Command Palette
Search for a command to run...
思维链:基于自适应认知模式的推理
思维链:基于自适应认知模式的推理
摘要
人类的问题求解从来不是单一思维模式的重复运用,这里的“思维模式”指的是一种特定的认知处理方式。在解决具体任务时,我们并非依赖单一的思维模式,而是将多种思维模式整合于同一求解过程之中。然而,现有的大语言模型(LLM)推理方法普遍存在一个共同缺陷:在整个推理过程中始终采用固定的、不变的思维模式,忽视了同一问题的不同求解阶段本质上需要截然不同的思维策略。这种“单一思维”的假设严重制约了模型向更高层次智能发展的潜力。为突破这一局限,我们提出思维链(Chain of Mindset, CoM),一种无需训练的代理式框架,支持在推理步骤层面实现动态自适应的思维模式调度。CoM将推理过程分解为四种功能异质的思维模式:空间思维(Spatial)、收敛思维(Convergent)、发散思维(Divergent)和算法思维(Algorithmic)。系统通过一个元代理(Meta-Agent)根据不断演化的推理状态,动态选择最优的思维模式;同时,引入双向上下文门控机制(Bidirectional Context Gate),有效过滤模块间的跨信息流,确保推理过程在保持高效性的同时维持高准确性。在涵盖数学推理、代码生成、科学问答与空间推理等六大挑战性基准上的实验结果表明,CoM实现了当前最先进的性能表现。在Qwen3-VL-32B-Instruct和Gemini-2.0-Flash两个模型上,其整体准确率分别超越最强基线模型4.96%和4.72%,同时兼顾了推理效率的平衡。相关代码已公开,可访问:https://github.com/QuantaAlpha/chain-of-mindset。
一句话总结
来自北京大学、北京交通大学、QuantaAlpha 等机构的研究人员提出了“思维链”(Chain of Mindset, CoM),这是一种无需训练的框架,能够在推理过程中动态选择四种认知思维模式,在关键基准测试中性能优于基线模型近 5%,同时保持高效,推动大语言模型的问题解决能力超越固定模式方法。
主要贡献
- 我们发现当前大语言模型推理的一个关键限制:尽管人类解决问题时需要在空间、收敛、发散和算法等不同认知模式间动态切换,但现有方法在所有推理步骤中依赖单一固定思维模式。
- 我们提出了“思维链”(CoM),一种无需训练的代理框架,通过元代理(Meta-Agent)在每一步推理中动态选择最优思维模式,并利用双向上下文门(Context Gate)控制模块间信息流,以保持效率和有效性。
- CoM 在六个不同基准测试中取得最先进成果,相较于最强基线模型,在 Qwen3-VL-32B-Instruct 和 Gemini-2.0-Flash 上整体准确率分别提升 4.96% 和 4.72%,且无需重新训练模型,保持计算效率。
引言
作者借鉴认知科学,解决大语言模型推理中的一个关键限制:当前方法在所有推理步骤中使用单一固定思维模式,而人类解决问题时会动态切换不同认知模式。以往方法要么将模型锁定在单一策略,要么在任务开始时选择静态方法,无法随子任务需求变化而自适应调整。他们的主要贡献是“思维链”(CoM),一种无需训练的代理框架,通过元代理在每一步推理中动态协调四种功能不同的思维模式——空间、收敛、发散和算法思维。双向上下文门过滤信息流,保持效率并减少干扰,实现无需重新训练的状态依赖切换。CoM 在六个基准测试中取得最先进成果,性能最高优于基线模型达 4.96%,并跨模型泛化,保持计算效率。
数据集
-
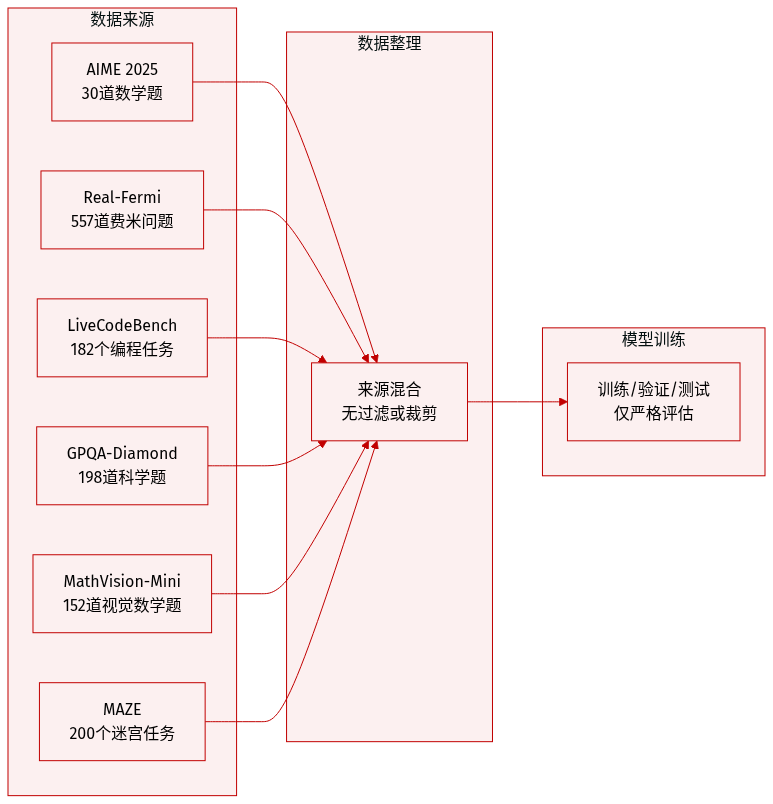
作者在四个类别的六个基准测试上评估 CoM,数据来源于近期学术数据集和竞赛。
-
数学推理包括:
- AIME 2025:30 道涵盖代数、几何、组合和数论的问题。
- Real-Fermi:557 道费米估算问题,需进行数量级推理。
-
代码生成使用 LiveCodeBench:182 道来自 LeetCode、AtCoder 和 CodeForces(2025 年 1 月至 5 月)的编程题,分为 45 道简单题、55 道中等题和 82 道难题。
-
科学问答采用 GPQA-Diamond:精选 198 道博士级别物理、化学和生物问题,因非专家准确率仅约 30%。
-
多模态推理包括:
- MathVision-Mini:152 道需先解读图表再进行符号求解的多模态数学题。
- MAZE:200 道由 maze-dataset 生成的迷宫导航任务,模型需在迷宫图像上执行给定动作序列后预测最终位置。
-
这些基准测试未使用任何训练数据,仅用于评估。所有数据集均按其原作者指定的形式或最小过滤后使用,未提及对测试集进行裁剪或元数据构建。
方法
作者采用一种三层解耦架构“思维链”(CoM),使大语言模型实现动态多模态推理。该框架将元认知协调与具体执行分离,使系统可根据中间进展和语义上下文在功能异构的推理范式(称为“思维模式”)间切换。核心组件包括元代理、四个专用思维模块,以及双向上下文门,后者调节信息流以防止上下文污染。
元代理作为中央控制器,负责生成认知决策,决定每一步调用哪种思维模式。它在迭代的“计划-调用-内化”循环中运作:给定当前状态 st=(q,H<t),它通过策略 π 选择思维模式 mt,分派相应调用 ct,接收输出与洞察,并内化洞察以可能修订其计划。这使系统在复杂推理轨迹中实现自我修正和自适应重规划。
如下图所示,该框架在每一步动态选择最优认知模式,与静态策略选择或单模式推理形成对比。四种思维模式——算法、空间、收敛和发散——各自封装不同认知策略,并在隔离上下文中运行。算法思维模式通过生成-执行-修复循环处理精确计算,最多迭代 Nmax=2 次以修复代码错误:
(ρi+1,ralgo)=⎩⎨⎧(ρi,EXEC(ρi))(FIX(ρi,ϵi),⊥)(ρi,ϵi)if execution succeedsif error ϵi∧i<Nmaxotherwise空间思维模式通过 Nano-Banana-Pro 生成或编辑图像,连接抽象逻辑与视觉直觉,支持三种模式:文本→图像、图像+文本→图像、代码→图像。生成的产物注册唯一标识符(如 [GEN_001])以便后续引用。收敛思维模式基于既定事实进行聚焦、深入推理,生成完整逻辑推导。发散思维模式通过生成 k∈[2,5] 个候选解分支打破僵局,各分支并行分析,结果返回元代理进行审议。
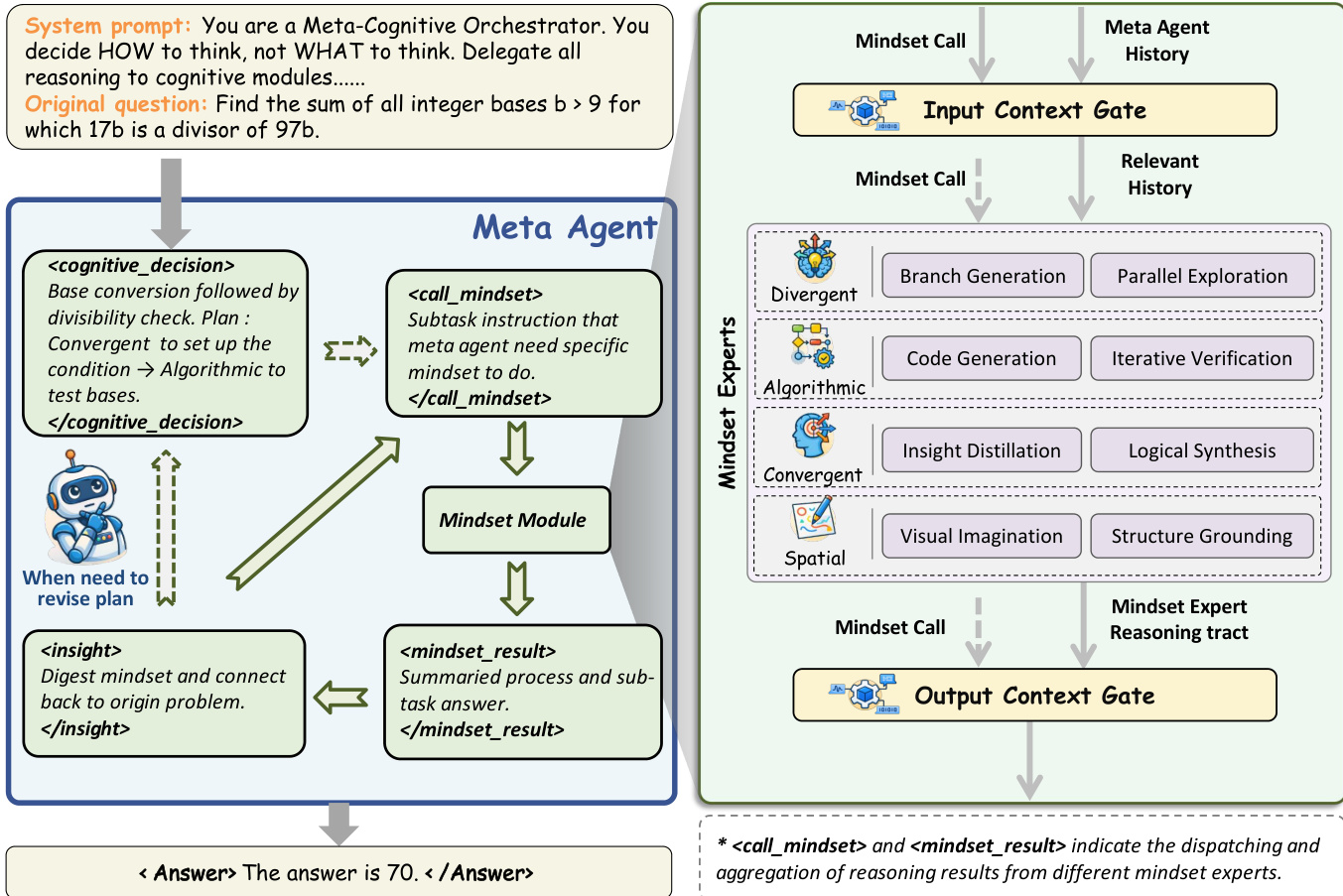
为解决模块化推理中的相关性-冗余性权衡问题,上下文门实现双向语义过滤。输入门从完整历史 H 中提取最小充分上下文子集 Hrel 和相关图像 Iini,以调用指令 c 作为语义锚点:
(Hrel,Iini)=Gin(H,c,M,I)输出门将冗长的思维模式输出 r 提炼为与指令目标对齐的简洁摘要 Osum:
Osum=Gout(r,c,Inew)这确保了双向高信息密度,使系统在隔离的思维模式环境中高效执行,同时保持主推理链的紧凑性。元代理内化这些提炼后的洞察,指导后续决策,形成能够动态适应的闭环认知架构。
实验
- CoM 在复杂推理中展示自适应思维切换,使用空间思维进行视觉锚定,收敛思维解决歧义,算法思维进行精确计算。
- 它在多个基准测试中优于基线模型,在需要灵活策略适应的任务(如费米估算和空间推理)上表现最强。
- 消融研究证实上下文门对协调至关重要,而发散和空间思维模式分别驱动数学和视觉任务的性能。
- CoM 以适度计算成本实现最先进准确率,位于准确率-效率权衡的帕累托前沿。
- 思维模式调用模式揭示任务特定协作:费米和代码任务偏好算法-收敛组合,而多模态任务严重依赖空间推理。
- 动态重规划是其核心优势——CoM 根据中间洞察在过程中修订策略,比静态元推理方法更高效地解决问题。
作者使用 CoM 在推理过程中动态切换认知思维模式,在多个基准测试中实现最高整体准确率,根据问题上下文自适应调整策略。结果表明,移除上下文门或发散思维模式等关键组件会显著降低性能,证实协调的自适应推理对复杂任务至关重要。CoM 还通过每项任务仅调用必要思维模式实现效率提升,在准确率与计算成本间取得平衡。
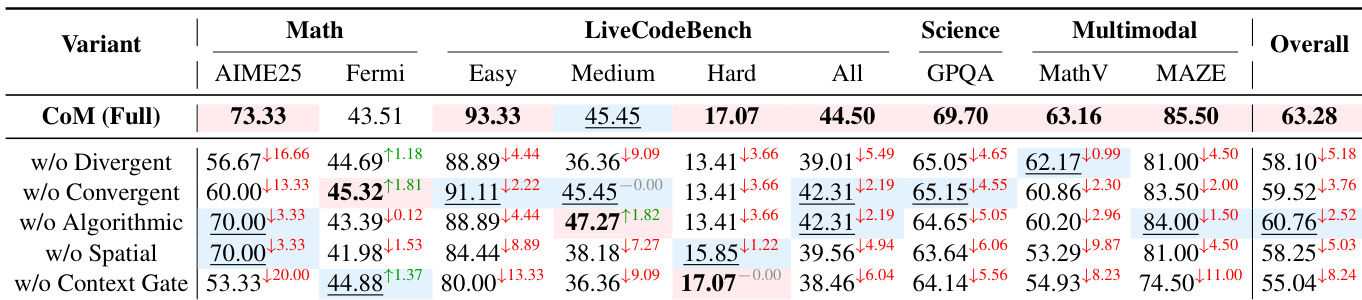
作者使用 CoM 在推理过程中动态切换认知思维模式,在多个基准测试中相比直接和元推理基线实现最高整体准确率。结果表明,CoM 在需要灵活策略适应的任务(如数学推理和多模态空间问题)上尤其出色,同时保持令牌使用的效率。该框架的优势在于根据问题上下文协调专用推理模式——如算法模式用于计算、空间模式用于可视化——而非依赖固定或统一策略。
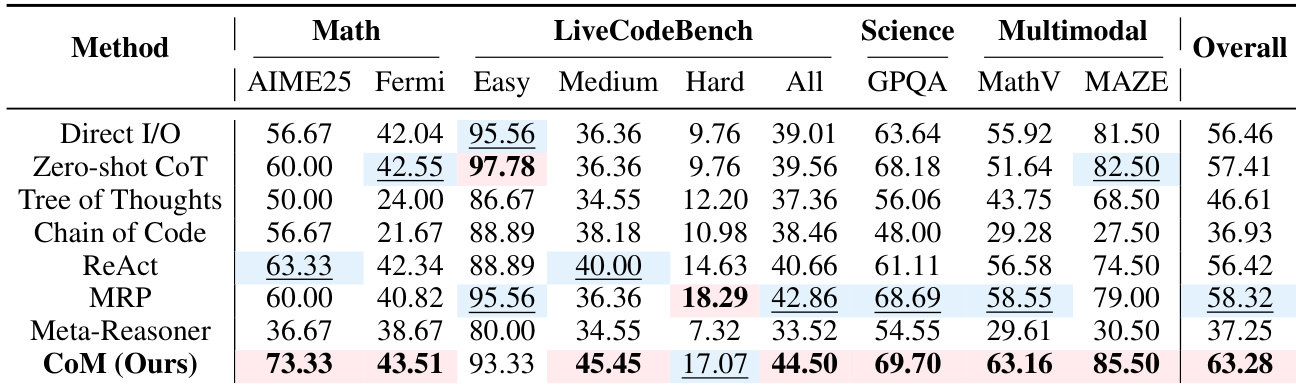
作者使用 CoM 在推理过程中动态切换认知思维模式,在多个基准测试中相比直接和元推理基线实现最高整体准确率。结果表明,CoM 在需要灵活策略适应的任务(如数学推理和多模态空间问题)上尤其出色,同时保持令牌使用的效率。该方法的优势在于根据问题上下文协调专用推理模式——如算法模式用于计算、空间模式用于可视化——而非依赖固定或统一策略。
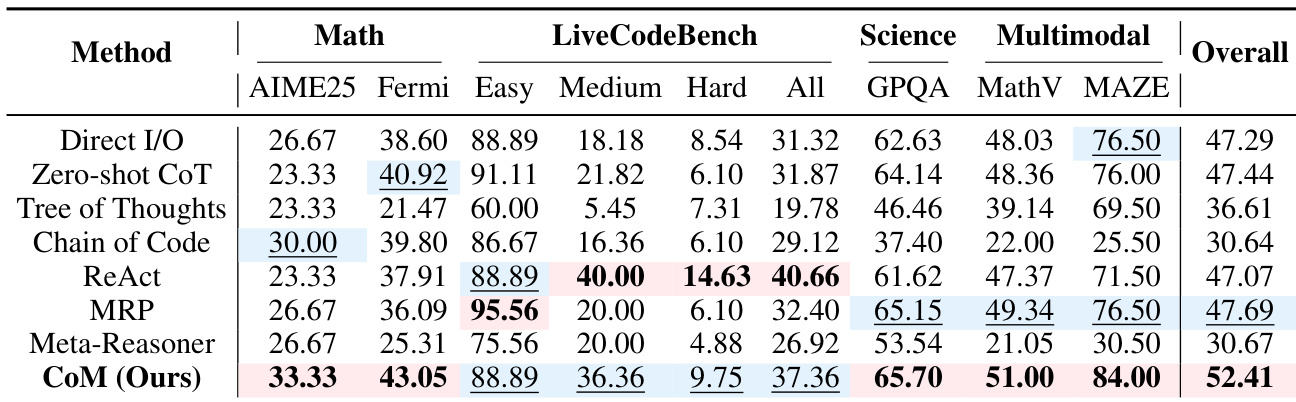
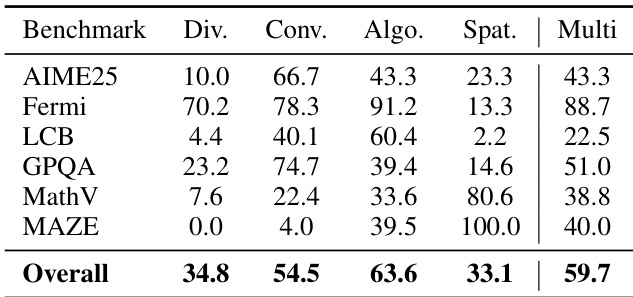
作者根据问题需求使用 CoM 动态切换认知思维模式——发散、收敛、算法和空间——大多数任务调用多种思维模式以实现最优推理。结果表明,算法和收敛思维模式整体最常被激活,而空间思维对 MAZE 和 MathVision 等视觉任务至关重要,发散思维在 AIME25 等数学推理中发挥关键作用。多思维模式协作实现自适应问题解决,59.7% 的问题需要至少两种不同模式才能有效解决。