Command Palette
Search for a command to run...
PanoWan:通过经纬度感知机制将 Diffusion 视频生成模型提升至 360° 全景维度
PanoWan:通过经纬度感知机制将 Diffusion 视频生成模型提升至 360° 全景维度
Yifei Xia Shuchen Weng Siqi Yang Jingqi Liu Chengxuan Zhu Minggui Teng Zijian Jia Han Jiang Boxin Shi
摘要
全景视频生成能够实现沉浸式的 360° 内容创作,在需要场景一致的世界探索应用中具有极高的价值。然而,由于数据集规模有限以及空间特征表示(spatial feature representations)之间存在差异,现有的全景视频生成模型难以利用传统文本生成视频(text-to-video)模型中预训练的生成先验(generative priors)来生成高质量且多样化的全景视频。在本文中,我们提出了 PanoWan,旨在通过极少的模块,有效地将预训练的 text-to-video 模型迁移(lift)至全景领域。PanoWan 采用纬度感知采样(latitude-aware sampling)以避免纬度失真;同时,通过旋转语义去噪(rotated semantic denoising)和填充式逐像素解码(padded pixel-wise decoding)来确保经度边界处的无缝衔接。为了提供充足的全景视频以学习这些迁移后的表示,我们贡献了 PANOVID——一个包含文本描述(captions)且涵盖多种场景的高质量全景视频数据集。实验结果表明,PanoWan 在全景视频生成任务中达到了 SOTA(state-of-the-art)性能,并在 zero-shot 下游任务中展现出了强大的鲁棒性。
一句话总结
为了将预训练的文本到视频模型提升至 360° 全景领域,作者提出了 PanoWan。该框架利用纬度感知采样、旋转语义去噪和填充式像素级解码,以防止空间失真和边界不连续,并通过在新增的 PANOVID 数据集上进行训练,实现了最先进的性能。
核心贡献
- 本文引入了 PanoWan,这是一个通过极小的架构修改,将生成先验从预训练的文本到视频模型提升到全景领域的框架。
- 该方法利用纬度感知采样来防止纬度失真,并将旋转语义去噪与填充式像素级解码相结合,以确保经度边界处的无缝过渡。
- 研究人员贡献了 PANOVID,这是一个高质量的全景视频数据集,具有多样化的场景和标注的文本描述,使模型能够实现最先进的性能和强大的 zero-shot 泛化能力。
引言
全景视频生成对于为虚拟现实、交互式游戏和具身 AI 模拟创建沉浸式 360 度内容至关重要。虽然传统的文本到视频模型拥有强大的生成先验,但由于数据集规模有限以及空间表示差距(如纬度失真和经度边界处可见的接缝),现有方法难以将这些模型适配到全景领域。作者通过引入 PanoWan 利用了这些预训练先验,该框架利用纬度感知采样、旋转语义去噪和填充式像素级解码来确保空间一致性和无缝过渡。为了支持这一方法,还贡献了 PANOVID,这是一个包含超过 13,000 个带字幕的全景视频剪辑的高质量数据集。
数据集

PANOVID 数据集概述
作者引入了 PANOVID,这是一个旨在解决基于文本的全景视频生成中配对数据匮乏问题的大规模数据集。
- 数据集组成与来源:该数据集汇总自多个全景视频源,包括 360-1M、360+x、Imagine360、WEB360、Panonut360、Miraikan 360度视频数据集以及公开的沉浸式 VR 视频集合。
- 关键细节与规模:最终收集的视频剪辑超过 13,000 个,总时长约为 944 小时。
- 元数据构建与处理:
- 字幕生成与标注:利用 Qwen-2.5-VL 为每个视频生成描述性文本字幕并预测兴趣点 (POI) 类别。
- 冗余去除:为了确保语义多样性,流水线根据字幕相似度去除冗余样本。
- 质量过滤:在每个 POI 类别内,视频根据光流平滑度和美学评分进行严格的过滤过程,仅保留排名最高的样本,以确保语义平衡和视觉质量。
方法
作者提出了 PanoWan,这是一个旨在通过解决等距柱状投影 (ERP) 的独特空间特性,使传统视频扩散模型适配全景视频生成的框架。核心方法利用预训练的视频扩散主干网络(具体为 Wan 2.1),并使用低秩自适应 (LoRA) 来微调极小部分的参数。这种策略允许模型在学习 360 度视图所需的球面坐标映射的同时,保留原始模型的强大生成先验。
整体架构旨在减轻将球面信号映射到笛卡尔坐标时固有的失真。参考框架图:
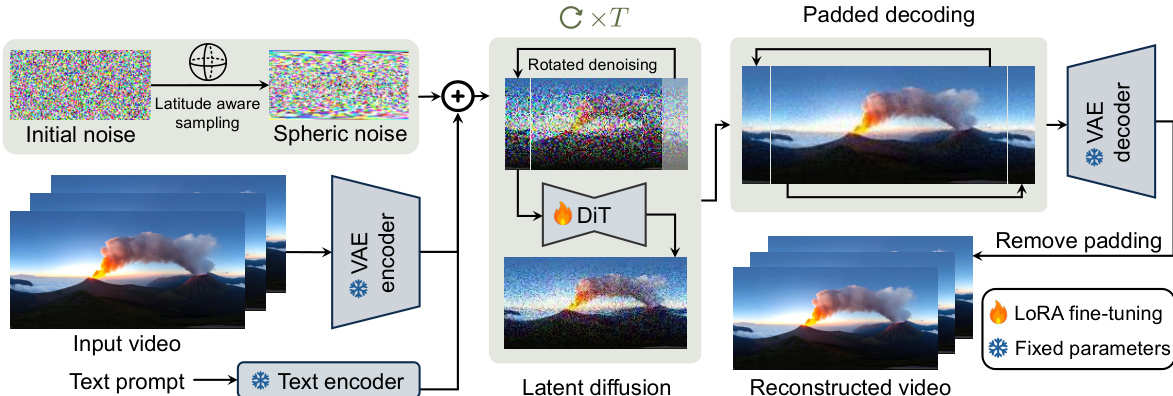
该过程始于视频扩散主干网络,该网络采用时空变分自编码器 (VAE) 将高维视频映射为紧凑的潜码 (latent codes)。为了解决 ERP 导致的极地地区极端的水平拉伸问题,作者引入了纬度感知采样机制。模型不再使用标准的独立同分布 (i.i.d.) 高斯噪声,而是根据纬度重新映射水平采样坐标。这确保了初始噪声与球面频率分布对齐,从而有效地保持了整个球面的频率一致性。
一旦准备好球面噪声,它将作为 VAE 编码潜空间中的潜码。在迭代去噪过程中,模型采用 Diffusion Transformer (DiT) 主干网络。为了防止经度边界(最东经度和最西经度的交汇点)处的接缝伪影,作者实现了旋转语义去噪。该模块通过在每个去噪步骤中将潜码水平滚动特定数量的列来工作。通过移动潜网格,过渡误差被均匀地分散到所有经度上,而不是集中在单个接缝处,从而显著抑制了视觉伪影。
最后,为了确保无缝的像素级过渡,该框架利用了填充式像素级解码。作者并非直接解码去噪后的潜码,而是应用循环填充算子,利用球面对侧的额外上下文来扩展潜码。随后 VAE 解码器处理这种扩展后的表示,并将结果进行中心裁剪以返回最终的全景视频。这确保了靠近原始接缝边界的像素在解码时具有足够的水平上下文,从而产生无缝且连续的视觉输出。
实验
评估结合了适配后的通用视频指标、用户偏好研究以及一种专门的定量指标,用于评估球面一致性和经度边界连续性。对比实验表明,PanoWan 通过保持卓越的全局一致性并避免先前模型中出现的极地失真或复杂的场景失效,表现优于现有方法。消融实验进一步验证了所提出的纬度感知和经度感知模块对于确保正确的几何渲染以及全景接缝处的无缝过渡至关重要。
作者进行了消融实验,以评估纬度感知采样、旋转语义去噪和填充式像素级解码对全景视频生成的影响。结果表明,在通用质量和全景质量指标方面,完整模型的表现均优于移除单个模块的版本。完整模型在通用视频质量、文本-视频对齐和图像质量方面达到了最高性能。移除纬度感知采样主要降低了通用指标,而省略去噪或解码模块则会对全景连续性产生负面影响。与基线方法和消融版本相比,完整实现提供了更优越的运动模式和场景丰富度。
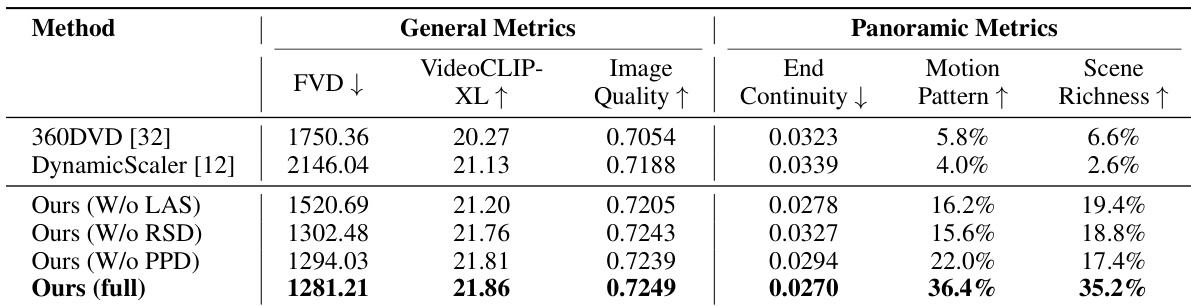
作者进行了消融实验,以评估纬度感知采样、旋转语义去噪和填充式像素级解码对全景视频生成的各自贡献。结果显示,与基线和消融版本相比,完整模型提供了更优越的运动模式、场景丰富度和文本-视频对齐度。虽然移除采样组件会降低通用视频质量,但省略去噪或解码模块会专门损害全景连续性。