Command Palette
Search for a command to run...
Code2World:一种通过可渲染代码生成的GUI世界模型
Code2World:一种通过可渲染代码生成的GUI世界模型
Yuhao Zheng Li'an Zhong Yi Wang Rui Dai Kaikui Liu Xiangxiang Chu Linyuan Lv Philip Torr Kevin Qinghong Lin
摘要
自主GUI代理通过感知界面并执行动作与环境进行交互。作为一项虚拟沙箱,GUI World模型通过实现动作条件下的预测,赋予代理类人的前瞻性能力。然而,现有的基于文本或像素的方法难以同时实现高视觉保真度与细粒度的结构可控性。为此,我们提出Code2World,一种视觉-语言编码器,通过生成可渲染代码来模拟下一视觉状态。具体而言,为解决数据稀缺问题,我们构建了AndroidCode数据集,将GUI轨迹转化为高保真HTML代码,并通过视觉反馈修正机制对生成代码进行优化,最终获得超过80,000对高质量的屏幕-动作配对数据。为了将现有视觉语言模型(VLMs)适配为代码预测任务,我们首先采用监督微调(SFT)作为冷启动策略,以学习格式布局的遵循能力;随后引入渲染感知强化学习(Render-Aware Reinforcement Learning),利用渲染结果作为奖励信号,强制保证视觉语义一致性和动作连贯性。大量实验表明,Code2World-8B在下一UI预测任务中表现卓越,性能媲美GPT-5与Gemini-3-Pro-Image等先进模型。尤为显著的是,Code2World以灵活方式显著提升了下游导航任务的成功率,在AndroidWorld导航任务中使Gemini-2.5-Flash的性能提升高达+9.5%。代码已开源,地址为:https://github.com/AMAP-ML/Code2World。
一句话总结
郑宇豪、钟炼等来自清华、牛津等机构的研究人员提出 Code2World,这是一种视觉-语言编码器,可生成可渲染的 UI 代码以预测下一状态,通过 AndroidCode 数据集和渲染感知强化学习克服保真度与控制权衡问题,使导航成功率较 Gemini-2.5-Flash 提升 9.5%。
主要贡献
- Code2World 引入了一种视觉-语言模型,通过生成可渲染的 HTML 代码预测下一 GUI 状态,在保持高视觉保真度的同时实现细粒度结构控制,克服了纯文本或像素方法的局限。
- 为解决数据稀缺问题,作者构建了 AndroidCode 数据集,包含 8 万+ 高质量屏幕-动作对,从 GUI 轨迹合成并通过视觉反馈机制优化,确保代码与渲染结果对齐。
- 模型采用渲染感知强化学习训练,以渲染图像作为奖励信号,在 AndroidWorld 上实现顶级的下一 UI 预测性能,并将下游代理导航成功率提升 +9.5%。
引言
作者利用结构化 HTML 代码作为原生表示,构建了 Code2World——一种通过生成可渲染代码预测下一界面状态的 GUI 世界模型,实现了高视觉保真度与细粒度结构控制的结合,这是以往文本或像素方法无法同时达成的。现有方法要么丢失空间细节(文本方法),要么难以处理离散 GUI 转换和布局精度(像素方法),限制了其在安全关键或文本密集型界面中的应用。为解决数据稀缺与对齐挑战,他们构建了 AndroidCode 数据集——包含 8 万+ 屏幕-动作对,经视觉反馈优化——并采用监督微调后接渲染感知强化学习进行训练,该方法以渲染图像和动作一致性作为奖励信号。Code2World-8B 在下一 UI 预测任务中超越主流模型,并作为即插即用模拟器集成后,使下游代理导航成功率提升 +9.5%。
数据集
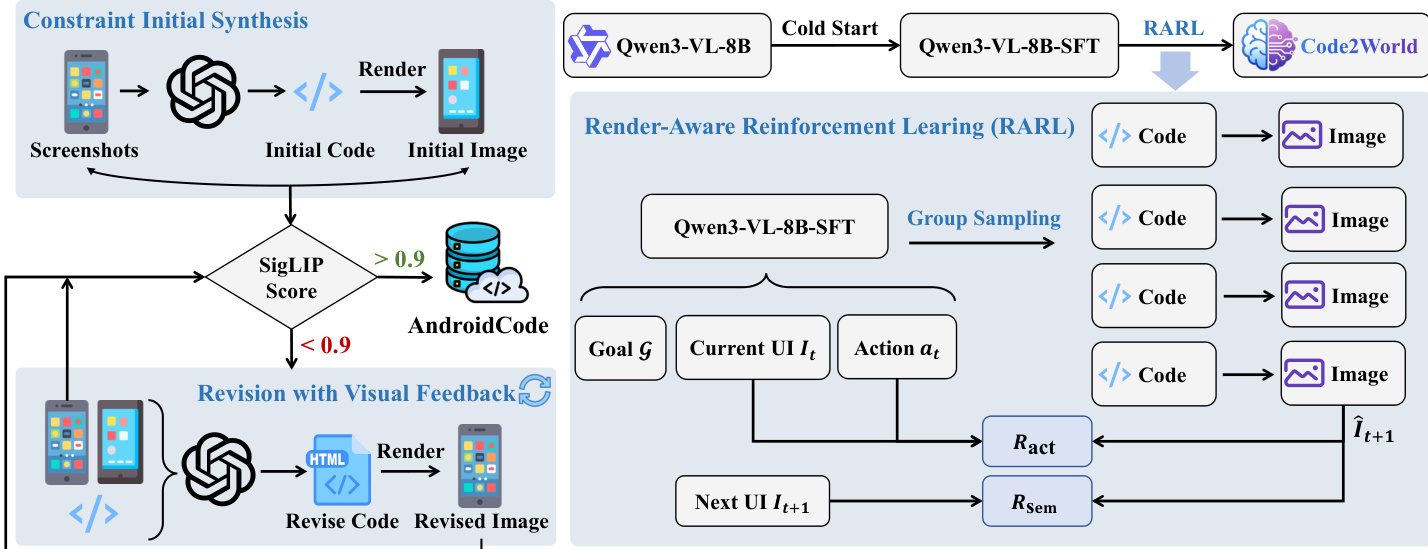
- 作者合成了 AndroidCode,一个大规模 GUI 截图与干净 HTML 表示配对的数据集,源自 Android Control 语料库,以解决现有基准中此类配对数据稀缺的问题。
- 数据集通过两阶段自动化流程构建:第一阶段,GPT-5 使用固定根容器和语义占位符(如 [IMG: Red Shoe])从截图生成受限 HTML,确保代码自包含且无依赖;第二阶段,通过视觉反馈循环使用 SigLIP 相似度分数(阈值 τ = 0.9)修订低保真输出,每样本最多修订一次。
- 经一次修订后仍不满足视觉保真度阈值的样本被丢弃,确保最终语料库仅保留高质量的 (I, C) 对。
- 为指令微调,作者通过叠加红色圆圈(表示点击)或方向箭头(表示滑动)增强视觉输入以引导空间注意力,并将稀疏动作日志扩展为描述意图、因果关系和预期结果的自然语言指令。
- 所有增强视觉和扩展指令均按标准化提示模板格式化,指导模型在训练中模拟界面动态。
方法
作者采用可渲染代码生成范式建模数字环境的确定性状态转移,将问题定义为“下一 UI 预测”。该方法不直接操作像素空间,而是通过生成可执行 HTML 代码,再由浏览器引擎确定性渲染为视觉状态,从而靶向界面的底层结构表示。核心状态转移被形式化为两步条件生成过程:给定视觉观测 It、用户动作 at 和任务目标 G,多模态生成器 Mθ 生成预测 HTML 代码 C^t+1,随后通过浏览器引擎 R 渲染为预测视觉状态 I^t+1。该方法将结构推理与像素级渲染解耦,实现对 UI 布局的精确控制,同时抽象掉资产生成。
为训练多模态生成器 Mθ,作者采用两阶段优化策略。第一阶段为监督微调(SFT),使用 Qwen3-VL-8B-Instruct 作为骨干模型,基于多模态三元组 (It,at,G) 训练以预测真实 HTML 代码 C∗。该阶段灌输语法与结构知识,但忽略渲染视觉结果。第二阶段为渲染感知强化学习(RARL),通过渲染视觉状态 I^t+1 的反馈精炼策略。该阶段引入复合奖励函数 Rtotal=λ1Rsem+λ2Ract,其中 Rsem 使用 VLM-as-a-Judge 评估渲染预测与真实值之间的语义对齐,Ract 验证状态转移是否逻辑上源于执行动作 at,同样由 VLM 判断器评估。模型使用组相对策略优化(GRPO)进行优化,该方法基于一组采样输出计算优势,并在更新参数时通过 KL 散度项惩罚偏离 SFT 策略。
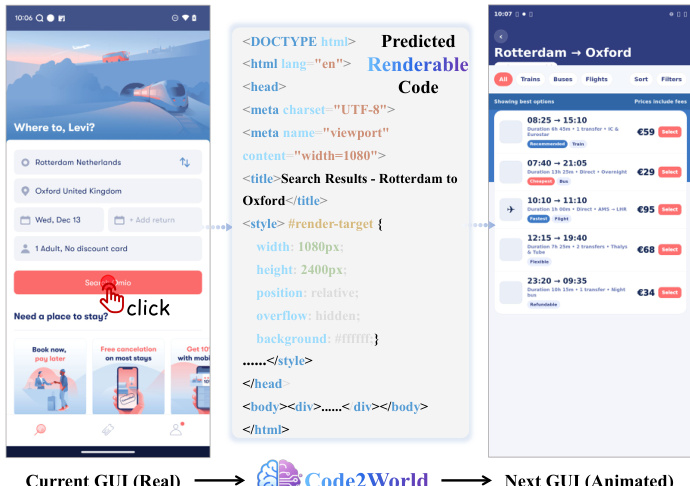
推理时,Code2World 通过“提出、模拟、选择”模式作为 GUI 代理的即插即用模拟器。代理首先生成 K 个候选动作及关联的推理与置信度评分。对每个候选,Code2World 通过生成 HTML 代码并渲染模拟其结果 UI 状态。评分器随后根据任务目标评估模拟结果,选择最能推进任务进展的动作。该机制使代理能够通过基于渲染视觉后果的决策,检测并修正幻觉或不合逻辑的计划。

训练数据 AndroidCode 通过受限初始生成阶段后接视觉反馈修订循环合成。初始 HTML 从截图生成并渲染;若渲染图像与目标图像的 SigLIP 分数低于 0.9,则迭代修订代码直至对齐。这确保严格的结构保真度,同时允许图像和图标使用语义占位符(如 [IMG: Avatar]),以避免幻觉外部资产。模型架构强制执行严格结构规则:所有内容包裹在 #render-target div 中并指定精确像素尺寸,body 重置为零边距/填充和透明背景,样式应用于容器而非 body 以确保一致渲染。

训练超参数针对高分辨率截图和冗长 HTML 调整:模型使用 24,576 令牌上下文窗口,DeepSpeed ZeRO-2 优化内存效率,Flash Attention 提升吞吐量。第一阶段,视觉编码器和投影器冻结,语言模型全量微调两个周期。第二阶段,GRPO 每提示采样四个输出,温度设为 1.0,KL 惩罚系数设为 0.01 以平衡探索与策略稳定性。视觉与动作奖励权重相等,确保结构与逻辑保真度兼顾。
实验
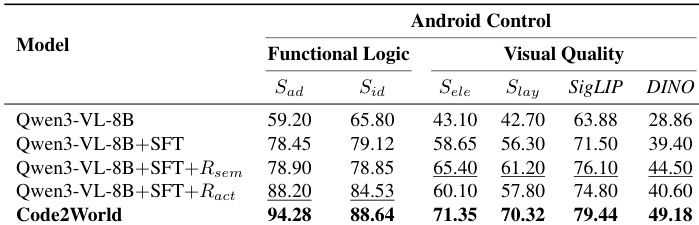
- Code2World 在预测下一 UI 状态方面表现出色,结合功能逻辑(动作遵循性与可识别性)与视觉保真度(元素对齐与布局完整性),尽管体积紧凑,仍优于更大模型。
- 它在域内和分布外 GUI 环境中均表现出强大泛化能力,即使视觉相似度下降仍维持高动态逻辑得分,表明其内化了交互规则而非仅记忆布局。
- 作为即插即用模拟器,它显著提升 GUI 代理在离线和在线设置中的性能,通过预判动作后果改善决策与任务成功率。
- 消融研究证实,结合监督微调与双重强化学习奖励(语义与动作导向)对实现逻辑与视觉精度平衡至关重要。
- 定性示例显示,Code2World 帮助代理避免冗余动作、发现更高效策略、并通过准确模拟未来 UI 状态做出情境适当决策。
作者使用 Code2World 增强 GUI 代理,使其能模拟未来界面状态,从而提高决策准确性和任务成功率。结果表明,将 Code2World 与通用及专用代理集成后,始终提升定位准确率与成功率,证明其跨模型的即插即用有效性。此提升源于模型能可靠预判动作后果,帮助代理避免冗余或低效步骤。

Code2World 在预测下一 UI 状态方面表现卓越,有效平衡功能逻辑与视觉质量,在域内和分布外基准测试中均优于大型开源模型和专有图像生成系统。其可渲染代码生成方法实现对交互动态与结构保真度的精确模拟,即使泛化至未见过的应用与设备界面仍保持高性能。模型内化 GUI 交互规则而非依赖像素匹配,使其成为提升现实场景代理导航的稳健基础。
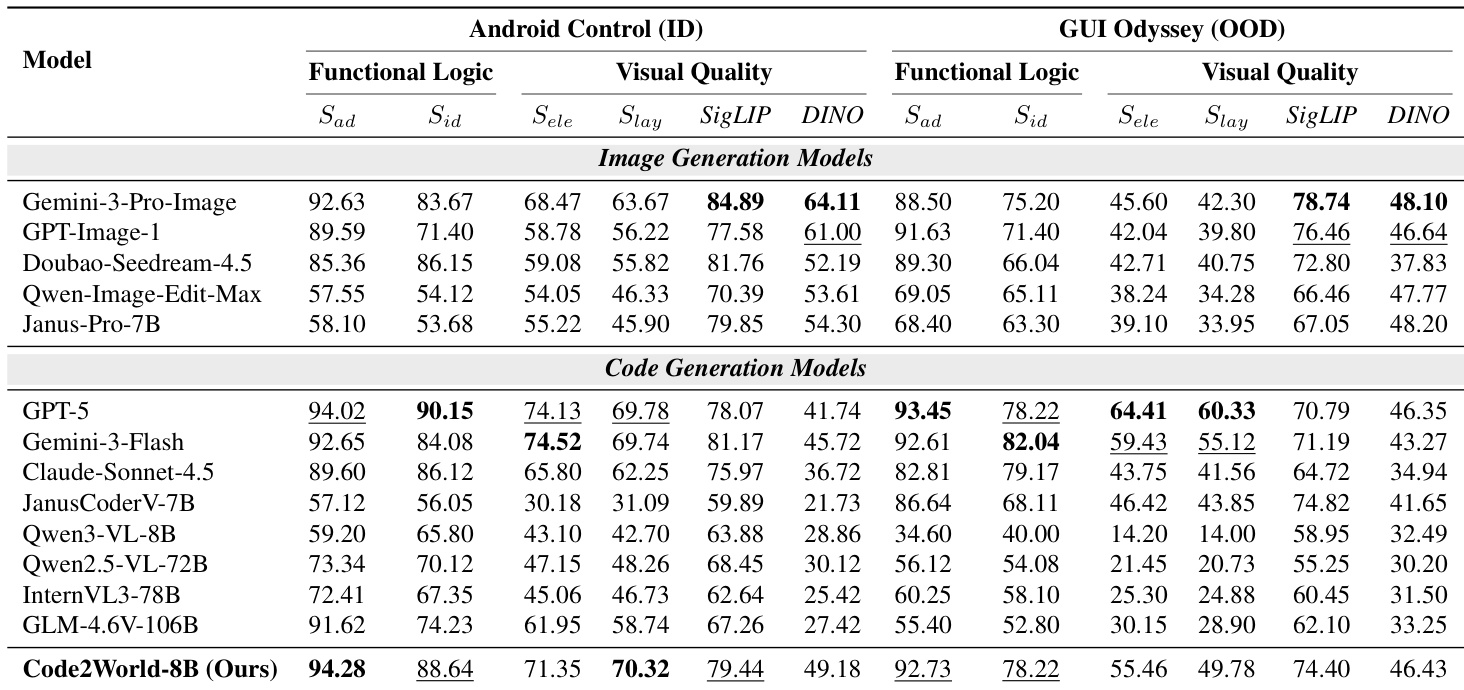
作者使用专门评估框架,从功能逻辑与视觉质量两个维度评估下一 UI 预测模型。结果表明,Code2World 在两维度均显著优于开源与专有基线,在动作遵循性、可识别性、元素对齐与布局完整性上得分最高,证明其即使在仅 8B 参数规模下,也能生成结构准确且交互一致的 GUI 状态。