Command Palette
Search for a command to run...
ACES:谁在测试测试集?面向代码生成任务的留一法(Leave-One-Out)AUC 一致性研究
ACES:谁在测试测试集?面向代码生成任务的留一法(Leave-One-Out)AUC 一致性研究
Hui Sun Yun-Ji Zhang Zheng Xie Ren-Biao Liu Yali Du Xin-Ye Li Ming Li
摘要
利用 LLM 生成的测试来筛选 LLM 生成的代码候选集是一项具有挑战性的任务,因为测试本身可能存在错误。现有方法要么对所有测试一视同仁,要么依赖于特定的启发式规则(ad-hoc heuristics)来过滤不可靠的测试。然而,判定测试的正确性需要预先知道哪些代码是正确的,这从而产生了一种循环依赖(circular dependency)。我们的核心洞察是:我们完全不需要去判定测试的正确性,即“测试投票应用于排序,而非仅仅是计数”。关键不在于有多少代码通过了某项测试,而在于该测试能否区分(distinguish)正确代码与错误代码。我们通过“留一法评估”(leave-one-out evaluation)打破了这种循环依赖:预留一项测试,根据代码在所有剩余测试上的综合得分进行排序,然后衡量被预留的测试在“通过/失败”模式上是否与该排序一致。我们将这种一致性形式化为“留一法 AUC”(LOO-AUC),并证明了预期的 LOO-AUC 与各项测试区分正确代码和错误代码的能力成正比。基于此,我们提出了 ACES(AUC ConsistEncy Scoring),并包含两种互补的变体:ACES-C 在关于平均测试质量的温和假设下,能够提供在期望意义上可证明逼近 Oracle(标准答案)的闭式解权重;ACES-O 则无需该假设,通过迭代优化一个可微的 LOO-AUC 目标函数来实现。两种方法仅需基于二值化的通过矩阵(binary pass matrix)即可运行,且开销极小,并在多个代码生成 benchmark 上实现了最先进的(state-of-the-art)Pass@k 性能。
一句话总结
南京大学的研究人员提出了 ACES,这是一个评分框架,通过利用留一法(leave-one-out)AUC 一致性来衡量测试区分正确与错误代码的能力,从而解决了评估 LLM 生成的代码测试时存在的循环依赖问题。该框架提供两种变体,分别提供闭式解权重或迭代优化权重。
核心贡献
- 本文引入了留一法 AUC(LOO-AUC)机制,这是一种正式的标准,通过衡量留出的测试的通过/失败模式与代码候选集的聚合排名之间的吻合程度,来识别具有信息量的测试。
- 本研究提出了 ACES(AUC ConsistEncy Scoring),该方法利用 LOO-AUC,仅通过二进制通过矩阵(pass matrix)根据测试区分正确代码与错误代码的能力来为测试分配权重。
- 研究提供了两种互补的变体:ACES-C 使用闭式解权重在平均测试质量下逼近 oracle;ACES-O 则对可微的 LOO-AUC 目标函数进行迭代优化,以应对更具挑战性的任务。
引言
为了提高代码生成的可靠性,研究人员通常使用测试时计算(test-time computation),通过基于执行的反馈从 LLM 生成的解决方案池中选择最佳候选者。然而,这里存在一个循环依赖问题,因为选择正确的代码需要可靠的测试,而确定一个测试是否可靠通常又需要知道哪些代码是正确的。现有方法通常将所有测试视为同等有效,或者依赖昂贵的启发式方法和强化学习来过滤不可靠的测试。作者通过提出 ACES(AUC Consistency Scoring)解决了这一问题,该方法仅基于测试对代码候选者的排名能力来识别具有信息量的测试。通过利用留一法 AUC(LOO-AUC)指标,作者可以在不需要 ground truth 标签的情况下,衡量一个测试区分不同代码候选者的能力,从而提供了一种基于判别力为测试分配权重的原则性方法。
数据集

作者利用三个主要的基准测试来评估和生成代码解决方案:HumanEval、HumanEval+ 和 MBPP。
- 数据集构成与来源:评估依赖于标准的编程数据集,具体包括 HumanEval、其增强版本 HumanEval+ 以及 MBPP。
- 提示策略:为了确保候选解决方案生成的一致性,作者实施了遵循 MPSC 协议的特定指令。提示词要求模型充当 Python 程序员,要求其根据提供的声明和 docstring 实现函数体,而不修改现有代码或提供额外的解释。
- 数据处理:生成过程使用结构化模板,将 docstring 注入到预定义的 Python 代码块中,以引导模型实现精确的代码。
方法
作者将代码排名建模为通过 pass matrix 进行的加权投票问题,其目标是为测试分配权重,使得生成的候选解决方案排名能够优化 Pass@k 等性能指标。该方法的核心在于利用测试的内部一致性,在没有外部监督的情况下估计其判别力。这是通过留一法 AUC(LOO-AUC)恒等式实现的,该恒等式在测试的观察一致性(即该测试与剩余测试诱导的排名之间的一致性)与其潜在判别力之间建立了直接联系。
该框架首先考虑一个编程问题,LLM 为其生成 n 个候选解决方案 C={c1,…,cn} 和 m 个测试用例 T={t1,…,tm}。执行结果形成一个二进制 pass matrix B∈{0,1}n×m,其中 Bij=1 表示代码 ci 通过了测试 tj。目标是根据得分 si(w)=∑j=1mwjBij 对这些代码进行排名,其中 w∈Δm 是测试的权重向量。作者表明,这种排名等同于一个加权投票问题,其中每个测试 tj 对正确代码 c+ 与错误代码 c− 进行投票 hj=Bc+,j−Bc−,j,而得分差异则是这些投票的加权和。
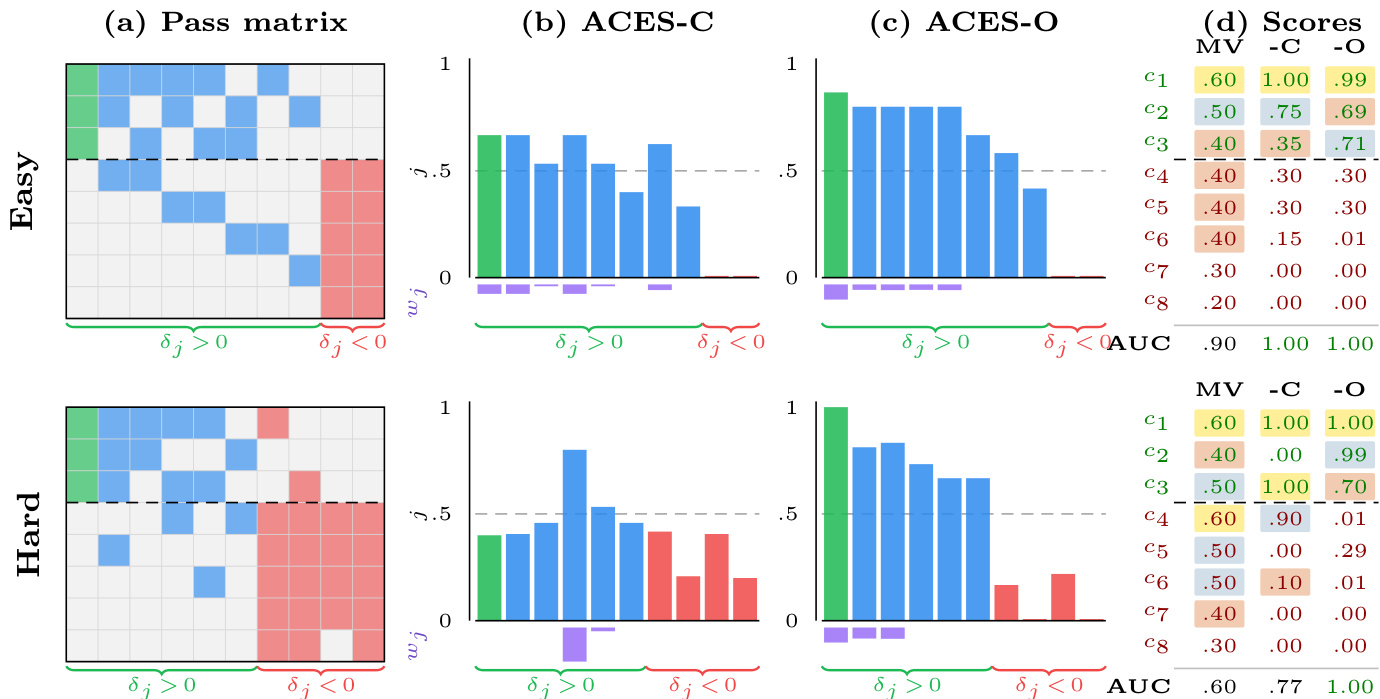
为了评估测试的质量,作者引入了 LOO-AUC 指标。对于测试 tj,LOO-AUC 衡量其通过/失败模式与所有其他测试得分产生的排名之间的吻合程度。其正式定义为 LOO−AUCj(w)=AUC(S(−j),B:,j),其中 S(−j) 是排除测试 tj 后计算出的得分向量,而 B:,j 是 tj 的通过/失败结果向量。LOO-AUC 恒等式(定理 3)证明,该指标的期望值减去 1/2,与测试的判别力 δj=αj−βj 成正比,其中 αj 和 βj 分别是正确代码和错误代码的条件通过率。该恒等式是 ACES 方法的理论基础。
ACES 框架包含两种互补的方法来估计这些测试权重。第一种是 ACES-C,这是一种闭式解、数据驱动的加权方案。它利用 LOO-AUC 恒等式为每个测试构建质量得分。在平均判别力为正且测试池足够大的假设下,作者表明留一法排名质量 A(−j)(wunif)−1/2 在所有测试中近似为常数。这使得他们能够推导出权重 wj=max(0,LOO−AUCj(wunif)−1/2)⋅pj(1−pj),其中 pj 是测试 tj 的经验通过率。这种公式有效地纠正了由通过率方差引入的偏差,确保与排名具有高一致性的测试被增加权重,而一致性较低的测试(误导性测试)权重被降至零。第二种方法 ACES-O 采用基于优化的方法。它直接最大化目标函数 J(w)=∑j=1mwj(LOO−AUCj(w)−1/2),旨在增加具有信息量的测试的贡献并减少误导性测试的贡献。该优化通过对不可微的 AUC 进行平滑逻辑代理(logistic surrogate)进行梯度上升来实现,权重通过 softmax 进行参数化以确保它们保持在单纯形 Δm 中。优化过程受益于正反馈循环,因为改进权重会增强留一法排名,进而改善 LOO-AUC 估计并进一步精炼权重。
实验
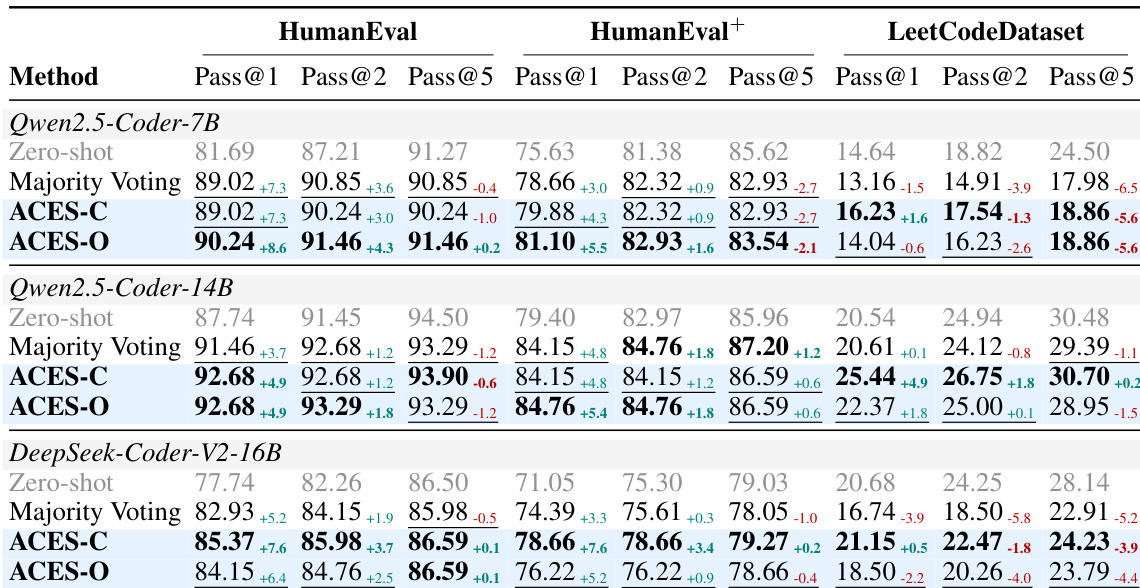
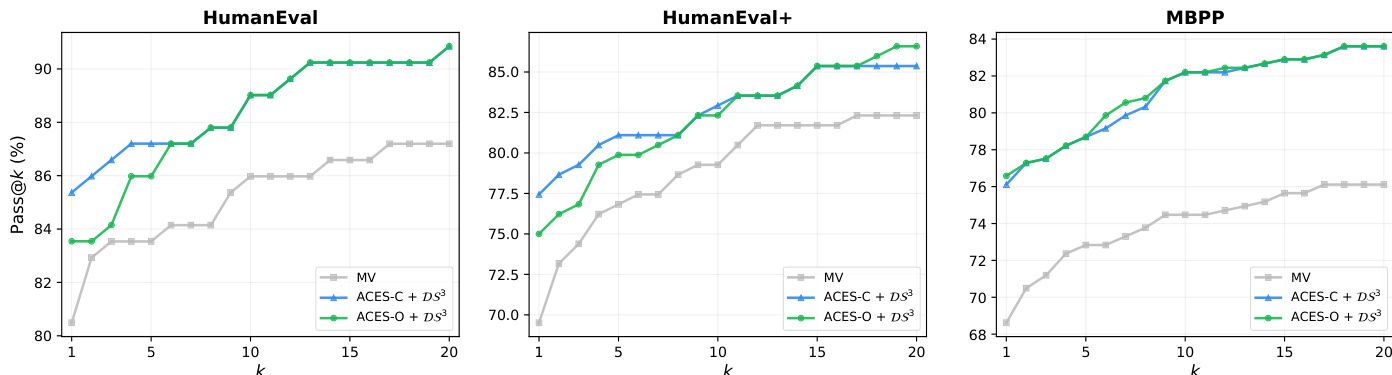
所提出的 ACES 方法在 HumanEval、HumanEval+ 和 MBPP 基准测试上进行了评估,以验证其仅使用二进制 pass matrix 区分具有信息量的测试与误导性测试的能力。结果表明,ACES-O 是一个卓越的独立重排序器(reranker),而 ACES-C 在与静态分析预过滤结合时表现出色。总体而言,实验证实,原则性的测试加权显著提高了排名质量,特别是在误导性测试普遍存在的挑战性场景中。
作者在代码生成基准测试上评估了 ACES-C 和 ACES-O,结果显示,仅使用二进制 pass matrix,两种方法都提高了 Pass@k 性能。ACES-O 在仅执行方法中取得了最佳结果,而 ACES-C 在与预过滤结合时表现优异,展示了互补的优势。在所有基准测试中,ACES-O 在仅执行方法中实现了最佳 Pass@k;当结合预过滤时,ACES-C 表现最好,甚至超过了使用额外静态信号的方法。这两个 ACES 变体表现出互补的优势,ACES-O 在低质量测试环境下表现出色,而 ACES-C 在高质量环境下表现出色。
作者分析了二进制 pass matrix 上的测试加权方法,展示了 ACES-C 和 ACES-O 如何通过识别具有信息量的测试来改进排名。在简单情况下,均匀加权就足够了,但在存在误导性测试的困难情况下,迭代优化对于实现完美排名至关重要。ACES-C 使用闭式解权重通过专注于信息量测试来改进排名;当误导性测试普遍存在时,ACES-O 通过迭代精炼权重来找回信息量测试。这两种方法具有互补优势:当假设成立时 ACES-C 表现出色,而当假设不成立时 ACES-O 更有效。
作者在三个代码生成基准测试上将 ACES 变体与基准方法进行了比较,结果显示 ACES-O 在仅执行方法中取得了最佳 Pass@k,而 ACES-C 在结合静态分析时表现良好。结果表明,两种方法都优于多数投票法(Majority Voting),且在误导性测试普遍存在时,ACES-O 提供了更大的增益。ACES-O 在所有基准测试中均优于所有仅执行方法;ACES-C 在结合静态分析时表现出色;两个 ACES 变体均优于多数投票法,尤其是在更难的基准测试上。
作者在代码生成基准测试上评估了 ACES-C 和 ACES-O,结果显示 ACES 变体在仅使用二进制 pass matrix 的情况下优于基准方法。ACES-C 优于多数投票法,而 ACES-O 在所有基准测试的仅执行方法中取得了最佳结果。ACES 变体通过仅使用 pass matrix 就超越了多数投票法和其他事后(post-hoc)方法。ACES-O 在所有基准测试的仅执行方法中达到了最佳性能。ACES-C 优于多数投票法,证明了基于 LOO-AUC 加权方法的价值。
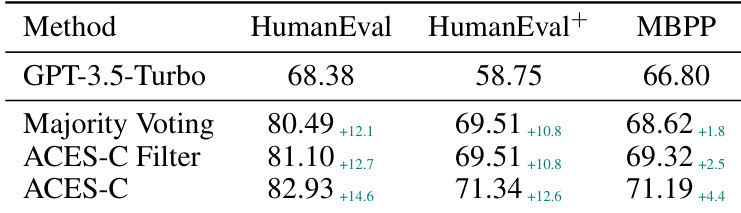
作者在代码生成基准测试上评估了 ACES 方法,结果显示 ACES-O 在所有基准测试的仅执行方法中取得了最佳 Pass@k。当与静态分析结合时,ACES 优于现有方法,其中 ACES-C 在测试质量假设得到良好满足的场景下表现更好。ACES-O 在所有基准测试中领先于所有仅执行方法,实现了最高的 Pass@1 得分。将 ACES 与静态分析结合可以提高所有基准测试的性能,其中当预过滤增强测试质量时,ACES-C 显示出更强的增益。ACES-C 和 ACES-O 表现出互补的优势:ACES-C 在数据有限时具有鲁棒性,而 ACES-O 则受益于更大的候选池和迭代精炼。
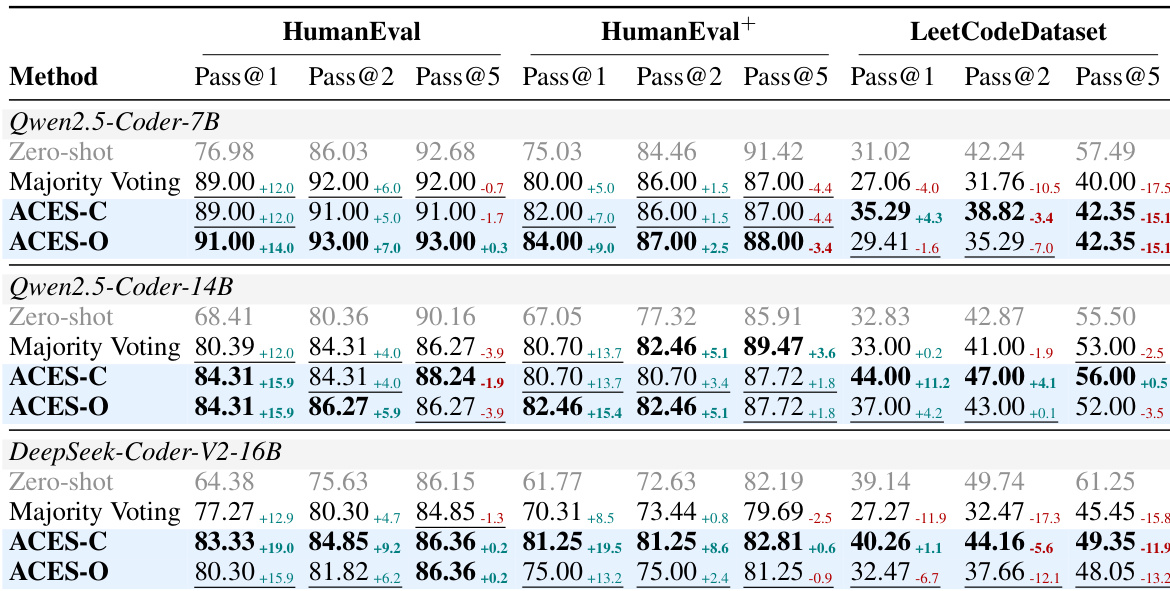
作者在各种代码生成基准测试上评估了 ACES-C 和 ACES-O 方法,以验证它们利用二进制 pass matrix 提高 Pass@k 性能的能力。实验表明,通过专门的加权方案识别出更多具有信息量的测试,两种变体都优于多数投票法和其他仅执行基准方法。虽然 ACES-O 通过迭代精炼在包含误导性测试的困难场景中表现出色,但 ACES-C 在结合静态分析或预过滤以增强测试质量时表现出更优越的性能。