Command Palette
Search for a command to run...
SURvHTE-Bench:生存分析中异质性治疗效应估计的基准测试
SURvHTE-Bench:生存分析中异质性治疗效应估计的基准测试
Shahrriar Noroozizadeh Xiaobin Shen Jeremy C. Weiss George H. Chen
摘要
在精准医疗和个体化政策制定等高风险应用领域,从右删失(right-censored)生存数据中估计异质性处理效应(Heterogeneous Treatment Effects, HTEs)至关重要。然而,由于存在删失现象、不可观测的反事实(unobserved counterfactuals)以及复杂的识别假设,生存分析场景为 HTE 估计带来了独特的挑战。尽管近期已取得了诸多进展——从 Causal Survival Forests 到生存 meta-learners 以及结果填补(outcome imputation)方法——但目前的评估实践仍然呈现出碎片化且不一致的状态。为此,我们推出了 SURVHTE-BENCH,这是首个针对含有删失结果的 HTE 估计所设计的全面 benchmark。该 benchmark 涵盖了以下内容:(i) 一套模块化的合成数据集,具有已知的 ground truth,并系统性地改变了因果假设和生存动态;(ii) 半合成数据集,将现实世界的协变量(covariates)与模拟的处理效应及结果相结合;(iii) 来自双生研究(具有已知 ground truth)和 HIV 临床试验的真实世界数据集。通过在合成、半合成及真实世界场景下的测试,我们首次在多样化的条件以及符合现实的假设违背(assumption violations)情况下,对生存 HTE 方法进行了严谨的比较。SURVHTE-BENCH 为因果生存分析方法的公平、可复现且可扩展的评估奠定了基础。
一句话总结
为了促进公平且可复现的评估,作者引入了 SURvHTE-Bench,这是第一个用于生存分析中异质性治疗效应(heterogeneous treatment effect)估计的全面基准测试。该基准利用合成、半合成和真实世界数据集,在多种删失条件和复杂的识别假设下,对因果生存方法进行严格比较。
核心贡献
- 本文引入了 SURVHTE-BENCH,这是第一个专门为评估删失生存数据设置下的异质性治疗效应估计而设计的全面基准。
- 该基准提供了一套模块化的工具:具有已知地面真值(ground truth)的合成数据集、结合真实世界协变量与模拟结果的半合成数据集,以及来自双胞胎研究和 HIV 临床试验的真实世界数据集。
- 该工作首次在多种条件和现实的假设违背情况下,对生存 HTE 方法进行了严格比较,为因果生存方法的复现性和可扩展性评估奠定了基础。
引言
从右删失生存数据中估计异质性治疗效应(HTEs)对于精准医疗和个体化决策等高风险领域至关重要。然而,删失的存在和未观测到的反事实增加了识别和估计的难度。尽管各种因果生存方法已经出现,但评估实践仍然是碎片化的,因为研究人员通常依赖于定制的模拟或地面真值未知的有限数据集。这种缺乏标准化的现状使得比较不同估计器的鲁棒性或衡量方法论的进展变得困难。作者引入了 SURVHTE-BENCH,这是第一个旨在为生存 HTE 估计提供公平且可复现评估的全面基准。该基准包含三个算法家族中 53 种方法的模块化实现,并包含一套多样化的合成、半合成和真实世界数据集,用于测试估计器在现实假设违背下的性能。
数据集
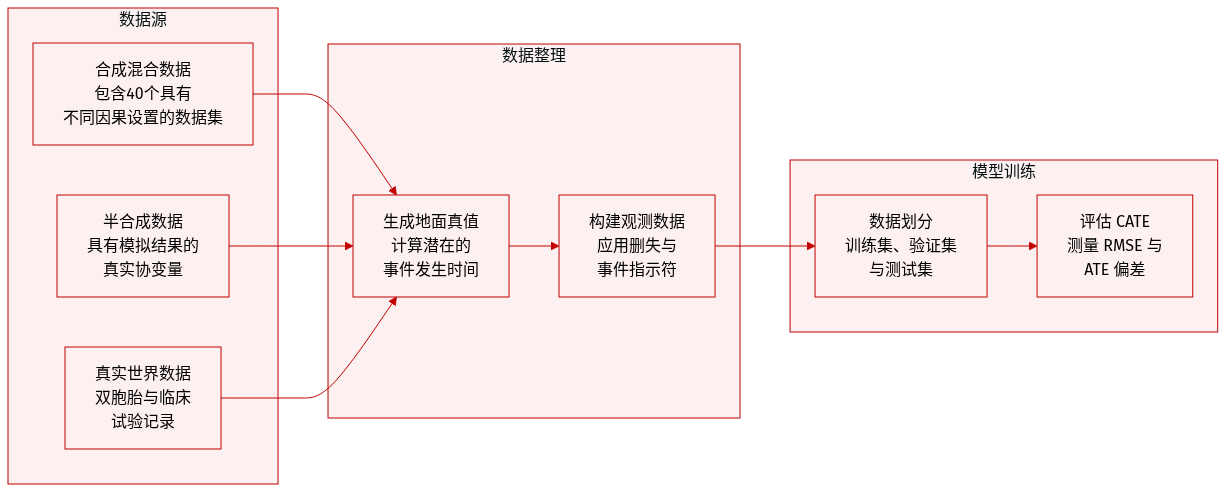
作者引入了 SURVHTE-BENCH,这是一个模块化基准,旨在评估各种因果和生存设置下的生存条件平均治疗效应(CATE)估计器。数据集由三个主要类别组成:
- 合成数据集:通过将 8 种因果配置与 5 种生存场景交叉生成的 40 个数据集套件。
- 因果配置:包括随机对照试验 (RCT) 和观察性研究 (OBS),用于测试对可忽略性(未观测到的混杂)、正值性(缺乏正值性)和可忽略删失(信息性删失)的违背。
- 生存场景:包括 Cox 比例风险模型、加速失效时间 (AFT) 模型和 Poisson 风险模型,删失率从低(低于 30%)到高(超过 70%)不等。
- 详情:每个数据集包含多达 50,000 个单位,具有五个独立的 Uniform(0, 1) 协变量和二元、时间固定的治疗。
- 半合成数据集:10 个数据集将真实世界协变量与模拟的治疗和结果配对,以在提供地面真值 CATE 的同时保持现实的特征分布。
- ACTG HIV 试验:使用来自 ACTG 175 试验的 23 个基线协变量,模拟依赖于协变量的治疗和 Gompertz-Cox 事件时间。
- MIMIC-IV ICU 记录:包含 36 个协变量的九个数据集套件。其中包括一个具有独立治疗分配的子集 (MIMIC-i-v),用于测试删失严重程度(53% 至 88% 删失),以及一个具有混杂分配的子集 (MIMIC-vi-ix),用于测试非线性函数形式。
- 真实世界数据集:
- 双胞胎数据集:专注于美国的双胞胎出生。作者使用兄弟姐妹作为反事实,创建了一个具有已知地面真值的观察数据集。它包含超过 11,000 对双胞胎,具有 43 个特征维度。
- ACTG 175:一个用于在无地面真值情况下进行评估的真实世界临床试验数据集。
数据处理与使用
- 处理:对于合成和半合成数据,作者生成潜在事件时间 T(0) 和 T(1),以确保地面真值 CATE 是已知的。通过取事件时间和删失时间的最小值来构建观测数据。
- 评估策略:使用 CATE RMSE、ATE 偏差以及诸如填补准确性和生存模型拟合度等辅助指标来评估模型。对于双胞胎数据集,采用 50/25/25 的训练、验证和测试划分。
- 目标估计量:该基准专注于截至用户指定时间范围 h 的受限平均生存时间 (RMST)。对于 Poisson 分布的事件时间,在实现事件时间分布的第 25、50 和 75 百分位数处计算地面真值生存概率。
方法
作者评估了多种用于生存分析的因果推断方法,这些方法大致可以分为三个不同的范式:结果填补法、直接生存 CATE 模型和生存 meta-learners。
结果填补法 (Outcome Imputation Methods)
第一种方法通过为删失对象填补代理事件时间,将右删失生存数据转换为标准的回归问题。当仅有观测时间 Y=min(T,C) 和删失指示符 δ 时,作者实现了三种具体的填补策略来估计真实的事件时间 T。
-
边缘填补 (Margin Imputation):该方法使用非参数 Kaplan-Meier 估计器分配一个“最佳猜测”值,解释为在事件发生在删失时间 ti 之后的情况下,事件时间的条件期望: T~imargin=E[Ti∣Ti>ti]=ti+SKM(D)(ti)∫ti∞SKM(D)(t)dt
-
IPCW-T 填补:该策略通过对所有在对象 i 被删失后才发生事件且未被删失的对象之观测事件时间求平均来填补事件时间: T~iIPCW=∑i=1N1{ti<tj}⋅1{δj=1}∑j=1N1{ti<tj}⋅1{δj=1}⋅tj
-
伪观测填补 (Pseudo-observation Imputation):该方法估计对象 i 对平均事件时间无偏估计量 θ^ 的个体贡献。伪观测定义为: T~ipseudo=ϵPseudo−Obs(ti,D)=N⋅θ^−(N−1)⋅θ^−i 其中 θ^ 和 θ^−i 使用 Kaplan-Meier 生存曲线的均值计算得出。
一旦生存结果转换为连续的填补值,就可以应用标准的 meta-learners,如 T-Learner、S-Learner、X-Learner、DR-Learner、Double-ML 和 Causal Forest。
直接生存 CATE 方法 (Direct-Survival CATE Methods)
或者,作者检查了无需填补即可原生处理删失观测的方法。
Causal Survival Forests (CSF) 通过结合双重稳健估计方程扩展了 Causal Forest 框架。该过程涉及估计干扰成分(倾向评分、结果回归和删失生存函数),并构建一个森林,其中树的生长使用针对双重稳健评分变化的因果分裂准则。对于目标点 x,CATE 通过求解以下方程进行估计: ∑α(x)ψτ^(x)(X,y(U),U∧h,W,Δh;e^,m^,S^wC,Q^w)=0
SurvITE 利用表示学习来解决选择偏差。它将协变量 X 映射到潜在表示 Φ(X),同时最小化积分概率度量 (IPM) 以平衡处理组和对照组的分布。同时,它使用特定于治疗的头部 h1 和 h0 来最小化事实损失函数 Lsurv: Φ,h0,h1min∑i=1NwiLsurv(hWi(Φ(xi)),Ti,Δi)+α⋅IPM
生存 Meta-Learners (Survival Meta-Learners)
最后一类由 meta-learning 框架的生存特定改编组成。这些方法直接作用于生存分布,通常使用受限平均生存时间 (RMST) 作为目标指标。
T-Learner-Survival 和 S-Learner-Survival 拟合独立的或统一的生存模型,以估计生存函数 S0(u∣x) 和 S1(u∣x)。然后从它们各自的 RMST 之差中导出 CATE: μ(x,w)=∫0hS(u∣x,w)du
最后,Matching-Survival 通过从相反治疗组中识别 K 个最近邻来填补反事实 RMST,从而在局部相似性之外做出最小的模型假设,以此估计 CATE。
实验
评估利用合成、半合成和真实世界数据集,在不同的因果配置和生存场景下对 53 种估计器变体进行基准测试。实验验证了不同的方法家族,特别是结果填补法、直接生存模型和生存 meta-learners,如何应对变化的删失率以及对可忽略性和正值性等因果假设的违背。研究结果表明,虽然结果填补法在低删失的随机设置中表现出色,但随着删失程度加剧或多个因果假设被违背时,具备生存感知能力的模型展现出更优越的鲁棒性和稳定性。
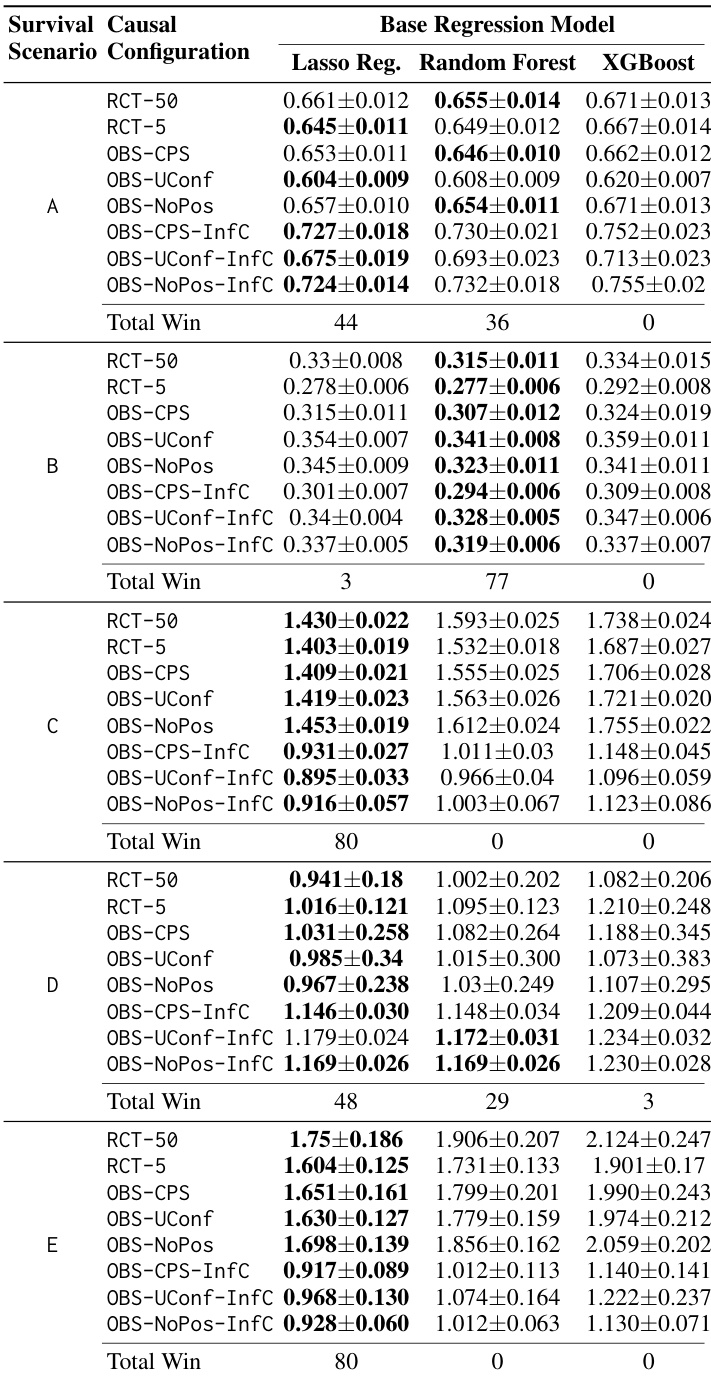
表展示了三种基础回归模型在五种生存场景和各种因果配置下的性能。结果以均值误差加标准差的形式报告,显示了模型准确度如何随删失水平和假设违背而波动。在多个场景中,Lasso Regression 的误差率通常低于 Random Forest 和 XGBoost,特别是在场景 C 和场景 E 中。性能随生存场景的不同而显著变化,场景 B 的误差水平明显低于场景 D 中观察到的较高误差。因果配置对误差的影响是显而易见的,因为模型在从随机试验转向具有信息性删失的观察性设置时,往往表现出不同的稳定性和准确度水平。
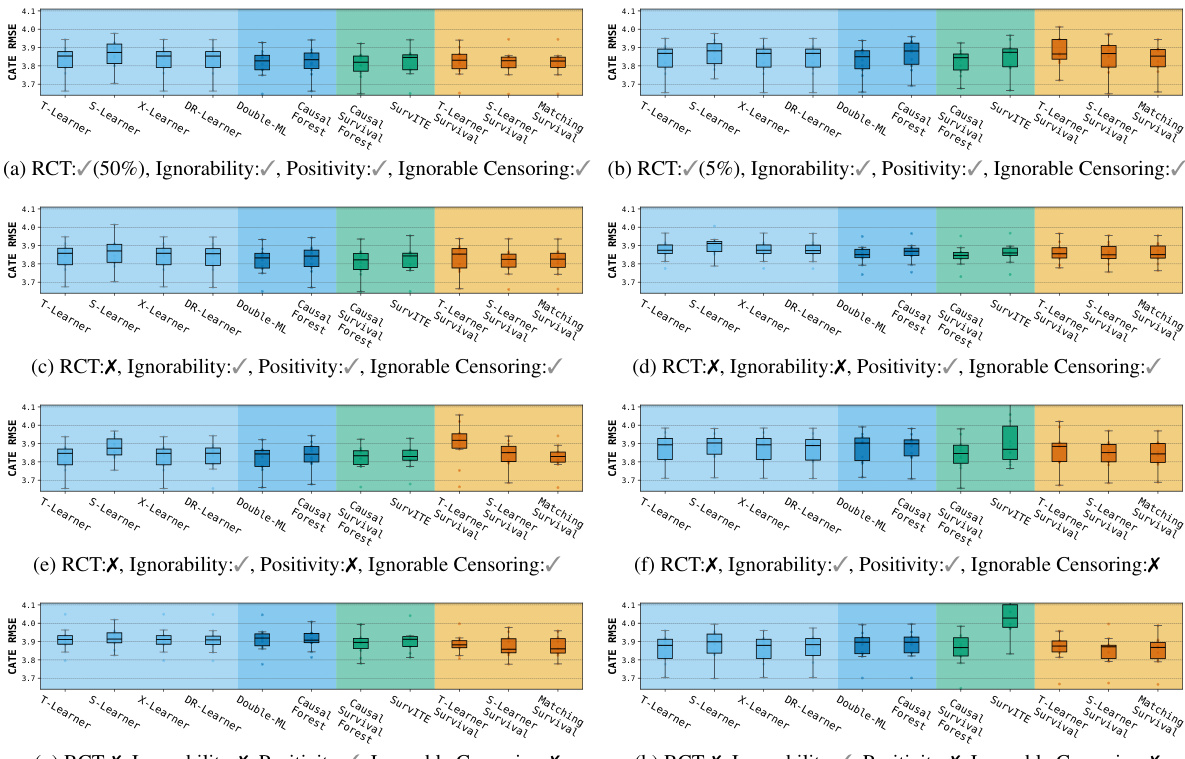
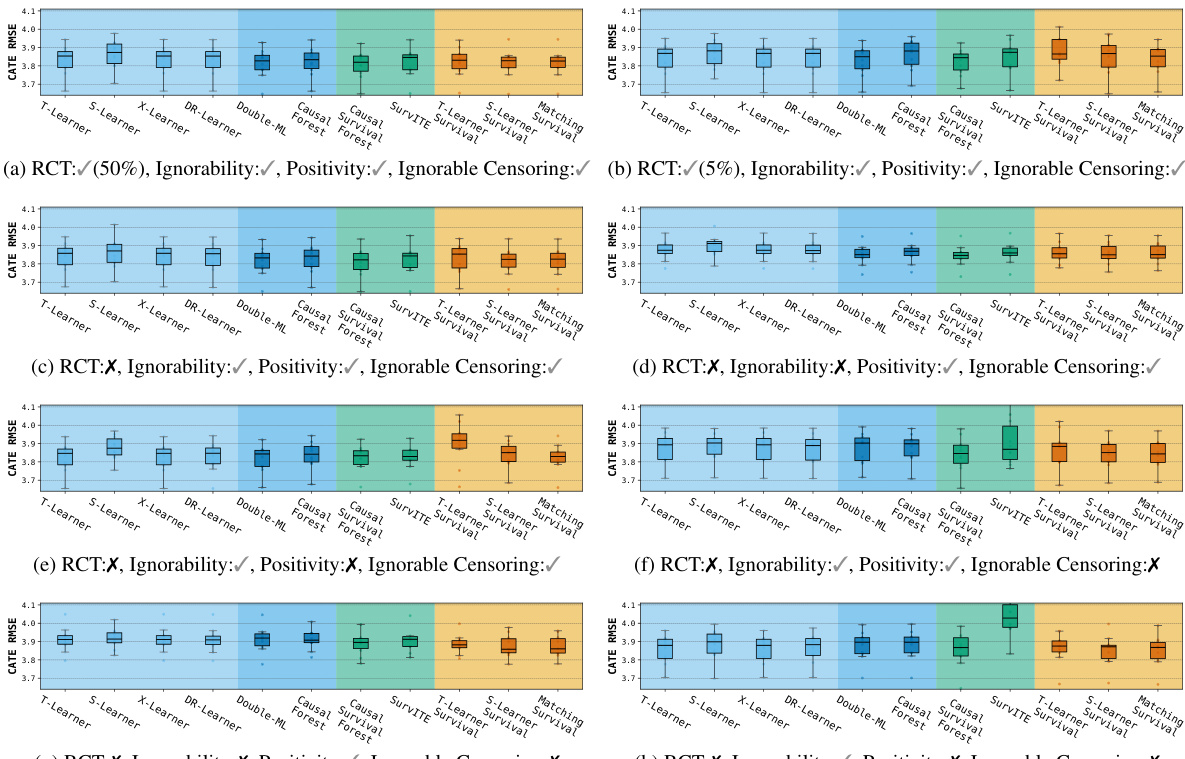
结果评估了各种因果配置下的 CATE RMSE,包括随机对照试验和具有不同假设违背的观察性设置。估计器家族的性能取决于数据遵循随机模式还是观察模式,以及是否满足可忽略性和正值性等因果假设。像 Double-ML 和 X-Learner 这样的结果填补法在治疗分配平衡的随机设置中表现良好。当面临多个因果假设同时违背时,生存 meta-learners 和直接生存模型表现出更高的鲁棒性。估计器性能对特定的因果配置高度敏感,特别是在存在未测量混杂或信息性删失的情况下。
表展示了不同方法家族在各种生存场景和因果配置下的胜率百分比。它说明了不同的数据生成过程和假设违背如何影响特定方法家族获得顶级性能的频率。性能指标随设置是随机对照试验还是观察性研究而显著不同。某些因果配置(如涉及未测量混杂的配置)显示出不同方法家族截然不同的成功模式。信息性删失的引入影响了不同生存场景下的胜率分布。
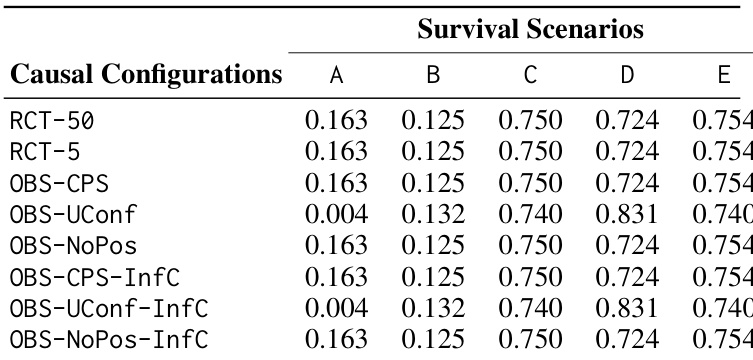
表展示了不同因果估计方法在各种生存场景和因果配置下的总胜场数。它比较了基础回归模型(特别是 Random Survival Forest (RSF)、DeepSurv 和 DeepHit)在处理组和对照组之间的性能。在场景 B 中,处理组的总胜场分布在三个基础模型中,其中 RSF 和 DeepHit 的胜场高于 DeepSurv。场景 C 显示 DeepSurv 模型在处理组中具有显著的胜场集中度,而对照组的胜场在三个模型之间分布较为均匀。在场景 A、D 和 E 中,对照组的胜场分布各异,某些场景表现出对 RSF 模型的强烈偏好,而其他场景在三个基础学习器之间表现出更平衡的结果。
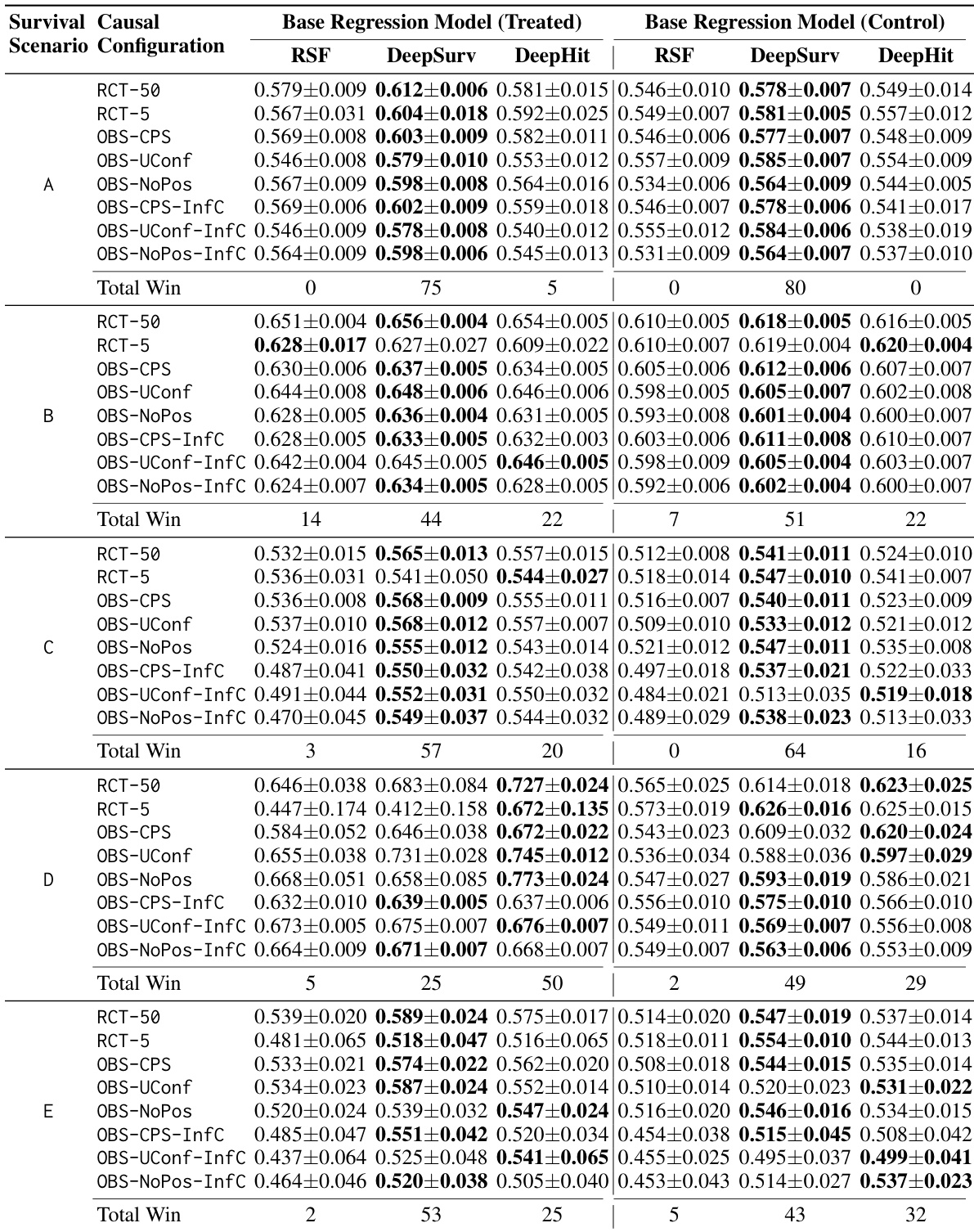
表汇总了不同方法家族在各种实验配置下,按 CATE RMSE 和 ATE Bias 分类的胜率百分比。它显示了每个家族在 Top-1、Top-3 和 Top-5 排名中出现的频率。Double-ML 在 CATE RMSE 方面表现卓越,在所有列出的家族中实现了最高的 Top-1 频率。生存 meta-learners,特别是 Matching-Survival,在 ATE Bias 排名中表现出很强的连贯性,频繁出现在 Top-3 和 Top-5 中。像 Causal Survival Forests 这样的直接生存方法在 CATE RMSE 和 ATE Bias 指标上都保持着具有竞争力的存在感。
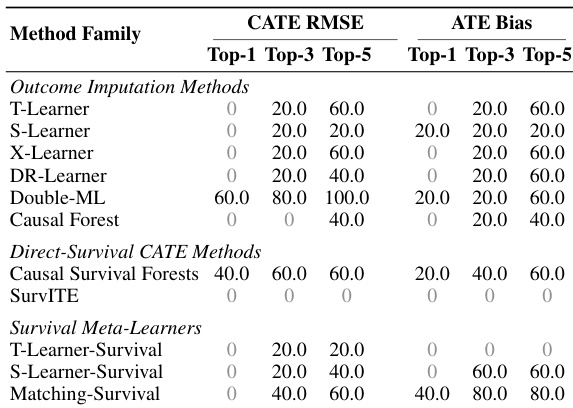
这些实验评估了各种回归模型、meta-learners 和直接生存方法在多种生存场景和因果配置(包括随机试验和具有假设违背的观察性设置)下的性能。结果表明,估计器的准确性和稳定性对数据生成过程(如信息性删失和未测量混杂)高度敏感。虽然 Double-ML 在最小化 CATE 误差方面占据主导地位,但生存 meta-learners 和直接生存模型在面对复杂的因果假设违背时提供了更高的鲁棒性和一致性。