Command Palette
Search for a command to run...
ThinkTwice:面向推理与自我修正的 Large Language Models 联合优化研究
ThinkTwice:面向推理与自我修正的 Large Language Models 联合优化研究
Difan Jiao Qianfeng Wen Blair Yang Zhenwei Tang Ashton Anderson
摘要
我们提出了 ThinkTwice,这是一个基于 Group Relative Policy Optimization (GRPO) 的简单两阶段框架,通过联合优化 LLMs 以解决推理问题并优化答案。在每一对训练步骤中,ThinkTwice 首先针对解决推理问题对模型进行优化,随后针对同一问题的解题过程进行自我修正(refinement)优化;在两个阶段中,均使用相同的二元正确性奖励(binary correctness reward),且无需额外的正确性信号或批判性标注(critique annotations)。通过在五个数学推理 benchmark 以及包括 Qwen3-4B 和 Olmo3-7B 在内的两个模型家族上进行测试,结果表明,相比于具有竞争力的在线策略优化(online policy optimization)基线,ThinkTwice 在推理和自我修正性能方面均有显著提升。具体而言,在 Qwen3-4B 模型上,以 pass@4 作为衡量标准,ThinkTwice 在 AIME 测试集上的表现,在修正前比 GRPO 高出 5 个百分点,在经过一次自我修正步骤后,领先幅度扩大至 11.5 个百分点。对 ThinkTwice 训练动态的分析揭示了一种隐式的“先纠错、后强化”(rectify-then-fortify)的学习课程:在训练初期,修正过程主要用于纠正错误;随着模型能力的提升,修正过程会自然地转向保留已经正确的解,从而产生更具纠错性的奖励信号。我们的工作证明,将推理与自我修正进行联合训练,是强化学习解决验证任务(Reinforcement Learning from Verifiable Rewards, RLVR)的一种原则性且有效的方法论。
一句话总结
来自多伦多大学和 Coolwei AI Lab 的研究人员提出了 ThinkTwice,这是一个两阶段框架,利用 Group Relative Policy Optimization 来共同优化大型语言模型的推理和自我改进(self-refinement)能力,且无需批评性注释(critique annotations),在包括 Qwen3-4B 和 Olmo3-7B 在内的两个模型家族以及五个基准测试中显著提升了数学推理性能。
核心贡献
- 本文介绍了 ThinkTwice,这是一个两阶段强化学习框架,通过使用 Group Relative Policy Optimization 共同优化大型语言模型以解决推理问题并进行自我改进。该方法在两个阶段中均使用共享策略和单一的二值正确性奖励,从而消除了对批评性注释、过程标签或外部验证器的需求。
- 研究展示了训练过程中一种隐式的“先纠错后强化”(rectify-then-fortify)课程学习机制,模型最初专注于纠正错误,随后转向保留正确的解法。这种动态行为产生了更有效的纠错奖励信号,且与标准优化基准相比,训练开销极小。
- 在五个数学推理基准测试和两个模型家族(包括 Qwen3-4B 和 Olmo3-7B)上的实验结果表明,与具有竞争力的在线策略优化基准相比,性能有了显著提升。例如,在 AIME 基准测试中,通过 pass@4 衡量,该框架在经过一个自我改进步骤后,将 Qwen3-4B 的性能提升了 11.5 个百分点。
引言
具有可验证奖励的强化学习(RLVR)是通过基于结果的信号来增强大型语言模型推理能力的关键技术。虽然现有的自我改进方法通常依赖于昂贵的过程监督、批评性注释或外部验证器,但它们往往无法学习到可重用的改进策略,或者在处理不可靠的仅基于提示(prompt-only)的修正时表现挣扎。作者利用名为 ThinkTwice 的两阶段框架,仅使用简单的二值正确性奖励来共同优化推理和自我改进。通过在优化问题解决和优化解法改进之间交替进行,该框架建立了一种隐式课程,在训练早期纠正错误,并随着模型的提升保留正确的解法。
数据集
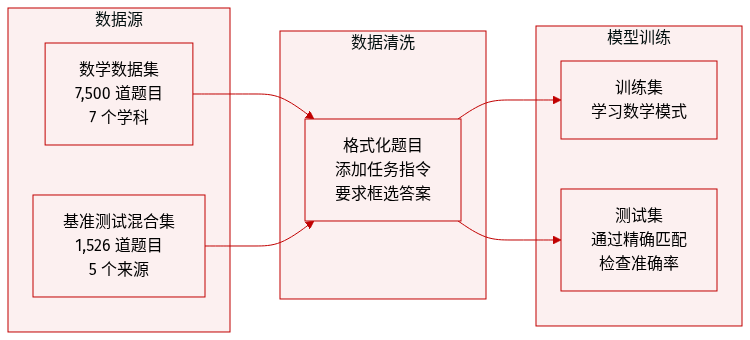
作者利用以下数据集进行训练和评估:
- 训练数据:模型在 MATH 数据集上进行训练,该数据集包含 7,500 个问题,分为七个学科和五个难度级别。
- 评估基准:为了评估数学推理能力,作者使用了从五个不同来源提取的 1,526 个问题的测试集:
- MATH500:源自 MATH 测试集的 500 个问题。
- OlympiadBench:来自奥林匹克级别竞赛的 581 个问题。
- Minerva Math:来自高中数学竞赛的 272 个问题。
- AIME:来自 2022 年至 2024 年期间 AIME 的 90 个问题。
- AMC:来自 AMC 10/12 竞赛的 83 个问题。
- 数据处理与评估:每个问题都结构化为一个特定的任务指令,指导模型在方框格式内提供最终答案。准确性通过使用 Huggingface Math-Verify 工具对方框内容进行精确匹配来衡量。
方法
作者利用 Group Relative Policy Optimization (GRPO) 作为 ThinkTwice 的基础强化学习算法,从而在没有外部验证信号的情况下实现推理和自我改进的共同优化。GRPO 的运行方式是为每个输入采样一组响应,并通过组归一化计算优势(advantages),这消除了对单独的 critic 模型的依赖并增强了训练稳定性。策略更新遵循剪切代理目标(clipped surrogate objective),该目标在性能提升与针对参考策略的 KL 散度约束之间取得平衡,奖励源自数学推理任务中基于结果的正确性。

如下图所示,ThinkTwice 框架在统一的 GRPO 结构内,在两个不同的训练阶段之间交替进行。在阶段 1 中,模型使用当前策略为一批问题生成多个候选解,使用正确性奖励对其进行评估,并根据这些结果更新策略。该阶段专注于推理优化,模型学习从零开始生成准确的解法。从生成的响应中,每个问题会随机选择一个基础解,作为后续改进阶段的输入。
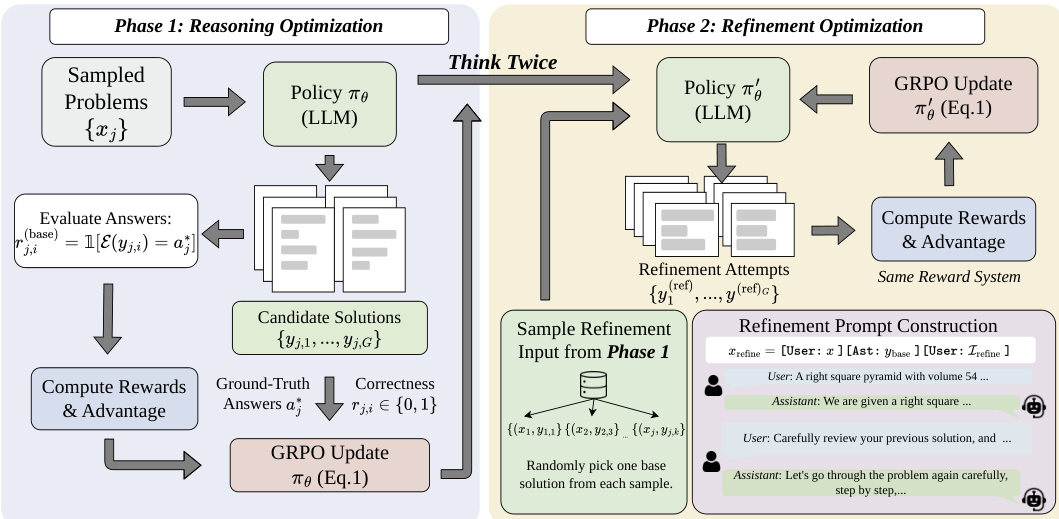
在阶段 2 中,模型使用更新后的策略为选定的基础解生成改进尝试。改进提示被构建为一个多轮对话,以模型自身的先前响应以及一个任务无关的审查和改进指令为条件。改进过程同样使用相同的正确性奖励进行评估,并通过 GRPO 再次更新策略,使模型能够学习自我改进策略。这种两阶段结构使模型在互补的目标下,针对每个问题进行两次处理:一次用于初始推理,一次用于改进。
该框架采用简单的随机采样策略来选择基础解,这自然地建立了一种涌现的课程学习机制:在训练早期,改进主要针对错误的解法,而在后期则专注于润色正确的解法。改进过程完全依赖于二值正确性奖励,允许模型在没有外部约束的情况下开发自己的改进策略。这种奖励设计鼓励模型要么检测并纠正错误,要么保留并增强正确的解法,这与无需外部信号进行自我改进的目标相一致。
实验
ThinkTwice 框架通过双重协议进行评估,该协议在五个数学推理基准测试中测试了直接推理能力和多轮自我改进性能。使用 Qwen3-4B 和 OLMo3-7B 的实验表明,求解任务与改进任务的共同优化显著增强了初始推理准确性和纠错能力。定性分析揭示了一种隐式的训练课程,模型在训练早期从纠正具体的错误和完成中断的推导,转变为在后期强化并压缩已经正确的解法。
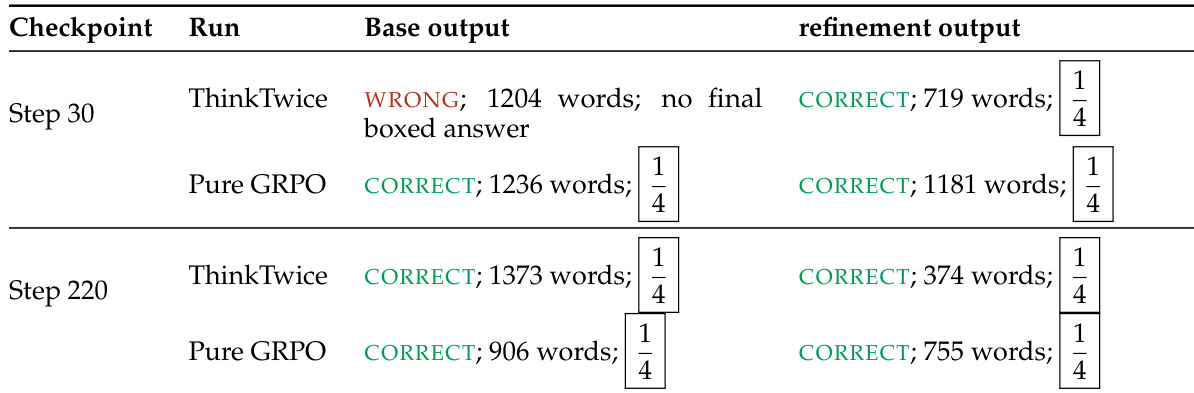
表格显示了 ThinkTwice 改进行为随训练步骤的演变。在训练早期,ThinkTwice 纠正错误的原始输出,而在后期,它会缩短并清理已经正确的解法。与基础生成相比,改进过程始终能产生输出长度更短且正确的答案。训练早期改进纠正错误的原始输出,训练后期改进缩短并清理正确的原始输出,改进过程始终产生比基础生成长度更短的正确答案。
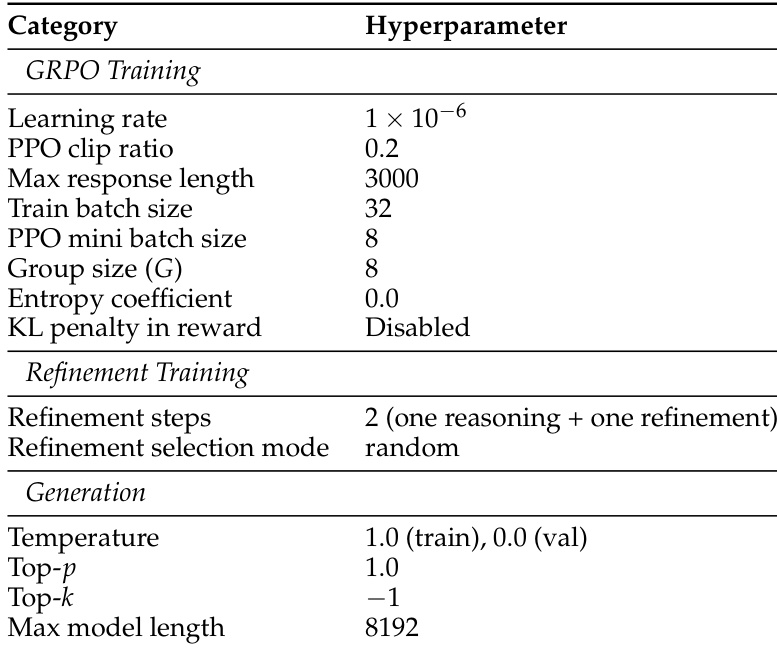
实验对 ThinkTwice 采用了两阶段训练过程,首先优化推理,然后改进解法。设置包括了 GRPO 训练、改进步骤和生成设置的超参数,重点在于训练期间对响应长度和采样的控制。ThinkTwice 使用两阶段训练过程,分别为推理和改进设置了独立的阶段。训练包括 GRPO 和改进的特定超参数,如 batch size 和响应长度。生成设置控制采样行为,通过设置 temperature 和 top-p 值来引导模型输出。
实验评估了模型在不同训练阶段改进自身解法的能力。结果表明,早期改进纠正结构性错误和不完整的推导,而后期改进通过删除不必要的细节来缩短正确的解法。这种从错误纠正到解法润色的转变在多个问题和模型中一致出现。早期改进纠正结构性错误和不完整的推导,后期改进通过删除不必要的细节来缩短正确的解法,改进过程在训练过程中从错误纠正转向解法润色。

ThinkTwice 在两个模型上均实现了最高的推理和改进性能,在直接推理和自我改进任务上始终优于所有基准。结果表明,ThinkTwice 在统一的训练框架内提升了这两种能力,且在最具挑战性的基准测试中增益最为明显。ThinkTwice 在所有模型和基准测试中,推理和改进的平均性能均达到最高。ThinkTwice 在最具挑战性的 AIME 基准测试中显著优于所有基准。ThinkTwice 在无需外部监督或批评性注释的情况下,同时提升了推理和自我改进能力。
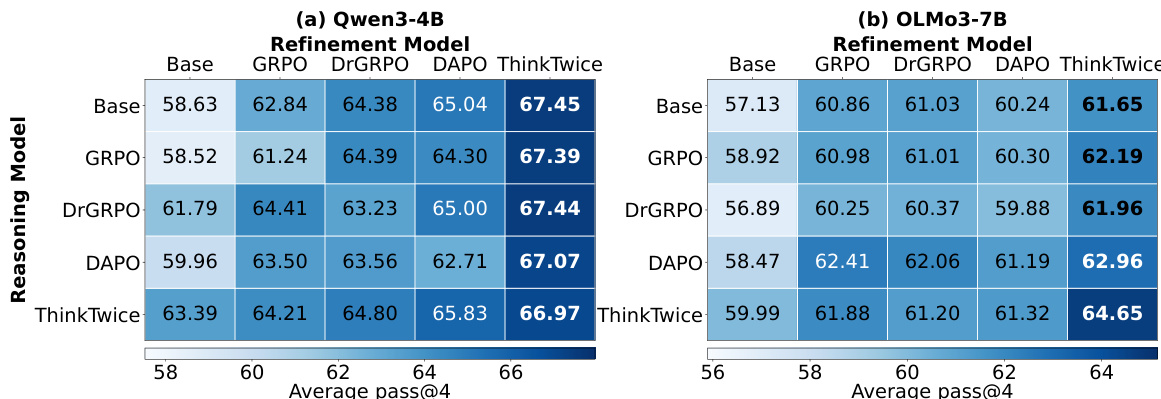
ThinkTwice 在 Qwen3-4B 和 OLMo3-7B 模型上,在多个数学推理基准测试中均实现了最高的平均性能,显示出在推理和自我改进方面均优于现有方法。在最具挑战性的 AIME 基准测试中增益最为显著,ThinkTwice 在该测试中的得分始终高于其他方法。ThinkTwice 在两个模型的所有基准测试中均实现了最高的平均性能,ThinkTwice 在 AIME 基准测试上优于所有基准,ThinkTwice 在无需外部监督的情况下提升了推理和自我改进能力。
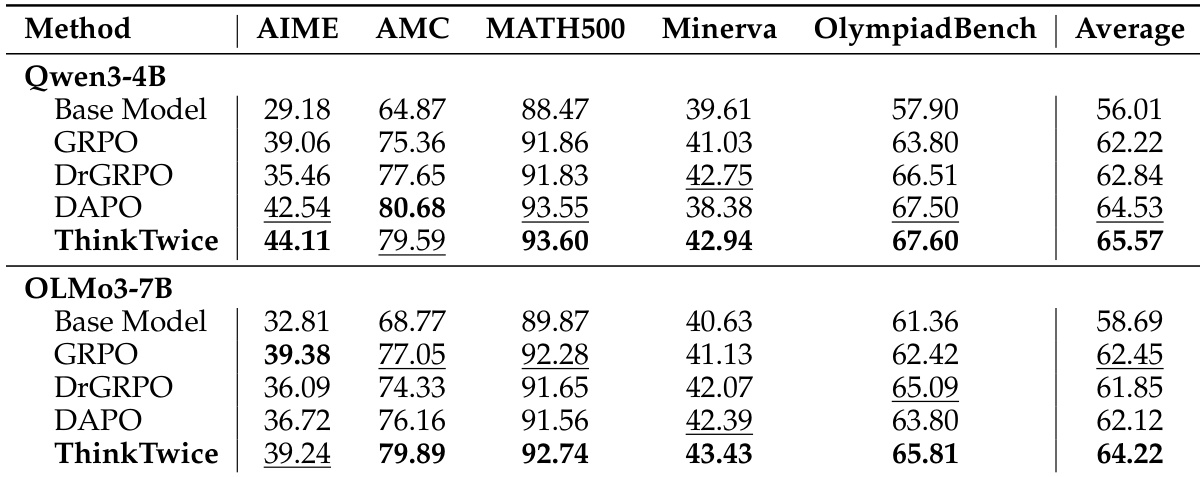
评估采用两阶段训练过程,以评估模型如何在各种数学基准测试中发展推理和自我改进能力。结果表明,改进行为从训练早期的纠正结构性错误,演变为后期对正确解法的润色和缩短。最终,ThinkTwice 在直接推理和自我改进方面均始终优于基准方法,在无需外部监督的情况下,在极具挑战性的任务上表现出最显著的提升。