Command Palette
Search for a command to run...
AudioSAE:基于稀疏自编码器的音频处理模型理解
AudioSAE:基于稀疏自编码器的音频处理模型理解
Georgii Aparin Tasnima Sadekova Alexey Rukhovich Assel Yermekova Laida Kushnareva Vadim Popov Kristian Kuznetsov Irina Piontkovskaya
摘要
稀疏自编码器(Sparse Autoencoders, SAEs)是解析神经表征的强大工具,但在音频领域的应用仍鲜有探索。本文在Whisper和HuBERT的所有编码器层上训练了SAEs,系统评估了其稳定性、可解释性,并验证了其实际应用价值。实验结果表明,超过50%的特征在不同随机种子下保持一致,且重构质量得以有效保留。SAE提取的特征能够捕捉通用的声学与语义信息,同时精准识别特定事件,包括环境噪声、副语言声音(如笑声、低语)等,并能有效解耦这些成分——仅需移除19%至27%的特征即可消除某一特定概念。通过特征调控,Whisper的误语音检测率降低了70%,而词错误率(WER)仅出现可忽略的上升,充分展示了其在真实场景中的适用性。最后,我们发现SAE特征与人类在语音感知过程中的脑电图(EEG)活动存在显著相关性,表明其表征机制与人类神经处理过程具有高度一致性。相关代码与模型检查点已开源,地址为:https://github.com/audiosae/audiosae_demo。
一句话总结
华为诺亚方舟实验室的研究人员提出用于解释 Whisper 和 HuBERT 的音频稀疏自编码器(Audio SAEs),揭示了稳定且可解释的特征,能有效分离声学与副语言事件;特征引导使虚假语音检测减少 70%,且特征与人类脑电图对齐,实现实用且具神经科学依据的音频分析。
主要贡献
- 我们在 Whisper 和 HuBERT 编码器层上训练稀疏自编码器(SAE),首次对音频表征进行大规模可解释性分析,并发布代码与检查点以推动后续研究。
- SAE 特征在不同随机种子下表现出高稳定性(一致性超 50%),能有效分离声学、语义与副语言概念(如笑声或耳语),仅需移除 19–27% 的特征即可消除特定概念。
- 我们通过引导 Whisper 将虚假语音检测减少 70%,同时对词错误率(WER)影响极小,展示了其实用价值;并通过 SAE 特征与人类在语音感知过程中脑电活动的相关性,体现其神经科学意义。
引言
作者利用稀疏自编码器(SAE)解释 Whisper 和 HuBERT 等大型音频模型,填补了音频表征分析中 SAE 应用不足的空白——尽管其在 NLP 和视觉领域已取得成功。先前的音频可解释性研究多聚焦于神经元级别解释或音乐等狭窄领域,缺乏跨语音模型的系统性评估或实际引导应用。其主要贡献是首次对音频模型进行大规模 SAE 分析,发布训练好的 SAE,并证明所提取特征稳定、语义明确,且可用于现实干预,如减少 Whisper 的幻觉和关联人类神经活动。
数据集
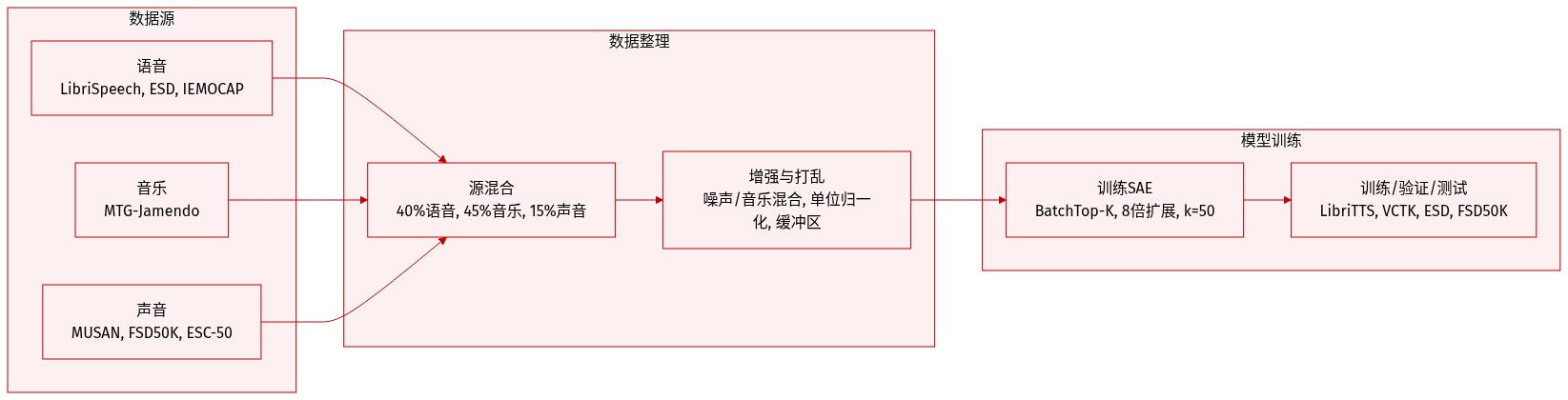
作者使用一个包含 2,800 小时音频的多样化语料库,在 HuBERT-base 和 Whisper-small 上训练稀疏自编码器(SAE),提取每一编码器层的激活值。数据集结合来自 15+ 个公开来源的语音、音乐与环境声音,加权偏向非语音内容:约 40% 语音、45% 音乐、15% 环境音。
关键子集:
- 语音:LibriSpeech、LibriHeavy、ESD、Expresso、CREMA、MELD、IEMOCAP
- 音乐:MTG-Jamendo
- 环境声音:MUSAN、WHAM、FSD50K、Nonspeech7k、DEMAND、VGGSound、VocalSound、ESC-50
每个数据集按其配置权重与规模成比例采样。激活值使用动态批处理策略提取:按数据集权重随机抽取音频,缓冲并打乱激活值以实现随机采样。每批包含 2,500 个向量(50 秒音频),支持 200,000 步的高效训练。
处理流程包括:
- 在线增强:添加噪声(p=0.05)和音乐(p=0.025),信噪比 0–20 dB
- 输入激活值单位归一化
- 内存映射缓冲区用于激活值存储与打乱
- 使用 8 张 V100 显卡进行多 GPU 并行化,用于基础模型推理与 SAE 训练
SAE 采用 BatchTop-K 架构,使用 L2 重构损失、Adam 优化器(lr=2e-4),并在前 10,000 步进行线性稀疏性预热。根据重构质量、稀疏性与活跃特征的权衡,选择 8x 扩展因子和 k=50 的稀疏性参数。
下游分析使用:
- 语音分类:LibriTTS(性别)、VCTK(口音)、ESD(情感)
- 幻觉评估:FSD50K(过滤后)、MUSAN、WHAM(非语音)、LibriSpeech(语音识别基线)
- 领域特化检测:在帧级(τ=0.2, 0.1, 0.04)和音频级(τ=0.5, 0.3)阈值下跨领域对识别跨模态特征角色。
方法
作者利用稀疏自编码器(SAE)将音频表征模型(特别是 Whisper 和 HuBERT)中的多义激活解耦为可解释的单义特征。SAE 架构通过非线性变换将输入激活 x 编码为稀疏潜在表示,再重建原始激活值。编码与解码函数定义如下:
f(x)=σ(Wencx+benc),x^(f(x))=Wdecf(x)+bdec,其中 σ 表示诱导稀疏性的激活函数。在 Jump-ReLU、Top-k 和 Batch-Top-k 中,作者选择 Batch-Top-k,因其在重构保真度与稀疏性之间取得更优平衡。训练使用 L2 重构损失,无辅助正则化,强调模型仅通过稀疏性即可恢复有意义特征。
为评估所学特征的鲁棒性与一致性,作者引入基于交并比(IoU)的分布相似性度量,比较不同数据集上的二值激活模式。若两特征 ak 和 bm 的激活重叠超过阈值 θ,则视为语义相似。特征覆盖率 c(A,B) 量化集合 A 中被集合 B 覆盖的特征比例,支持跨随机种子、层与模型架构的比较。冗余性通过识别单个 SAE 内高 IoU 的重复特征进行评估。
领域特化分析依据特征在语音、音乐或环境声音中的激活频率(帧级与音频级)进行归因。若某特征在领域 i∗ 的激活频率比其他领域高出至少阈值 τ,则归类至该领域,置信度由渐进阈值集推导。未达任何阈值的特征标记为“未分配”;所有领域激活均为零的标记为“死亡”。最终领域分配聚合所有领域组合,通过编码器权重的 t-SNE 投影可视化,颜色强度由阈值索引调制以反映置信度。
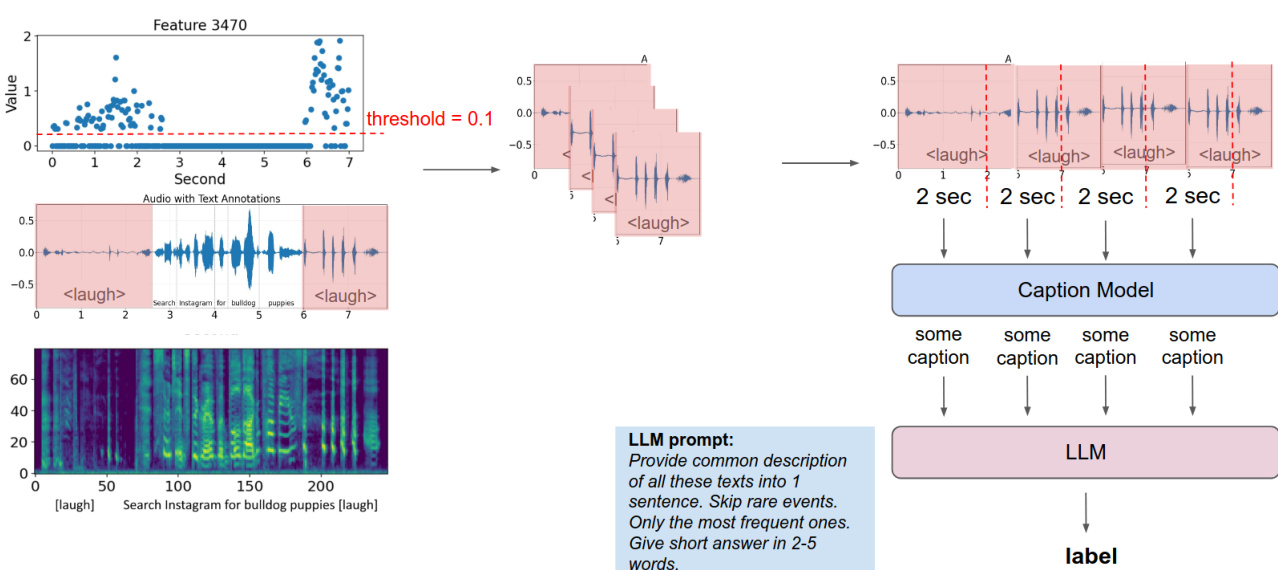
请参考框架图,了解 SAE 衍生特征的解释与应用方式。图中显示特征 3470 随时间的激活模式(阈值 0.1),与标注 的音频片段对齐。这些激活输入到字幕模型生成简短描述,再输入大语言模型(LLM)进行最终标注。此流程展示了稀疏、可解释特征如何映射到音频中的语义事件,支持下游可解释性与控制。
为减少 Whisper 中的幻觉,作者实施 SAE 引导:在潜在空间中进行线性干预,使激活值偏离易产生幻觉的区域。他们通过在非语音数据的 SAE 激活上进行逻辑回归,识别出 top-k 幻觉相关特征,使用 Whisper 内部的 no_speech_prob 作为代理标签。引导向量 sSAE 通过反转 top-k 回归系数的符号构建,确保与促进幻觉的特征相反。推理时,激活值修改如下:
actsteered=x^(f(act)+αsSAE),其中 α 控制引导强度。该干预使非语音输入的 no_speech_prob 分布向 1 偏移,语音输入向 0 偏移,有效减少假阳性,同时保留真阳性。
实验
- 在 Whisper 和 HuBERT 上训练的 SAE 在不同随机种子下特征一致性超 50%,在保持重构质量的同时捕捉声学、语义与副语言内容(如笑声或耳语)。
- 特征解耦效果显著:移除 19–27% 的特征即可消除特定概念(如元音发音),但语音信息比基于文本的 SAE 更分散。
- SAE 特征支持实用引导:抑制 top-100 特征使 Whisper 的虚假语音检测减少 70%,对词错误率影响极小,体现现实应用价值。
- 分类任务显示,少量特征(二元任务 10–150 个)即可捕获大部分任务相关信息,而消除复杂特征(如口音)需抑制数千个特征,表明存在冗余。
- 帧级分析识别出与特定事件相关的特征(如语音边界、笑声、打喷嚏),自动解释发现未标注声音(如警报、鸟鸣),但语音音素常被泛化。
- 领域特化因模型而异:Whisper 显示强音频级音乐特化,峰值位于网络中部;HuBERT 分布更均匀;两者中段层均以语音特征为主导。
- SAE 特征与人类语音感知过程中的脑电活动相关,尤其在 Pz 电极处,时间对齐显著,暗示与神经处理对齐。
- 跨模型比较显示 Whisper 与 HuBERT 特征对齐度低(因训练目标不同),但后期层内稳定性高。
- 评估确认 SAE 鲁棒且可解释,但性能随任务变化;单一指标不足,需多维度评估以适配具体应用。
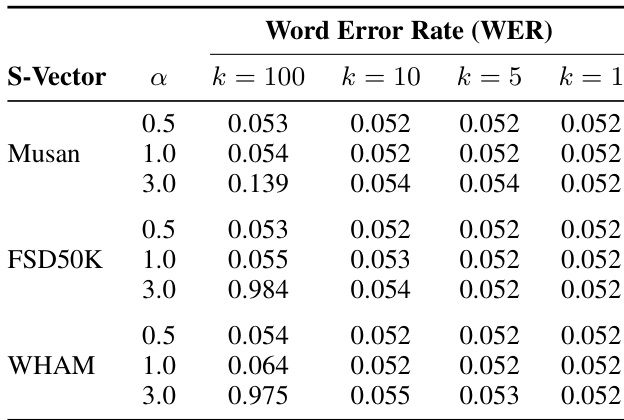
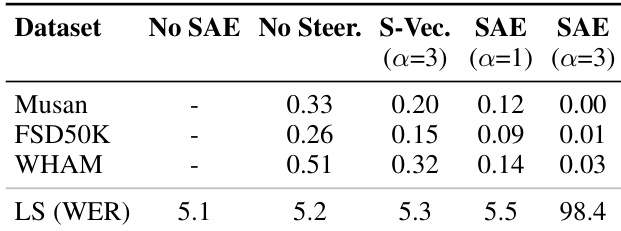
结果表明,使用 top-100 特征并施加中等强度引导(α=1.0)可使 Whisper 在非语音数据集上虚假语音检测减少高达 70%,同时保持接近基线的语音识别准确率。激进引导(α=3.0)可接近零假阳性,但可能损害模型性能,凸显幻觉抑制与功能完整性之间的权衡。效果因数据集与引导向量来源而异,FSD50K 衍生向量抑制效果最强。
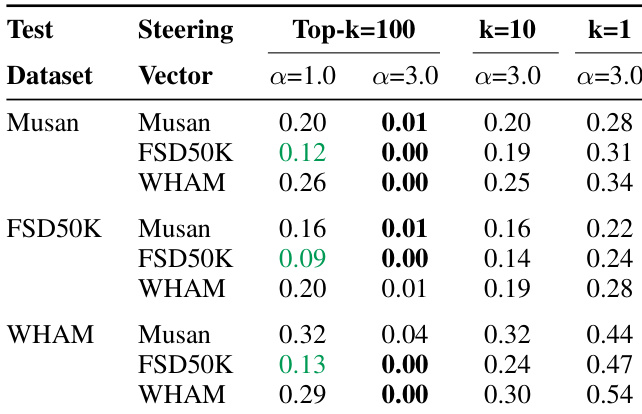
作者使用基于 SAE 的引导显著减少 Whisper 中的虚假语音检测,在非语音数据集上假阳性率最高下降 70%,同时保持接近原始的语音识别准确率。结果显示,中等引导强度(α=1)提供最佳权衡,而激进引导(α=3)严重降低词错误率,表明存在明确的安全性-性能平衡。
作者使用稀疏自编码器从 Whisper 和 HuBERT 音频模型中提取可解释特征,发现超过一半的特征在不同随机种子下保持一致,且这些特征能有效分离声学与语义概念。结果显示,基于这些特征的引导使虚假语音检测减少 70%,对识别准确率影响极小,且部分特征与人类语音感知过程中的脑电活动相关,暗示其与神经处理对齐。
作者使用 SAE 引导减少 Whisper 中的虚假语音检测,在非语音数据集上假阳性率最高下降 70%,同时在干净语音上保持几乎相同的词错误率。结果显示,使用 top-100 特征并施加中等引导强度(α=1)在幻觉抑制与识别准确率间提供最佳权衡,而激进引导(α=3)可能损害语音理解。
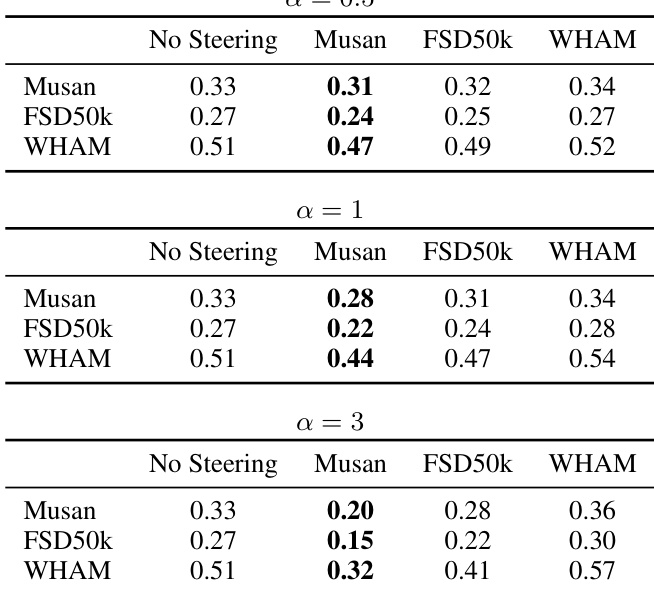
作者使用 SAE 引导减少 Whisper 中的虚假语音检测,发现中等引导(α=1, k=100)使假阳性减少 70%,对 WER 影响极小,而激进引导(α=3)严重损害语音识别。结果显示,引导效果取决于引导向量来源数据集与调整特征数量,Musan 和 FSD50k 在强引导下比 WHAM 提供更稳定的 WER。