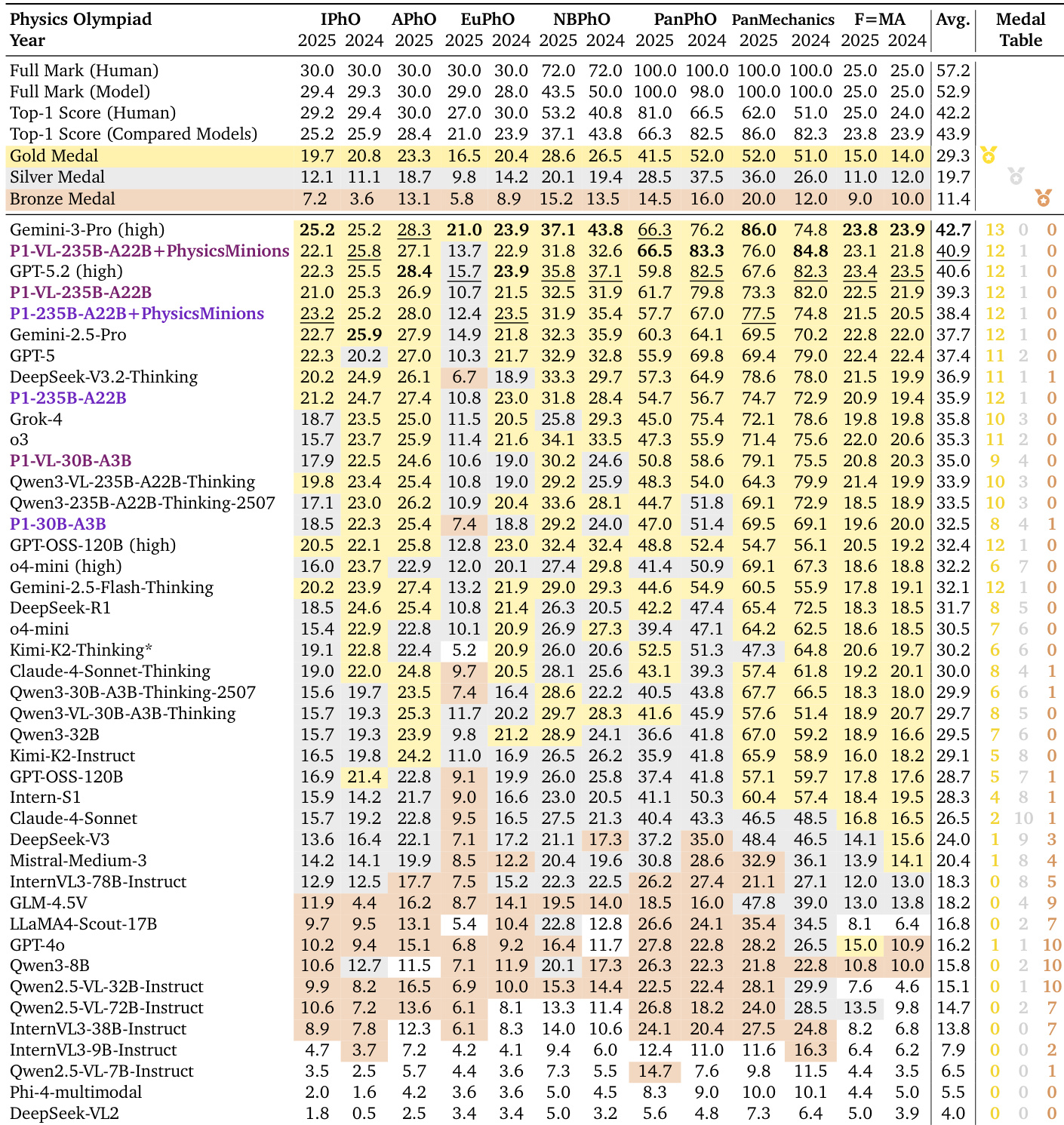
Command Palette
Search for a command to run...
P1-VL:连接视觉感知与物理奥赛中的科学推理
P1-VL:连接视觉感知与物理奥赛中的科学推理
摘要
从符号操作向科学级推理的转变,是大型语言模型(LLMs)发展的关键前沿,而物理学则成为连接抽象逻辑与物理现实的核心检验基准。物理学要求模型在推理过程中严格遵循宇宙运行的基本规律,这一任务本质上依赖于多模态感知能力,以将抽象逻辑锚定于真实世界。在奥林匹克竞赛级别中,图表往往具有构成性而非仅作说明性,其中蕴含了文本中缺失的关键约束条件,如边界条件和空间对称性等。为弥合视觉与逻辑之间的鸿沟,我们提出了P1-VL系列开源视觉-语言模型,专为高级科学推理而设计。我们的方法融合了课程强化学习(Curriculum Reinforcement Learning),通过逐步提升任务难度来稳定模型的后训练过程;同时引入代理增强机制(Agentic Augmentation),在推理阶段实现迭代式自我验证。在HiPhO这一严格基准测试中——涵盖2024至2025年共13场国际物理竞赛试题——我们的旗舰模型P1-VL-235B-A22B成为首个斩获12枚金牌的开源视觉-语言模型,并在开源模型中达到当前最优性能。该代理增强系统在全球范围内排名第二,仅落后于Gemini-3-Pro。超越物理领域,P1-VL在科学推理能力与泛化性能方面展现出卓越表现,在多个STEM基准测试中显著超越基础模型。通过开源P1-VL,我们为实现通用型物理智能奠定了关键基础,推动机器在科学发现过程中更有效地将视觉感知与抽象物理规律相统一。
一句话摘要
由上海人工智能实验室P1团队开发的P1-VL是首个通过融合课程强化学习与代理式自验证,在物理奥赛中斩获12枚金牌的开源视觉-语言模型系列,独特地连接了图示与物理定律,实现了多模态科学推理。
主要贡献
- P1-VL通过将视觉感知与抽象逻辑相结合,解决了物理推理中的关键空白,特别针对奥赛题目中图示编码了文本所缺失的重要约束条件,从而实现基于现实的科学推理。
- 该模型采用课程强化学习,通过逐步提升难度,并在推理阶段引入代理式增强以实现迭代自验证,稳定训练过程并超越标准微调方法,提升推理保真度。
- 在包含13套2024–2025年考试题的HiPhO基准上评估,P1-VL-235B-A22B获得12枚金牌,结合PhysicsMinions后全球排名第二,优于所有其他开源VLM,并在STEM任务中展现出强大的泛化能力。
引言
作者利用物理奥赛题目作为高风险测试平台,推动大语言模型超越符号推理,进入基于现实的多模态科学理解。以往工作大多忽视了图示在物理中的关键作用——视觉内容编码了文本中缺失的重要约束,导致模型仅限于不完整的纯文本推理。为弥合这一差距,他们引入P1-VL——一个通过课程强化学习训练、逐步掌握复杂推理的开源视觉-语言模型系列,并辅以代理框架,支持推理阶段的迭代自我修正。其旗舰模型在HiPhO基准上获得12枚金牌,全球排名第二,且在STEM领域展现出强大泛化能力——为开源物理智能树立了新标准。
数据集
-
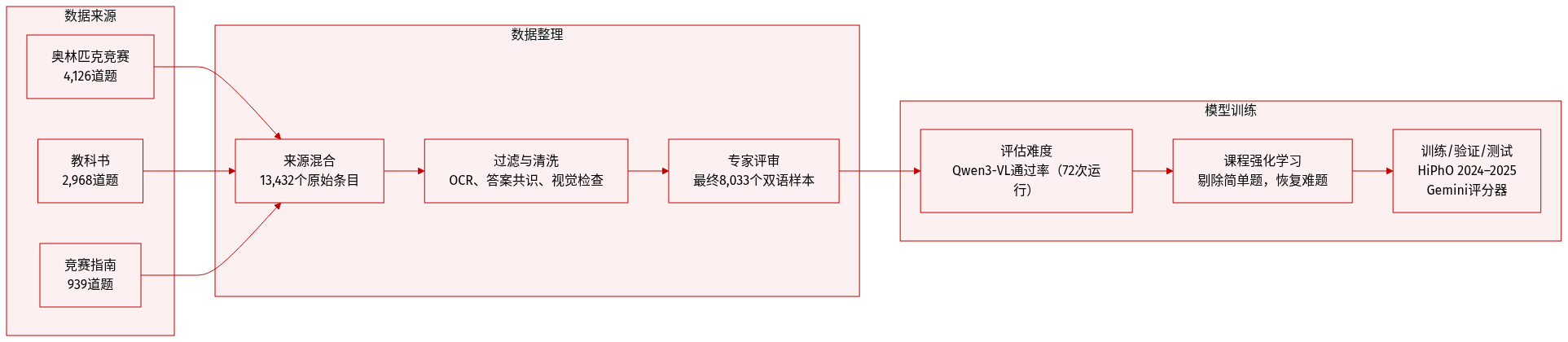
作者使用了一个精选的多模态物理数据集,共包含8,033道题目,来源包括三部分:4,126道来自物理奥赛(含IPhO和APhO,截至2023年)、2,968道来自本科教材、939道来自竞赛指南。选择这些来源旨在平衡概念深度、视觉丰富性与可验证答案。
-
每个子集均经过多阶段处理流程:扫描材料的OCR校正、基于模型的答案提取(使用Gemini-2.5-Flash、Claude-3.7-Sonnet和GPT-4o,采用多数投票共识)、过滤图示生成或开放性任务、通过Gemini-2.5-Flash进行视觉一致性检查,最后由专家审核。最终从初始13,432项中筛选出8,033个高保真、双语样本。
-
训练时采用课程强化学习。首先使用Qwen3-VL-30B-A3B在72次 rollout 中的通过率估算题目难度,移除简单样本(通过率 > 0.7),并使用Gemini-2.5-Flash验证和修正零样本失败题目(通过率 = 0.0)。训练分阶段进行,逐步降低难度阈值,扩大组规模和生成窗口,以维持搜索深度。
-
该数据集仅用于RLVR训练,测试数据来自不同来源。评估在HiPhO上进行,这是一个包含13套近期奥赛试题(2024–2025)的独立基准,使用Gemini-2.5-Flash作为自动评分器,评分内容包括最终答案和推理步骤,模拟人工评分,以便进行奖牌门槛比较。
方法
作者采用强化学习(RL)框架训练视觉-语言模型以解决复杂的物理奥赛题目,将任务建模为马尔可夫决策过程(MDP),其中状态空间包含题目上下文与生成的推理标记,动作空间对应输出标记的离散词汇表。策略通过最大化预期回报进行优化,回报计算为轨迹中各标量奖励之和,奖励信号来源于最终答案相对于真实答案的正确性。为稳定训练并提高样本效率,他们采用组序列策略优化(GSPO),在序列级别而非标记级别操作,使用长度归一化的重要性比率降低方差,并采用裁剪目标约束策略更新。
请参考框架图,该图展示了从原始题目来源到最终训练数据的端到端数据流水线。流程始于PDF转换为Markdown,随后进行问答解析以提取问答对。人工标注者对答案进行标注,确保解决方案符合结构化格式——如符号表达式使用LaTeX、最终答案加框——符合系统提示要求。后处理包括语言转换和专家审核,最终形成包含题目、答案、相关图像和元数据的多模态训练数据。此结构化流水线确保模型学会生成可验证、格式合规的解决方案,同时处理文本和视觉输入。

为解决分布式RL训练固有的训练-推理不匹配问题,作者实现了序列级掩码重要性采样(Seq-MIS),拒绝几何平均重要性权重超过阈值的整个轨迹,从而强制硬信任区域。此机制缓解了rollout与训练引擎之间差异引入的梯度偏差。训练动态通过课程学习进一步稳定,通过逐步增加数据难度、扩大组规模和延长生成窗口来提升复杂性。实现采用VERL框架,RL训练期间冻结视觉编码器和投影层,以保留预训练视觉表示,同时微调语言模型参数。
推理时,系统辅以PhysicsMinions——一个包含视觉、逻辑和审查工作室的多代理框架。视觉工作室处理图示并将其转换为符号表示,支持基于现实的推理。逻辑工作室通过求解器-检查器协作迭代优化解决方案,审查工作室则使用领域特定验证器验证输出。此代理循环支持多模态问题的可扩展、稳健推理,领域自适应机制根据检测到的科学领域将问题路由至适当的求解器和验证器。
实验
- 通过强化学习训练的P1-VL模型在物理奥赛中表现顶尖,优于许多闭源模型,即使无代理增强也展现出卓越的视觉-科学推理能力。
- 代理增强的P1-VL系统甚至超越顶级闭源模型,在多个奥赛中创下新基准,验证了“模型+系统”范式在复杂科学任务中的有效性。
- P1-VL模型不仅限于物理领域,还能良好泛化至数学和多模态推理等多样STEM基准,相比基础模型持续提升,且无灾难性遗忘。
- 通过序列级掩码重要性采样实现训练稳定,缓解训练-推理不匹配,避免其他采样方法导致的RL崩溃。
- 混合训练数据(纯文本 + 图文)提升性能且无负迁移,支持异构数据用于稳健的多模态训练。
- 基于课程的RL训练显著提升推理深度和响应长度,对开发高级科学推理能力至关重要。
- RL训练在包括InternVL系列在内的多种模型架构中均有效,证实其可推广性,可解锁多样基础模型中的潜在科学推理能力。
作者使用物理奥赛基准评估强化学习训练的模型,显示其P1-VL系列在科学推理中优于开源和闭源基线,即使无代理增强。结合多代理系统后,模型在多个竞赛中达到最先进水平,表明结构化训练与系统级协作显著增强复杂问题解决能力。模型亦能良好泛化至其他STEM领域,在纯文本和多模态任务中提升性能,同时保持稳健的视觉推理能力。
作者使用强化学习训练P1-VL模型,在物理奥赛中表现顶尖,并展现出向其他STEM领域的强大泛化能力。结果表明,即使较小变体也优于更大基线模型,结合代理框架进一步提升分数,凸显集成系统设计的价值。模型在纯文本和多模态任务中保留并增强推理能力,表明有效实现视觉-语言对齐且无灾难性遗忘。
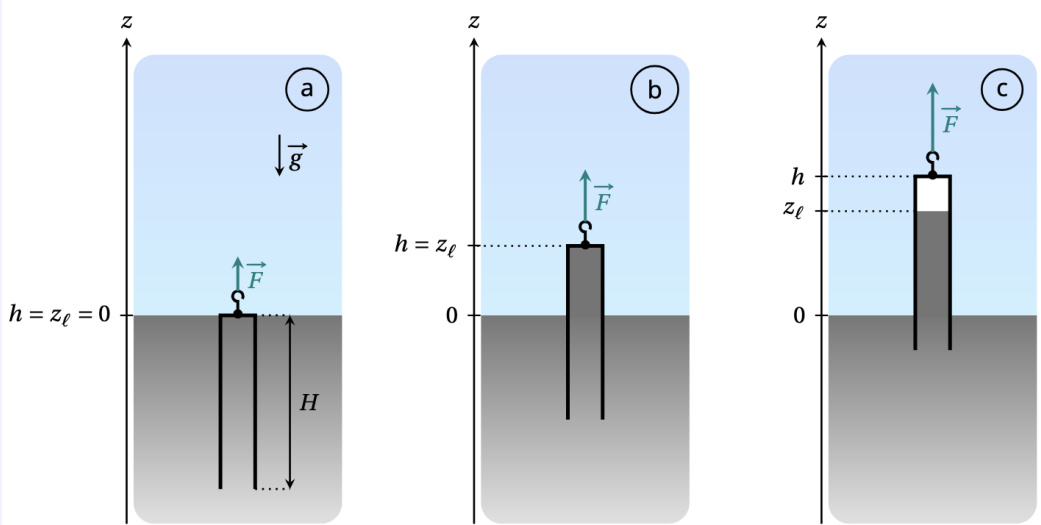
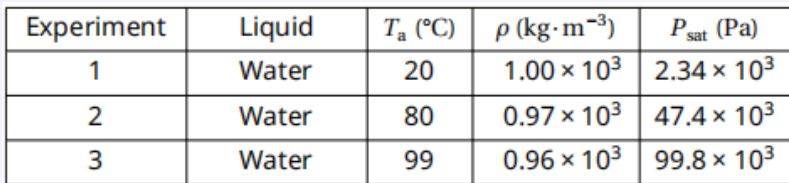
作者使用涉及流体力学与大气压的物理题评估模型推理能力,需整合视觉示意图、表格数据与符号方程。结果显示模型正确识别行为区域并在各实验中精确计算力值,展现视觉感知与科学计算间的稳健对齐。此案例凸显模型在真实物理约束下维持多步推理的能力,无虚构无效假设。

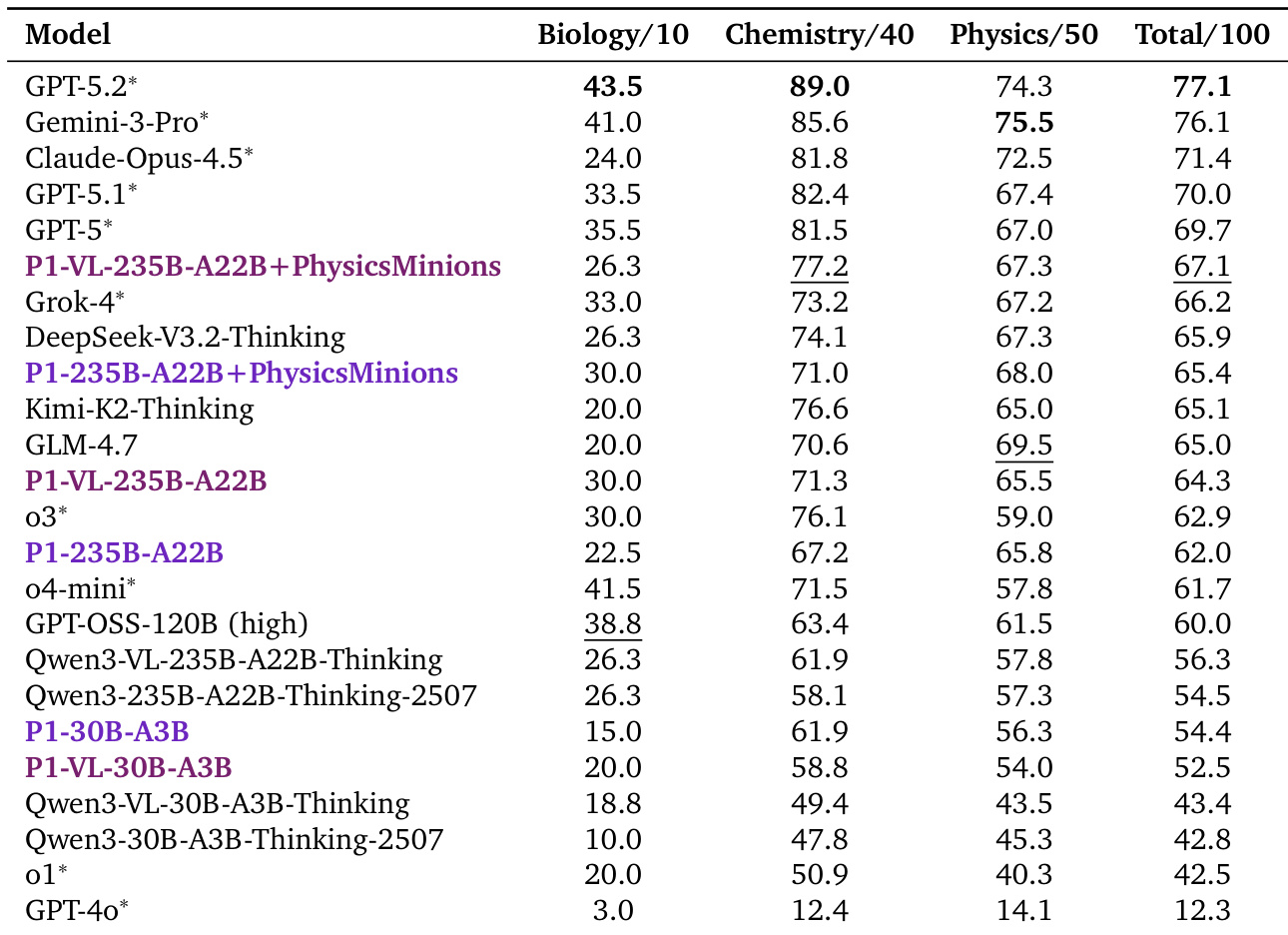
作者使用强化学习训练P1-VL模型,在物理奥赛基准中表现顶尖,最大变体排名所有模型第三,即使无代理增强也优于多个闭源系统。结合PhysicsMinions代理框架后,模型全球排名第二,在多个竞赛中创下新最先进分数,表明多代理协作显著增强复杂科学推理。结果还显示其在物理领域外的强大泛化能力,在多样STEM和多模态基准上持续优于基础模型,表明领域特定训练不仅未损害反而增强了更广泛的推理能力。