Command Palette
Search for a command to run...
BagelVLA:通过交错视觉-语言-动作生成提升长时程操作能力
BagelVLA:通过交错视觉-语言-动作生成提升长时程操作能力
摘要
赋予具身智能体推理任务、预判物理结果并生成精确动作的能力,是实现通用操作的关键。尽管近期的视觉-语言-动作(Vision-Language-Action, VLA)模型利用了预训练的基础模型,但它们通常仅专注于语言规划或视觉预测中的某一方面,很少将这两种能力同时整合以指导动作生成,导致在复杂、长时程操作任务中表现欠佳。为弥补这一差距,我们提出BagelVLA,一种统一的模型框架,将语言规划、视觉预测与动作生成整合于同一系统之中。该模型基于预训练的统一理解与生成模型初始化,并通过训练实现文本推理与视觉预测在动作执行循环中的交替融合。为高效耦合多模态信息,我们引入残差流引导(Residual Flow Guidance, RFG)机制:该机制从当前观测出发,利用单步去噪过程提取预测性视觉特征,从而以极低延迟引导动作生成。大量实验表明,BagelVLA在多个仿真与真实世界基准测试中显著优于现有基线方法,尤其在需要多阶段推理的任务中表现突出。
一句话总结
清华大学与字节跳动Seed的研究人员提出BagelVLA,这是一种统一的VLA模型,通过残差流引导(Residual Flow Guidance)整合语言规划与视觉预测,实现精确、低延迟的动作生成,在复杂多阶段操作任务中显著优于基线方法。
主要贡献
- BagelVLA引入了一个统一框架,在单一Transformer架构内联合执行语言规划、视觉预测与动作生成,解决了以往VLA模型将这些组件孤立处理所导致的碎片化问题。
- 该方法采用残差流引导(RFG),以当前观测为条件,通过单步去噪高效预测视觉动态,实现低延迟的前瞻性预测,无需完整图像合成,同时引导精确动作执行。
- 在模拟和真实世界基准测试中,BagelVLA显著优于现有基线方法,尤其在多阶段任务中表现优异,并展现出对未见过的指令和物体布局的强大泛化能力。
引言
作者利用近期统一视觉-语言模型的进展,解决长时程机器人操作任务,其中智能体需依次理解指令、预测视觉结果并执行精确动作。以往的VLA模型通常仅单独处理语言规划或视觉预测,导致在复杂多步任务中表现脆弱。BagelVLA通过将这三项能力整合到单一Transformer架构中,以统一循环方式交错执行基于文本的规划、视觉预测和动作生成,克服了这一限制。为保持推理效率,他们引入残差流引导(RFG),以当前观测作为结构先验,应用单步去噪预测视觉变化——避免昂贵的全帧生成。该方法在模拟和真实世界环境中均显著优于基线方法,尤其在需多阶段推理和对新指令泛化的任务中表现突出。
数据集

作者使用多源、多阶段数据集训练模型,用于具身子任务规划与关键帧预测。数据组成、处理与使用方式如下:
-
数据集组成与来源:
- 机器人数据:结合自采集专家演示与公开数据集。专有数据手动标注子任务边界(lt);无细粒度标签的公开数据使用Seed-1.5-VL-thinking生成lt和时间边界,随后进行质量筛选。
- 通用数据:包括第一人称人类视频和大规模图像-文本VQA数据。Seed-1.5-VL-thinking为人类视频生成语言标注,但仅执行最终帧预测(无子任务标注)。VQA数据保留通用语言理解能力。
-
关键子集详情:
- 通用VQA(语言联合训练):256万QA对——用于维持基础模型的语言能力。
- 人手数据(视觉动态):31万片段——源自第一人称人类视频,通过Seed-1.5-VL-thinking标注。
- 开源机器人数据(规划与动态):38.2万片段——通过Seed-1.5-VL-thinking处理子任务和帧标注。
- 自采集真实机器人数据(规划与动态):4500片段——手动分割与标注,用于高质量训练。
- 下游机器人任务(阶段2):
- Calvin:使用ABC数据集。
- Robotwin:50任务 × 50片段 = 2500片段。
- Aloha短时程:3000片段。
- Aloha长时程:1500片段。
-
数据使用方式:
- 阶段1(预训练):使用通用VQA(256万)、人手(31万)、开源机器人(38.2万)和自采集机器人(4500)数据微调理解和生成专家。通用QA联合训练保留语言能力。
- 阶段2(动作规划):在带动作标签的下游机器人数据集上微调完整模型,同时训练三项规划任务,实现稳健的交错规划。
-
处理与元数据:
- Seed-1.5-VL-thinking为未标注数据集(如Bridge、EgoDex、AgiBot)生成子任务标注(lt)和时间边界。
- 提示模板(图12和13)从视频或图像序列中提取任务描述和子任务标签。
- 未提及显式裁剪策略;重点在于时间分割与标注合成。
- 所有数据均经过质量筛选,尤其在公开机器人数据集中,以确保可靠的训练信号。
方法
作者采用交错规划范式,解决传统视觉-语言-动作(VLA)模型在长时程操作任务中的局限性。BagelVLA不直接将观测和全局指令映射到动作,而是显式建模联合分布 pθ(at,vt+k,lt∣vt,L),将策略分解为三个顺序推理步骤:语言规划、视觉预测与动作生成。这种分解使模型能通过先识别即时子任务 lt,再预测视觉结果 vt+k,最终生成具身动作 at,从而推理任务的因果结构。训练目标最大化该分解分布的对数似然,优化三个独立损失:Ll 用于子任务预测,Lv 用于关键帧预测,La 用于动作生成。
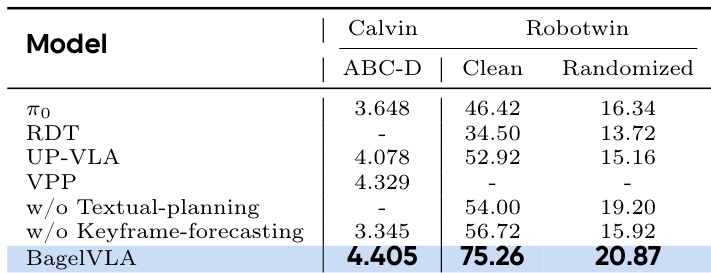
为实现该框架,作者提出BagelVLA——一种统一的混合Transformer(MoT)架构,包含三个专用专家:用于语言规划的理解专家、用于视觉预测的生成专家、用于控制的动作专家。如框架图所示,这些专家在共享的交错标记序列上操作,该序列表示文本、视觉特征和本体状态。理解和生成专家初始化自Bagel模型,采用Qwen2.5-LLM-7B架构,配备不同视觉编码器(SigLIP2用于ViT特征,FLUX VAE用于潜在图像编码)处理观测。动作专家是一个较小的20亿参数Transformer,专为低延迟推理设计,在动作生成时同时关注视觉和文本上下文。
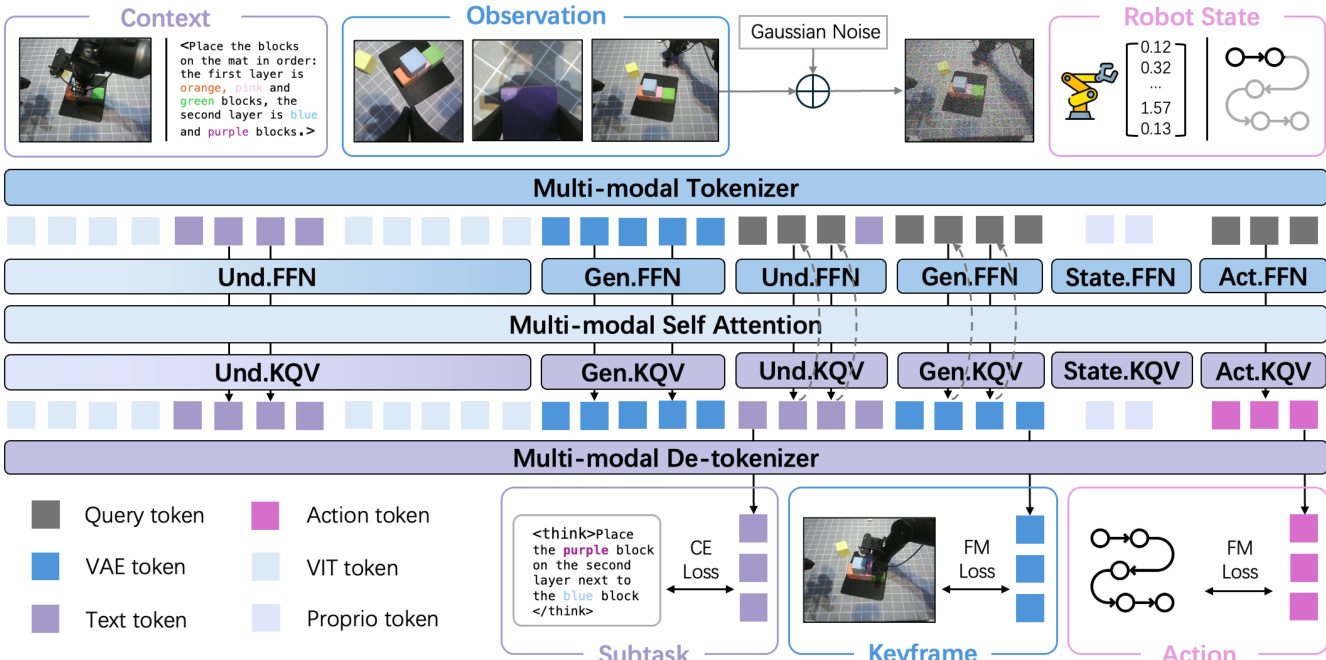
为协调视觉与动作生成过程,作者提出双流匹配机制。如图所示,探索了三种条件方案:完整去噪、联合去噪与单步去噪。完整去噪在动作生成前完全去噪关键帧,确保高保真但延迟高。联合去噪同步两个去噪过程,允许动作专家关注中间噪声关键帧。选定默认方案单步去噪,以关键帧初始噪声状态为条件生成动作,大幅降低计算成本。变体残差流引导(RFG)将当前观测 vt 注入初始噪声,使模型聚焦任务相关动态而非重建静态背景。
训练分两阶段进行。阶段1使用通用VQA数据与机器人数据集预训练理解和生成专家,发展语言规划与视觉动态能力。阶段2引入带动作标签的机器人数据微调完整模型,对齐三项规划任务。推理时,模型以交错方式生成子任务、关键帧与动作,每步去噪仅激活一个专家。单步去噪方案结合异步执行,通过仅更新本体输入并重用缓存的视觉与文本上下文,在单GPU上实现72Hz实时控制。

该模型在堆叠指定顺序积木、组装算术等式等任务中展现出长时程规划能力。在这些场景中,BagelVLA交错语言推理(如计算“21+3=24”)与视觉预测和动作生成,使其能处理需语义理解与物理预见的复杂多步指令。框架设计确保每个动作均基于预测的未来状态与分解的子任务,增强鲁棒性与指令遵循保真度。
实验
- BagelVLA在模拟(Calvin、Robotwin)和真实世界(Aloha-AgileX)环境中展示卓越的交错规划能力,优于包括π₀、RDT、UP-VLA和VPP在内的基线方法。
- 在模拟中,BagelVLA在域内和OOD设置下均表现优异,尤其在结合文本规划时,实现最先进的成功率和对视觉变化的稳健泛化。
- 在真实世界基础任务中,BagelVLA展示强大的多任务学习与OOD泛化能力,利用预训练语义特征处理未见物体与干扰物。
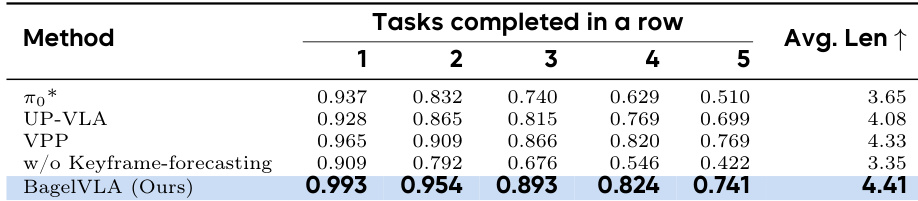
- 对于长时程任务,BagelVLA在规划准确性(近90%)和任务成功率上显著优于基线,验证其推理、遵循指令和执行子任务序列的能力。
- 消融实验证实,结合RFG(递归流引导)的单步去噪在推理速度和生成质量上优于联合或完整去噪,同时保持背景保真度。
- 在语言规划与视觉动态上预训练可提升下游性能,即使无显式交错推理也能实现隐式子任务规划。
- 视觉预测与文本规划均为关键组件:移除任一都会降低性能,尤其在复杂长时程场景中。
- 模型鲁棒性在多样化操作任务中得到验证,包括抓取放置、堆叠、清扫、倾倒和基于算术的序列,在随机化条件和新物体下表现稳定。
结果表明,BagelVLA在干净和随机化Robotwin任务中持续优于基线模型,其完整配置实现最高平均成功率。当结合文本规划与关键帧预测时,模型优势尤为明显,显著提升OOD设置下的性能。消融实验确认交错规划框架的每个组件对稳健动作生成与泛化均有实质贡献。
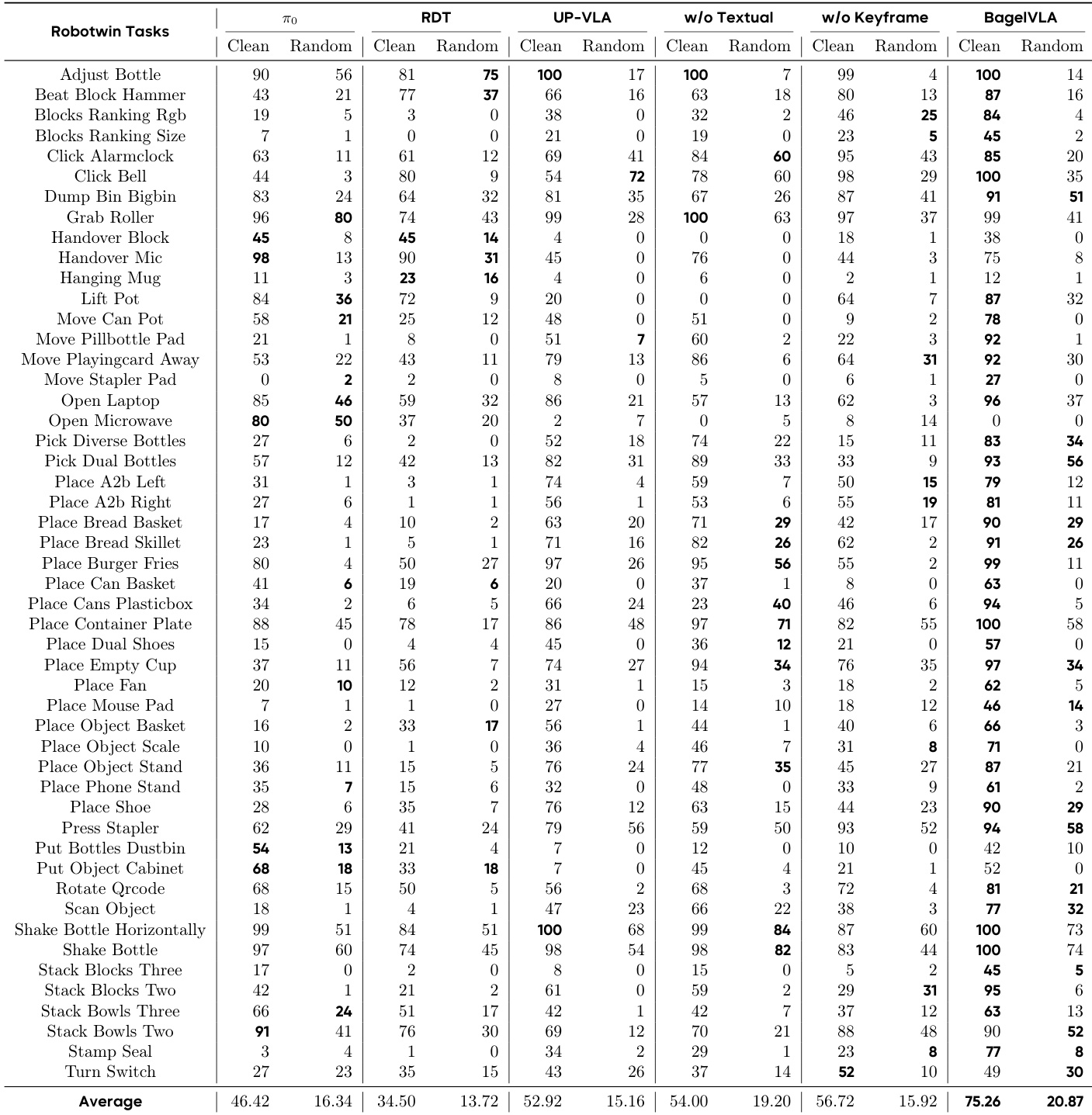
作者使用BagelVLA评估模拟与真实世界机器人任务中的交错规划,与π₀、UP-VLA和VPP等基线对比。结果表明,BagelVLA在模拟环境和真实世界长时程任务中均持续优于所有基线,尤其在结合文本规划与视觉预测时。模型卓越性能源于其将语言引导的子任务分解与视觉目标预测相结合的能力,实现跨多样和未见场景的稳健泛化。
作者在Calvin ABC-D环境中评估不同双流匹配方案,发现单步去噪和RFG均实现每动作块1.23秒的最低推理延迟,而RFG实现最高的任务完成长度3.600。这表明RFG不仅保持快速推理速度,还显著提升任务成功率,可能因其利用初始帧上下文实现更明智的动作生成。

BagelVLA在多样真实世界操作任务中展示卓越多任务性能,在已见和未见物体设置中持续优于基线模型。其优势源于微调期间保留的语义特征,即使在视觉和物体变化下也能实现稳健泛化。模型实现最高平均成功率,尤其在需精细运动控制和语义理解的任务中表现突出。

BagelVLA在Calvin ABC-D和Robotwin基准测试中均优于所有基线模型,在干净和随机化设置中实现最高成功率。结合文本规划与关键帧预测显著提升模型性能,确认其交错规划框架的有效性。结果还表明,视觉预测作为辅助任务可增强对OOD场景的泛化能力,同时保持高操作精度。