Command Palette
Search for a command to run...
DFlash:用于快速推测解码的块扩散方法
DFlash:用于快速推测解码的块扩散方法
Jian Chen Yesheng Liang Zhijian Liu
摘要
自回归大语言模型(LLMs)虽表现出色,但其固有的序列解码机制导致推理延迟高、GPU利用率低。推测式解码(speculative decoding)通过使用一个快速的草稿模型生成候选输出,并由目标模型并行验证,从而缓解这一瓶颈;然而,现有方法仍依赖自回归式草稿生成,仍需顺序执行,限制了实际加速效果。扩散模型语言模型(Diffusion LLMs)提供了一种有前景的替代方案,能够实现并行生成,但当前的扩散模型在性能上通常仍落后于自回归模型。本文提出DFlash,一种基于轻量级块扩散模型(block diffusion model)的推测式解码框架,实现并行草稿生成。该方法通过单次前向传播生成草稿token,并利用目标模型提取的上下文特征对草稿模型进行条件化,从而在保证高质量输出的同时显著提升接受率。实验结果表明,DFlash在多种模型和任务上实现了超过6倍的无损加速,相较当前最先进的推测式解码方法EAGLE-3,最高可提升2.5倍的加速效果。
一句话总结
来自 Z-Lab 的陈健、梁业胜和刘志坚提出了 DFlash,这是一种使用轻量级块扩散模型进行并行草稿生成的推测解码框架,实现了超过 6 倍的无损加速,并通过上下文条件单次生成,在性能上超越 EAGLE-3 达 2.5 倍。
主要贡献
- DFlash 引入了一种推测解码框架,使用轻量级块扩散模型并行草稿生成标记,克服了自回归草稿的顺序瓶颈,同时保持无损输出质量。
- 它基于从目标大语言模型中提取的上下文特征对草稿模型进行条件化,通过单次前向传播实现高接受率草稿,有效将草稿模型转化为利用目标模型推理能力的扩散适配器。
- 在包括 Qwen3-8B 在内的多个模型和基准测试中评估,DFlash 实现了超过 6 倍的加速,最高比 EAGLE-3 快 2.5 倍,展示了在真实服务场景下的卓越效率。
引言
作者利用推测解码加速自回归大语言模型推理,用轻量级块扩散模型取代传统的顺序草稿模型。虽然先前的推测方法(如 EAGLE-3)仍依赖自回归草稿——限制加速比为 2–3 倍——而单独的扩散大语言模型则面临质量下降或步数过多的问题,DFlash 通过使用目标模型的隐藏特征对扩散草稿器进行条件化,规避了这些问题。这使得在单次前向传播中并行生成高质量草稿块,实现高达 6 倍的无损加速,并比 EAGLE-3 快 2.5 倍,同时保持较低的内存和计算开销。
方法
作者采用了一种名为 DFlash 的基于扩散的推测解码框架,通过并行块级生成解耦草稿延迟与生成标记数量的关系。该架构允许使用更深、更具表达力的草稿模型,而无需承担自回归草稿器典型的线性延迟惩罚。核心创新在于通过持久的键值(KV)缓存注入,将目标模型上下文特征紧密集成到草稿模型的内部状态中,确保所有草稿层的一致条件化。
在推理过程中,目标模型首先执行预填充阶段以生成初始标记。从该阶段中,从浅层到深层的分层集合中提取隐藏表示,并通过轻量级投影层融合为紧凑的上下文特征向量。然后将此融合特征注入每个草稿层的键和值投影中,存储在草稿模型的 KV 缓存中,并在所有草稿迭代中重复使用。该设计确保目标模型的上下文信息在整个草稿网络中保持强大且未被稀释,使接受长度能够随草稿深度扩展。如框架图所示,草稿模型处理由目标解码标记(黄色)、掩码标记(绿色)和融合目标上下文特征(蓝色)组成的序列,每个块内使用双向注意力,并通过注入的 KV 缓存进行条件化。
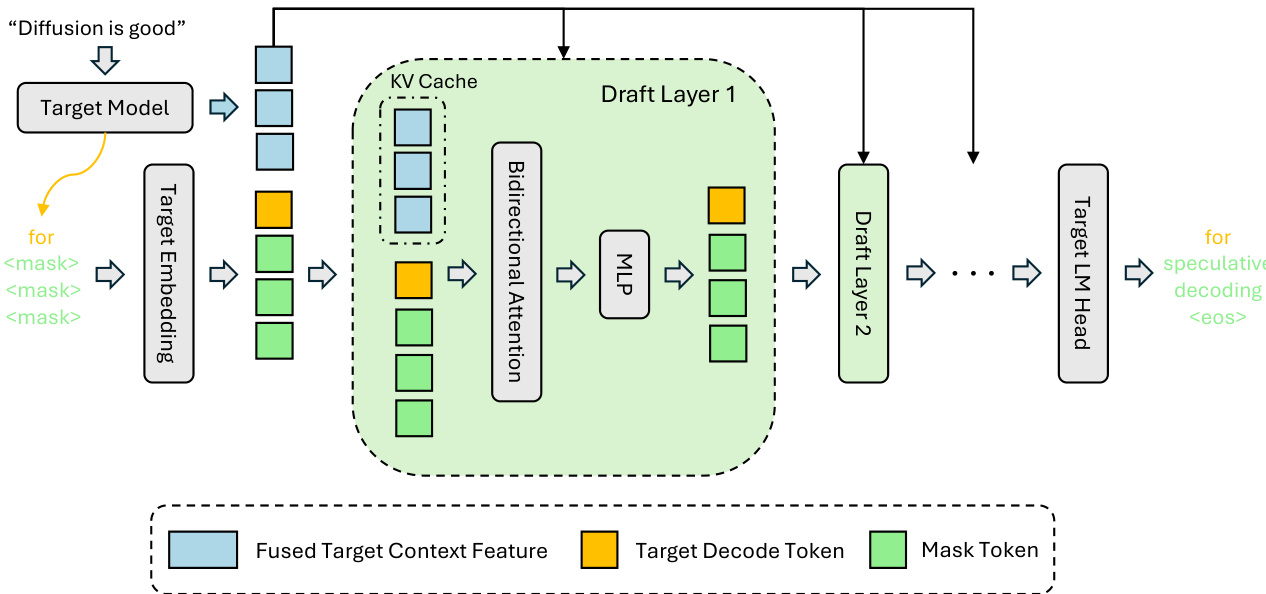
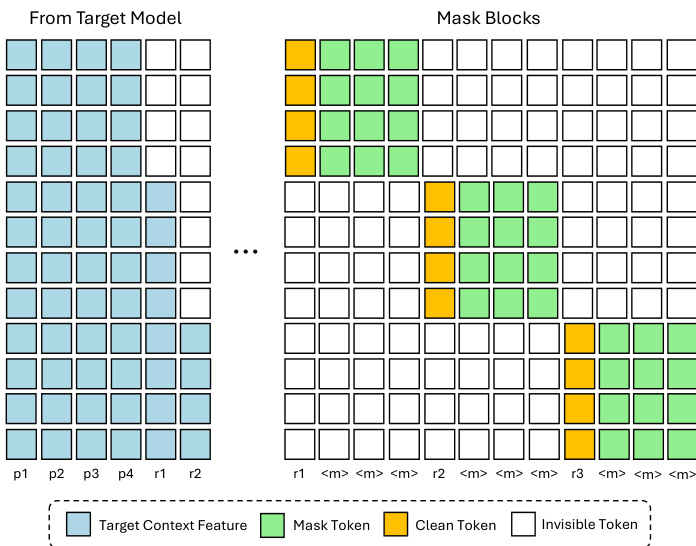
训练结构旨在模仿推理行为。草稿模型被训练为在冻结的目标模型隐藏特征条件下对掩码块去噪。DFlash 并非将响应均匀划分为块,而是从响应中随机采样锚点标记,并构建每个块以锚点开头,掩码后续位置。这模拟了推测解码过程,其中草稿模型始终以目标模型生成的干净标记为条件。所有块被连接成单个序列,并使用稀疏注意力掩码联合处理,强制因果一致性:标记在自身块内双向关注,并关注注入的目标上下文特征,但不跨块关注。这允许在单次前向传播中高效进行多块训练。
为了加速收敛并优先考虑早期标记准确性(这对接受长度影响不成比例),作者在块内每个标记位置 k 应用指数衰减损失权重:
wk=exp(−γk−1),其中 γ 控制衰减率。此外,草稿模型与目标模型共享其标记嵌入和语言建模头,并在训练期间保持冻结。这减少了可训练参数,并使草稿模型的表示空间与目标对齐,有效将其转化为轻量级扩散适配器。对于长上下文训练,每序列的掩码块数量固定,锚点位置在每个 epoch 重新采样,实现高效数据增强而不增加无界计算成本。
实验
- DFlash 在数学、代码和聊天任务中始终优于 EAGLE-3,实现高达 5.1 倍于自回归解码的加速,同时保持更长的接受长度和更低的验证开销。
- 它在推理模式和通过 SGLang 的真实服务场景中展示了强大的效率提升,降低部署成本而不牺牲输出质量。
- 消融研究表明,DFlash 的性能对训练数据选择具有鲁棒性,并受益于更深的草稿模型(5–8 层)和更多目标隐藏特征,尽管最佳层数需在草稿成本和质量之间取得平衡。
- 块大小显著影响性能:在较大块上训练的模型在较小推理块上泛化良好,支持潜在的动态调度以提高效率。
- 训练增强——如位置依赖损失衰减和随机锚点采样——提高了收敛性和接受长度。
- 目标上下文特征至关重要;移除它们仅带来适度增益,凸显其在有效基于扩散的草稿中的作用。
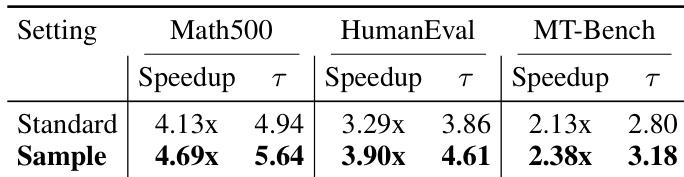
作者使用 DFlash 加速数学、代码和聊天任务的推理,在启用采样时相比标准贪婪解码实现了更高的加速比和接受长度。结果表明,采样在 Math500 和 HumanEval 上尤其改善了效率和草稿质量,表明随机生成增强了推测草稿性能。这表明在推理期间引入采样可显著提升基于扩散的推测解码的实际吞吐量。
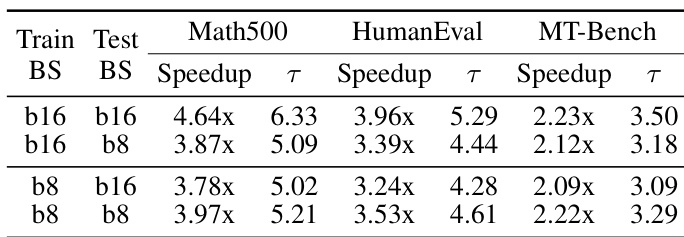
作者在不同训练和推理块大小下评估 DFlash 草稿模型,发现使用较大块大小(例如 16)训练的模型在推理块大小匹配训练大小时实现更高的接受长度和加速比。在较大块上训练的模型也能很好地泛化到较小的推理块大小,但反之则不然,表明在部署设置中具有灵活性。这种行为支持动态块大小调度,以在不同计算约束下优化效率。
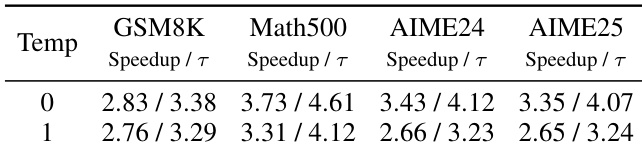
作者使用 LLaMA-3.1-8B-Instruct 在贪婪和非贪婪解码下评估 DFlash 在数学推理任务中的表现,显示在 GSM8K、Math500、AIME24 和 AIME25 上始终优于自回归基线。结果表明,虽然较高温度会降低加速比和接受长度,但 DFlash 仍保持强劲性能,展示了对采样变化的鲁棒性。这些发现突显了该方法在加速复杂推理任务的同时不牺牲输出质量的有效性。
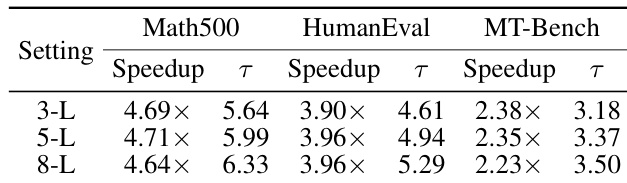
作者评估了不同层数的草稿模型,发现 5 层配置在草稿质量和计算效率之间取得了最佳平衡,实现了最高的整体加速比。虽然更深的模型(8 层)生成更长的接受序列,但其增加的草稿成本降低了净性能增益。结果强调,最佳草稿模型深度取决于接受长度与推理延迟之间的权衡。
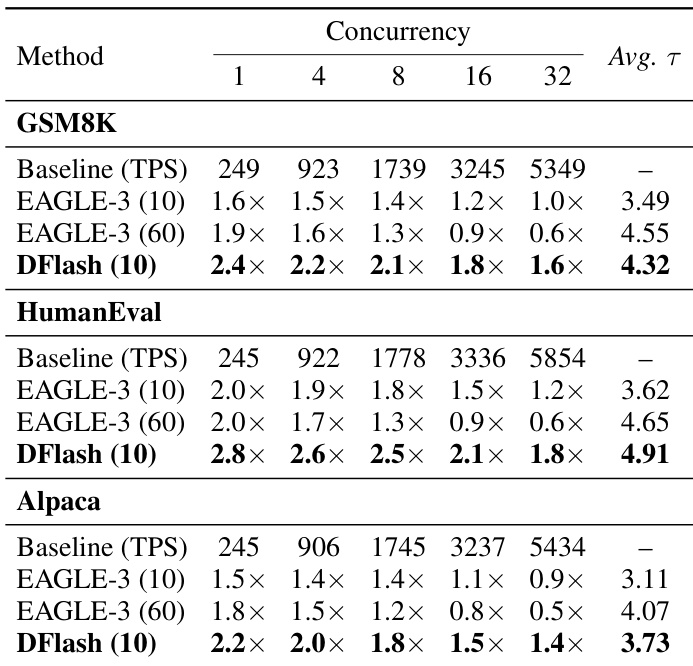
作者使用 DFlash 在 LLaMA-3.1-8B-Instruct 上跨多个任务和并发级别加速推理,并与不同树大小的 EAGLE-3 进行比较。结果显示,DFlash 始终比两种 EAGLE-3 配置实现更高的加速比和更好的接受长度,尤其在较低并发时,展示了其在实际部署设置中的效率和鲁棒性。