Command Palette
Search for a command to run...
Agent世界模型:用于智能体强化学习的无限合成环境
Agent世界模型:用于智能体强化学习的无限合成环境
Zhaoyang Wang Canwen Xu Boyi Liu Yite Wang Siwei Han Zhewei Yao Huaxiu Yao Yuxiong He
摘要
近年来,大型语言模型(LLM)的进展使得自主智能体能够执行需要与工具及环境进行多轮交互的复杂任务。然而,此类智能体训练的规模化受限于缺乏多样且可靠的环境。本文提出了一种全合成环境生成管道——智能体世界模型(Agent World Model, AWM)。通过该管道,我们构建了1,000个涵盖日常场景的合成环境,每个环境中平均集成35种工具,支持智能体进行丰富的交互,并获取高质量的观测信息。值得注意的是,这些环境由代码驱动并依托数据库运行,相较于基于LLM模拟的环境,其状态转移更加可靠且一致。此外,相比从真实环境中采集轨迹,该方法显著提升了智能体交互的效率。为验证该资源的有效性,我们在多轮工具使用智能体上开展了大规模强化学习实验。得益于完全可执行的环境与可访问的数据库状态,我们能够设计出稳定可靠的奖励函数。在三个基准测试上的实验表明,仅在合成环境中训练的智能体,相比仅在特定基准环境训练的模型,展现出更强的分布外泛化能力。相关代码已开源,地址为:https://github.com/Snowflake-Labs/agent-world-model。
一句话总结
来自 Snowflake Labs 和加州大学圣地亚哥分校的研究人员提出了 Agent World Model(AWM),这是一种合成环境生成器,支持可扩展的、代码驱动的智能体训练,每个环境包含 1,000 个多样化场景和 35 个工具,性能优于 LLM 模拟环境,并通过可执行的、数据库支持的状态提升分布外泛化能力。
主要贡献
- 我们提出了 Agent World Model(AWM),这是一个可扩展的开源流水线,可生成 1,000 个多样化、代码驱动、数据库支持的环境,用于训练使用工具的智能体,相比 LLM 模拟或真实世界设置,确保可靠的状态转换和高效交互。
- AWM 通过提供可通过 MCP 访问状态和工具接口的可执行环境,支持大规模强化学习,允许通过自动状态验证和自我修正代码生成设计稳健的奖励函数。
- 在三个基准测试上的实验表明,在 AWM 环境中训练的智能体在分布外泛化方面表现优异,证明了针对现实世界工具使用任务的合成、非基准定制训练的价值。
引言
作者利用大型语言模型构建了 Agent World Model(AWM),这是一个可扩展的流水线,可生成 1,000 个可执行的、数据库支持的环境,用于通过强化学习训练使用工具的智能体。先前的工作要么依赖于小型手工环境,要么使用 LLM 模拟状态转换——这两种方法都存在可扩展性差、幻觉或成本高的问题。AWM 通过将环境合成分解为结构化组件(任务、数据库模式、工具接口和验证代码)克服了这些问题,确保一致的状态转换并支持高效的并行 RL 训练。其主要贡献包括一个开源生成流水线、一个包含 35,000 多个工具的大规模多样化环境集合,以及实证证据表明在 AWM 上训练的智能体在未见过的基准测试中表现良好。
数据集

作者使用合成生成的数据集训练基于状态、数据库支持的应用程序中的智能体——重点关注 CRUD 操作而非静态内容。以下是数据集的构建和使用方式:
-
数据集组成与来源:
- 从 100 个种子域名(流行网站)开始,使用 Self-Instruct 风格的 LLM 扩展到 1,000 个多样化场景。
- 每个场景代表一个需要数据库交互的真实世界应用领域(例如电子商务、CRM、银行、旅游)。
- 场景经过筛选,排除只读或内容密集型网站(如新闻或博客),并按类别限制以确保多样性。
-
关键子集详情:
- 场景生成:
- LLM 分类器根据 CRUD 适用性对候选场景评分(拒绝非交互式内容)。
- 基于嵌入的去重(余弦相似度阈值:0.85)确保独特性。
- 最终集合:1,000 个独特、有状态的场景,涵盖 20 多个领域(见图 6、7,表 9)。
- 任务生成:
- 对每个场景,LLM 生成 10 个具体、可通过 API 解决的任务(无 UI 依赖)。
- 任务包括具体参数(例如产品 ID、用户名),并假设已认证上下文。
- 输出:共 10,000 个任务(表 11),用于驱动模式和工具集合成。
- 场景生成:
-
数据在训练中的使用方式:
- 任务用于合成全栈环境:数据库模式、FastAPI 端点和 MCP 兼容工具。
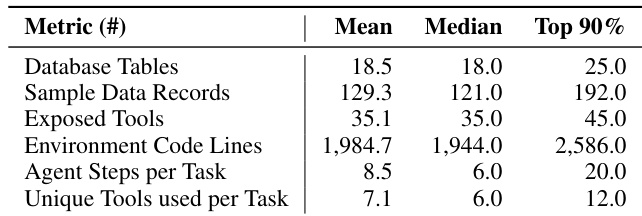
- 每个环境包含约 2,400 行代码、25+ 个数据库模型和 45+ 个可发现工具(图 25)。
- 环境通过配置(环境变量、数据库路径)隔离并启动,用于 RL 训练。
- 工具通过 MCP 协议动态发现;智能体通过结构化 API 调用交互。
-
处理与元数据:
- 合成数据包括数字、实体、状态值、短文本、时间戳和地理数据——不包括长篇内容、媒体或 AI 推理。
- 高适用性领域(如电子商务、银行)优先;中等适用性领域(如 Spotify 播放列表)仅关注 CRUD 方面。
- 验证使用结构化 JSON 输出,包含推理、置信度评分、分类和证据(图 22),以奖励 RL 智能体。
- 所有生成的代码和模式均有效、可运行,并包含 OpenAPI 元数据以供工具发现。
方法
作者利用完全自动化的流水线合成基于结构化关系状态的可执行智能体强化学习环境。整体框架如图所示,分为五个顺序阶段:场景合成、任务生成、数据库与数据合成、接口与环境实现,最后是验证与在线 RL 训练。每个阶段均由大型语言模型(LLM)驱动,并包含自我修正机制以确保功能正确性。
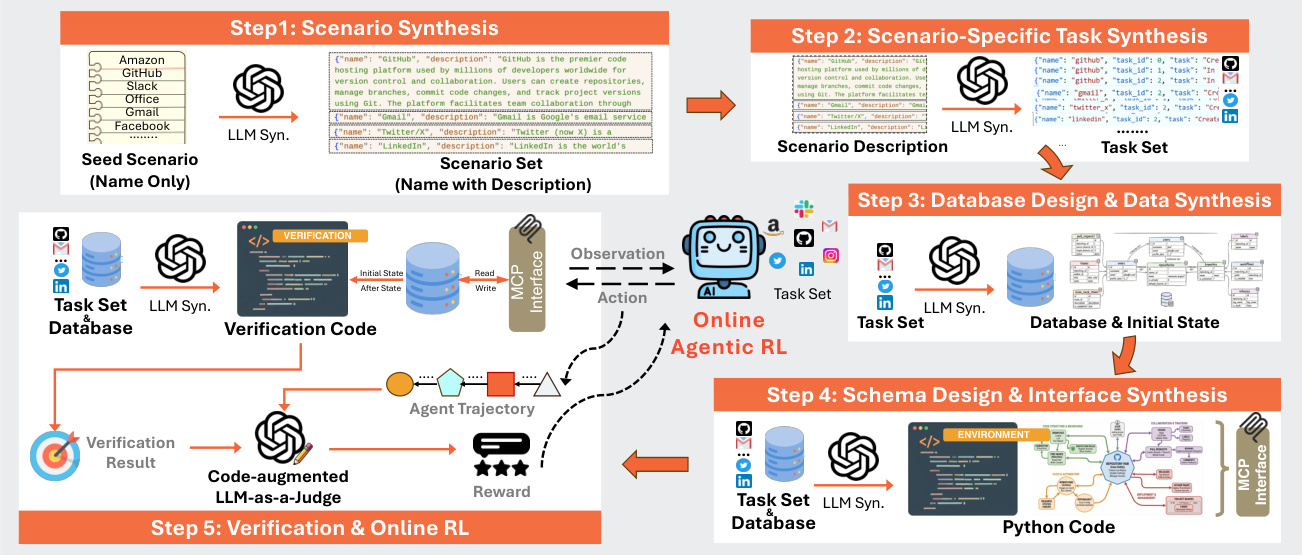
过程从场景合成开始,LLM 从种子名称生成目标平台(如 GitHub、Gmail)的描述性上下文。该描述随后驱动每个场景生成 k=10 个可执行的用户任务,确保 API 可解性和认证后上下文。这些任务作为环境的功能需求,决定必要的实体和操作。
在数据库合成阶段,LLM 从任务集中推断出最小 SQLite 模式,定义状态空间 SEi,包含显式键和约束。为确保任务从一开始就可执行,LLM 还合成满足任务前提条件的样本数据,用现实初始状态 s0 填充数据库。模式和数据生成均通过基于执行的自我修正循环验证:如果生成的 SQL 失败,LLM 总结错误并重新生成代码,接受阈值为 10% 失败率。
接口层分两阶段合成。首先,LLM 根据任务集和模式设计机器可读的 API 规范,定义一组最小的原子、可组合端点。该规范包括类型化参数、响应模式和作为智能体文档的摘要。其次,LLM 使用 FastAPI 和 SQLAlchemy ORM 生成完整的 Python 实现,通过 Model Context Protocol(MCP)暴露端点。每个环境平均包含 2,000 行代码和 35 个工具,并通过启动服务器和检查健康端点进行验证。
对于奖励设计,作者采用混合方法。在每一步 t,智能体的工具调用通过基于规则的检查验证格式正确性;违规将触发早期终止,奖励为 rt=−1.0。如果运行正常完成,任务级奖励 Rτ 通过代码增强的 LLM-as-a-Judge 分配。该评判器结合结构化验证信号(通过比较执行前后数据库状态提取)和智能体轨迹确定结果:完成(奖励 1.0)、部分完成(奖励 0.1)或其他(奖励 0.0)。
为使训练与推理对齐,作者在 Group Relative Policy Optimization(GRPO)下实施历史感知训练。不同于使用完整交互历史优化策略,他们在训练期间将历史截断为固定窗口 w,匹配推理时使用的上下文窗口。GRPO 目标为:
LGRPO=Eτ,Ei,{y(k)}[G1k=1∑GA(k)t=1∑Tklogπθ(at(k)∣httrunc,(k))]其中 A(k) 是从运行奖励计算的组相对优势。这确保策略在部署时将面临的相同上下文约束下进行优化。
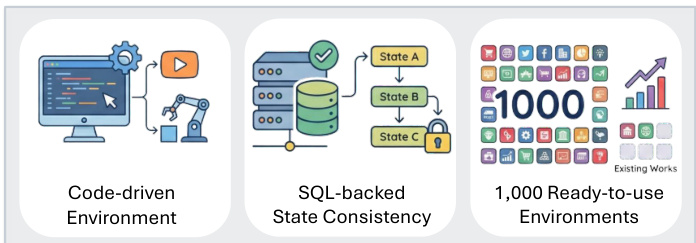
整个合成流水线设计用于稳健性和可扩展性,生成 1,000 个即用型环境,具有 SQL 支持的状态一致性,如图所示。
实验
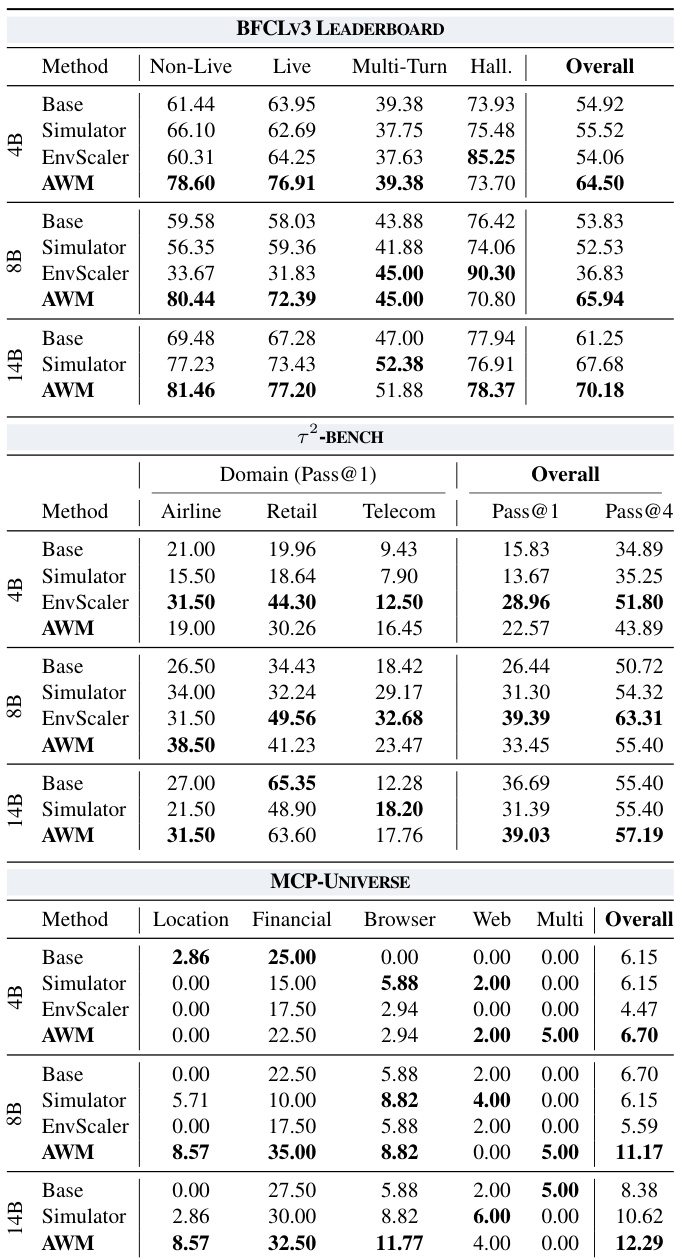
- AWM 成功合成了 1,000 个可执行环境和 10,000 个任务,成功率超过 85%,所需人工输入极少,规模比先前方法如 EnvScaler 大 5 倍,同时通过 SQL 维持状态一致性。
- 在 AWM 环境中训练智能体在多个基准测试(BFCLv3、τ²-bench、MCP-Universe)中表现提升,展示强大的分布外泛化能力,尤其在金融和位置任务中,超越模拟和并发合成基线。
- AWM 环境表现出高质量和多样性:LLM-as-a-Judge 评估确认更高的任务可行性、数据对齐和工具集完整性;语义和主题多样性随规模增加保持稳定,避免退化为重复项。
- 代码增强的验证策略——结合结构化数据库检查与 LLM 推理——比仅使用 LLM 或仅使用代码的方法更稳健,有效处理环境缺陷,同时增加的延迟可忽略不计。
- 在截断上下文中进行历史感知训练可提升性能并减少训练与推理间的分布偏移,验证历史管理应作为策略学习的一部分进行优化。
- 环境扩展显示单调性能提升:10 个环境导致过拟合,100 个环境带来显著改进,526 个环境进一步提升结果,表明 AWM 支持超过 1,000 个环境的扩展并持续受益。
- 步级格式正确性奖励显著减少工具调用错误,加速训练收敛并提高任务完成率,证明其在合成环境中实现稳定高效 RL 的关键作用。
作者使用 AWM 生成具有庞大代码库和多样化工具集的复杂可执行环境,如指标所示,每个环境平均包含近 2,000 行代码和 35 个以上暴露工具。结果表明,这些环境支持非平凡的多步智能体交互,同时保持远超玩具设置的结构丰富性。这种规模和复杂性确认了流水线高效合成真实、高保真训练环境的能力。
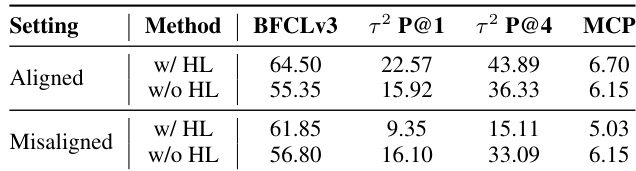
作者在对齐和不对齐设置下评估历史感知训练,发现当推理条件与训练匹配时,使用历史截断(w/ HL)训练可获得更优性能。当设置不对齐时,未使用历史限制训练的模型(w/o HL)表现出更强的鲁棒性,有时甚至因减少无关上下文干扰而略有提升。这表明历史管理应整合到策略优化中,而非作为推理时的单独调整。
作者使用 LLM-as-a-Judge 评估合成环境在任务可行性、数据对齐和工具集完整性方面的表现,AWM 在 GPT-5.1 和 Claude 4.5 下均持续优于 EnvScaler。尽管生成的环境代码更多,AWM 每环境的错误更少,阻塞任务显著减少,表明其在强化学习中具有更好的可扩展性和可靠性。结果确认 AWM 从任务到数据库再到接口保持更高的端到端一致性,减少因环境错误导致的训练中断。

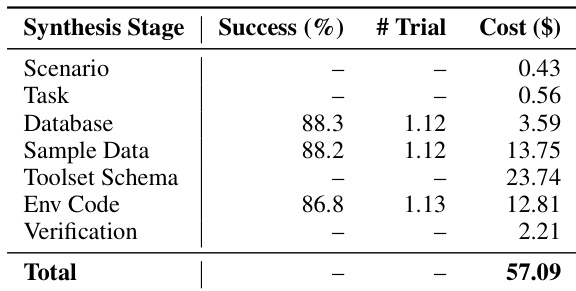
作者通过多阶段流水线使用 AWM 合成可执行环境,在数据库和环境代码生成阶段实现高成功率,同时保持较低的平均自我修正迭代次数。结果表明该流水线成本效益高且可扩展,验证和工具集模式阶段虽贡献显著成本,但支持生成稳健、非玩具环境,适合训练智能体。该设计支持大规模合成,人工输入极少,确认其在大规模生成多样化可执行环境中的可行性。
作者使用 AWM 合成大规模可执行环境以训练智能体,相比先前方法在成功率和可扩展性上表现更优,且人工输入极少。结果表明,在 AWM 上训练的智能体在多个分布外基准测试中持续优于基线,尤其在现实世界工具使用场景中,表明从合成环境到真实环境的强泛化能力。混合代码增强验证设计进一步提升训练稳定性和奖励可靠性,即使存在环境缺陷。