Command Palette
Search for a command to run...
从 Agent Trajectories 中学习检索
从 Agent Trajectories 中学习检索
Yuqi Zhou Sunhao Dai Changle Qu Liang Pang Jun Xu Ji-Rong Wen
摘要
传统的的信息检索(Information Retrieval, IR)系统主要针对人类用户进行设计与训练,其学习排序(learning-to-rank)方法高度依赖于大规模的人类交互日志,例如点击率(clicks)和停留时间(dwell time)。然而,随着由大语言模型(LLM)驱动的搜索 Agent 的快速涌现,检索任务正日益由 Agent 而非人类用户完成,并作为核心组件嵌入到多轮推理与行动循环(reasoning and action loops)之中。在这种背景下,基于“以人为中心”假设训练的检索模型,在 Agent 发起查询(queries)及消费结果的方式上,表现出根本性的不匹配。在本研究中,我们认为面向 Agent 搜索的检索模型应当直接从 Agent 的交互数据中进行训练。我们提出了一种全新的训练范式——“从 Agent 轨迹中学习检索”(learning to retrieve from agent trajectories),其监督信号来源于多步 Agent 交互过程。通过对搜索 Agent 轨迹的系统性分析,我们识别出了能够揭示文档效用(document utility)的关键行为信号,包括浏览行为(browsing actions)、未浏览拒绝(unbrowsed rejections)以及浏览后的推理轨迹(post-browse reasoning traces)。基于这些洞察,我们提出了 LRAT,这是一个简单且有效的框架,能够从 Agent 轨迹中挖掘高质量的检索监督信号,并通过加权优化(weighted optimization)引入相关性强度(relevance intensity)。在领域内(in-domain)和领域外(out-of-domain)深度研究 benchmark 上的广泛实验表明,使用 LRAT 训练的检索器在不同的 Agent 架构与规模下,都能持续提升证据召回率(evidence recall)、端到端任务成功率以及执行效率。我们的研究结果强调了 Agent 轨迹是一种实用且可扩展的监督来源,为 Agent 搜索时代的检索技术指明了一个充满前景的方向。
一句话总结
为了解决以人为中心的检索训练与 agentic search 之间的不匹配问题,来自中国人民大学和中国科学院的研究人员提出了 LRAT。该框架通过从多步 agent 轨迹中挖掘高质量监督信号(具体利用浏览动作、未浏览拒绝以及浏览后的推理轨迹)来优化检索模型,从而提高不同 agent 架构和规模下的证据召回率、任务成功率和执行效率。
核心贡献
- 本研究形式化了一种名为“从 agent 轨迹中学习检索”的新训练范式,该范式直接从多步 agent 交互中获取监督信号,使检索模型与 agentic search 行为保持一致。
- 本文引入了 LRAT 框架,该框架通过利用浏览动作、未浏览拒绝和浏览后的推理轨迹从 agent 轨迹中挖掘高质量监督信号,并通过加权优化来纳入相关性强度。
- 在域内和域外深度研究基准测试上的广泛实验表明,使用 LRAT 训练的检索器在各种 agent 架构和规模下均提高了证据召回率、端到端任务成功率和执行效率。
引言
随着搜索引擎从服务人类用户转向支持由 LLM 驱动的 agent,检索已成为多轮推理和动作循环中的关键瓶颈。传统的检索模型是在以人为中心的数据(如点击率和停留时间)上训练的,这造成了根本性的不匹配,因为 agent 的查询旨在推进中间推理目标,而不是满足即时的信息需求。作者利用 agent 交互轨迹来弥补这一差距,提出了一种名为“从 Agent 轨迹中学习检索”(Learning to Retrieve from Agent Trajectories, LRAT)的新训练范式。通过从浏览动作、未浏览拒绝和浏览后的推理轨迹中挖掘高质量监督信号,LRAT 框架使检索目标与 agent 行为对齐,从而提高证据召回率和任务成功率。
数据集
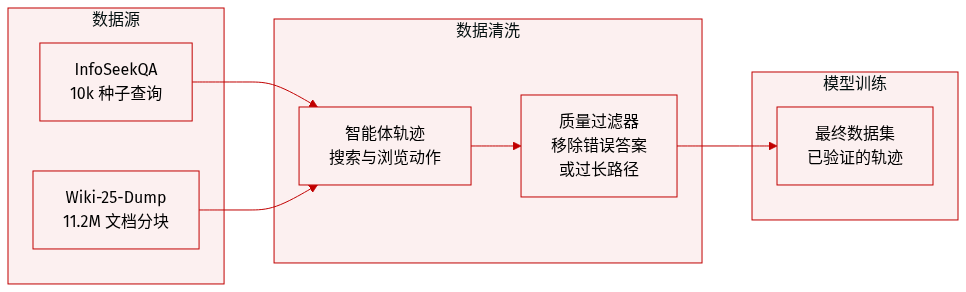
作者通过基于以下组件的轨迹生成过程构建了数据集:
- 数据集组成与来源: 作者使用 InfoSeekQA 作为种子数据的基础。该基准测试包含超过 50,000 个问答对,专为分层推理和迭代信息获取而设计。对于底层知识语料库,他们使用了包含超过 1120 万个文档块的 Wiki-25-Dump。
- 子集详情与过滤: 从原始 InfoSeekQA 集中,作者选择了一个包含 10,000 个具有验证真值答案的查询种子子集。Wiki 语料库中的每个文档块都被截断为 512 tokens 的固定长度。
- 数据处理与轨迹生成: 作者通过在每个种子查询上执行 search agent 来生成 agent 轨迹。agent 执行迭代推理并执行 [Search] 或 [Browse] 动作。为了确保数据质量,他们过滤掉了任何超过最大步数限制或导致最终答案错误的轨迹。
- 验证与元数据: 通过使用 Qwen3-30B-A3B-Thinking-2507 模型将 agent 的输出与真值进行比较,来验证答案的正确性。最终生成的轨迹作为其分析的主要数据。
方法
作者利用深度研究 agent 框架,通过迭代推理和动作循环来建模复杂的信息寻求任务。该框架如下图所示,遵循 ReAct 风格的交互模式,其中 agent 根据其内部推理状态在思考和行动之间交替进行。在每一轮 t 中,agent 生成一个推理状态 rt,该状态综合了先前的证据并识别缺失的信息。然后,它从集合 A 中选择一个动作 at,该动作可以是 [Search] 动作(即制定一个中间查询 qt 以检索文档排序列表 Dt),也可以是 [Browse] 动作(即选择之前检索到的文档 dt 以获取完整内容)。agent 在搜索时接收结果的片段列表,在浏览时接收完整的文档内容,并使用这些观测值 ot 来更新其推理状态。此过程持续进行,直到 agent 确定已收集到足够的信息以合成最终答案 y。轨迹被结构化为一系列推理-动作-观测三元组 T={(rt,at,ot)}t=1T,捕捉了 agent 不断演变的逻辑状态以及与检索环境的交互。

该框架结合了多个检索模型来模拟多样化的检索行为,包括稀疏的 BM25 检索器和三个规模递增的稠密检索器:Qwen3-Embedding-0.6B、4B 和 8B。在轨迹生成期间,每个搜索动作返回前 10 个候选文档,且 agent 每次仅观察每个文档 64 tokens 的短片段,这模拟了现实世界的搜索环境,即初始评估依赖于粗粒度的信号。这种设置能够从 agent 交互中提取真实的语义相关性信号,随后通过 LRAT 框架用于训练检索模型。
如下图所示,LRAT 框架由三个主要阶段组成:朴素相关性挖掘、推理感知正样本过滤和强度感知训练。首先,通过识别 [Search] → [Browse] 的转换从 agent 轨迹中挖掘相关性信号。对于每一次此类转换,被浏览的文档 dt+1 被视为朴素正样本,而检索集 Dt 中的所有其他文档都被视为朴素负样本。这产生了形式为 (qt,dt+1,Nt) 的初始训练实例,其中 Nt=Dt∖{dt+1}。
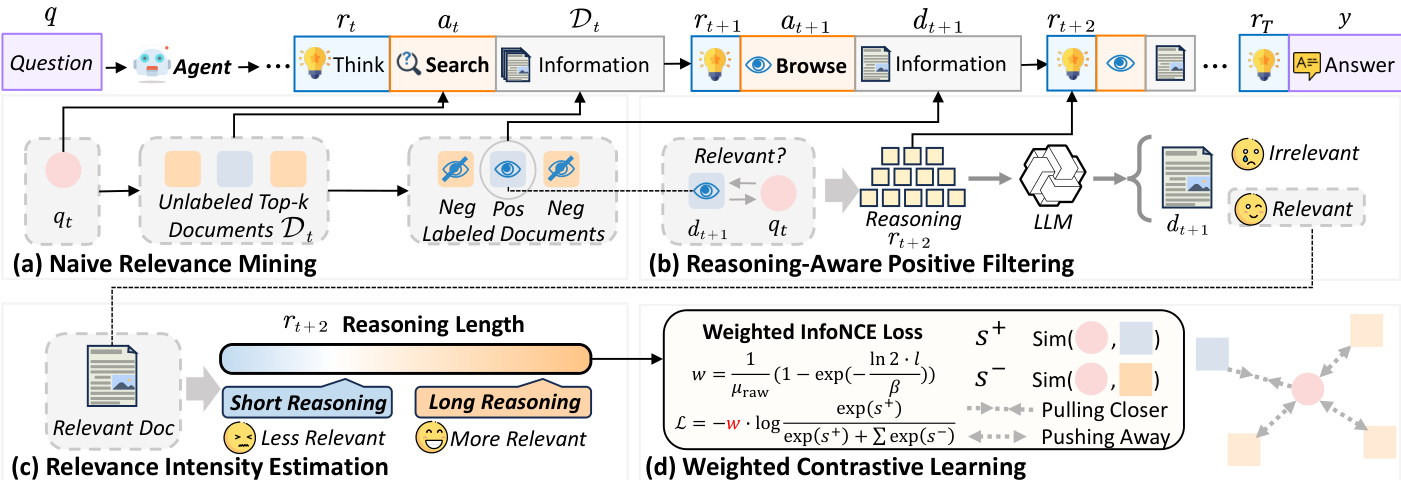
为了细化这些粗糙的标签,应用了推理感知过滤步骤。对于每个被浏览的文档 dt+1,使用基于 LLM 的验证器分析 agent 紧随其后的浏览后推理轨迹 rt+2,以确定文档内容是否被明确用于支持任务进展。不具有明确相关性的文档会被过滤掉,从而在保留高质量正样本的同时减少正样本集中的噪声。这种过滤利用了一个洞察:浏览后的推理轨迹可以作为文档效用的可靠指标。
最后,框架通过估计每个文档对任务进展的贡献,将相关性强度纳入训练。如图所示,相关性强度源自浏览动作后的推理轨迹长度,这与文档的有用程度相关。作者受到时间感知点击模型(time-aware click models)的启发,使用指数饱和函数将此建模为一个连续的效用分数。相关性强度权重 w 计算如下:
w=μraw1(1−exp(−βln2⋅l)),其中 l 是推理轨迹的 token 长度,β 是轨迹间的推理长度中位数,μraw 是未归一化分数的全局平均值。这种加权方案确保了在训练过程中,触发更长推理链的文档会被分配更高的重要性。
该框架使用加权的 InfoNCE 损失来优化稠密检索器,其中相关性强度 w 用于调节损失。正样本对 (qt,dt+1) 以权重 w 在嵌入空间中被拉近,而负样本对 (qt,dt′) 则以权重 1 被推开。这种强度感知训练确保了检索器能够优先考虑那些不仅相关而且对 agent 推理过程有显著贡献的文档。
实验
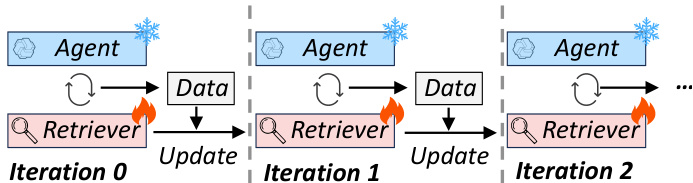
研究人员通过分析深度研究 agent 轨迹来评估 LRAT 框架,以确定浏览行为和浏览后推理如何指示文档效用。通过在域内和域外基准测试上针对多种检索器和 agent 主干进行的实验,他们证明了引入推理感知监督可以显著提高证据召回率、任务成功率和执行效率。研究结果进一步表明,该框架可以随着更多数据的增加而有效扩展,并且可以通过利用正确的和错误的 agent 轨迹来维持持续的数据飞轮。
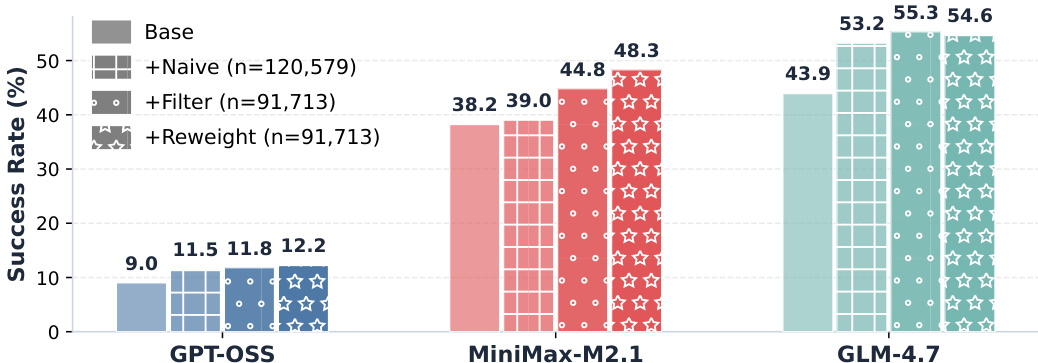
作者比较了使用基础检索器和使用 LRAT 训练的检索器时不同 agent 的性能,训练时均使用了正确和错误的轨迹。结果显示,LRAT 在所有 agent 中一致地提高了成功率,其中在正确轨迹上训练时观察到最高的增益。与基础检索器相比,LRAT 提高了所有 agent 的成功率。使用正确轨迹训练比使用错误轨迹产生更高的成功率。这种改进在不同的 agent 主干(包括 GPT-OSS、MiniMax-M2.1 和 GLM-4.7)上是一致的。
柱状图比较了使用各种检索器配置时不同 agent 的成功率。结果显示,所提出的方法一致地提高了所有 agent 的成功率,在较大的模型中观察到最显著的增益。这些改进归功于增强的检索质量和更高效的 agent 执行。所提出的方法一致地提高了所有 agent 的成功率。与较小的模型相比,较大的模型表现出更显著的性能增益。这些改进归功于更好的检索质量和更高效的 agent 执行。
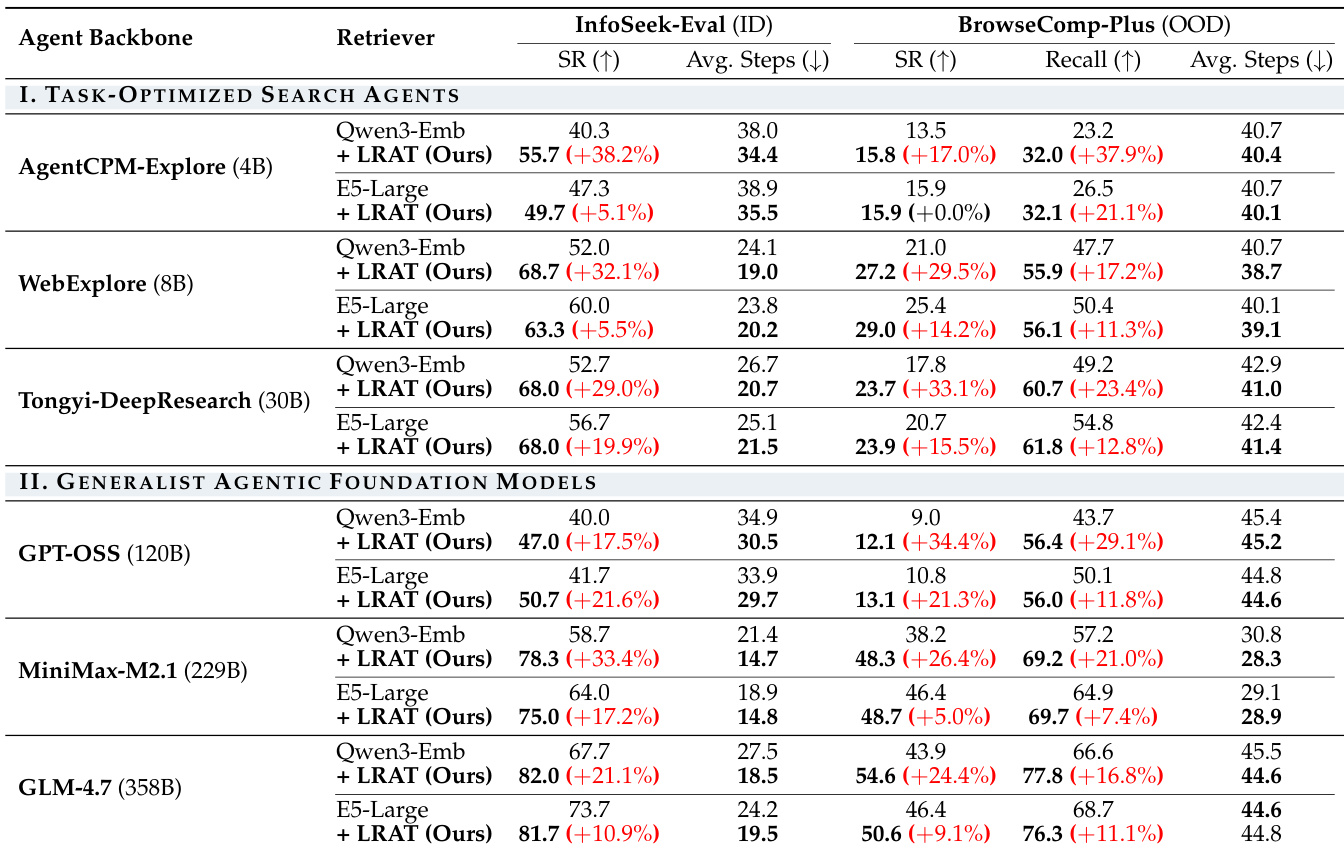
作者在多个搜索 agent 和检索器上,针对域内和域外基准测试评估了 LRAT 框架。结果显示,与基线模型相比,使用 LRAT 训练的检索器在任务成功率、检索质量和执行效率方面均有持续改进。在域内和域外基准测试上,LRAT 提高了所有 agent 和检索器组合的任务成功率和证据召回率。使用 LRAT 训练检索器的 agent 需要更少的交互步数来完成任务,表明信息获取更加高效。这些改进在从小型任务优化型 agent 到大型通用型模型的各种 agent 架构和规模上都是一致的。
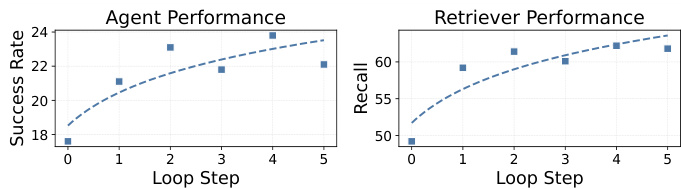
图表显示,随着循环步数的增加,agent 和检索器的性能均有所提高。成功率和召回率指标显示出持续的上升趋势,表明更多的交互步数会带来更好的任务结果。随着循环步数增加,agent 成功率上升,检索器召回率随循环步数增加而提高,性能趋势在迭代中显示出稳定增长。
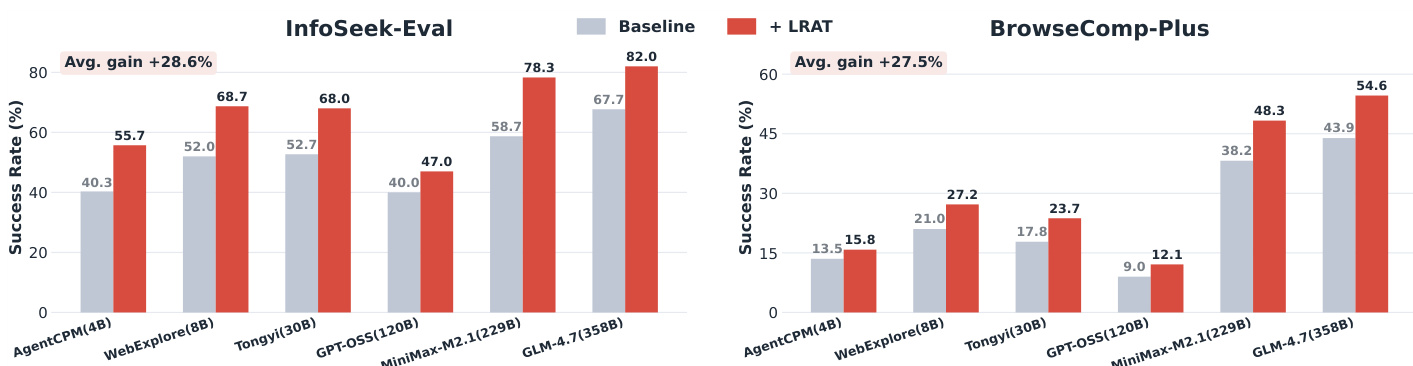
作者在两个基准测试上评估了 LRAT 框架,显示出在不同 agent 和检索器组合中成功率的一致提升。结果表明,LRAT 增强了检索质量并实现了更高效的 agent 执行,在域内和域外设置中均观察到了增益。LRAT 在两个基准测试的所有评估 agent 和检索器中一致地提高了成功率。与 BrowseComp-Plus 相比,在 InfoSeek-Eval 基准测试上的改进更为显著。LRAT 减少了解决任务所需的平均交互步数,表明 agent 执行更加高效。
作者通过在域内和域外基准测试中比较各种 agent 主干和检索器配置,评估了 LRAT 框架。结果表明,LRAT 一致地增强了任务成功率、检索质量和执行效率,其中在正确轨迹上训练并利用较大的模型时观察到最显著的增益。此外,该框架通过减少完成任务所需的交互步数,实现了更高效的信息获取。