Command Palette
Search for a command to run...
Nemotron-Cascade 2:使用级联强化学习与多域在线策略蒸馏的后训练 LLM
Nemotron-Cascade 2:使用级联强化学习与多域在线策略蒸馏的后训练 LLM
摘要
我们推出了 Nemotron-Cascade 2,这是一款开源的 30B 参数 Mixture-of-Experts (MoE) 模型,其中仅激活 3B 参数,提供了顶级的推理能力和强大的 Agentic(智能体)能力。尽管模型体量紧凑,其在数学和代码推理方面的性能已接近最先进(frontier)的开源模型。继 DeepSeek-V3.2-Speciale-671B-A37B 之后,Nemotron-Cascade 2 成为第二款在 2025 年国际数学奥林匹克竞赛 (IMO)、国际信息学奥林匹克竞赛 (IOI) 以及 ICPC 全球总决赛中达到金牌水平表现的开源 LLM 模型,以相比前者少 20× 的参数规模,展现了极高的智力密度。与 Nemotron-Cascade 1 相比,本代模型的主要技术进展如下:在对精心构建的数据集进行监督微调 (SFT) 后,我们大幅扩展了 Cascade RL 的适用范围,覆盖了更广泛的推理和 Agentic 领域。此外,我们在整个 Cascade RL 过程中引入了针对各个领域中最强中间教师模型的多领域在线策略蒸馏 (on-policy distillation),从而使我们能够高效地恢复在基准测试中出现的性能衰退,并持续获得显著的性能提升。目前,我们已公开模型检查点(checkpoint)和训练数据的集合。
一句话总结
Nemotron-Cascade 2 是一个开放的 30B MoE 模型,拥有 3B 激活参数,提供同类最佳的推理能力和强大的 agent 能力,同时在 2025 年国际数学奥林匹克、信息学奥林匹克和 ICPC 世界总决赛中达到金牌水平表现。通过扩展的 Cascade RL 和多领域策略内蒸馏,其参数比前沿模型少20×,并发布了模型检查点和训练数据。
核心贡献
- Nemotron-Cascade 2 是一个开放的 30B MoE 模型,拥有 3B 激活参数,在 2025 年 IMO、IOI 和 ICPC 世界总决赛中达到金牌水平表现。该工作展示了极高的智能密度,参数比可比的开放前沿模型少 20 倍。
- Cascade RL 大幅扩展,在基于精心策划的数据集进行监督微调后,覆盖了更广泛的推理和 agent 领域。这一扩展使系统能够在多样化任务中保持强劲的性能提升。
- 在 Cascade RL 过程中引入了来自最强中间教师模型的多领域策略内蒸馏,以有效恢复基准回归。模型权重、训练数据和方法细节完全开源,以支持社区复现。
引言
强化学习已成为增强 LLM 推理和 agent 能力的关键,但在多样化现实任务中扩展这些过程往往会导致训练不稳定。之前的 Cascade RL 框架缓解了灾难性遗忘,但在应对日益复杂的环境时难以维持性能提升。该研究通过 Nemotron-Cascade 2 解决了这些挑战,这是一个扩展了 Cascade RL 到更广泛领域的开放 30B MoE 模型。它集成了来自中间教师模型的多领域策略内蒸馏,以恢复基准回归并维持性能提升。这种方法使紧凑模型能够以比前沿竞争对手少 20 倍的参数,在数学和编程方面达到金牌水平表现。
数据集
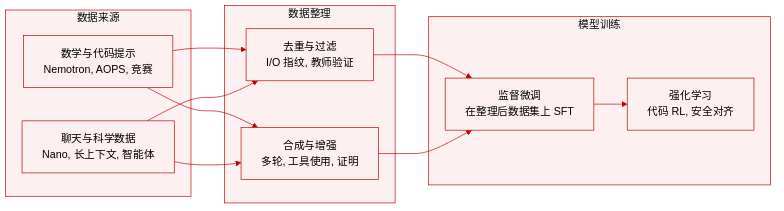
- Mathematics: 非证明提示源自 Nemotron-Cascade 和 Nemotron-Math-v2,总计 440 万样本,分为 180 万工具调用和 260 万非工具类别。证明数据将 9.8 万 AOPS 问题扩展为 81.6 万样本,用于使用 DeepSeek-V3.2-Speciale 进行生成和验证。
- Code Reasoning: 来自竞赛平台的约 16.5 万个独特编码提示经过严格去重,移除了 24.2% 的冗余条目。最终集合包括 190 万 Python 和 100 万 C++14 推理轨迹,以及 130 万 Python 工具调用轨迹。科学编码增加了 110 万涵盖生物、物理和化学的样本。
- Science and Long Context: 科学提示结合了来自 Nemotron-Cascade 的 140 万样本和来自 Nemotron-3-Nano 的 130 万样本。长上下文训练利用了 16 万平均长度为 128K tokens 的样本和 7.4 万平均长度为 29K tokens 的样本。
- General Chat and Instructions: 通用聊天数据包括 490 万推理开启和 37.2 万推理关闭样本,辅以 70 万合成的多轮对话。指令遵循子集优先考虑客观可验证性,源自 Nemotron-Cascade 和 Nemotron-3-Nano 以确保严格遵守约束。
- Agentic Tasks: 对话式工具使用包括 82.2 万多轮样本。软件工程数据混合了 12.5 万 agent 轨迹和 38.9 万 agentless 样本,用于代码修复等任务。终端 agent 任务总计 49 万样本,通过 Terminal-Task-Gen 方法创建。
- Safety and RL: 安全训练使用 4K 样本来模拟适当的拒绝行为。代码强化学习将 Nemotron-Cascade 语料库筛选至 3.5K 高难度提示,其中教师模型在所有 rollouts 中未能正确解决。
- Processing Details: 流水线采用 I/O 指纹和 n-gram 分析进行去重。GPT-OSS-120B 等教师模型验证编码轨迹的正确性,而多轮对话使用角色扮演设置进行合成以防止重复交换。
方法
训练框架始于监督微调 (SFT),为模型提供数学、编程、科学和 agent 任务的基础能力。该研究采用特定的聊天模板以简化交互模式。为简化起见,移除了显式的思考标签,而是前置一个空块以激活非思考模式。对于工具调用任务,系统提示明确列出可用函数,指示模型将工具调用包裹在特定标签内。

在 SFT 之后,实施了级联强化学习 (Cascade RL) 流水线。这种顺序的、按领域的排序旨在随着模型与日益多样化的环境交互时缓解灾难性遗忘。过程始于指令遵循 RL (IF-RL) 以建立基础指令遵循。随后是多领域 RL 以增强工具调用、STEM 推理和响应格式遵循。为了统一专业专长并缓解性能下降,流水线集成了多领域策略内蒸馏 (MOPD)。后续阶段包括用于对齐的人类反馈强化学习 (RLHF)、用于大规模序列推理的长上下文 RL、用于竞赛编程的代码 RL,以及用于掌握 agent 软件交互的软件工程 RL。

这些阶段的顺序由最小化跨领域负面干扰的需求决定。例如,IF-RL 优先早期进行,因为它可能负面影响人类对齐,随后由 RLHF 恢复。MOPD 作为关键的稳定点,以恢复可能在专门阶段退化的基准性能。在整个 Cascade RL 过程中,使用组相对策略优化 (GRPO) 算法进行严格的策略内训练。移除了 KL 散度项,将目标简化为具有组归一化奖励和 token 级损失的标准 REINFORCE 目标。损失函数定义为:
IGRPO(θ)=E(q,a)∼D,{oi}i=1G∼πθ(⋅∣q)∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣A^i,t其中优势 A^i,t 使用组归一化奖励计算。对于 RLHF,奖励从生成奖励模型聚合,而对于其他领域,则根据真实答案进行验证。
实验
Nemotron-Cascade-2 在涵盖数学推理、编程、长上下文理解和对齐的综合基准套件上进行了评估,以验证其 Cascade RL 和 MOPD 训练流水线的有效性。该模型在 IMO 2025 和 IOI 2025 等顶级竞赛中达到金牌表现,尽管其紧凑的 30B MoE 规模,仍优于更大的前沿模型。此外,实验展示了相对于标准方法的显著训练效率优势,并表明 agentless 强化学习将代码修复能力泛化到更广泛的 agent 任务。
在 LiveCodeBench Pro 25Q1 Medium 基准上评估了 Nemotron-Cascade-2-30B-A3B 模型。结果表明,该紧凑的 30B 参数模型显著优于规模相似的竞争对手,同时实现了与数百亿参数的大得多的模型相当的性能。Nemotron-Cascade-2-30B-A3B 在中等难度编码基准上达到了与领先模型相当的性能。该模型通过匹配 Kimi-K2.5-1T 等显著更大模型的结果展示了卓越的效率。它显示出优于参数数量相似的 Qwen3.5-35B-A3B 模型的显著改进。

在三个著名竞赛上评估了 Nemotron-Cascade-2 模型:IMO 2025、IOI 2025 和 ICPC 世界总决赛 2025。该模型在所有三项赛事中均达到金牌状态,尽管规模紧凑,但在数学推理和竞赛编程方面展示了强大的能力。该模型通过成功解决大部分问题,在 IMO 2025 竞赛中获得了金牌。在 IOI 2025 竞赛中,该模型以高总分获得金牌,显示出在算法问题解决方面的高熟练度。对于 ICPC 世界总决赛 2025,该模型解决了几乎所有问题以赢得金牌,验证了其在复杂编码环境中的有效性。

在涵盖 Div 1 和 Div 2 类别的 40 轮 Codeforces 上评估了模型,详细说明了问题级分数和聚合指标。结果表明,在较简单的问题上持续成功,并在众多 Div 2 竞赛中达到顶级估计排名。此外,该模型在 Div 1 轮次中实现了显著更高的 ELO 评分,展示了在困难任务上的强大推理能力。该模型在多个 Div 2 竞赛中获得了第一名的估计排名。Div 1 轮次通常比 Div 2 轮次产生更高的 ELO 评分。该模型在几乎所有竞赛中持续解决了初始简单问题。

在包括 LiveCodeBench 和 Codeforces 在内的竞赛编程基准上评估了 Nemotron-Cascade-2-30B-A3B 模型。结果表明,该模型实现了与更大前沿模型相当的强大性能,特别是在利用工具集成推理时。数据表明,启用工具使用显著提高了其他模型经常挣扎的困难问题的成功率。具有工具集成推理的模型在大型基线模型经常得零分的困难编码问题上实现了非零准确率。LiveCodeBench 和 Codeforces 基准上的性能可与或超过具有超过 1000 亿参数的显著更大的开源模型。与标准配置相比,启用工具集成 consistently 提升了 Easy、Medium 和 Hard 难度类别的分数。

在几个强大的基线上评估了 Nemotron-Cascade-2-30B-A3B 模型,显示其在数学和编码推理任务中实现了最先进性能。结果表明,该模型在大多数推理和对齐基准上优于更大的 120B 参数变体和规模相似的 Qwen3.5 模型。然而,数据表明它在特定知识密集型和 agent 领域落后于 Qwen3.5 基线。该模型在 IMO 2025 和 IOI 2025 等主要数学和编程竞赛中达到了金牌水平结果。它在数学和代码推理类别中持续优于更大的 Nemotron-3-Super-120B-A12B 模型。与 Qwen3.5-35B-A3B 基线相比,该模型显示出更优越的指令遵循和对齐分数。

Nemotron-Cascade-2-30B-A3B 模型在包括 LiveCodeBench、Codeforces 以及 IMO 和 IOI 2025 等主要数学竞赛在内的著名基准上进行了评估。结果表明,该紧凑模型达到了金牌状态,优于规模相似的竞争对手,同时匹配了显著更大的前沿模型的性能,特别是在利用工具集成推理解决困难问题时。尽管它在特定知识密集型领域显示出轻微局限性,但该架构在复杂编码和数学任务中提供了最先进的效率和对齐。