Command Palette
Search for a command to run...
VLingNav: 具备自适应推理与视觉辅助语言记忆的具身导航
VLingNav: 具备自适应推理与视觉辅助语言记忆的具身导航
Shaoan Wang Yuanfei Luo Xingyu Chen Aocheng Luo Dongyue Li Chang Liu Sheng Chen Yangang Zhang Junzhi Yu
摘要
Vision-Language-Action (VLA) 模型通过统一感知与规划,并继承了大规模 Vision-Language Models (VLMs) 强大的泛化能力,在具身导航(embodied navigation)领域展现出了巨大的潜力。然而,现有的大多数 VLA 模型依赖于从观测到动作的直接反应式映射,缺乏处理复杂、长程(long-horizon)导航任务所需的显式推理能力和持久记忆能力。为了应对这些挑战,我们提出了 VLangNav,一种基于语言驱动认知的具身导航 VLA 模型。首先,受人类认知双过程理论(dual-process theory)的启发,我们引入了一种自适应思维链(adaptive chain-of-thought, AdaCoT)机制,该机制仅在必要时动态触发显式推理,使 Agent 能够在快速、直觉式的执行与缓慢、深思熟虑的规划之间流畅切换。其次,为了处理长程空间依赖关系,我们开发了一个视觉辅助语言记忆模块(visual-assisted linguistic memory module, VLangMem),用于构建持久的跨模态语义记忆,使 Agent 能够通过回溯过往观测来防止重复探索,并能针对动态环境推断运动趋势。在训练方面,我们构建了 Nav-AdaCoT-2 数据集。
一句话总结
作者提出了 VLingNav,这是一种用于具身导航的 Vision-Language-Action 模型,利用自适应思维链(chain-of-thought)机制在直觉执行与深思熟虑的推理之间进行动态平衡,并结合视觉辅助语言记忆模块来管理长程空间依赖并防止重复探索。
核心贡献
- 本文引入了 VLangNav,这是一种 Vision-Language-Action 模型,结合了自适应思维链(AdaCoT)机制,能够在直觉执行与深思熟虑的规划之间进行动态切换。
- 开发了一种视觉辅助语言记忆模块(VLangMem),用于构建持久的跨模态语义记忆,使 agent 能够回忆过去的观测结果并处理长程空间依赖。
- 该研究实施了专家引导的强化学习后训练阶段以及 Nav-AdaCoT-2 数据集,使模型在基准测试中达到最先进的性能,并实现了向真实世界机器人平台的 zero-shot 迁移。
引言
具身导航是机器人技术的一个关键组成部分,要求 agent 遵循自然语言指令,在未见过的环境中进行感知、推理和规划。虽然 Vision-Language-Action (VLA) 模型提高了泛化能力,但大多数现有方法依赖于从观测到动作的反应式映射。这种缺乏显式推理和持久记忆的情况,使得当前模型难以处理复杂的长程任务或避免重复探索。
作者利用语言驱动的认知架构引入了 VLangNav。提出了一种自适应思维链(AdaCoT)机制,根据环境复杂度在快速、直觉的执行与缓慢、深思熟虑的规划之间进行动态切换。为了管理长期空间依赖,开发了视觉辅助语言记忆(VLangMem)模块,将视觉观测提炼为持久的语义摘要。最后,利用大规模推理数据集和在线专家引导的强化学习阶段,超越了简单的模仿学习,使模型能够达到最先进的性能并实现向真实世界机器人平台的 zero-shot 迁移。
数据集
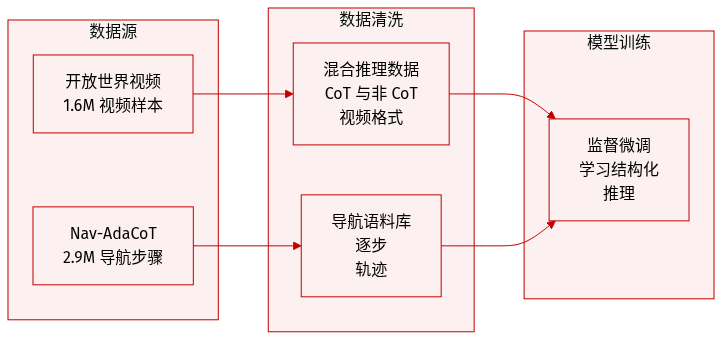
作者构建了一个总计 450 万个样本的大规模训练语料库,由两个主要部分组成:
- Nav-AdaCoT-2.9M (具身导航数据): 该子集包含 290 万条逐步自适应思维链 (CoT) 轨迹,旨在桥接感知、语言和动作。它由多个基准测试构建而成:
- Object-Goal Navigation: 包括通过 Habitat-Web 获取的来自 HM3D ObjNav 的人类演示数据,以及来自 MP3D ObjNav 和 HM3D OVON 的最短路径轨迹。
- Visual Tracking: 利用 EVT-Bench 提供多人员室内追踪数据。
- Image-Goal Navigation: 通过生成最短路径轨迹和逐步动作标签,从 HM3D Instance ImageNav 中衍生而来。
- Open-World Video Data: 为了提高泛化能力并缩小 sim-to-real 差距,作者纳入了来自 LLaVA-Video-178K、Video-R1 和 ScanQA 的 160 万个样本。该子集被处理成两种不同的格式:
- CoT-annotated subset: 由来自 Video-R1 的具有挑战性的视频 QA 对组成。
- Non-CoT subset: 包含另外两个数据集中的剩余样本。
使用与处理细节:
- 训练目的: Nav-AdaCoT-2.9M 作为监督微调阶段的基石,允许模型在强化学习后训练之前获取结构化推理能力。
- 自适应推理策略: 通过将 CoT 标注的视频数据与非 CoT 数据混合,使模型能够学习何时自主决定特定输入是否需要推理。
- 标注风格: 与仅提供指令和动作的传统数据集不同,该数据使用基于轨迹的标注,通过与观测对齐的结构化推理来提供细粒度的监督。
方法
VLingNav 框架通过集成动作模型扩展了基于视频的 Vision-Language Model (VLM),具体为 LLaVA-Video-7B,以实现文本 token 生成与轨迹规划的同步进行。该系统旨在通过涉及观测编码、自适应推理和连续动作预测的多阶段过程来处理复杂的具身导航任务。
参考框架图:
架构始于观测编码模块。为了管理在线推理期间增加的视频帧带来的计算负担,作者提出了一种受艾宾浩斯遗忘曲线启发的动态 FPS 采样策略。历史帧以速率 fs(i) 进行采样,该速率随着距离当前帧的时间间隔 ΔT 的增加而降低: fs(i)=fsmaxe−sΔT 其中 s 代表记忆的稳定性。这确保了作为短期记忆的近期帧以较高的速率被捕获,而作为长期记忆的较旧帧则以更稀疏的速率被采样。为了进一步减少冗余,对历史视觉特征应用了网格池化策略。下采样率 g(i) 也由时间间隔决定: g(i)=⌊e−gΔT⌋Vti′=G(Vti,g(i)) 为了减轻动态采样引起的时序不一致性,引入了使用旋转位置嵌入 (RoPE) 的时序感知指示 token ET,以反映历史观测与当前帧之间的绝对时间间隔 ΔT: ET(ΔT)=EbaseT+RoPE(ΔT) 随后,使用两层多层感知机 (MLP) 投影器 P(⋅) 将编码后的视觉特征投影到 VLM 的潜在空间中,得到投影视觉 tokens EtV=P(Vt′)。
核心推理能力由自适应思维链 (CoT) 机制驱动。模型将视觉 tokens EtV、语言 tokens EI 和时序感知 tokens ET 拼接以形成输入序列。通过预测 CoT 指示 token(⟨think_on⟩ 或 ⟨think_off⟩),训练 VLM 自主决定是否执行推理。当选择 ⟨think_on⟩ 时,模型在 ⟨think⟩ 标签内生成推理内容,并在 ⟨summary⟩ 标签内生成环境摘要。该摘要作为语言记忆存储,并被纳入后续输入中。
如下图所示:
为了将高层推理转化为机器人特定的动作,集成了一个基于 MLP 的动作模型 Aθ(⋅)。它将来自 VLM 最终预测 token 的隐藏状态向量 htpred 作为条件,用以预测运动轨迹 τ^t: τ^t=Aθ(htpred) 动作模型被参数化为多元高斯分布,以提供高精度的连续控制: πθ(at∣st)=N(μθ(ht),diag(σθ(ht)2))
训练过程遵循三阶段流水线。首先,模型在开放世界自适应 CoT 视频数据集上进行预训练,使用交叉熵损失来建立基础推理技能。其次,结合具身导航和开放世界视频数据进行监督微调 (SFT)。SFT 目标在轨迹预测的均方误差 (MSE) 和文本生成的交叉熵 (CE) 之间取得平衡: minθLSFT(θ)=αLMSE(τ^t,τtgt)+(1−α)LCE(Etpred,Etgt) 最后,实施在线后训练阶段,使模型与闭环机器人动作对齐。该阶段利用混合 rollout 策略,在用于 on-policy 数据收集的朴素 rollout 与在 agent 失败时提供纠偏轨迹的专家引导 rollout 之间交替进行。使用结合了 PPO 风格策略梯度损失 LRL 与 SFT 损失 LSFT 的复合目标来更新策略: minθLpost(θ)=λLRL(θ)+(1−λ)LSFT(θ)
实验
VLingNav 通过广泛的模拟基准测试进行了评估,涵盖了 object goal navigation、具身视觉追踪和 image goal navigation,并在四足机器人上进行了 zero-shot 真实世界部署。消融实验证实,自适应推理和跨模态记忆显著提高了导航效率并防止了冗余探索,而在线强化学习有助于 agent 超越模仿学习的局限性。结果表明,多任务训练促进了涌现的跨任务和跨领域能力,使模型能够稳健地泛化到未见过的环境和复杂指令。
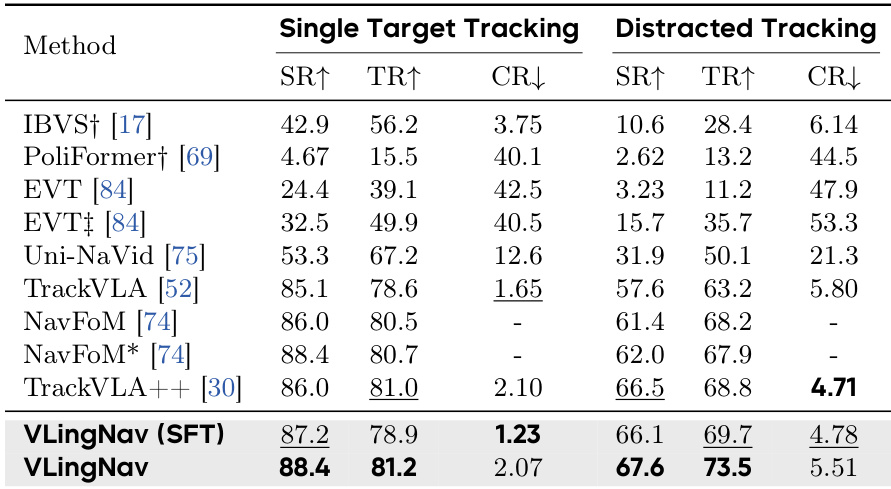
作者在 EVT-Bench 上评估了 VLingNav 在具身视觉追踪任务中的表现。结果显示,该模型在单目标和干扰追踪场景下均达到了最先进的性能。VLingNav 在单目标追踪任务中实现了最高的成功率和追踪率。在更具挑战性的干扰追踪场景中,VLingNav 在对比方法中达到了最高的成功率和追踪率。与之前的最先进基准相比,该模型在干扰设置中表现出更强的鲁棒性。
作者评估了与开放世界视频数据协同训练对各种导航任务的影响。结果表明,引入协同训练提高了 object goal navigation、视觉追踪和 image goal navigation 的性能。协同训练增强了 object goal 和 image goal navigation 任务中的成功率和路径效率。在视觉追踪过程中,加入协同训练数据提高了追踪率并降低了碰撞率。使用协同训练策略时,在多个不同的导航基准测试中性能增益是一致的。

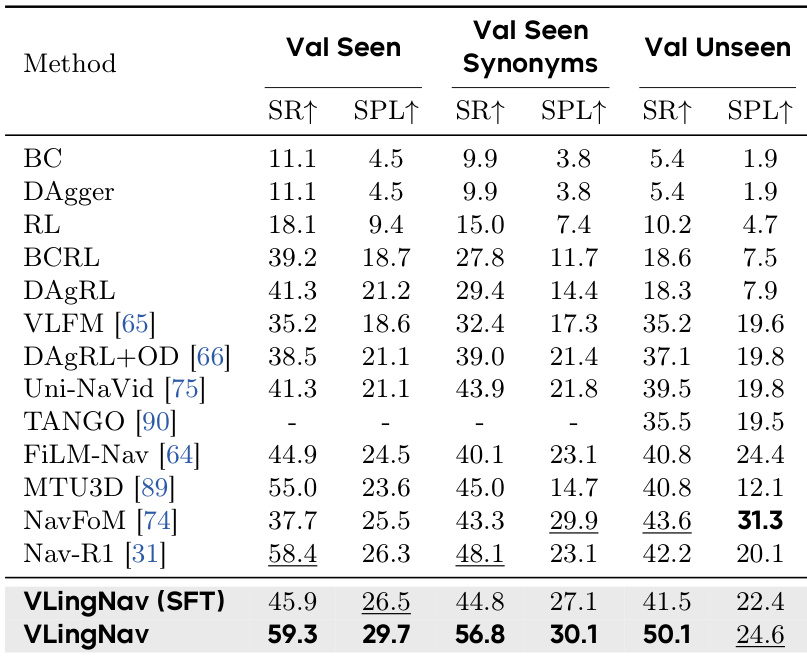
作者在三个不同的测试划分上评估了 VLingNav 在 HM3D-OVON 基准测试中的性能。结果显示,完整的 VLingNav 模型与各种基于模仿学习和 VLA 的基准相比,实现了更优的成功率和路径效率。在已见、同义词和未见物体类别中,VLingNav 的成功率均优于所有对比方法。在已见和同义词划分中,该模型表现出比之前最先进 VLA 模型更高的路径效率。完整的模型比相同架构的 SFT 版本对未见物体类别表现出更好的泛化能力。
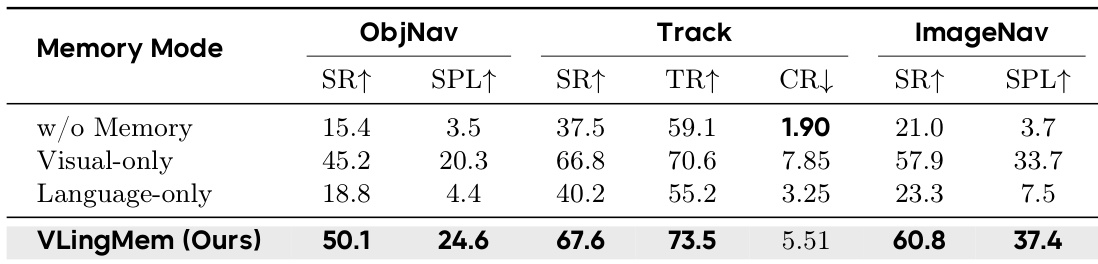
作者进行了消融研究,以评估不同记忆模态对三个不同任务导航性能的影响。结果表明,集成的视觉辅助语言记忆方法优于独立的视觉或语言记忆,也优于没有任何记忆模块的配置。所提出的记忆模块在 object navigation、追踪和 image goal navigation 任务中实现了最高的成功率和效率。完全移除记忆模块会导致所有评估指标达到最低水平。仅使用视觉特征或仅使用语言信息虽有部分改进,但效果仍不如完整的集成记忆系统。
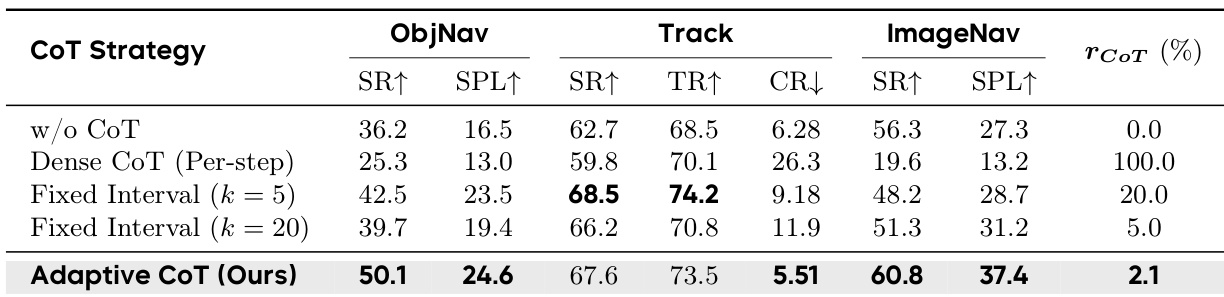
作者进行了消融研究,以评估在 Object Goal Navigation、Visual Tracking 和 Image Goal Navigation 任务中不同的思维链推理策略。结果表明,与不进行推理或在每一步都使用穷举推理相比,所提出的自适应 CoT 策略在大多数指标上都实现了更优的性能。在成功率和路径效率方面,自适应 CoT 优于无推理和密集逐步推理。与固定间隔方法相比,自适应方法在利用显著较低的推理频率的同时保持了高性能。虽然固定间隔策略在某些追踪指标上表现出竞争力,但自适应方法在所有测试的导航任务中提供了最均衡的性能。
作者在各种具身导航和追踪任务中评估了 VLingNav,以验证其性能、协同训练的益处以及架构组件的有效性。结果表明,VLingNav 在单目标和干扰追踪场景中均实现了最先进的成功率和鲁棒性,同时对未见物体类别表现出强大的泛化能力。此外,开放世界视频协同训练、多模态视觉语言记忆系统以及自适应思维链推理策略的集成,显著提升了导航效率和任务成功率。