Command Palette
Search for a command to run...
ASA:面向工具调用领域适应的激活控制
ASA:面向工具调用领域适应的激活控制
Youjin Wang Run Zhou Rong Fu Shuaishuai Cao Hongwei Zeng Jiaxuan Lu Sicheng Fan Jiaqiao Zhao Liangming Pan
摘要
在通用大语言模型(LLM)代理的实际部署中,核心挑战往往并非工具使用本身,而是在快速演进的工具集、API 和协议环境下实现高效的领域自适应。在不同领域间反复进行低秩适配(LoRA)或监督微调(SFT),会导致训练与维护成本呈指数级增长;而基于提示(prompt)或模式(schema)的方法在面对分布偏移和复杂接口时则表现出脆弱性。为此,我们提出激活引导适配器(Activation Steering Adapter, ASA),这是一种轻量级、推理时可执行且无需训练的机制。ASA 通过读取中间激活层的路由信号,利用一个极轻量级的路由模块,生成精确的自适应控制强度,实现对目标领域的精准对齐。在多种模型规模与领域场景下,ASA 在实现与 LoRA 相当的适应性能的同时,显著降低了计算与存储开销,并展现出强大的跨模型迁移能力,因而特别适用于应对频繁接口变更动态的鲁棒、可扩展且高效的多领域工具生态系统。
一句话总结
王、周等人提出了激活引导适配器(ASA),一种无需训练的推理控制器,通过中间层干预引导大语言模型可靠地使用工具,弥合表征与行为之间的差距,在MTU-Bench上将F1分数从0.18提升至0.50,且开销极小。
主要贡献
- 我们识别了一种“懒惰代理”失效模式:工具必要性几乎可从中间层激活中完美解码,但由于严格解析约束下的表征-行为差距,模型未能触发工具模式。
- 我们提出激活引导适配器(ASA),一种无需训练的推理时控制器,使用路由条件化的引导向量混合与探针引导的符号门,以最小开销放大真实意图并抑制虚假触发。
- 在Qwen2.5-1.5B模型上,ASA将MTU-Bench的严格工具使用F1从0.18提升至0.50,将假阳性从0.15降至0.05,仅需20KB资源且无需权重更新。
引言
作者利用大语言模型常在中间层激活中编码工具使用意图,但因表征-行为差距(潜在意图无法在严格解析下转化为离散动作)而未能触发工具模式的观察。先前方法要么依赖脆弱的提示工程,要么依赖成本高昂的参数高效微调,两者在工具模式演进时扩展性差,且存在遗忘或脆弱性风险。其主要贡献是ASA——一种无需训练的推理时控制器,通过路由条件化的引导向量混合与探针引导的符号门,在单一中间层注入干预,放大真实意图同时抑制虚假触发。该方法在Qwen2.5-1.5B模型的MTU-Bench上将严格工具使用F1提升超170%,降低假阳性67%,仅需20KB可移植资源——无需权重更新即可实现鲁棒、可扩展的工具适配。
数据集

- 作者使用一个包含1600个样本的多领域基准,覆盖MATH、CODE、SEARCH和TRANSLATION,数据源自Alpaca和Natural Questions等公开指令跟随与问答数据集。
- 每个样本根据领域特定规则过滤为“需工具”与“非需工具”配对,工具使用通过输出中的显式标记验证。
- 评估集随机下采样至1600个实例——为工程选择,可扩展至更大语料库——严格用于测试,不用于训练。
- 工具调用检测为二元:仅当输出包含时才计为调用。
- 指标包括精确率、召回率、F1、准确率、FPR(非工具触发率)及成功精确率(P_succ),后者要求JSON有效性、模式一致性及有效参数。
- 超参数L、α、τ在验证数据上调整:L通过探针扫描(最佳AUC),α通过F1优化,τ通过网格搜索(0.50–0.70),然后固定用于测试。
- 路由器与探针仅在训练数据上训练;向量表示仅使用CAL数据集。
方法
作者利用ASA——一种推理时干预机制——动态控制冻结的大语言模型是否进入工具调用模式。该方法不修改模型参数,而是在预填充阶段对选定中间层(通常为第18层)的隐藏状态施加一次符号扰动。该干预设计为轻量级、可逆且领域感知,可在保留模型原始能力的同时精确引导工具使用行为。
ASA的核心架构包含三个轻量级组件:领域路由器、各领域意图探针及一组引导向量。推理时,ASA首先从第L层Pre-LN残差流中提取最后一个词的隐藏状态 hL(x)。该表示通过训练集统计标准化为 h~L(x),作为路由器输入。路由器——一个小型线性分类器——将标准化表示映射为预测领域 d^,计算方式为 d^=argmaxdsoftmax(Wrh~L(x)+br)d。同时,领域特定线性探针计算意图概率 p(x)=σ(wd^⊤hL(x)+bd^),估计给定输入下工具调用的适当性。
请参阅框架图,该图展示了ASA如何将这些组件整合为单次干预管道。该方法通过组合领域特定引导向量 v^d^ 与全局意图向量 v^global(按超参数 β 缩放)构建混合向量(MoV)方向:MoV(hL(x))=v^d^+βv^global。全局向量源自工具必要与非工具隐藏状态的类条件均值之差,领域向量则在各领域内类似计算。两者均单位归一化以确保一致缩放。
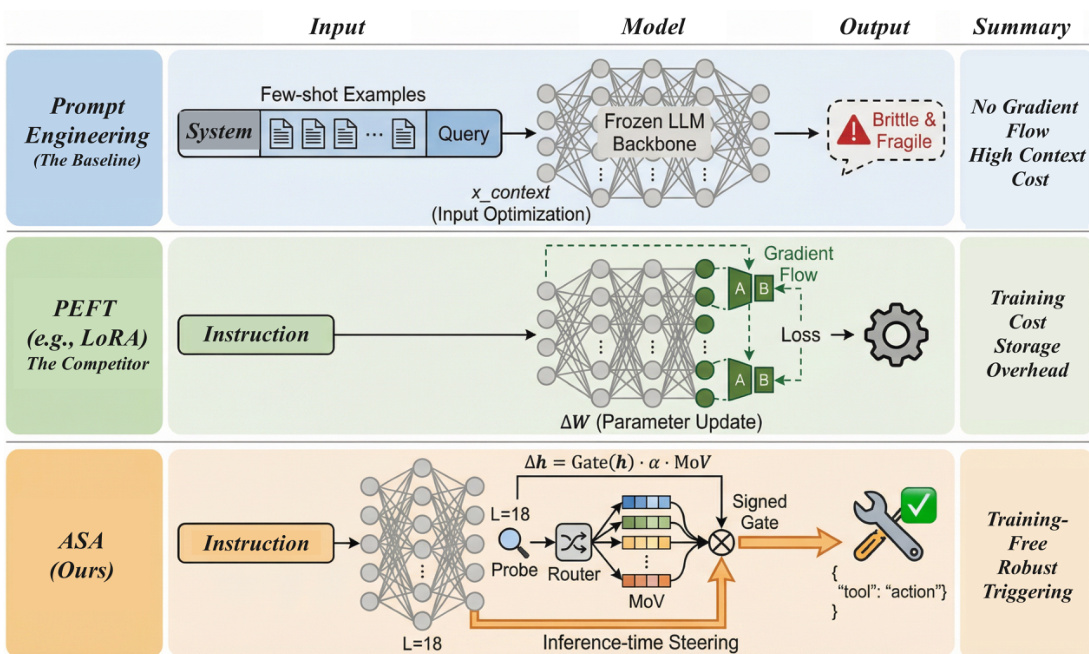
干预由探针置信度控制:计算三元信号 Gate(hL(x)),当 p(x)>τ 时为 +1,p(x)<1−τ 时为 −1,否则为 0,其中 τ∈(0.5,1) 为验证选择的阈值。最终扰动施加为 Δh=Gate(hL(x))⋅α⋅MoV(hL(x)),其中 α≥0 控制干预强度。此符号注入仅修改隐藏状态一次,随后继续从第L层到剩余层的前向传播及自回归解码。
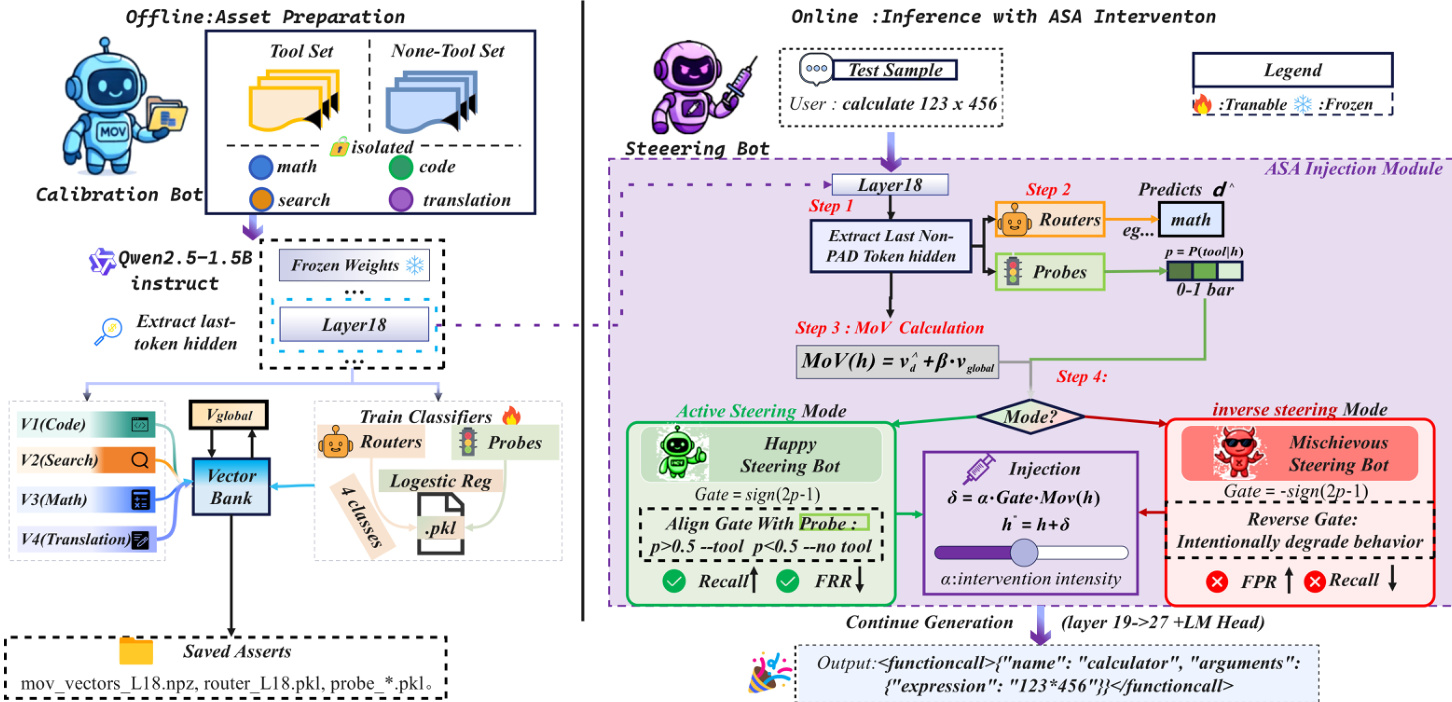
如下图所示,离线阶段使用独立数据集校准引导向量、路由器与探针,所有资源保存供推理使用。在线推理时,ASA模块提取第18层隐藏状态,路由输入,计算MoV,评估门控,并在必要时应用扰动。系统支持“正向引导”(增强工具召回)与“反向引导”(抑制假阳性),通过翻转门控符号实现无需重训练的工具使用行为细粒度控制。
实验
- ASA验证了工具意图在中间层激活中线性可解码,并可通过目标方向向量因果操控以影响早期触发logits。
- 领域特定意图向量减少跨领域干扰,支持模块化路由以提高模式一致性并减少虚假触发。
- 探针引导门控对安全性至关重要,抑制非工具输入上的虚假工具模式激活,同时保留必要情况下的召回率。
- ASA在严格解析下优于仅提示或PEFT基线,实现更优的召回率-FPR权衡,且不破坏触发后输出有效性。
- 该方法无需训练、轻量且可移植,仅需小型引导向量与线性控制器,适用于动态部署环境。
- 最优干预深度随模型规模变化,且ASA仅在基础模型已具备潜在工具调用能力时可迁移。
- 消融实验证实收益源于结构化、意图对齐的控制——而非随机扰动——且结合全局与领域特定方向效果最佳。
- 严格评估协议确保收益反映真实行为控制,而非采样方差或宽松解析,紧密贴合实际部署需求。
作者在第18层使用线性探针评估不同规模Qwen2.5模型的工具意图可解码性,发现近完美的AUC分数,表明无论规模如何,工具意图在中间层激活中线性可分。结果表明该可解码性在所有测试模型规模上统计显著,支持基于引导的工具调用行为控制的可行性。然而,高AUC本身不能保证正确工具执行,因行为还需严格输出格式与模式合规性,超越单纯意图检测。

作者使用仅提示基线建立严格工具触发约束下的性能基线,显示即使少样本提示也会以显著增加假触发为代价提升召回率。完全移除系统规范会导致工具模式崩溃,确认输入级方法在协议变更下脆弱。这些结果凸显了结构化、推理时控制机制的必要性,以在不降低精度的前提下可靠触发工具使用。

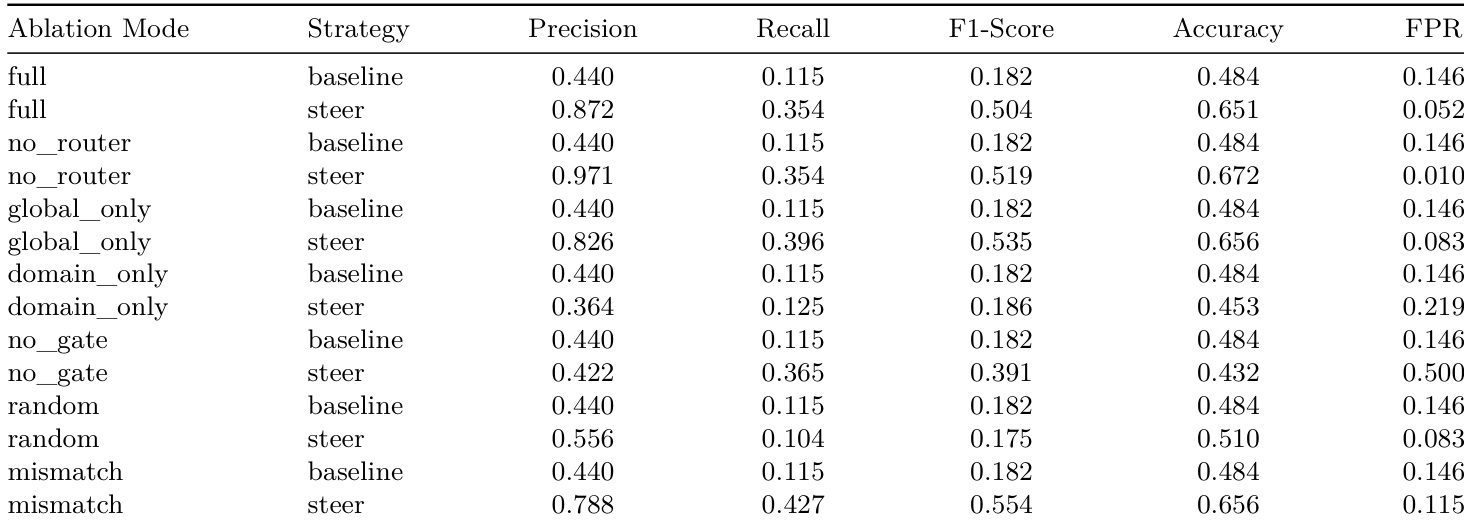
作者使用消融实验隔离引导框架中各组件的贡献,显示完整系统在精度、召回率与FPR间取得最佳平衡。移除探针引导门控会导致假阳性急剧上升,确认其作为关键安全机制的作用,而仅使用全局或领域特定方向会导致次优权衡。随机或不匹配方向无法改善性能,表明结构化、意图对齐的干预对有效控制是必要的。
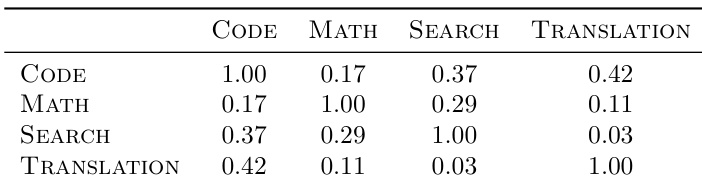
作者使用领域特定意图向量引导工具调用行为,发现这些向量在不同领域间余弦相似度低,表明几何表示不同。这支持按领域路由干预的设计选择,而非依赖单一全局方向,因跨领域干扰会降低模式一致性。结果确认领域感知引导在无关上下文中减少意外激活,同时保留任务特定工具调用。
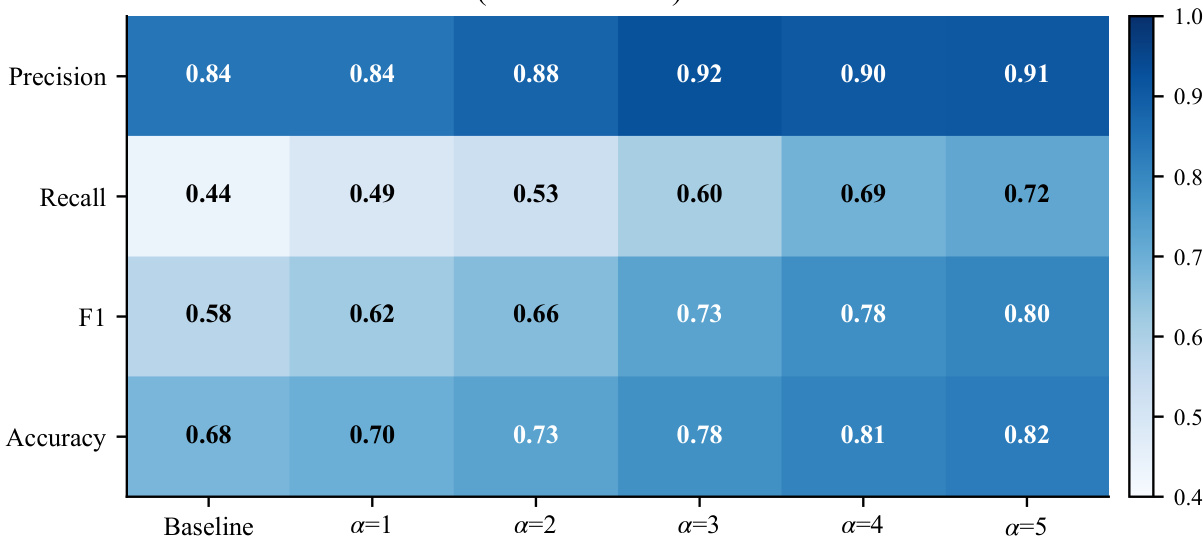
作者使用引导参数α调节工具触发行为,观察到增加α可提升召回率与F1,同时保持或轻微提升精度,表明选择性放大工具意图而非无差别触发。结果显示中等α值取得最佳平衡,更高值因虚假触发风险导致精度损失,验证了探针引导门控对保持控制的必要性。各指标的一致提升确认激活引导有效弥合了潜在意图与严格行为执行在确定性解析下的差距。