,从而实现对 FFN 功能的确定性和可解释性分析。在传统大语言模型中,FFN 在动态演化的残差流上运行,该流结合了前层的上下文信息,使其内部机制难以理解。MemoryLLM 通过在所有 Transformer 层中直接以初始词元嵌入 X0 训练 FFN 模块来解决此问题,X0 是静态的,仅由分词器根据词元 ID 生成。该设计将 FFN 与上下文依赖隔离,使其作为上下文无关的词元索引记忆库运行。
参见框架图,该图对比了传统密集型 LLM 与 MemoryLLM。在传统架构中,每个 Transformer 层 L 在残差流 XL 上计算自注意力,将结果加至 XL,然后对总和应用 FFN。在 MemoryLLM 中,自注意力模块照常运行,但第 L 层的 FFN 接收原始输入嵌入 X0 而非残差流。第 L 层的输出计算如下:
XL+1=XL+Attn(XL)+FFN(X0)这种上下文感知的自注意力与上下文无关的 FFN 计算的并行化保留了残差流,同时使 FFN 可被解释为在有限、人类可理解查询空间(即词汇表)上的神经键值记忆。
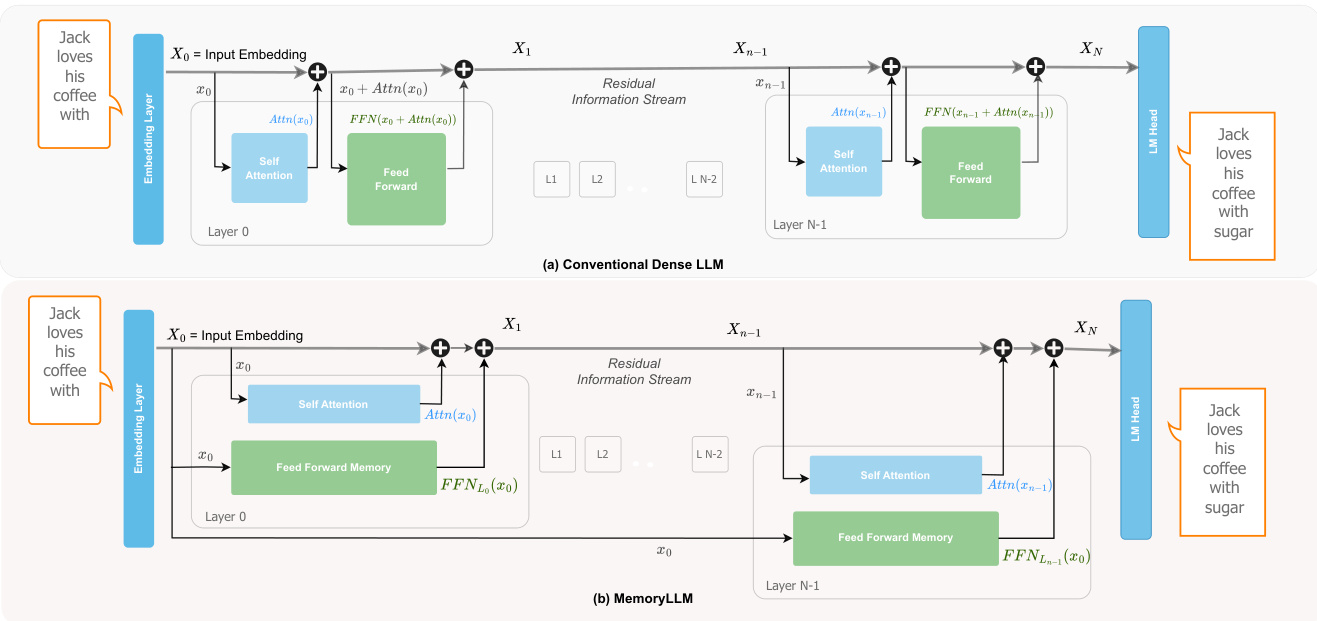
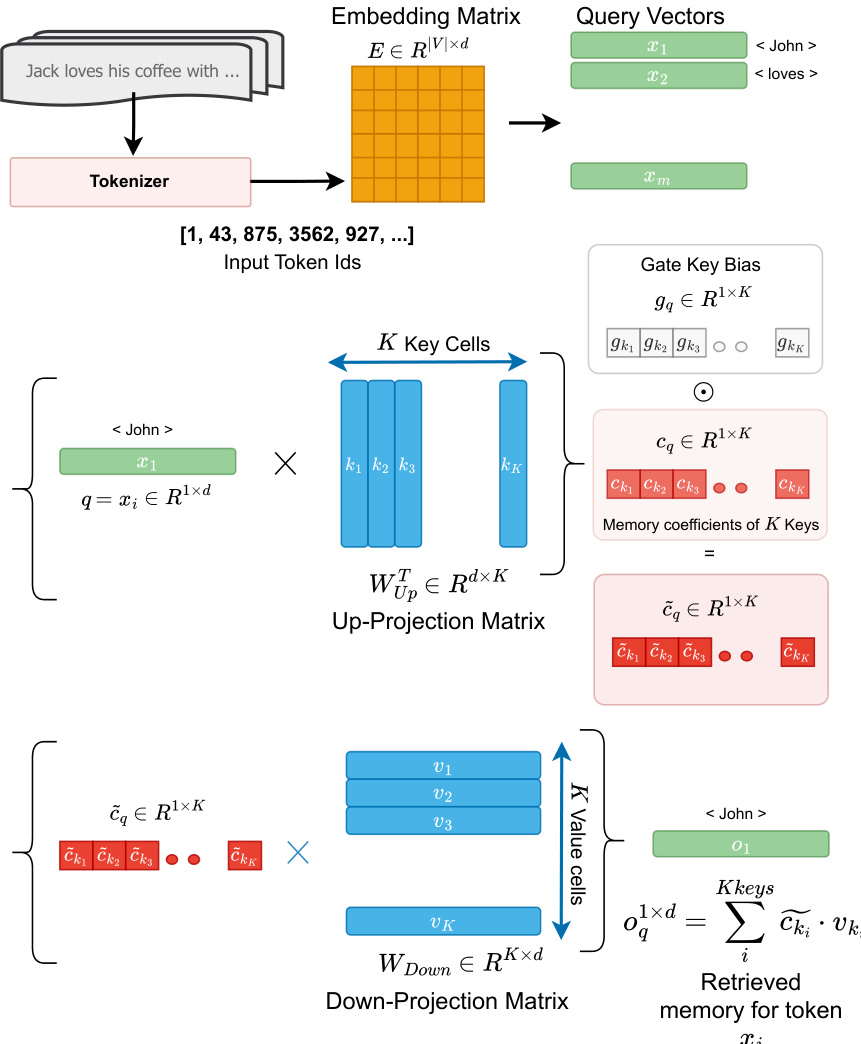
为形式化此解释,作者引入 TKV(词元-键-值)框架。在每个 FFN 中,上投影矩阵 WUp 被视为一组 K 个键向量,下投影矩阵 WDown 为对应的值向量。门投影矩阵 WGate 作为学习的重加权函数,调节每个键的贡献。对于对应词元 ti 的查询向量 q=xi,记忆检索过程包含两个步骤。首先,通过 q 与 WUp⊤ 的列的点积计算记忆单元系数 cki,然后通过门向量 gki 逐元素重加权:
c~ki=(q1×d⋅WUp[:,ki]⊤)×gki其次,检索输出是值向量 vki 的加权和:
FFN(X0q)=σq1×d=i∑Kc~ki⋅vki该框架消除了繁琐的输入前缀逆向工程需求,提供了从词元 ID 到记忆单元的直接映射。
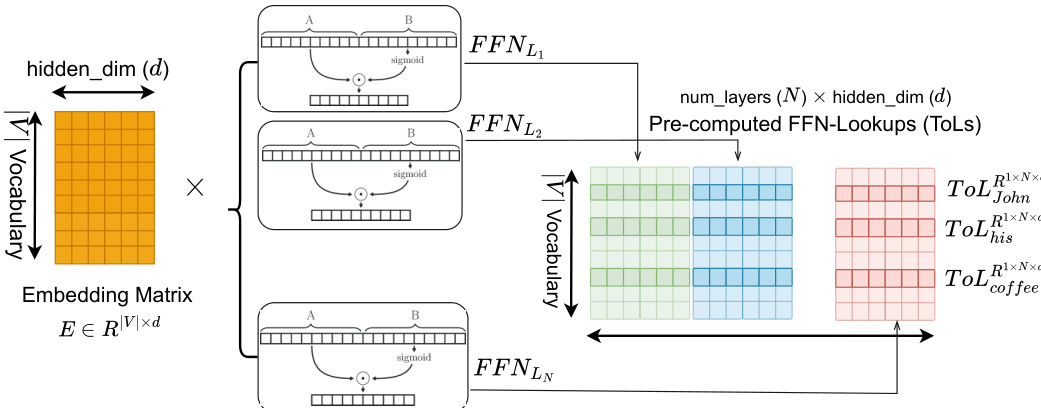
MemoryLLM 中 FFN 输入的静态性质带来显著效率提升:所有词汇表词元的 FFN 输出可离线预计算并存储为词元级查找表(ToLs)。每个词元 ti 的 ToL 是所有 N 层 FFN 输出的拼接:
ToLxti1×(N×d)=Concatk=0N−1{FFNLk(xti),dim=1}这些 ToLs 可卸载至存储设备并在推理期间异步预取,降低计算负载和显存占用。作者进一步提出按需即插即用策略,缓存高频词元的 ToLs(遵循齐夫定律),按需加载低频词元。
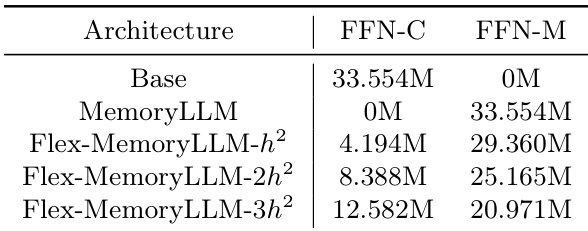
为弥合 MemoryLLM 与传统密集型 LLM 之间的性能差距,作者引入 Flex-MemoryLLM。该混合架构将每层 FFN 参数拆分为两个组件:FFN Compute(FFN-C),一个在残差流上运行的密集模块,以增强计算能力;FFN Memory(FFN-M),一个在 X0 上训练的上下文无关记忆模块,如 MemoryLLM 中所述。总参数量与基础模型相同,但部分 FFN 参数(例如,β=3 时为 5h2)可在推理期间作为静态 ToLs 卸载。Flex-MemoryLLM 中第 L 层的输出为:
XL+1=XL+Attn(XL)+FFN-C(XL)+FFN-M(X0)该设计允许在性能与效率之间进行平滑权衡,使具有显著更少活跃参数的模型可匹配甚至超越密集型对应模型的性能。
作者还探索了 ToLs 的存储优化,估计总存储大小为:
Storage Size=vocab size×num layers×hidden dim×bits per param对于具有 24 层和 2048 隐藏维度的 1B 参数 MemoryLLM,F16 精度下约为 12.6 GB。他们建议采用量化、低秩压缩和逐层压缩等策略来减少存储占用。
实验
- 语义相似的词元在 FFN 记忆中激活相似的键,形成可解释的聚类(如标点、人名、地点),支持定向记忆编辑或毒性控制。
- 所有层的聚类强度均保持较高,末层显示更多异常键,表明词元级信息收敛更集中。
- 通过插值降低 FFN 贡献对依赖回忆的任务影响更大,而对推理任务影响较小,证实 FFN 作为词元索引检索记忆的作用。
- MemoryLLM 在总参数对比下表现不如基础 LLM,但在活跃参数对比下表现更优,验证了其通过预计算 ToLs 实现的效率。
- MemoryLLM 和 Flex-MemoryLLM 在匹配活跃参数数量时优于剪枝的基础模型,为剪枝技术提供可行替代方案。
- ToLs 在末层表现出强低秩特性,可通过 SVD 实现约 2 倍存储压缩,性能损失极小。
- 从中间层移除 ToLs 导致性能下降极小,表明高度冗余,提供实用压缩策略。
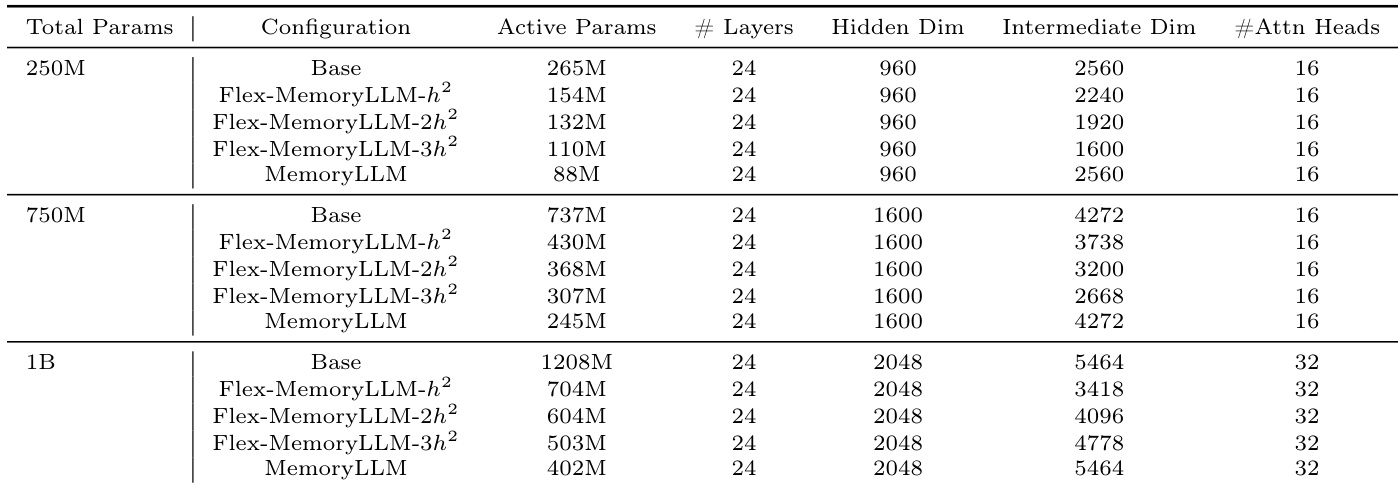
作者在不同总参数量的模型中采用统一的 24 层架构,调整中间维度以控制活跃参数量,同时保持隐藏维度和注意力头数不变。MemoryLLM 和 Flex-MemoryLLM 变体通过设计实现比基础模型更低的活跃参数量,支持更高效的部署,无需更改层数或核心结构。这些配置支持在评估基于记忆的架构与传统剪枝方法时,比较性能与活跃参数效率。
作者在不同精度级别下评估 MemoryLLM-1B 的词元级查找表,发现将精度从 16 位降至 4 位在多个下游任务中仅引起微小性能变化。结果表明,即使在 4 位精度下,模型仍保持有竞争力的得分,表明其对低精度量化的强鲁棒性。这支持了在显著减少存储需求的同时部署 MemoryLLM 的可行性,而不会大幅降低任务性能。

作者使用受控插值参数降低 FFN 贡献,观察到依赖回忆或检索的任务性能下降更大,而推理任务受影响较小。结果表明,随着 FFN 影响降低,模型保持更强的逻辑推理能力,但在事实性任务上准确性下降。这表明 MemoryLLM 中的 FFN 作为词元索引记忆存储,对知识检索比推理更重要。

作者将 MemoryLLM 及其变体与基础模型对比,发现 MemoryLLM 实现最低推理内存占用,同时提供每词元最快的解码速度。Flex-MemoryLLM 变体在内存和速度间权衡,更高隐藏维度扩展增加内存但未持续提升速度。结果表明 MemoryLLM 架构在不牺牲吞吐量的情况下实现更高效推理。
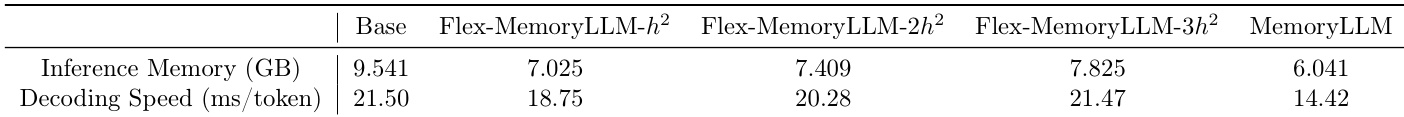
作者使用参数分配策略将前馈网络组件拆分为上下文依赖和上下文无关记忆模块,表明将更多参数移至记忆模块会减少上下文依赖组件,同时保持总参数量不变。结果表明,Flex-MemoryLLM 等架构可灵活平衡这些组件,实现在不改变整体模型大小的情况下,在计算效率与记忆容量间权衡。