Command Palette
Search for a command to run...
密度引导的响应优化:基于隐含接受信号的社群对齐
密度引导的响应优化:基于隐含接受信号的社群对齐
Patrick Gerard Svitlana Volkova
摘要
部署于在线社区的语言模型必须适应那些随社会、文化及特定领域背景而变化的规范。现有的对齐方法依赖于显式的偏好监督或预设原则,这些方法在资源充足的场景中表现有效,却将大多数在线社区排除在外——尤其是那些缺乏机构支持、标注基础设施,或围绕敏感话题组织的社区。在这些社区中,偏好 elicitation(偏好 elicitation,即偏好获取)往往成本高昂、涉及复杂的伦理问题,或存在文化错位。我们观察到,社区实际上已通过其对内容的接受、互动及留存行为隐性地表达了偏好。研究表明,这种接受行为在表示空间(representation space)中诱导出可测量的几何结构:被接受的答案占据着连贯且高密度的区域,反映了特定于社区的规范;而被拒绝的内容则分布于稀疏或与社区规范不一致的区域。我们将这种结构转化为隐式的偏好信号,并提出了“密度引导响应优化”(Density-Guided Response Optimization, DGRO)方法。该方法能够在无需显式偏好标签的情况下,将语言模型与社区规范对齐。利用标注好的偏好数据,我们证明局部密度能够还原社区成对判断,表明几何结构确实编码了有意义的偏好信号。随后,我们在跨越平台、主题和语言的多种社区中,应用于标注稀缺的场景。结果显示,经 DGRO 对齐的模型所生成的响应,在人类标注者、领域专家及基于模型的评审者的评估中,均优于监督学习及基于提示(prompt-based)的基线方法。我们将 DGRO 定位为一种实用的对齐替代方案,适用于那些缺乏显式偏好监督或其与情境化实践存在错位的社区,并探讨了从自发接受行为中学习所涉及的潜在影响与风险。
一句话总结
Patrick Gerard(南加州大学)和 Svitlana Volkova(Aptima)提出了 DGRO 方法,该方法利用隐式接受信号——建模表示空间中接受内容聚集的局部密集区域——使语言模型与社区规范对齐,无需显式偏好标签,特别适用于敏感或标注稀缺的在线社区。
主要贡献
- 作者证明,社区接受行为(如内容留存和互动)会在嵌入空间中诱导可测量的高密度区域,这些区域编码了隐式偏好信号,从而无需显式标注即可实现对齐。
- 作者引入了密度引导响应优化(DGRO),该方法利用表示空间中的局部密度使语言模型与社区规范对齐,并在包括敏感和非英语论坛在内的多样化、标注稀缺场景中得到验证。
- DGRO 对齐的模型在人类和基于模型的评估中优于监督和提示基线方法,但作者明确将该方法定位为描述性方法,并警告因偏见放大和排斥风险而不加批判地部署。
引言
作者利用社区行为——哪些内容被接受、互动或允许留存——作为隐式信号,使语言模型与特定上下文规范对齐,从而避免了昂贵或伦理上棘手的偏好标注需求。先前的方法如 RLHF 和 DPO 依赖于显式的人类反馈,这排除了许多缺乏机构支持或面临文化敏感性的在线社区。DGRO 则将接受的响应建模为嵌入空间中的高密度区域,将局部密度视为偏好的代理。其关键贡献是一种实用的、无需标注的对齐方法,在多样化、标注稀缺的社区中表现优于或匹配监督基线,同时明确将该方法定位为描述性而非规范性,以避免放大有害或排他性规范。
数据集

-
作者使用斯坦福人类偏好(SHP)基准,该基准提供了来自五个不同 Reddit 社区的成对偏好判断:changemyview、askkulinary、askhistorians、legaladvice 和 explainlikeimfive。这些社区因其不同的审核风格、互动规范和响应评估标准而被选中,以测试偏好结构是否能在异质环境中泛化。
-
每个数据实例包括对话历史(提示)、首选响应和非首选响应,由社区投票决定。元数据包括响应间的归一化点赞比率,作为偏好强度的代理。各社区的数据集大小详见附录表 4。
-
为测试流形假设,作者使用固定的句子编码器嵌入所有训练响应,构建无标签参考池。在嵌入或密度估计过程中不使用偏好标签。测试提示通过基于社区分布下估计的局部密度对候选响应进行排序进行评估,使用 150 个最近的训练历史进行条件化。
-
该模型称为“接受密度”,计算首选和非首选响应之间的成对边际,并报告边际为正的概率作为准确率。性能与基线进行比较:随机分配、kNN 多数投票、全局密度估计和原始监督 SHP 奖励模型(作为上限)。
-
所有数据均公开可用,符合平台条款和 CSS 研究规范。未尝试识别个人;分析聚焦于聚合社区模式。作者强调 DGRO 模型描述的是规范,而非规定性价值观,并警告在没有监督、透明度和特定领域保障措施的情况下部署。
方法
作者采用一种称为密度引导响应优化(DGRO)的新方法,从社区接受的响应中推导隐式偏好信号,而不依赖显式人类标注。与 RLHF 或 DPO 等传统对齐方法使用成对偏好标签不同,DGRO 将嵌入空间中接受响应的分布解释为社区规范的代理。具体而言,嵌入在该空间中更高密度区域的响应被视为更符合社区期望,从而能够构建合成的首选/非首选对用于训练。
为实现这一概念,作者采用上下文条件局部密度估计策略。对于给定查询上下文 h,他们首先使用 kNN 搜索在嵌入空间中识别其 k 个最近邻居。这些邻居对应的接受响应形成上下文特定参考集 B(h)。候选响应 x 的接受密度随后通过核密度估计器估计:
logp(x∣h,c)∝log∣B(h)∣1j∈B(h)∑Kσ(x,xj),其中 Kσ 表示带宽由中位数启发式确定的 RBF 核。该公式确保偏好信号是局部校准的——响应相对于社区在语义相似上下文中接受的内容进行评估,而不是相对于可能误导的全局聚合分布。
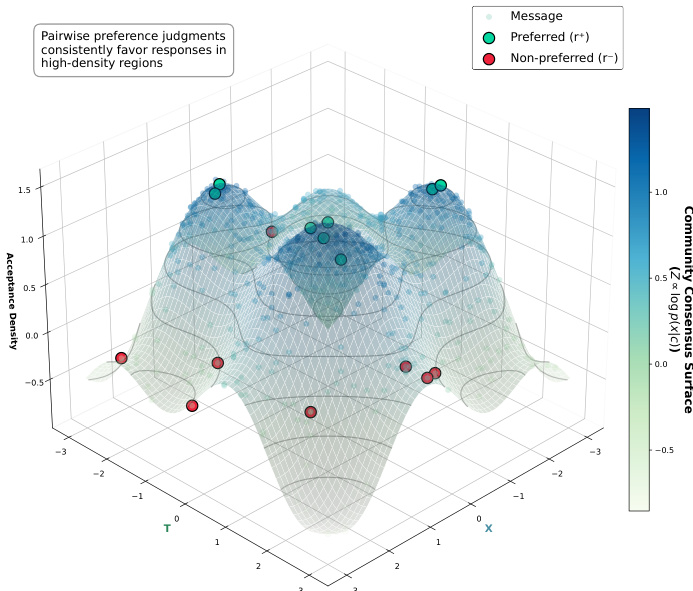
如下图所示,这种局部密度估计使 DGRO 能够自适应地建模跨不同主题和意图的社区规范,保留全局密度估计会掩盖的细粒度偏好结构。
实验
- 验证了流形假设:表示空间中的局部接受密度可靠地恢复了人类偏好信号,特别是在社区共识强烈的情况下,优于全局密度和 kNN 基线。
- 证明了接受密度可以在标准优化目标中替代显式偏好标签,在无标注数据的情况下达到接近监督奖励模型的性能。
- 成功将密度引导响应优化(DGRO)应用于标注稀缺、高风险社区(如饮食失调支持、冲突记录),在生成真实、语境恰当的响应方面始终优于 SFT 和 ICL 等基线。
- 确认在敏感领域,基于 LLM 的评估与人类专家判断一致,能够在不损害可靠性的情况下实现可扩展验证。
- 展示了 DGRO 在不同模型架构和嵌入选择下的鲁棒性,性能在很大程度上独立于基础模型或嵌入类型。
- 识别出一个关键限制:当候选响应完全位于局部接受流形之外时,基于密度的排名变得任意且无信息。
作者使用局部接受密度从社区话语中恢复人类偏好信号,无需显式标注,发现其始终优于无监督基线并接近监督模型性能。结果表明,随着人类共识增强,偏好恢复效果提升,表明表示空间中的局部几何结构编码了有意义的社区规范。这支持将密度引导优化作为对齐任务中标注偏好数据的可行替代方案。

作者使用局部接受密度从社区话语中恢复人类偏好信号,无需显式标注,在高共识情境下达到接近监督模型的性能。结果表明,随着社区共识增强,偏好对齐效果提升,表明表示空间中的局部几何结构编码了有意义的规范区分。在饮食失调和冲突记录等标注稀缺领域,密度引导优化始终优于标准微调和上下文学习,生成在相关性和语气上更符合真实社区规范的响应。
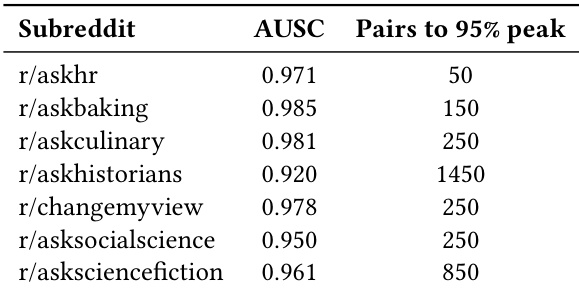
作者评估了不同嵌入模型对多个子版块中局部接受密度恢复社区偏好的影响。结果表明,尽管各子版块性能略有差异,但嵌入模型的选择对整体准确率影响极小,所有测试模型在狭窄置信区间内达到可比结果。这表明在评估条件下,该方法对嵌入架构具有鲁棒性。

作者发现,局部接受密度在社区话语中可靠地恢复人类偏好信号,性能与每个子版块内人类共识强度密切相关。表现出更高共识的社区(如 r/asksciencefiction 和 r/askhr)在基于密度的排名与人类判断之间显示出最强相关性,表明随着规范固化,偏好结构更易恢复。这一模式支持假设:表示空间中的局部几何结构编码了有意义的偏好信息,特别是在社区规范明确的情况下。
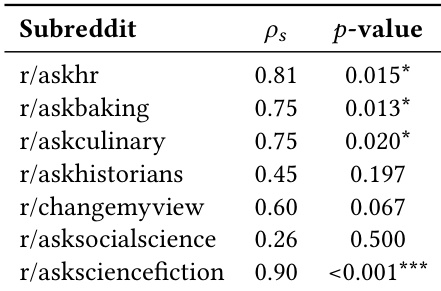
作者使用专家评估验证在标注稀缺领域中基于 LLM 的判断与人类偏好一致,显示中等的标注者间一致性以及专家与 LLM 之间的强等级相关性。聚合的 LLM 判断在 78.4% 的情况下匹配专家多数决定,支持其作为人类评估的可扩展代理。这种可靠性使得在缺乏显式偏好标签的情况下能够大规模评估模型对齐。