Command Palette
Search for a command to run...
检索增强模型相较于LLM在推理方面带来了多少提升?面向混合知识的多跳推理基准测试框架
检索增强模型相较于LLM在推理方面带来了多少提升?面向混合知识的多跳推理基准测试框架
Junhong Lin Bing Zhang Song Wang Ziyan Liu Dan Gutfreund Julian Shun Yada Zhu
摘要
大型语言模型(LLMs)在处理需要实时信息与多跳推理的知识密集型问题时仍面临挑战。通过引入混合外部知识(如非结构化文本与结构化知识图谱)来增强LLMs,为替代昂贵的持续预训练提供了一条有前景的路径。因此,对模型检索与推理能力进行可靠评估变得至关重要。然而,现有许多基准测试数据集与LLM的预训练数据存在日益严重的重叠,导致答案或支撑性知识可能已编码于模型参数中,难以区分真正的检索与推理能力与参数化记忆(parametric recall)。为此,我们提出HybridRAG-Bench——一个用于构建基准测试框架的方法,旨在评估在混合知识源上的检索密集型、多跳推理能力。HybridRAG-Bench能够自动整合来自arXiv最新科学文献的非结构化文本与结构化知识图谱表示,并生成基于明确推理路径的知识密集型问答对。该框架支持灵活的领域与时间范围选择,可实现对模型与知识演进过程中的“污染感知”(contamination-aware)与可定制化评估。在人工智能、治理与政策、生物信息学三个领域开展的实验表明,HybridRAG-Bench能够有效奖励真正的检索与推理行为,而非依赖参数记忆,为评估混合知识增强型推理系统提供了一个原则性强、可靠的测试平台。我们已将代码与数据开源,发布于github.com/junhongmit/HybridRAG-Bench。
一句话总结
来自麻省理工学院、IBM 和中佛罗里达大学的研究人员推出了 HYBRIDRAG-BENCH,这是一种具备污染感知能力的框架,通过结合 arXiv 文本与知识图谱,评估大语言模型(LLM)在混合知识上的多跳推理能力,支持领域特定、时间限定的评估,可区分真实检索与参数化记忆。
主要贡献
- HYBRIDRAG-BENCH 引入了一种污染感知的基准框架,从近期 arXiv 文献中构建多跳推理任务,确保问题依赖外部检索而非参数化记忆,使用时间限定、动态演化的科学语料库。
- 该框架自动构建结合非结构化文本与结构化知识图谱的混合知识环境,生成基于明确推理路径的多样化问题类型,评估 AI、政策和生物信息学等领域的真正检索与推理能力。
- 实验表明,HYBRIDRAG-BENCH 有效区分了依赖真实检索推理的模型与依赖预训练记忆的模型,为评估混合知识增强系统提供了一个可扩展、可定制的测试平台。
引言
作者利用检索增强生成(RAG)与结构化知识图谱,应对大语言模型(LLM)常因知识过时或推理能力不足而失败的知识密集型多跳推理任务。以往的基准测试存在预训练污染问题——模型通过记忆而非检索正确作答——导致难以评估系统是否真正推理或仅是回忆。为解决此问题,他们引入 HYBRIDRAG-BENCH,该框架从近期 arXiv 论文中自动构建污染感知基准,结合非结构化文本与结构化知识图谱,并生成与明确推理路径相关的问题。该方法支持跨领域与时间段的公平、可扩展评估,区分真实检索与多跳推理与参数化记忆。
数据集

作者使用 HYBRIDRAG-BENCH,这是一个动态构建的、领域特定的基准,用于评估检索增强和知识驱动的 LLM。关键细节如下:
-
数据集组成与来源
- 基于 arXiv 论文按领域构建,使用学科分类(如 cs.AI)和可选关键词收集。
- 每个领域拥有独立的、随时间演化的知识图谱,源自用户指定时间窗口内的文档,该窗口晚于 LLM 预训练截止时间,以避免参数化记忆。
- 各领域之间无共享实体或关系。
-
关键子集细节
- 问题类型:单跳、带条件的单跳、多跳、困难多跳(通过高阶实体)、反事实和开放性问题。
- 规模:依领域而异;各类型分布见表 2。
- 过滤机制:问题必须仅通过混合上下文(KG 路径 + 支持文本)可答,通过 LLM 作为裁判的忠实性检查,并避免文档局部引用或歧义。
- 元数据:包括论文标题、作者、类别和时间戳;文本按章节(摘要、方法等)分段。
-
数据在模型训练/评估中的用途
- 问题通过条件化 LLM 生成:(1) 采样 KG 推理路径,(2) 关联文本证据,(3) 上下文示例。
- 每个问答对绑定特定时间点 t_i 的知识图谱快照,确保时间隔离。
- 仅用于 LLM 评估而非训练,以衡量其整合结构化与非结构化证据的能力。
-
处理与裁剪策略
- 从领域知识图谱采样推理路径;为每个实体/关系检索文本片段。
- 问题合成时隐藏中间节点(多跳情况)或包含反事实扰动。
- 最终问答对经过归一化(小写、标点)和多阶段过滤,确保清晰性、忠实性和独立性。
方法
作者利用四阶段自动化流水线构建 HYBRIDRAG-BENCH,该基准旨在评估混合知识源上的检索增强推理。框架从用户指定参数(如时间范围、主题领域、问题类型)开始,指导收集时间限定的 arXiv 语料库。该语料库作为非结构化文本块与结构化知识图谱的基础数据源。
请参考框架图了解流水线架构概览。第一阶段“时间限定语料库收集”根据用户约束从 arXiv 摄取文档。这些文档随后并行处理,生成两种互补的知识表示:非结构化文本块与结构化知识图谱。知识图谱使用 EvoKG 构建,这是一个文档驱动框架,通过大语言模型提取实体与关系。实体提取后进行上下文感知对齐,通过联合嵌入(类型、名称、描述)将新提及与现有节点匹配,以解决词汇变异与语义歧义。若无足够相似节点,则创建新实体;否则合并提及并保留来源。
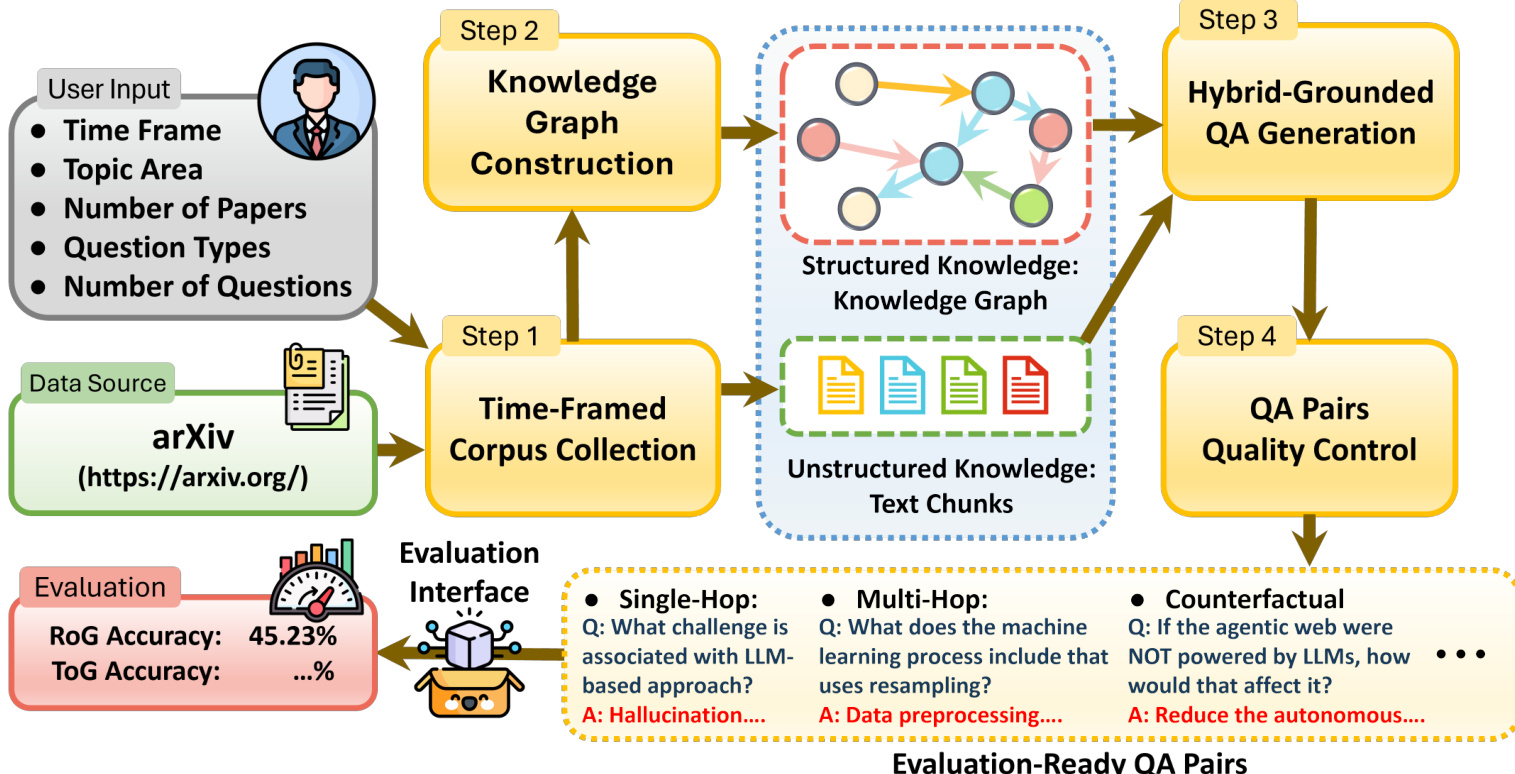
随后进行关系归一化,将提取的关系映射到领域特定模式并链接支持文本证据。图谱保留语料库支持的多个候选关系,并用频率、时效性与文本支持推导的置信度分数标注——从而保留科学文献固有的不确定性与变异性。
第三阶段“混合知识驱动的问答生成”中,系统合成多样化问答对,其基于明确推理路径,跨越知识图谱与检索文本块。这些问题涵盖单跳、多跳、条件、反事实和开放性推理类型。最终阶段“问答对质量控制”应用自动化过滤器,确保可答性、独立于文档措辞与非冗余性,产出可评估的问答对。
最终基准通过提供反映真实科学话语的结构化与非结构化知识源,实现对 RAG 与 KG-RAG 系统的可控、可复现评估。模型预测正式定义为 a^=f(q,Gtq(m),Dtq(m)),其中模型 f 在查询时间 tq 基于知识图谱快照 Gtq(m) 与检索文档 Dtq(m) 进行推理。
实验
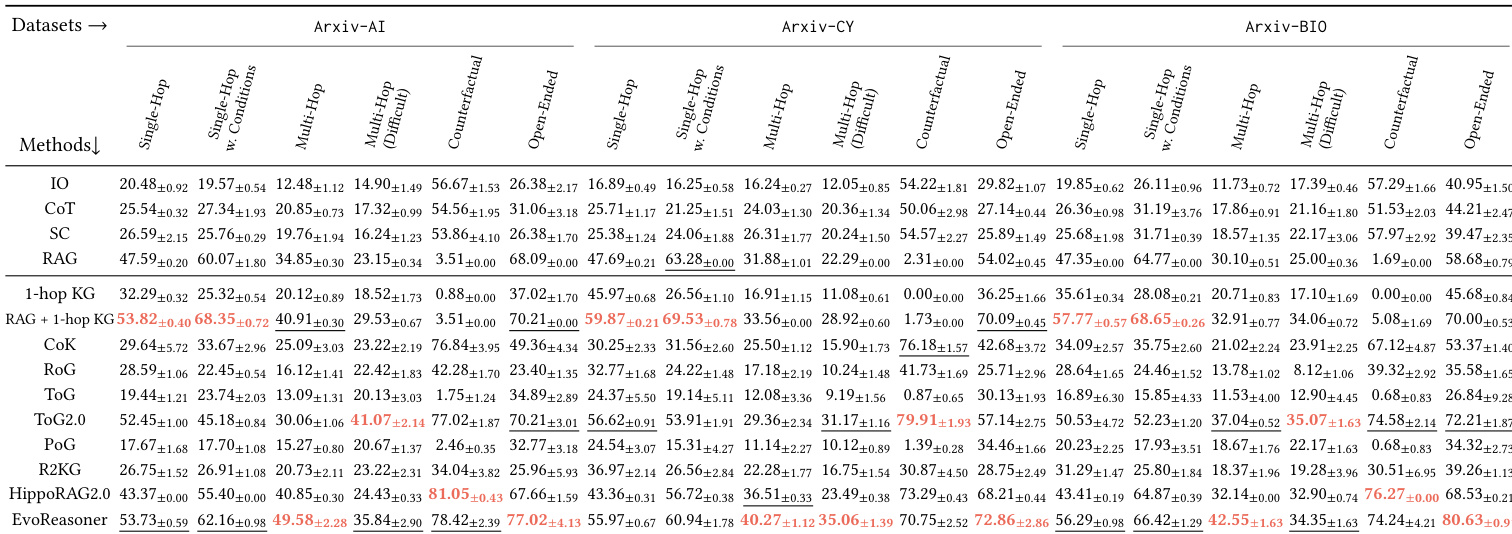
- HYBRIDRAG-Bench 对各规模 LLM 均构成持续挑战,证实问题无法仅靠参数化知识可靠回答,需外部检索与推理。
- 外部检索至关重要:基于文本的 RAG 显著优于纯 LLM 方法,而朴素 KG 注入常因噪声降低效果。
- 结构化知识补充价值:混合 KG-RAG 方法持续优于纯文本 RAG,尤其在关系型、多跳与消歧任务中。
- 基准有效区分推理策略:不同问题类型表现差异显著,结构化方法在多跳与反事实查询中表现优异,文本检索在开放性问题中占优。
- KG 构建高效可扩展:流水线恢复约 71% 可验证事实,成本与延迟接近线性扩展,确保实际部署无性能瓶颈。
作者将 KG 构建流水线与先前方法对比,发现 EvoKG 从源文档捕获显著更多可验证事实,恢复率达 71.36%,优于 KGen 的 66.46% 与 OpenIE 和 GraphRAG 的更低比率。这表明 HybridRAG-Bench 使用的知识图谱稳健,并非基准难度的限制因素。结果确认挑战源于检索与推理需求,而非知识提取不完整或不准确。

作者使用 HybridRAG-Bench 评估不同检索与推理策略在领域特定任务中的表现,发现无论模型规模如何,纯 LLM 方法始终表现不佳。结果表明,结合结构化知识图谱与文本检索可获得最强性能,尤其在多跳与反事实问题上,表明有效推理不仅需外部信息访问。基准按问题类型有意义地区分方法,揭示混合方法优于纯文本检索与朴素图增强。
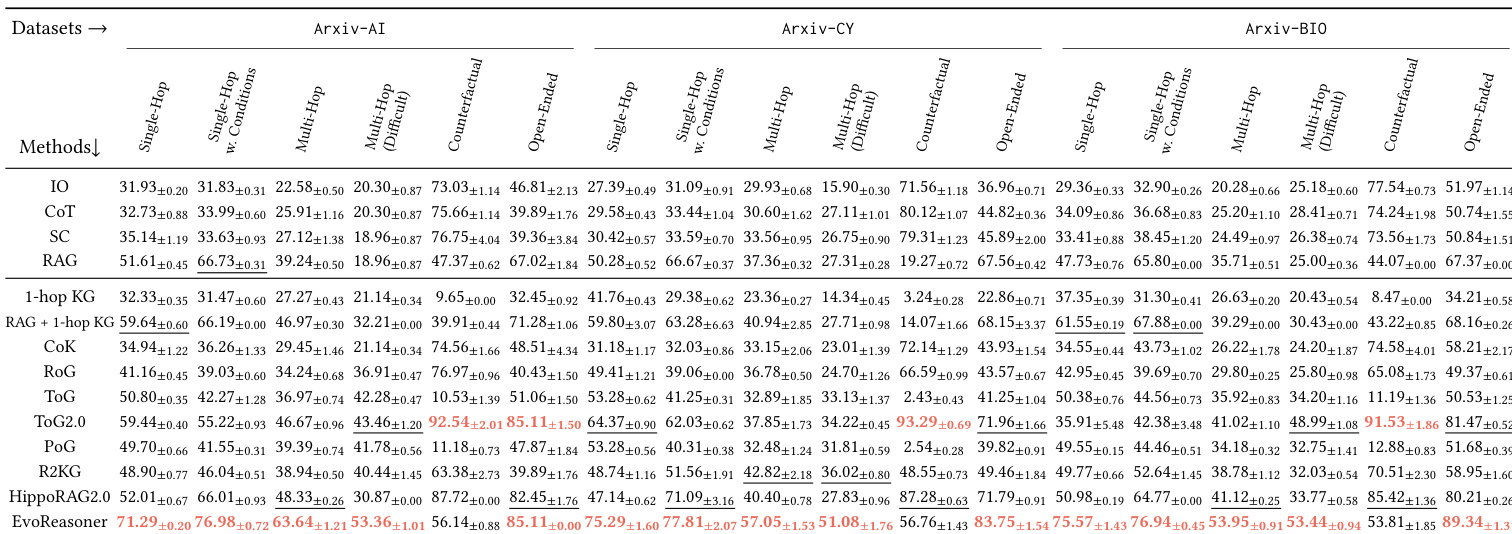
作者使用 HybridRAG-Bench 评估不同检索与推理策略在领域特定任务中的表现,发现无论模型规模如何,纯 LLM 方法始终表现不佳。结果表明,结合结构化知识图谱与文本检索可获得最强性能,尤其在多跳与反事实问题上,表明有效推理不仅需外部信息访问。基准按问题类型有意义地区分方法,揭示混合方法优于纯文本检索与朴素图增强。
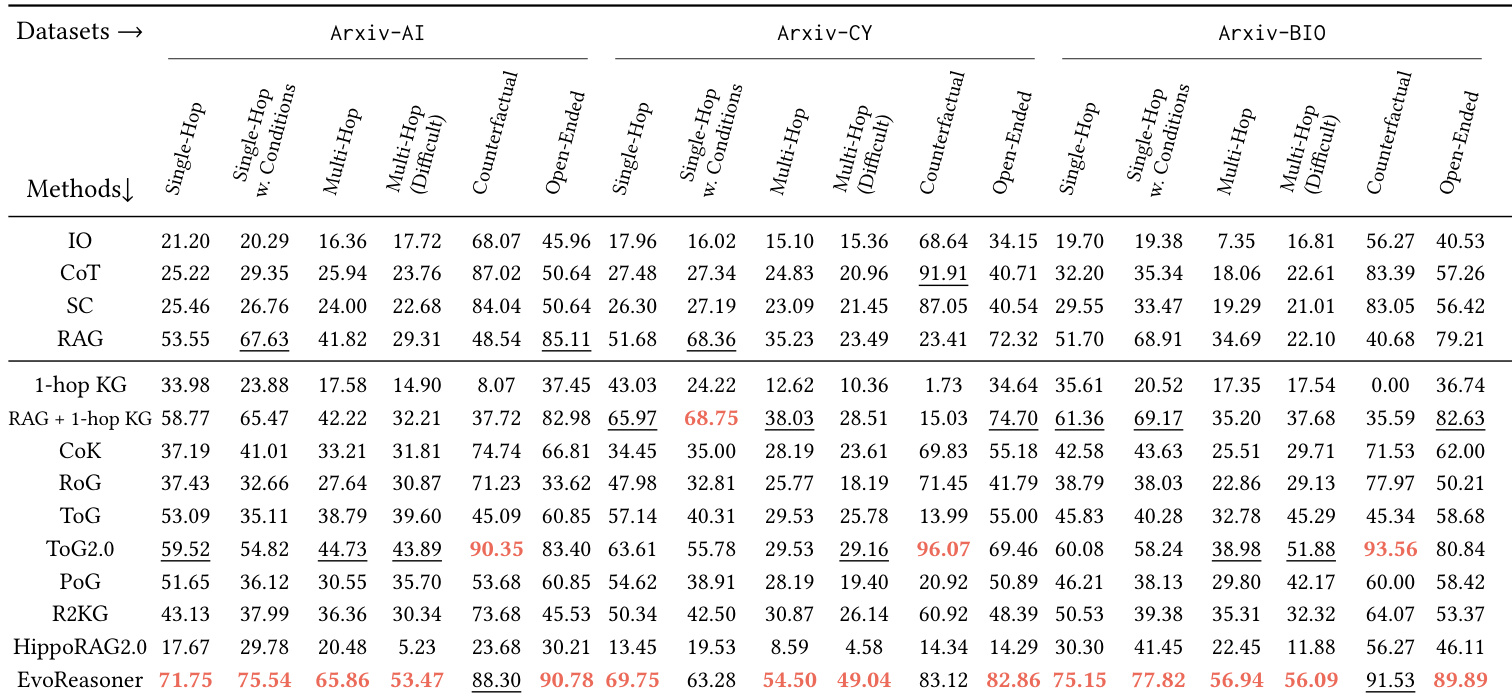
作者使用 HybridRAG-Bench 评估不同 LLM 与检索策略在三个领域知识密集型推理任务中的表现。结果表明,无论模型规模如何,纯 LLM 方法表现差,而结合结构化知识图谱与文本检索的混合方法持续优于纯文本 RAG,尤其在多跳与反事实问题上。基准有效区分推理策略,揭示成功更多取决于知识整合方式而非模型规模。
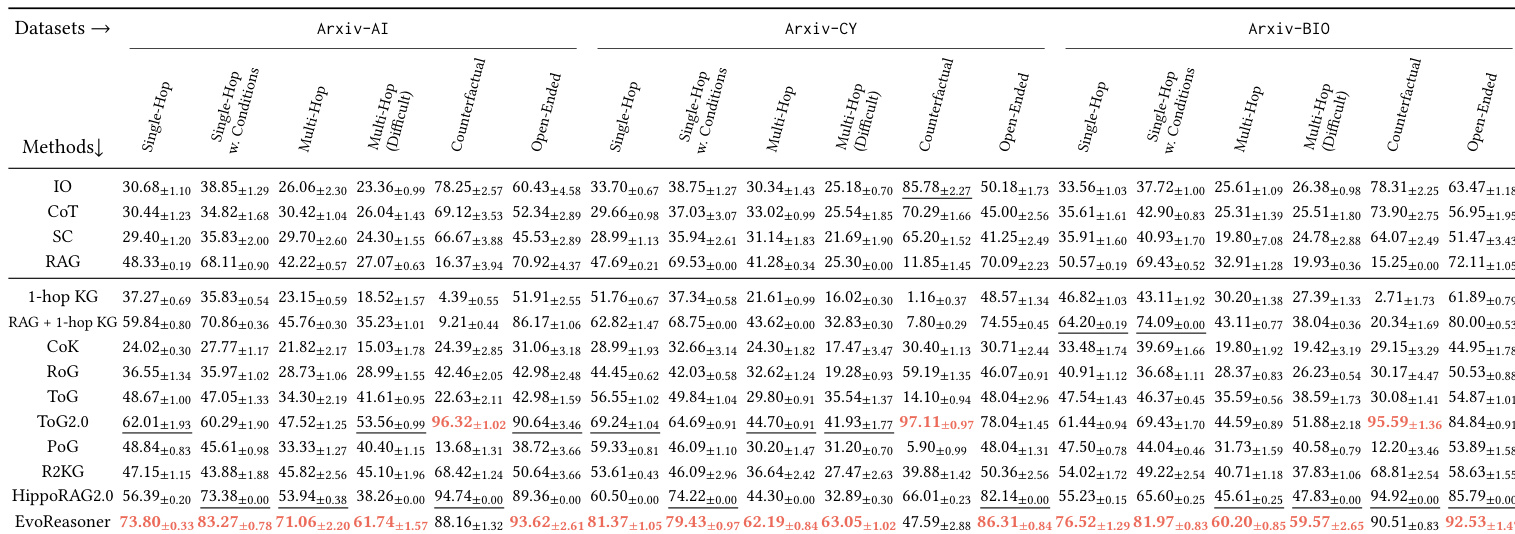
作者使用 HybridRAG-Bench 评估不同检索与推理策略在领域特定任务中的表现,发现无论模型规模如何,纯 LLM 方法始终表现不佳。结果表明,结合结构化知识图谱与文本检索可获得最强性能,尤其在多跳与反事实问题上,表明有效推理不仅需外部信息访问。基准按问题类型有意义地区分方法,揭示混合方法在所有领域均优于纯文本或朴素图增强策略。