Command Palette
Search for a command to run...
大型语言模型强化微调中的熵动态研究
大型语言模型强化微调中的熵动态研究
Shumin Wang Yuexiang Xie Wenhao Zhang Yuchang Sun Yanxi Chen Yaliang Li Yanyong Zhang
摘要
熵(Entropy)是衡量大语言模型(LLMs)输出多样性的重要指标,能够为模型的探索能力提供关键洞察。尽管近期研究日益关注在强化学习微调(Reinforcement Fine-Tuning, RFT)过程中监控与调控熵,以更好地平衡探索与利用,但关于熵在该过程中的动态行为仍缺乏系统性的理论理解。本文构建了一个理论框架,用于分析RFT过程中熵的动态变化。该框架始于一个判别性表达式,用于量化单个logit更新下的熵变化量;在此基础上,推导出熵变化的一阶表达式,并进一步推广至分组相对策略优化(Group Relative Policy Optimization, GRPO)的更新公式。由此得出的推论与理论洞见,不仅启发了熵控制方法的设计,也为理解现有研究中各类基于熵的方法提供了统一的分析视角。我们通过实证研究验证了分析的主要结论,并展示了所推导出的熵判别器裁剪(entropy-discriminator clipping)方法的有效性。本研究揭示了RFT训练动态中的新见解,为优化大语言模型微调过程中的探索-利用平衡提供了理论依据与实用策略。
一句话总结
王淑敏与张艳勇(清华大学)及其合作者提出了一种用于大语言模型强化微调中熵动力学的理论框架,推导出适用于GRPO的一阶熵更新公式,从而实现新型熵控制方法,改善探索-利用平衡,并通过实验证实其有效性。
主要贡献
- 我们引入了一个理论框架,量化强化微调过程中每个token层级的熵变化,推导出可扩展至组相对策略优化(GRPO)的一阶表达式,揭示熵动力学依赖于token更新方向与判别分数 S⋆。
- 我们的分析为现有基于熵的方法提供了统一解释,并启发了新的熵控制策略,包括基于判别分数 S⋆ 的裁剪技术,为平衡探索与利用提供原则性指导。
- 实验结果验证了我们的理论预测,表明 S⋆ 可靠指示熵趋势,且我们的裁剪方法在RFT期间有效稳定熵,提升模型探索能力而不损害性能。
引言
作者利用熵作为诊断工具,以理解和控制大语言模型强化微调(RFT)过程中的探索-利用权衡。尽管以往基于熵的方法常依赖启发式且缺乏理论基础——导致策略不一致与昂贵的超参数调优——作者推导出一个原则性框架,量化单个token的logit更新如何传播至熵变化。他们将其扩展至GRPO,揭示熵动力学取决于token概率、更新方向与策略熵之间的相互作用,从而解释常见的熵崩溃现象。该框架支持实用的熵裁剪策略,并统一解释现有基于熵的技术。
数据集
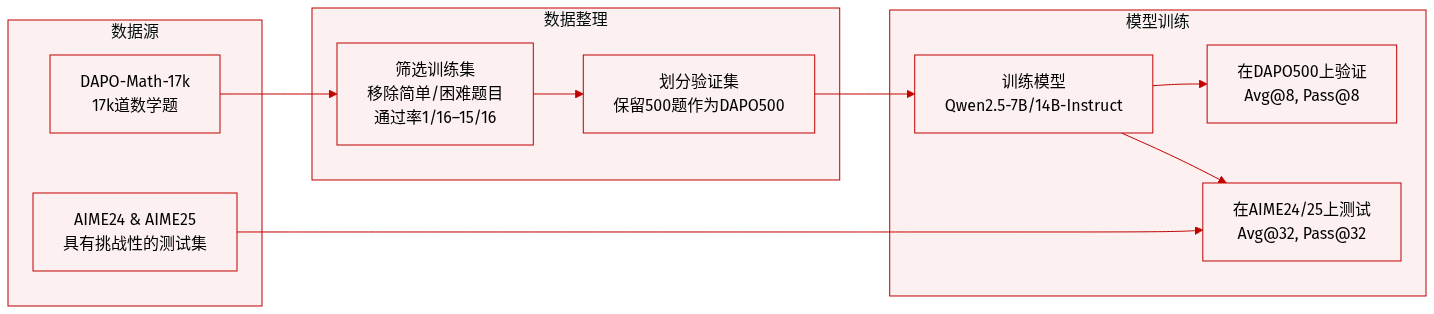
- 作者使用DAPO-Math-17k(Yu等,2025)作为主要训练数据集,从中选取17,000道数学题用于微调Qwen2.5-7B-Instruct和Qwen2.5-14B-Instruct模型。
- 从DAPO-Math-17k中保留500道题作为验证集(DAPO500),遵循先前工作(Lightman等,2023)。
- 通过排除Qwen2.5-7B-Instruct评估下通过率≤1/16或≥15/16的训练样本,确保训练难度适中。
- 测试时使用AIME24和AIME25——两个具有挑战性的数学数据集——并采用Avg@32和Pass@32指标评估。
- 对于DAPO500验证集,使用Avg@8和Pass@8指标,其中Avg@K为每题K个回答的平均准确率,Pass@K为K个回答中至少有一个正确的概率。
方法
作者利用理论框架刻画强化微调(RFT)中策略优化期间token层级的熵动力学,重点关注组相对策略优化(GRPO)。其分析始于微观层面——考察单个token更新如何改变下一token分布的熵——并扩展至完整的GRPO优化步骤,从而在训练期间实现对熵演化的原则性控制。
该方法的核心是熵判别分数 S∗t,定义为在位置 t 采样的token ak 的 S∗t=pkt(Ht+logpkt),其中 pkt 为当前策略下该token的概率,Ht 为该步骤完整token分布的熵。该分数作为熵变化的一阶预测器:对token的正向更新(奖励)若 S∗t<0(即该token概率相对较低)则增加熵,若 S∗t>0(即该token概率较高)则减少熵。此关系由logit扰动 δz=ε⋅ek 下熵的泰勒展开推导得出:ΔH=−εS∗+O(ε2)。
扩展至GRPO,作者建模完整优化步骤引起的熵变化。在GRPO下,每个token的更新由代理损失 L(z)=r⋅A⋅logpk(z) 控制,其中 r 为重要性比率,A 为优势值。学习率为 η 的梯度步诱导logit更新 δz=α(ek−p),其中 α=ηrA。代入熵梯度后得到关键结果:一阶熵变化为 ΔH=−α(S∗−Ei∼p[Si])+O(α2)。这表明熵变化不仅由 S∗ 决定,还取决于其与策略加权期望 Ei∼p[Si] 的偏差,后者作为动态基线。该基线确保在策略内采样下,词汇表或批次的期望熵变化为零——这一性质在推论3.4和3.5中形式化。
基于此,作者提出两种裁剪方法以稳定训练期间的熵。第一种ClipB在批次级别操作:对批次 TB 中每个token t,计算 S∗t 的批次均值 Sˉ 与标准差 σ,然后应用掩码 mt=1{−μ−σ≤S∗t−Sˉ≤μ+σ},过滤驱动极端熵波动的异常token。第二种ClipV在词汇表级别操作:对每个token,计算中心化分数 Sct=S∗t−Ei∼pt[Sit],然后基于这些中心化分数的批次标准差应用掩码。两种方法计算开销极小——仅操作标量值——并可无缝集成至现有RFT流程。
作者进一步证明,现有熵控制方法——如裁剪机制、熵正则化和概率加权更新——均可通过其熵动力学框架解释。例如,GRPO中的裁剪主要影响低概率token(其 S∗−E[Si]<0);因此,裁剪正样本(奖励这些token)倾向于增加熵,而裁剪负样本(惩罚这些token)倾向于减少熵。类似地,仅更新高熵token的熵正则化方法隐式针对 S∗−E[Si]>0 的token,其正样本更新会减少熵。这种统一视角使作者能解释为何某些方法促进探索(通过放大增加熵的更新),而其他方法抑制探索(通过放大减少熵的更新)。
最后,作者将分析扩展至离策略设置,表明在引入重要性比率 r 后,相同的熵动力学仍成立,熵变化因子变为 r(S∗−Ei∼p[Si])。他们还推导了批次级别的协方差表达式(推论C.2和C.2.1),将熵变化与优势值和判别分数偏差的协方差联系起来,提供一个可计算的指标用于监控训练期间的熵崩溃。其实验结果证实该协方差主要为负,表明模型倾向于强化“安全”的高概率token,从而抑制探索——这正是其裁剪方法旨在抵消的动态。
实验
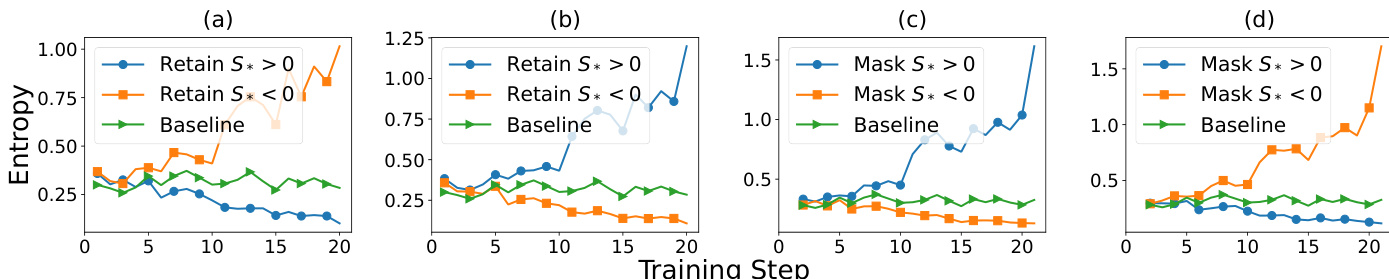
- 实验测试证实判别分数可靠预测熵变化:正分数在正样本中减少熵,在负样本中增加熵;负分数则相反,验证了理论主张。
- 梯度掩码实验进一步支持此关系,显示当屏蔽减少熵的梯度时熵增加,当屏蔽增加熵的梯度时熵减少。
- 裁剪方法(Clip_B和Clip_V)有效控制训练期间的熵衰减,可通过超参数μ灵活调整,防止过度熵崩溃。
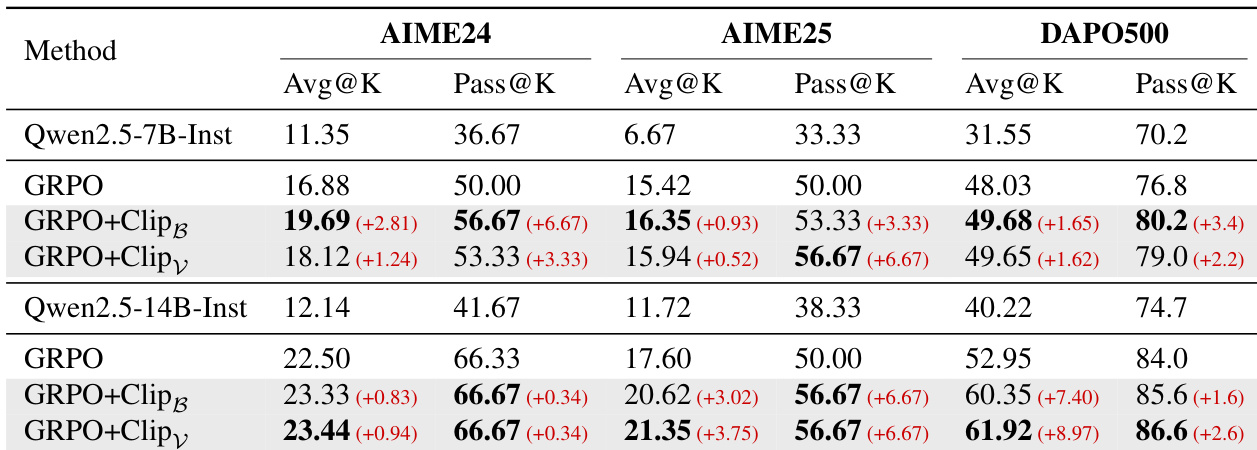
- 使用裁剪方法训练的模型在各数据集上优于标准GRPO,保持探索能力并提升整体性能。
- Pass@K和Avg@K指标分析显示,裁剪增强了解决方案多样性(探索)和模式利用,拓宽了可解问题范围。
- 问题通过率分布显示裁剪鼓励平衡探索,减少极端解决/失败结果,促进在不同问题上取得适度成功。
- 在PPO和多种模型架构(Qwen3、Distilled-Llama、InternLM)上的实验确认裁剪方法在稳定训练和提升性能方面的通用性。
- 对InternLM,裁剪防止训练崩溃并稳定梯度,凸显其在过滤异常token和增强训练鲁棒性方面的作用。
作者使用基于熵的裁剪方法在强化微调期间选择性控制token更新,有效稳定熵并防止其崩溃。结果表明,Clip_B和Clip_V在多个数据集和模型规模上均持续提升模型性能,尤其在Pass@K衡量的探索能力方面。这些增益源于鼓励更广泛的解决方案多样性,而非过度依赖高奖励模式,从而带来更稳健和稳定的训练动态。
作者使用基于熵的裁剪方法在强化微调期间选择性控制token更新,稳定熵并在多个数据集和架构上提升模型性能。结果表明,Clip_B和Clip_V始终优于标准GRPO,尤其在维持探索和防止熵崩溃方面。这些增益在Qwen3、Distilled-Llama和InternLM等不同模型中均被观察到,证实了该方法的通用性。
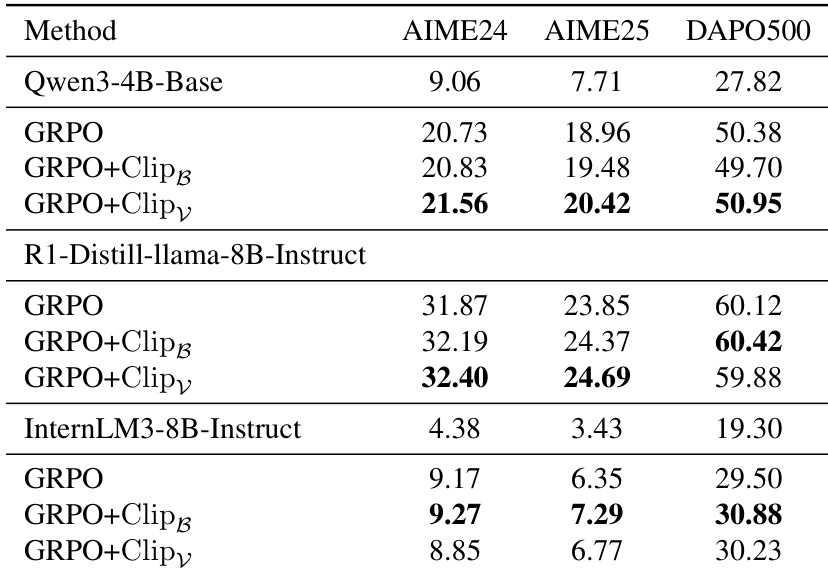
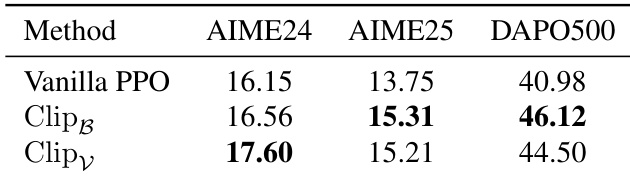
作者将熵控制方法应用于PPO训练,在多个数据集上观察到一致的性能提升。结果表明,Clip_B和Clip_V均优于Vanilla PPO,其中Clip_V在AIME24和DAPO500上取得最高分。这些改进表明,训练期间调节token层级熵可增强模型探索能力与整体有效性。