Command Palette
Search for a command to run...
Vanast: 通过合成三元组监督实现基于人体图像动画的虚拟试穿
Vanast: 通过合成三元组监督实现基于人体图像动画的虚拟试穿
Hyunsoo Cha Wonjung Woo Byungjun Kim Hanbyul Joo
摘要
我们提出了 Vanast,这是一个统一的框架,能够直接从单张人物图像、服装图像以及姿态引导视频中生成完成服装转移(garment-transferred)的人物动画视频。传统的两阶段 pipeline 将基于图像的虚拟试穿(virtual try-on)与姿态驱动的动画生成视为两个独立的过程,这往往会导致身份漂移(identity drift)、服装变形以及前后不一致的问题。我们的模型通过在单个统一步骤中执行整个流程来实现连贯的合成,从而解决了这些问题。为了实现这一设定,我们构建了大规模的三元组监督(triplet supervision)数据。我们的数据生成 pipeline 包括:生成穿着与服装目录图像不同的、能够保持身份一致性(identity-preserving)的人物图像;获取完整的上下装三元组,以克服单一服装-姿态视频对的局限性;以及在无需服装目录图像的情况下,组装多样化的自然场景(in-the-wild)三元组。此外,我们为 video diffusion transformers 引入了一种双模块(Dual Module)架构,以稳定 training 过程,保留预训练的生成质量,并提升服装准确度、姿态遵循度(pose adherence)及身份保持能力,同时支持 zero-shot 服装插值(garment interpolation)。通过这些贡献,Vanast 能够在广泛的服装类型中生成高保真且身份一致的动画。
一句话总结
来自首尔大学的研究人员提出了 Vanast,这是一个统一的框架,通过大规模合成三元组监督和用于视频扩散 transformer 的 Dual Module 架构,能够通过单步生成换装人体动画视频,从而在多种服装类型中实现高保真、身份一致的合成。
核心贡献
- 本文引入了 Vanast,这是一个统一的框架,通过使用人体图像、服装图像和姿态引导视频,单步合成换装人体动画视频。该方法通过单一的统一步骤执行整个过程,避免了传统两阶段流水线中常见的身份漂移和服装变形问题。
- 通过专门的数据生成流水线构建了一个大规模三元组监督数据集,该流水线捕捉了保持身份的人体图像、完整的上下装三元组以及多样化的自然场景(in-the-wild)三元组。这些数据实现了保持身份的训练,并克服了现有单件服装姿态视频对的局限性。
- 该工作为视频扩散 transformer 提出了一种 Dual Module 架构,将姿态和服装调节(conditioning)分离到独立的模块中。这种设计在支持零样本(zero-shot)服装插值和无需微调的多服装转换的同时,提高了服装保真度、姿态遵循度和身份保持度。
引言
虚拟试穿技术对于数字时尚至关重要,然而现有的将基于图像的试穿与姿态驱动的动画分离的两阶段流水线,往往面临身份漂移、服装变形和时间不一致的问题。这些传统方法在从单张静态图像进行动画制作时,也难以处理前后几何结构。作者利用名为 Vanast 的统一单阶段框架,直接从人体图像、服装图像和姿态引导视频合成换装人体动画视频。为了支持这一点,他们引入了一个可扩展的三元组监督流水线,从自然场景视频和保持身份的合成图像中构建训练数据。此外,作者为视频扩散 transformer 提出了一种 Dual Module 架构,以稳定训练并提高服装准确性、姿态遵循度和身份保持度,同时实现零样本服装插值。
数据集

作者引入了一种合成三元组数据集生成流水线,以克服缺乏包含必要的人-衣-视频关系的公开数据的问题。
-
数据集组成与来源
- 训练集由 9,135 个视频组成,每个视频长度在 3 到 10 秒之间。
- 来源包括在线购物平台、用于多服装场景的定制采集工作室数据集,以及来自 ViViD 数据集的自然场景视频。
- 评估在两个不相交的集合上进行:一个互联网数据集(购物中心视频和服装图像)和 ViViD 测试集。
-
关键细节与处理子集
- 来自购物视频的合成三元组: 作者使用扩散修复模型 (FLUX) 来创建穿着不同服装的目标人物图像 (IG′)。这涉及通过视觉语言模型 (VLM) 根据面部清晰度、眼睛状态和图像质量选择代表性帧。
- 自然场景三元组: 为了增加多样性,作者直接从无约束视频中提取三元组。他们通过从高质量帧中分割服装并应用随机平移来生成服装图像 (G),以防止位置偏差。
- 多服装数据集: 使用专门的工作室采集数据集来支持涉及单人多件服装的场景。
-
处理与元数据构建
- 帧选择: 使用 VLM (Qwen2.5-VL) 根据正面姿态、无遮挡情况以及至少 95/100 的质量评分来过滤帧。
- 修复掩码生成: 为了确保真实的服装合成,作者避免遵循原始服装轮廓。相反,他们使用文本生成图像模型来合成一张带有不同服装的辅助图像,然后从该图像中提取掩码来引导修复过程。
- 提示词工程: ChatGPT 生成多样化的服装描述,而 VLM 通过在将描述纳入提示词之前对主体进行分类,以确保性别一致性。
- 自适应裁剪: 作者采用面部和身体检测模型进行自适应裁剪。他们在面部和身体边界框之间使用随机线性插值来生成各种尺度,最终得到 9:16 宽高比的裁剪结果。
方法
作者利用双模块架构实现了带有换装功能的人体单阶段动画,旨在高效处理多个调节输入。该框架命名为 Vanast,输入包括目标服装图像或一组服装 G、描绘穿着不同服装的人物参考图像 IG′、运动引导视频 K 以及文本提示 T。目标是生成一个时间相干的动画序列 V={ItG}t=1F,其中每一帧都合成穿着目标服装的人物。为了实现这一目标,该模型采用了源自骨干文本生成视频 DiT 模型的分布式级联结构,将处理过程划分为两个专门的模块:人体动画模块 (HAM) 和服装转换模块 (GTM)。这种设计解决了单上下文融合的局限性,因为单上下文融合可能会阻碍收敛并导致难以平衡多个调节条件。
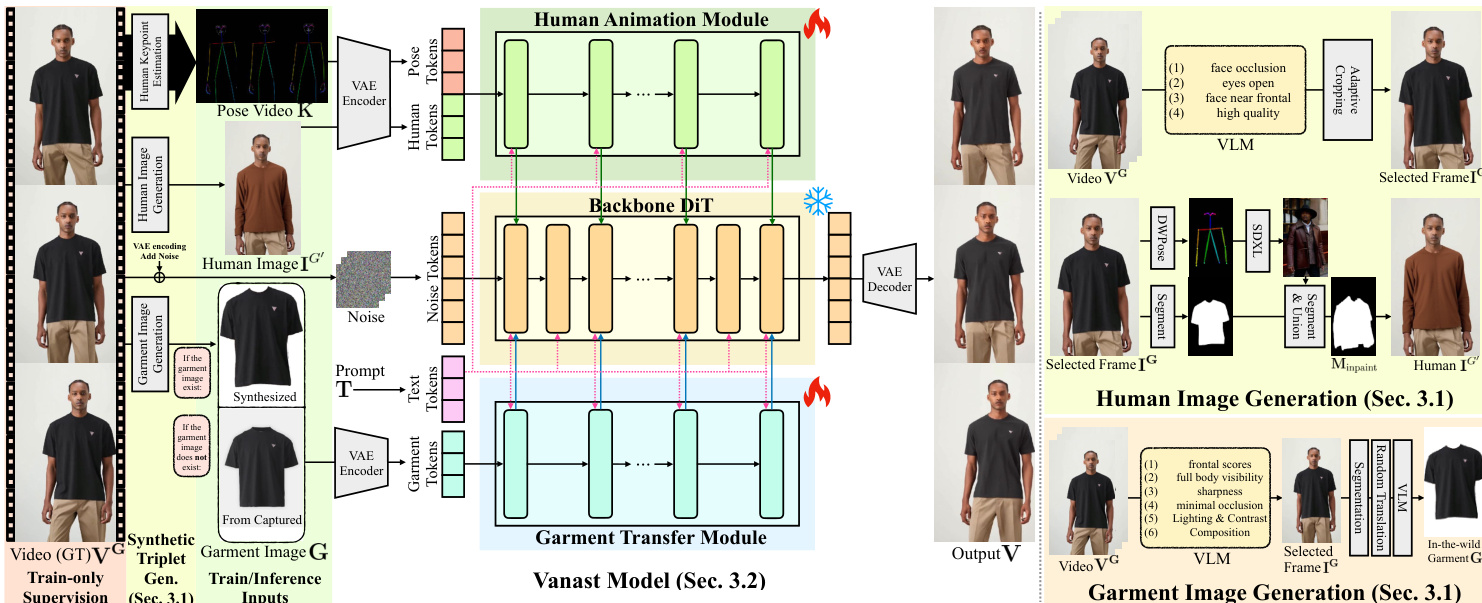
如下图所示,模型架构由一个共享的骨干 DiT 组成,HAM 和 GTM 模块集成在特定层。HAM 处理人体和姿态信息以生成动画,而 GTM 则专注于服装转换。两个模块都以级联方式集成到骨干网络中,其中每个 transformer 块的输出 hl 根据骨干块 BlT2V 以及来自 HAM 和 GTM 的贡献进行更新。集成定义如下方程:
hl+1={BlT2V(hl),BlT2V(hl)+α⋅BlHAM(hl)+β⋅BlGTM(hl),if l=2k,if l=2k.这里,l 是 transformer 块的索引,k 的范围从 0 到 14,h 代表隐藏状态。标量值 α=0.5 和 β=0.5 控制特征集成期间 HAM 和 GTM 模块的相对贡献。骨干 DiT 在训练期间是冻结的,仅对 HAM 和 GTM 模块进行优化,这减轻了计算负担并允许高效的微调。
输入调节通过 tokenization 处理。模型使用预训练的 VAE 编码器 EVAE 将输入组件转换为潜在表示。具体而言,zH、zG 和 zP 分别表示人体图像 IG′、服装图像 G 和运动视频 K 的编码潜在变量。对于 HAM 模块,通过沿时间维度拼接 zH 和 zP 来形成运动调节的外观上下文。对于 GTM 模块,直接使用服装潜在变量 zG;为了匹配 HAM 输入的时间维度,附加一个零张量作为占位符。这些拼接后的潜在体积随后使用 3D 卷积层投影为 token 嵌入。
该框架进一步支持零样本服装插值。给定来自同一类别的两种服装 GA 和 GB,模型可以通过在每个 transformer 块计算它们 GTM 输出的 γ 加权和来生成中间服装。该过程的集成方程为:
hl+1=BlT2V(hl)+α⋅BlHAM(hl)+γ⋅BlGTM(hl;GA)+(1−γ)⋅BlGTM(hl;GB),其中 γ∈[0,1] 控制插值比例。这使得在动画过程中能够在服装之间生成平滑且语义一致的过渡。整个框架在由参考人体图像、目标服装和地面真值(ground truth)动画视频组成的三元组数据集上进行训练,运动序列使用现成的 2D 关键点估计器提取。
实验
通过与涉及主体到图像(subject-to-image)和虚拟试穿基线的两阶段流水线进行对比,以及通过消融研究来验证其架构组件和合成数据集,对模型进行了评估。结果表明,与现有方法相比,所提出的方法实现了卓越的姿态遵循、服装转换准确度和身份保持度。此外,该模型在零样本应用中表现出强大的通用性,包括服装插值、同时进行多服装转换以及在自然场景图像上的鲁棒表现。
作者进行了消融研究,以评估不同模型组件和数据集配置的影响。结果显示,完整模型在所有指标上都优于所有变体,其中单模块基线无法控制姿态条件,而其他变体在准确的服装转换方面表现挣扎。与消融变体相比,完整模型在所有指标上均达到了最佳性能。单模块基线无法准确控制姿态条件。缺乏合成人体数据或骨干 LoRA 的变体在准确的服装转换方面表现不佳。

作者使用两个数据集将他们的方法与各种基线进行了比较,显示出在多个指标上的卓越性能。结果表明,在大多数情况下,他们的模型优于主体到图像与动画模型的各种组合,以及图像虚拟试穿与动画模型的组合。与基线组合相比,我们的模型在所有指标上都实现了最佳性能。在互联网数据集上,该模型在所有指标上均优于所有方法,并在 ViViD 数据集的大多数指标上表现优异。它在基于主体到图像和基于虚拟试穿的基线中都表现出强劲性能。
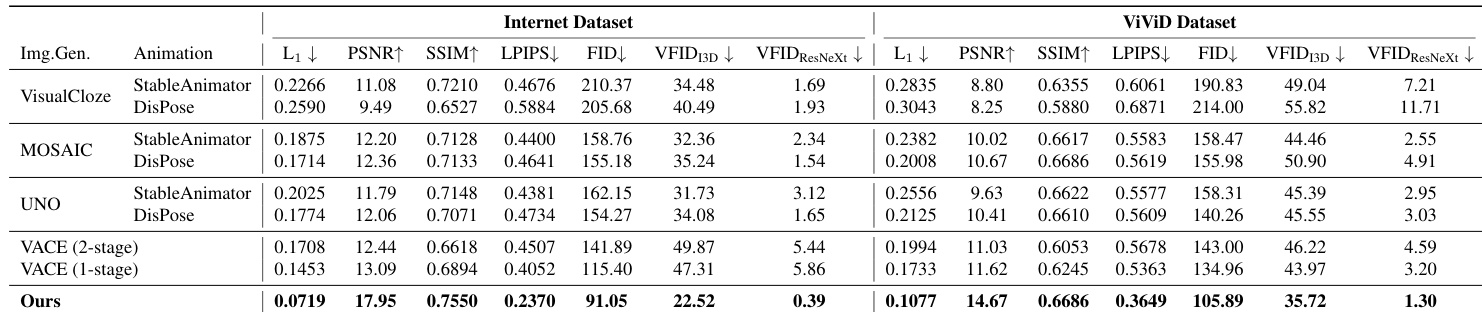
作者使用结合了图像生成和动画模型的两阶段流水线,将他们的方法与各种基线进行了比较。结果显示,在两个数据集上的多个指标中,他们的方法都优于所有基线,在大多数评估中实现了最佳性能。与基线组合相比,我们的方法在所有指标上都实现了最佳性能。该模型在互联网和 ViVid 数据集上均优于基线,并在关键领域实现了持续的改进。定性结果证实,与所有基线相比,该方法具有更优越的姿态遵循、服装转换和身份保持能力。
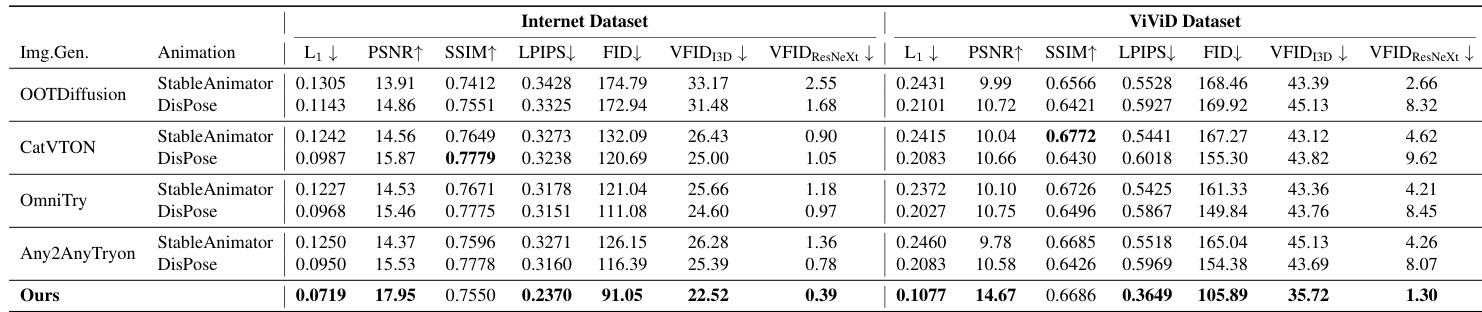
通过消融研究以及与各种基线组合的对比评估,作者验证了每个模型组件的必要性以及所提方法的整体有效性。结果表明,与单个模块或两阶段流水线相比,完整模型提供了对姿态条件的卓越控制和更准确的服装转换。最终,该方法在多个数据集上实现了高性能,在姿态遵循、服装转换和身份保持方面表现出显著改进。