Command Palette
Search for a command to run...
UI-Venus-1.5 技术报告
UI-Venus-1.5 技术报告
摘要
图形用户界面(GUI)智能体已成为自动化数字环境交互的一种强大范式,然而实现广泛通用性与持续优异的任务性能仍是重大挑战。本文提出UI-Venus-1.5,一个面向真实世界应用的统一、端到端GUI智能体。该模型系列包含两个稠密架构变体(2B和8B)以及一个专家混合架构变体(30B-A3B),以适应多样化的下游应用场景。相较于此前版本,UI-Venus-1.5引入了三项关键技术突破:(1)引入全面的中段训练阶段,基于30余个数据集共100亿token的训练数据,建立扎实的GUI语义基础;(2)采用全轨迹(full-trajectory)在线强化学习,使训练目标与大规模环境中的长周期、动态导航任务保持一致;(3)通过模型融合(Model Merging)技术构建单一统一的GUI智能体,将领域专用模型(如视觉定位、网页、移动端)整合为一个统一的检查点(checkpoint)。大量实验评估表明,UI-Venus-1.5在多个基准测试中达到新的最先进水平,包括ScreenSpot-Pro(69.6%)、VenusBench-GD(75.0%)和AndroidWorld(77.6%),显著超越此前的强基线模型。此外,UI-Venus-1.5在多种中文移动端应用中展现出稳健的导航能力,能够有效执行真实场景下的用户指令。代码地址:https://github.com/inclusionAI/UI-Venus模型地址:https://huggingface.co/collections/inclusionAI/ui-venus
一句话总结
蚂蚁集团Venus团队推出UI-Venus-1.5,这是一个统一的GUI代理家族(2B/8B/30B),通过100亿token的中期训练、基于完整轨迹回放的在线强化学习及模型合并技术,显著提升现实世界自动化能力,在ScreenSpot-Pro(69.6%)和AndroidWorld(77.6%)等基准测试中超越现有最优模型,同时在中文移动应用中表现优异。
主要贡献
- UI-Venus-1.5引入中期训练阶段,使用来自30多个数据集的100亿token构建基础GUI语义,使模型在强化学习开始前即具备强大的零样本接地和导航任务能力。
- 采用扩展的在线强化学习,结合完整轨迹回放,使训练更贴近长周期导航任务,解决步级轨迹准确性不匹配问题,显著提升AndroidWorld等动态基准测试表现(77.6%成功率)。
- 通过模型合并将领域特定能力(接地、网页、移动)统一为单一端到端检查点,在ScreenSpot-Pro(69.6%)和VenusBench-GD(75.0%)等基准测试中达到最先进水平,同时保持在中文移动应用中的实用性能。
引言
作者利用GUI代理——一种能视觉解析并交互数字界面的系统——在移动端和网页环境中自动化现实任务。以往方法常依赖静态数据集或僵化框架,导致在动态、长周期场景中表现脆弱,且步级与轨迹级准确性存在不匹配。UI-Venus-1.5通过三项关键创新解决这些问题:使用来自30多个GUI数据集的100亿token进行中期训练以建立基础理解;采用完整轨迹回放的在线强化学习,使训练更贴近真实导航;通过模型合并将接地、网页和移动能力统一为单一端到端代理。最终形成一个包含2B、8B和30B MoE的模型家族,在接地和导航基准测试中创下新纪录,并在40多个中文移动应用(如订票、购物)中展现稳健表现。
数据集

-
作者使用由30多个多样化来源(包括Mind2Web、ShowUI和AITW)构建的100亿token中期训练语料库,弥合通用视觉语言理解与细粒度GUI结构建模之间的差距。该语料库按四个功能领域分层:语义感知(20.8%)、GUI-VQA(22.1%)、接地(24.8%)和混合导航推理(32.3%)。
-
每个子集支持不同的监督目标:导航与接地将语言指令与可执行动作对齐;顺序推理生成思维链轨迹;GUI-VQA解释组件语义和布局逻辑;细粒度感知捕捉图标状态、小部件属性及无需OCR的密集描述。
-
为提高数据质量,作者实施迭代精炼流水线:Qwen3-VL-235B根据动作-视觉对齐和任务可达性对样本评分(0–10)。高分样本(≥7)保留;中分样本(4–6)重写;低分样本(0–3)重构或丢弃。此方法使高保真样本比例从69.7%提升至89.7%,随后进行人工验证。
-
通过真实设备数据生成循环进一步扩充语料库:种子提示经MLLM扩展,验证语义唯一性后在云设备上执行并抓取轨迹。验证轨迹作为上下文示例反馈,使生成成功率从17.9%提升至70%以上。最终获得30,000多条验证交互轨迹。
-
所有源数据集的动作均映射到表8定义的统一动作空间,确保训练一致性。中期训练阶段用于构建基础表征,通过编码GUI布局和交互逻辑,为后续强化学习阶段做准备。
方法
作者采用统一的端到端多模态代理架构UI-Venus-1.5,旨在将自然语言指令转化为跨移动和网页环境的可执行GUI交互。系统通过闭环感知-行动机制运行:接收用户任务,从截图中解析当前界面状态,将语义意图转化为具体动作,并迭代执行交互直至任务完成。此设计无需手工构建中间表征或平台特定API,实现跨异构界面的无缝部署。如框架图所示,代理通过统一动作空间(包括Click、Drag、Scroll、Type及新引入的网页特有动作如Hover、DoubleClick、Hotkey)与移动和网页GUI环境交互。
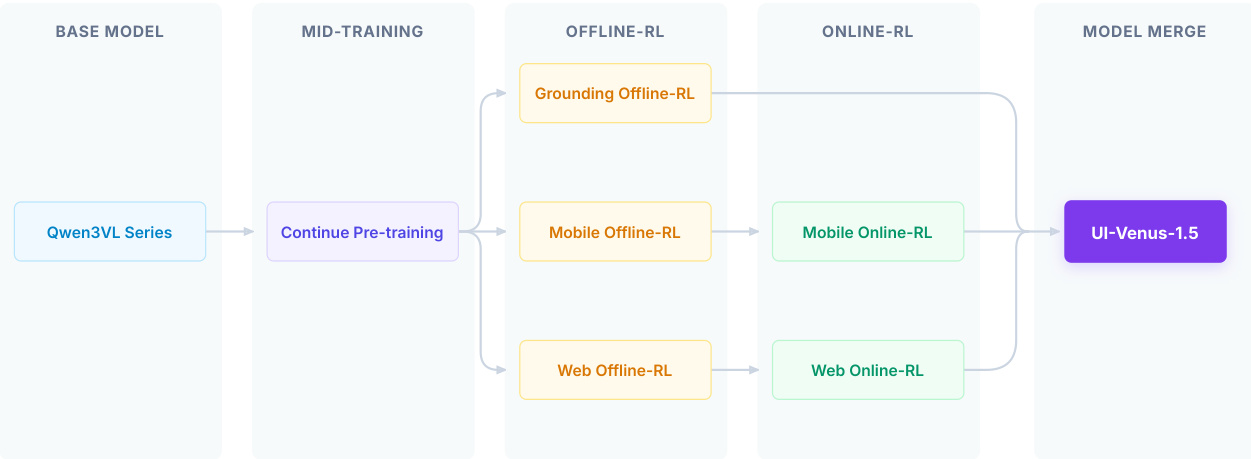
训练流程分为四个阶段。首先基于Qwen3VL系列基础模型,通过在大规模GUI数据上继续预训练进行中期训练,注入领域特定知识。随后进入三个并行的离线强化学习阶段——接地、移动和网页,各阶段使用解耦奖励系统优化特定目标。接地阶段的奖励由格式正确性 Rformat 和点在框内定位精度 Rpoint-in-box 组成,权重分别为 w1 和 w2。关键创新是引入拒绝能力:当指令引用不存在的UI元素时,模型被训练输出 [−1,−1],以缓解幻觉。对于导航任务,奖励系统扩展为包含动作奖励 Raction,其分解为动作类型准确率 Rtype 和基于内容的F1分数 Rcontent 或分层坐标容差 Rcoord。总奖励为 R=w1⋅Rformat+w2⋅Raction。
为解决离线强化学习的局限性——步级奖励无法优化完整轨迹成功率——作者引入在线强化学习阶段。该阶段使用Group Relative Policy Optimization(GRPO)算法显式优化轨迹级奖励。GRPO通过从一组采样轨迹中估计相对优势,无需价值函数。对于任务 q,代理在当前策略 πθold 下生成 G 条轨迹 {τi}。轨迹级优势 A^i 通过将复合奖励 R(τi,q)——包含任务完成、无效动作惩罚和轨迹长度衰减——相对于组均值和标准差归一化计算。GRPO损失定义为:
LGRPO(θ)=−G1i=1∑G∣τi∣1t=1∑∣τi∣min(ri,t(θ)A^i,clip(ri,t(θ),1−ϵ,1+ϵ)A^i),其中 ri,t(θ) 为重要性采样比。为确保稳定性,作者引入针对参考策略 πref 的自适应KL约束(当当前策略优于参考策略时更新参考策略)及退火熵正则化项以平衡探索与利用。最终优化目标为 J(θ)=LGRPO(θ)−LKL(θ)+Lentropy(θ)。
在线强化学习的任务池通过混合策略构建:静态任务使用LLM为预定义应用生成,动态任务通过MLLM从离线轨迹推断并使用语义相似度阈值 ϵ 过滤唯一性。任务按预期步数分层为简单、中等、困难以支持课程学习。成功通过双轨机制验证:基于规则检查系统侧结果,MLLM作为裁判处理语义模糊任务。
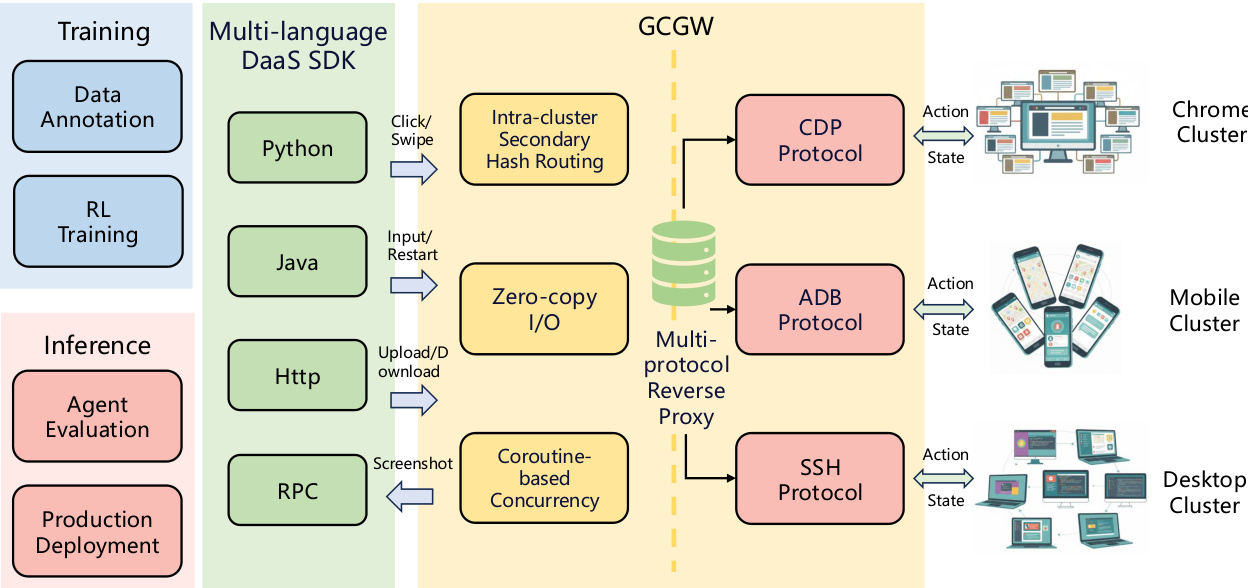
为支持跨异构设备的大规模训练与部署,作者实现Device-as-a-Service(DaaS)层。该架构包含组控制网关(GCGW)和统一客户端SDK。GCGW作为多协议反向代理,抽象ADB、CDP、SSH等控制协议,采用二级哈希路由算法防止连接爆炸,零拷贝I/O实现低延迟转发,协程模型支持高并发。统一客户端SDK提供多语言API,自动化设备生命周期管理并标准化交互语义,屏蔽用户协议复杂性。

最后,在离线强化学习和在线强化学习后,作者将专用模型(接地、移动、网页)合并为单一统一代理。比较线性合并(加权插值模型权重 θlinear=∑i=13wi⋅θi)与TIES-Merge(修剪低幅值更新并解决符号冲突以减少参数干扰),TIES-Merge始终优于线性合并,在无需从头训练多任务模型开销下实现跨领域和谐平衡。
实验
- UI-Venus-1.5在多样基准测试中实现最先进或顶级接地性能,在高级推理(VenusBench-GD)、细粒度专业UI(ScreenSpot-Pro)和复杂桌面任务(OSWorld-G、UI-Vision)中表现优异,同时在广泛跨平台基准测试(ScreenSpot-V2、MMBench-GUI L2)中保持高度竞争力。
- 模型展现强缩放行为,参数量增加时性能持续提升,尤其在ScreenSpot-Pro和Android导航任务等挑战性领域表现明显。
- UI-Venus-1.5在移动端(AndroidWorld、AndroidLab、VenusBench-Mobile)和网页端(WebVoyager)的端到端导航中优于GUI专用及通用VLM,即使仅使用视觉输入(无XML元数据)。
- 中期训练增强GUI特定表征学习,提升潜在空间中聚类可分性和特征判别力,同时不损害全局稳定性,为下游强化学习阶段奠定更强基础。
- 消融研究证实:离线强化学习构建基础接地和导航能力,在线强化学习在复杂动态导航中带来最大提升,模型合并平衡专业化与泛化,略微牺牲细粒度接地以提升导航鲁棒性。
作者在多个接地基准测试中评估UI-Venus-1.5,发现其始终优于通用VLM和先前GUI专用模型,尤其在ScreenSpot-Pro等细粒度专业UI任务和OSWorld-G等复杂推理基准测试中表现突出。结果表明模型规模增加带来清晰性能提升,30B-A3B变体在多数类别中达到最先进或接近最先进水平,展现跨多样UI领域和输入类型的强泛化能力。其架构和训练流程(包括中期训练和强化学习阶段)贡献了卓越的判别能力和稳健跨平台适应性。
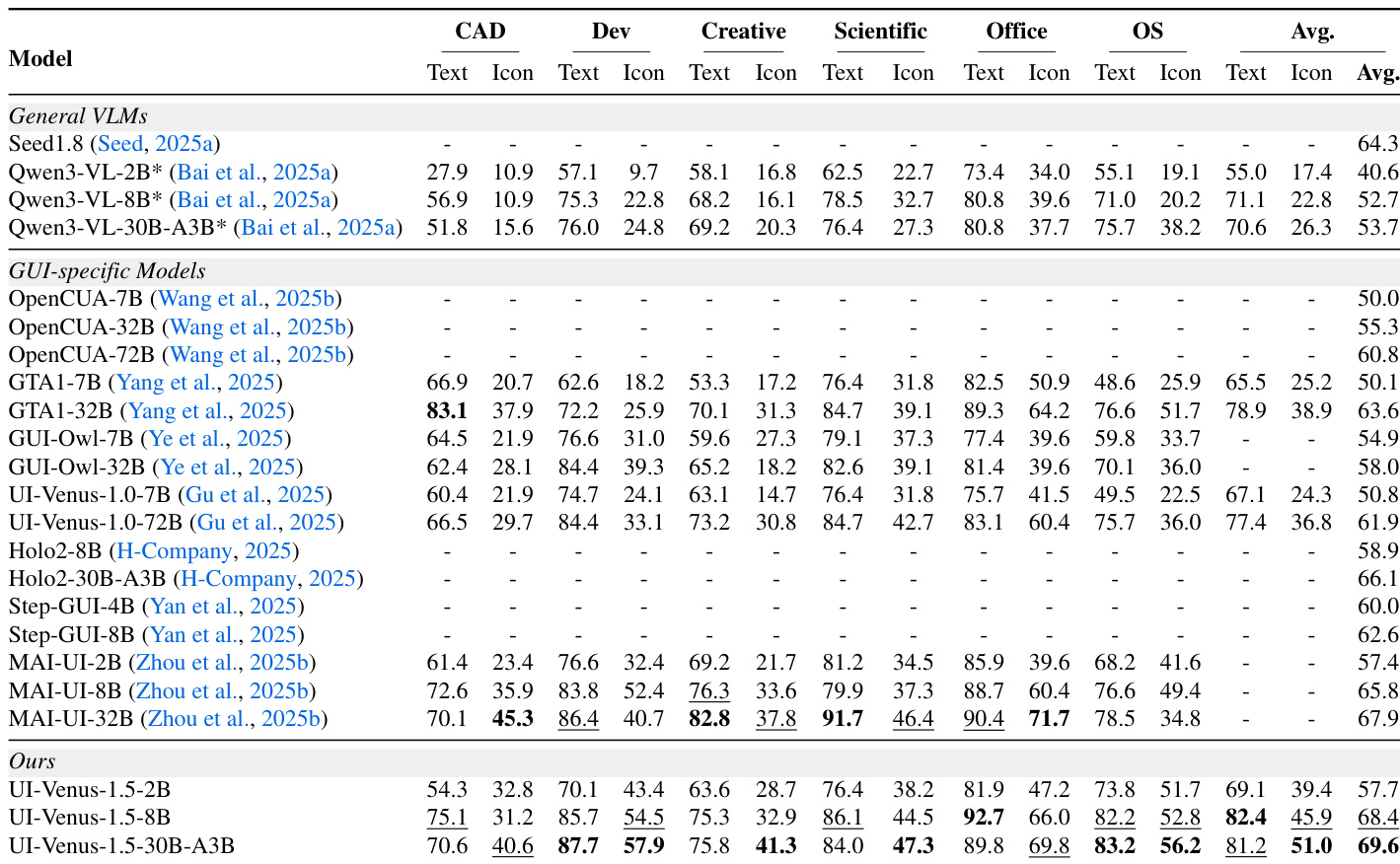
作者在多个操作系统和任务类型中评估UI-Venus-1.5,显示其优于通用VLM和GUI专用模型。结果表明强跨平台泛化能力,30B-A3B变体在多数类别中达到顶级或接近顶级表现,尤其在高级Android和iOS任务中表现突出。模型规模与稳定提升相关,强化其训练流程在增强多样环境GUI理解中的有效性。
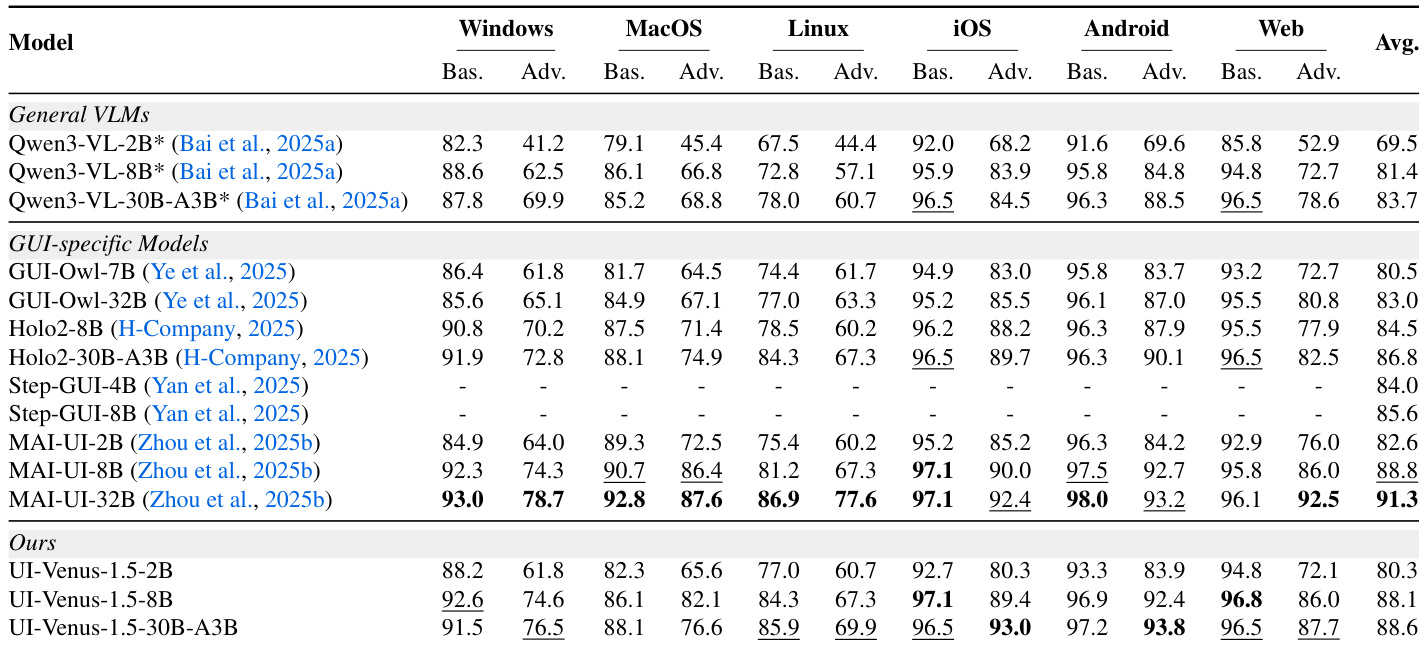
作者在多个导航基准测试中评估UI-Venus-1.5,发现其始终优于通用VLM和GUI专用模型,在AndroidWorld、VenusBench-Mobile和WebVoyager中实现最先进结果。结果表明清晰的缩放收益,更大变体实现更高成功率,8B模型已超越先前72B基线。模型还展现强视觉推理能力,在无XML等辅助输入的动态环境中表现优异。
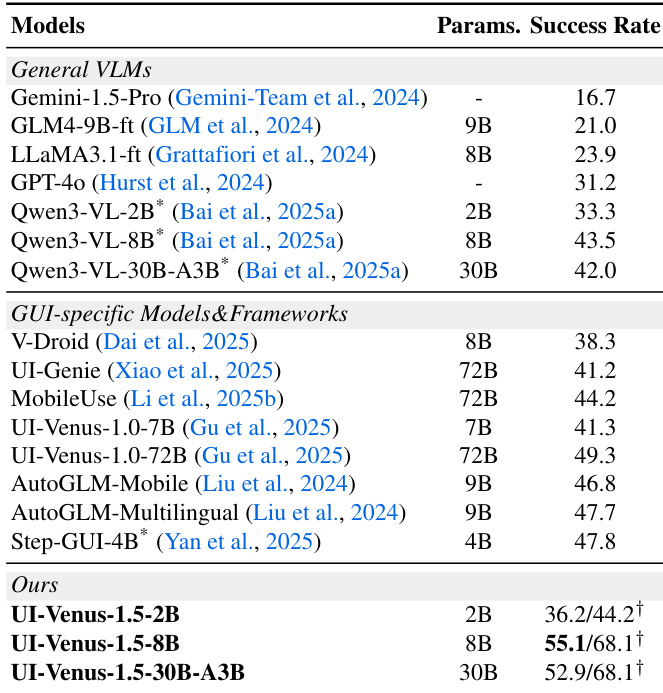
作者在多个接地和导航基准测试中评估UI-Venus-1.5,显示随模型规模增加性能持续提升。结果表明UI-Venus-1.5-30B-A3B在多数任务中达到最先进或接近最先进水平,优于通用VLM和专用GUI模型。模型在移动、桌面和网页环境等多样界面中展现强泛化能力,仅依赖视觉输入无需辅助结构数据。
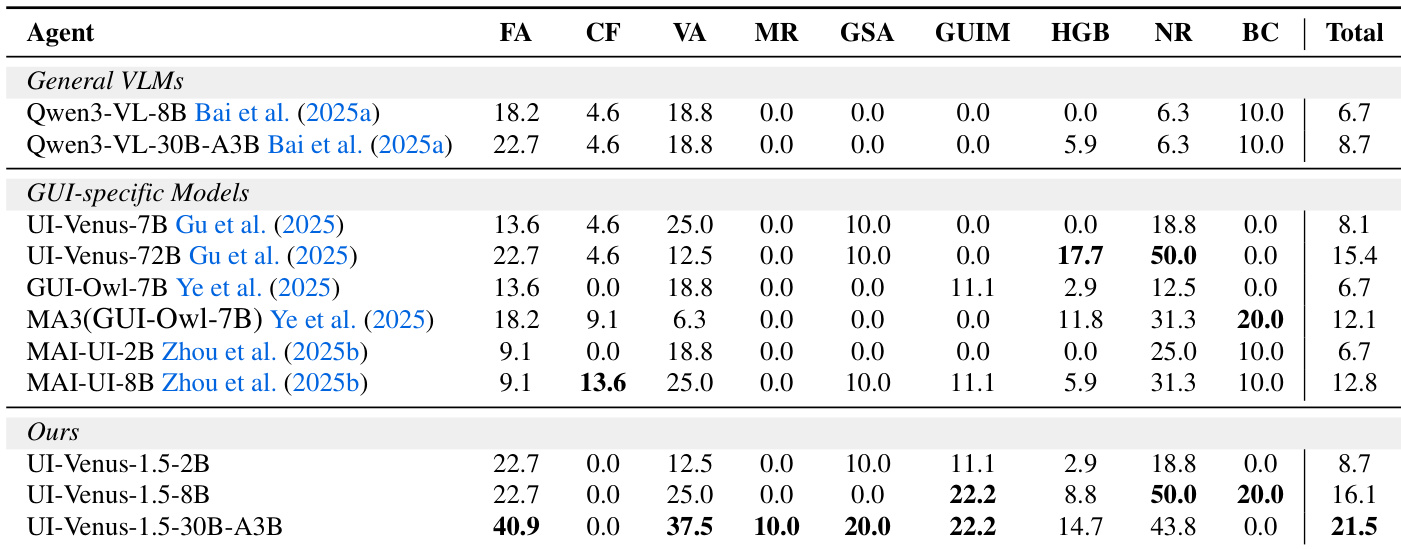
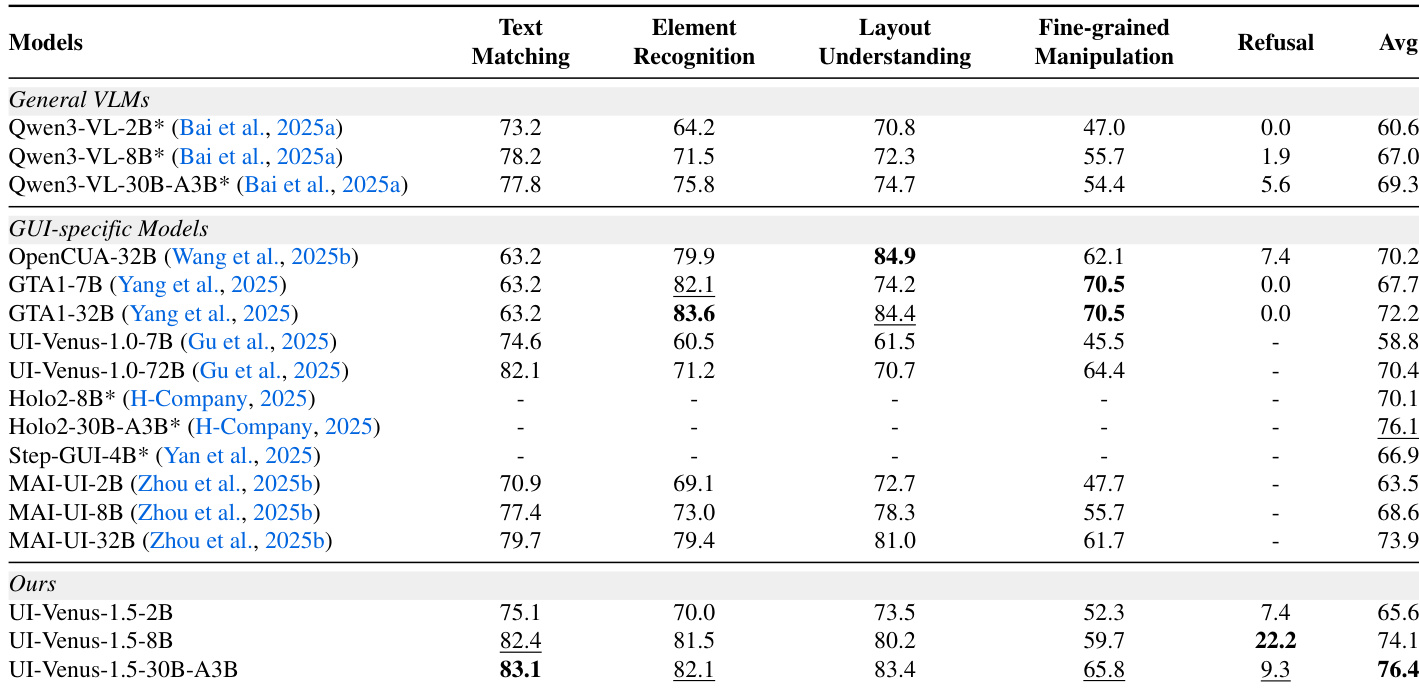
作者在多个接地基准测试中评估UI-Venus-1.5,发现其始终优于通用VLM和先前GUI专用模型,尤其在细粒度操作和拒绝处理方面。结果表明模型规模增加带来清晰性能提升,30B-A3B变体获得最高平均分,展现跨多样UI任务的强泛化能力。其架构和训练流程(包括中期训练和强化学习阶段)贡献了卓越的判别能力和任务对齐能力。