Command Palette
Search for a command to run...
Video-MME-v2:迈向全面视频理解 Benchmark 的下一阶段
Video-MME-v2:迈向全面视频理解 Benchmark 的下一阶段
摘要
随着视频理解技术的飞速发展,现有的 benchmark 正逐渐趋于饱和,这暴露出排行榜上的虚高分数与模型实际能力之间存在严重脱节。为了弥补这一日益扩大的差距,我们推出了 Video-MME-v2,这是一个旨在严苛评估视频理解鲁棒性(robustness)与忠实度(faithfulness)的全面 benchmark。为了系统性地评估模型能力,我们设计了一个渐进式的三级层级体系,逐步提升视频理解的复杂度:从多点视觉信息聚合(multi-point visual information aggregation),到时序动态建模(temporal dynamics modeling),最终上升到复杂的模态间推理(complex multimodal reasoning)。此外,不同于传统的单题准确率评估,我们提出了一种基于分组的非线性评估策略,旨在强制要求相关查询之间的一致性以及多步推理的连贯性。该策略会惩罚碎片化或基于猜测的正确回答,仅对有有效推理支撑的答案给予评分。为确保数据质量,Video-MME-v2 通过严格控制的人工标注 pipeline 构建而成,参与人员包括 12 名标注员和 50 名独立审核员。在投入 3,300 个工时并经过多达 5 轮质量保证流程后,Video-MME-v2 旨在成为最具权威性的视频 benchmark 之一。广泛的实验表明,当前表现最佳的模型 Gemini-1.5-Pro 与人类专家之间仍存在巨大差距,并揭示了一个清晰的层级瓶颈问题:视觉信息聚合与时序建模阶段的错误会不断传递,从而限制了高层级的推理能力。我们进一步发现,基于思考(thinking-based)的推理高度依赖于文本线索,在有字幕辅助时性能会有所提升,但在纯视觉环境下性能有时反而会下降。通过揭示这些局限性,Video-MME-v2 为下一代视频 MLLM 的开发建立了一个极具挑战性的新测试场。
一句话总结
为了应对现有视频理解评估趋于饱和的问题,Video-MME 团队推出了 Video-MME-v2。这是一个全面的基准测试,它利用了任务复杂度不断增加的渐进式三级层级结构,以及一种新颖的基于分组的非线性评估策略,旨在严格评估模型的鲁棒性、忠实度(faithfulness)和推理一致性。
核心贡献
- 本文引入了 Video-MME-v2,这是一个旨在通过渐进式三级层级结构来评估视频多模态大语言模型鲁棒性和忠实度的全面基准测试。该层级结构将任务复杂度从多点视觉信息聚合逐步提升到时序动态建模和复杂的多模态推理。
- 开发了一种基于分组的非线性评估策略,通过强制要求相关查询之间的一致性和多步推理的连贯性来评估模型性能。该方法通过仅向由有效推理支持的答案授予分数,来惩罚碎片化或基于猜测的正确性。
- 该基准测试的特点是拥有高质量的数据集,该数据集通过严格的人工标注流程构建,涉及 12 名标注员和 50 名独立评审员。广泛的实验证明了该基准测试的挑战性,并验证了新评估和评分策略的有效性。
引言
随着视频多模态大语言模型(MLLMs)的发展,现有的基准测试正变得日益饱和,导致排行榜上的高分与实际现实世界的表现之间存在差异。目前的评估方法通常侧重于特定领域或基础任务,未能深入研究感知与复杂推理之间的关系。为了解决这些局限性,作者引入了 Video-MME-v2,这是一个旨在评估视频理解的鲁棒性和忠实性的严格基准测试。作者利用了从视觉信息聚合扩展到复杂多模态推理的渐进式三级层级结构,并结合了一种新颖的基于分组的非线性评估策略,该策略会惩罚不一致或基于猜测的答案。
数据集
作者引入了 Video-MME-v2,这是一个旨在评估渐进式推理能力的全面视频理解基准测试。数据集详情如下:
-
数据集组成与来源
- 数据集由来自互联网的 800 个视频组成。
- 内容分为四个顶级领域:体育与竞赛、生活方式与娱乐、艺术与文学、知识与教育。
- 这些领域进一步细分为 31 个细粒度子类别,例如烹饪、旅行、电影、物理学和计算机科学。
- 视频具有多样化的长度分布,平均时长为 10.4 分钟,其中 99% 的视频时长在 20 分钟以内。
-
关键细节与过滤规则
- 面向时效性的策划: 为了防止模型预训练导致的数据泄露,作者优先考虑了新发布的内容。超过 80% 的视频发布于 2025 年或更晚,近 40% 的视频发布于 2025 年 10 月之后。
- 质量控制: 作者使用观看次数作为质量的代理指标,过滤掉了低曝光的内容。具体而言,84.3% 的视频观看次数超过 10,000 次,94.4% 的视频观看次数超过 1,000 次。
- 人工去污染: 团队手动筛选并排除了经典电影、电视作品和头部网红内容,以确保基准测试测试的是真正的推理能力而非记忆检索。
-
层级化能力结构
- 作者将问题组织为三个渐进的层级:
- Level 1(视觉信息聚合): 侧重于视觉识别、跨模态一致性(视听对齐)和基础计数。
- Level 2(时序动态): 评估动作与运动分析、序列排序和因果推理。
- Level 3(复杂推理): 评估涉及多跳推理的叙事理解、社会动态和物理世界推理。
- 作者将问题组织为三个渐进的层级:
-
标注与处理细节
- 问题设计: 每个视频配有 4 个问题,每个问题提供 8 个多选题选项(A 到 H),将随机猜测的概率降低到 12.5%。
- 推理连贯性: 作者实施了基于分组的构建方式,问题和答案的平均长度从 Q1 到 Q4 逐渐增加,从而创建了逻辑链,要求后续问题具有更高的深度。
- 对抗性干扰项: 每个问题至少包含一个对抗性干扰项,该干扰项基于部分线索看起来很合理,但基于细粒度细节则是错误的。
- 质量保证流程: 数据经过了 3,300 个工时的人工处理,涉及 12 名标注员和 50 名评审员。该过程包括使用前沿模型(如 Gemini-3-Pro)进行仅文本基准测试,以确保在没有视觉信息的情况下无法解决问题,以及多轮交叉验证和独立的盲测。
方法
作者引入了一个评估视频理解模型的结构化框架,通过两种截然不同的分组问题类型:基于一致性的分组和基于连贯性的分组,来强调一致性和连贯性。这种方法旨在通过超越孤立的问题准确率,转而评估推理的可靠性和逻辑递进,从而提供对模型能力的更全面评估。
该框架组织为三个层级:Level 1(检索与聚合)、Level 2(时序理解)和 Level 3(复杂推理)。这些层级代表了所需认知和感知技能复杂度的不断增加。在此结构中,基于一致性的分组旨在评估模型在相关问题中保持可靠且连贯理解的能力。这是通过从两个维度构建问题组来实现的:广度和粒度。广度涉及在单个领域内包含多样化的问题类型,以捕捉不同的推理方面,例如在空间理解领域结合物体定位和相对运动推理。粒度则将单一问题类型扩展到多个时空尺度,例如在健身教程中,既评估动作的全局序列,又评估单个动作内子动作的细粒度排序。通过整合这些维度,基于一致性的分组能够对模型在特定领域内的能力进行系统的、多粒度的评估。
基于连贯性的分组专门设计用于评估复杂视频推理任务中推理过程的质量。与以往仅评估最终答案的基准测试不同,这种方法强调中间推理步骤,以确定模型是真正执行了多步推理,还是仅仅正确地进行了猜测。每个基于连贯性的分组中的问题集被构建为模拟人类在解决复杂问题时所遵循的逻辑进展。例如,在一个涉及伪装死亡的情节分析任务中,评估过程通过一系列步骤进行:识别直接的视觉线索、检测异常细节、推断欺骗的目的,并根据证据得出最终结论。这种层级化验证过程确保了模型的推理是基于视频内容的,并允许对其真实的推理能力进行更严格且可解释的评估。
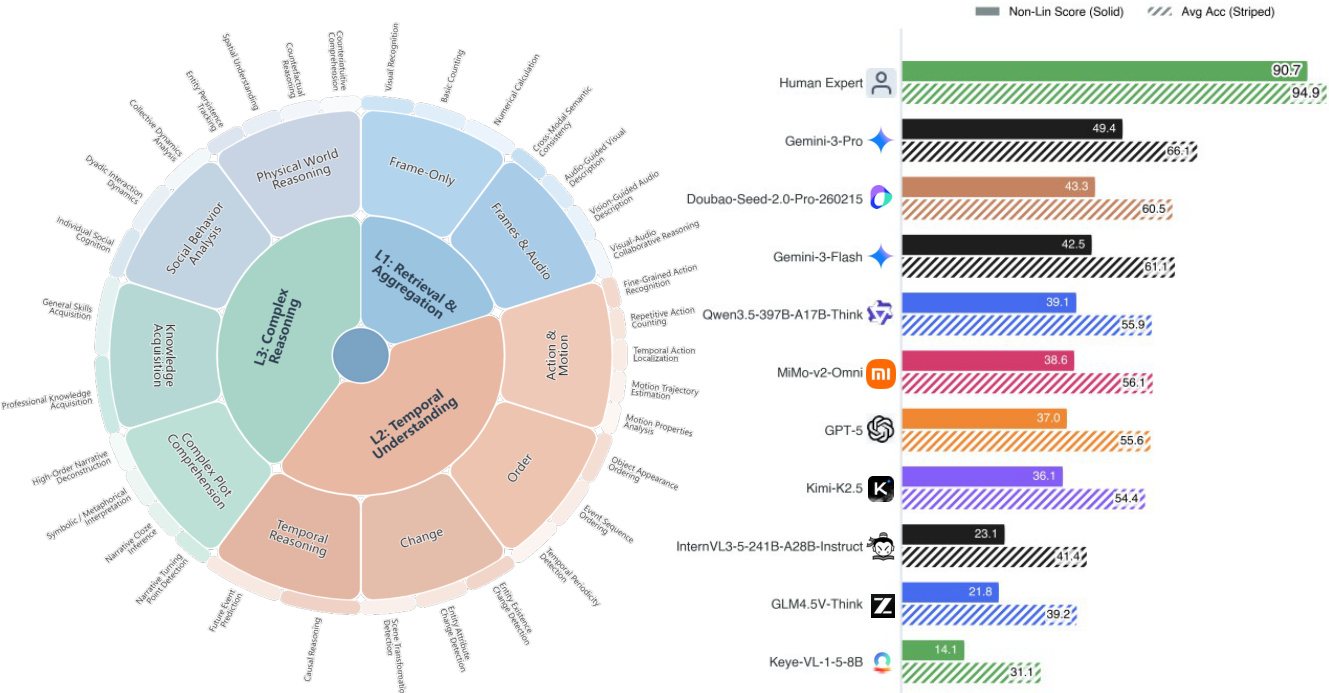
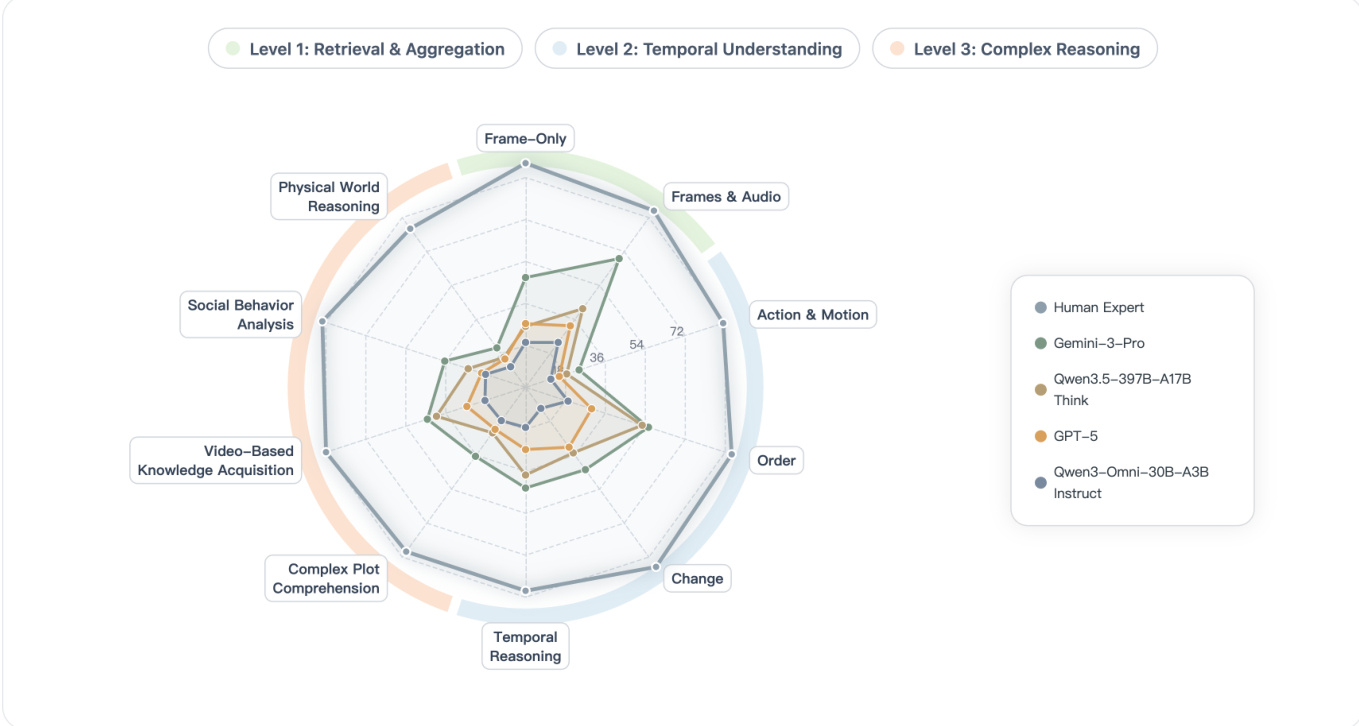
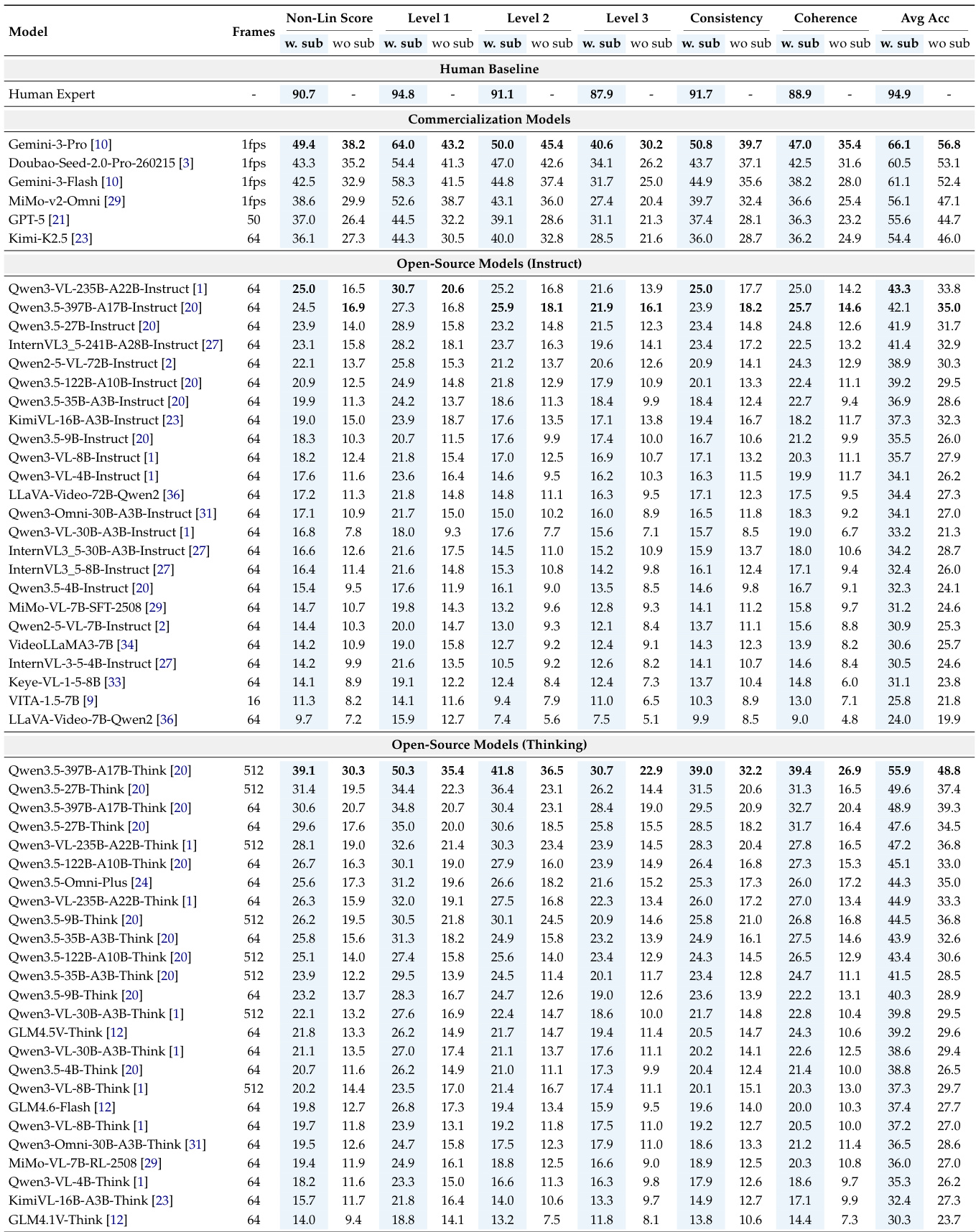
实验
Video-MME-v2 基准测试通过多级层级结构和基于分组的评估策略来评估视频多模态大语言模型的鲁棒性和忠实度。通过使用非线性评分机制评估能力一致性和推理连贯性,实验揭示了当前前沿模型与人类专家之间显著的性能差距。研究结果表明存在层级瓶颈,即高层推理的失败通常是由基础感知和时序建模中的错误驱动的,同时当前模型也表现出对语言先验和辅助文本线索的严重依赖。
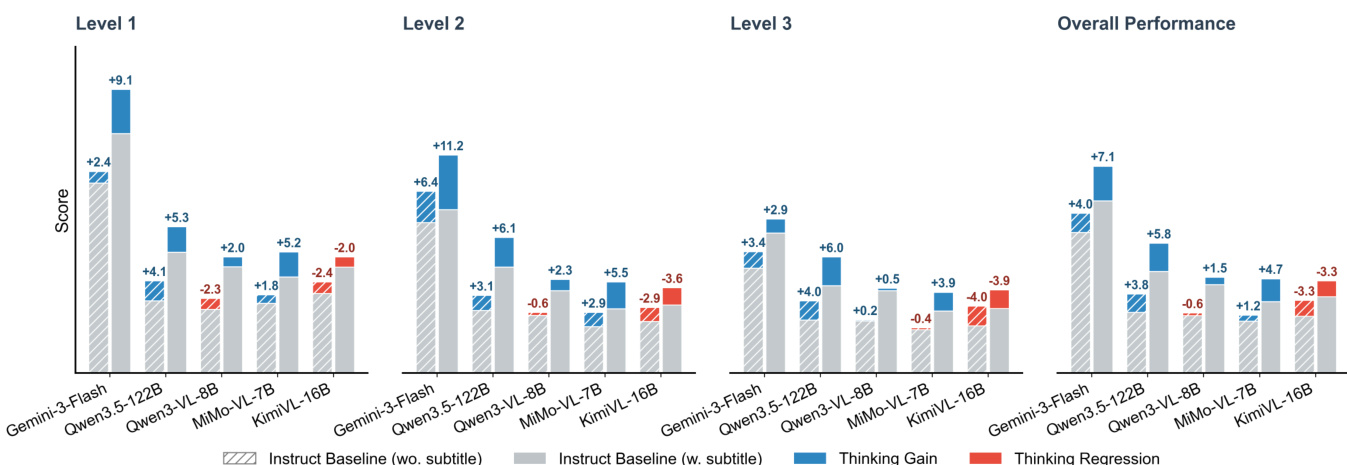
作者使用一个全面的基准测试评估了一系列视频多模态大语言模型,该基准测试包括多个层级的视频理解和基于分组的评分,以评估能力一致性和推理连贯性。结果显示,人类专家与表现最好的模型之间存在显著的性能差距,商业模型优于开源模型,尤其是在可以使用辅助文本或音频的情况下。评估表明,当前模型在相关问题之间难以保持一致的性能,并且更加依赖文本线索,这表明需要提高鲁棒性和集成的多模态感知能力。商业模型比开源模型获得更高的性能,尤其是在使用字幕或音频时。人类表现与模型表现之间存在显著差距,突显了提高鲁棒性和推理连贯性的必要性。启用思考模式可以提高带有字幕时的性能,但在没有字幕时可能会导致性能退化,这表明了对语言先验的过度依赖。
作者在从基础信息聚合到复杂推理的三个渐进理解层级上评估了视频 MLLMs。结果显示,性能从 Level 1 到 Level 3 持续下降,即使是最好的模型仍然显著落后于人类表现。分析表明,低层级任务中的错误会传播到高层级,表明当前模型中存在层级瓶颈。所有模型的性能从 Level 1 到 Level 3 单调下降,表明视频理解中存在层级瓶颈。表现最好的模型得分显著低于人类专家,突显了在鲁棒和忠实理解方面的巨大差距。启用推理模式可以提高带有字幕时的性能,但在没有字幕时可能会导致退化,这表明了对文本线索的过度依赖。
结果显示人类表现与当前模型之间存在显著差距,最好的模型获得的非线性得分为 49.4,而人类基准为 90.7。评估强调,依赖文本线索的模型表现更好,但当这些线索被移除时,它们的一致性会急剧下降,表明其对基于语言的推理存在依赖。表现最好的模型获得的非线性得分为 49.4,显著低于人类基准 90.7,揭示了巨大的性能差距。模型在没有字幕的情况下表现大幅下降,表明推理对文本线索有很强的依赖性。非线性得分大幅低于平均准确率,表明模型往往无法在同一组内一致地回答相关问题。
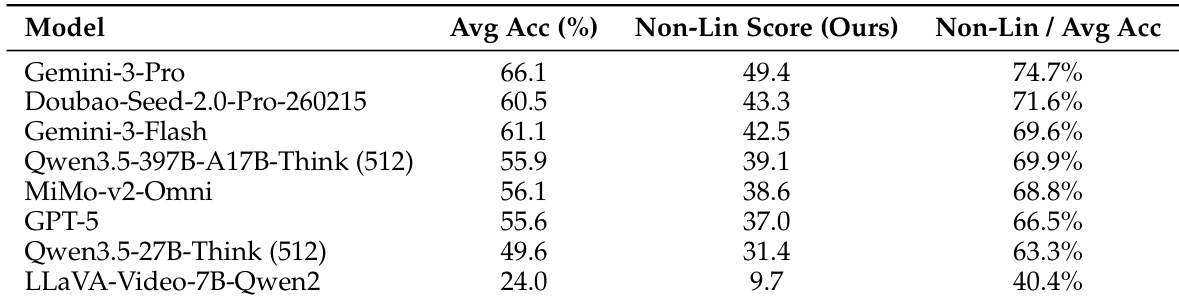
作者使用一个全面的基准测试评估了最先进的视频 MLLMs,该基准测试通过非线性评分方法评估能力一致性和推理连贯性。结果表明,虽然像 Gemini-3-Pro 这样的商业模型表现最好,但所有模型与人类专家相比都存在显著差距,其性能受到核心能力与模型规模组合的强烈影响。商业模型优于开源模型,尤其是在缺乏文本线索的情况下。性能与全模态聚合和长上下文建模等核心能力的存在相关。较大的模型可以部分补偿缺失的能力,但完整的能力配置仍然具有优势。
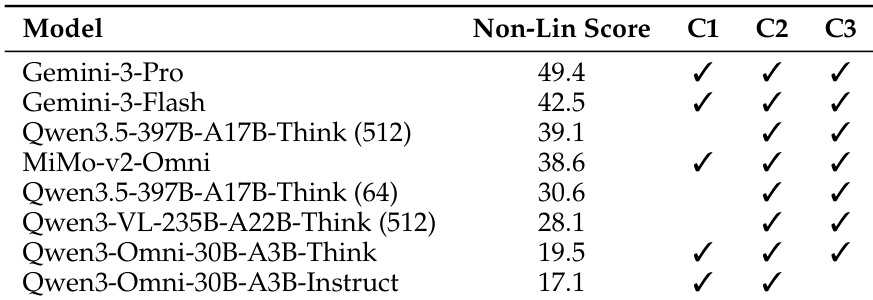
作者使用一个旨在评估渐进理解水平、能力一致性和推理连贯性的全面基准测试,评估了各种视频多模态大语言模型。结果揭示了当前模型与人类专家之间显著的性能差距,商业模型通常优于开源替代方案。研究结果表明,模型遭受层级瓶颈的影响,即基础任务中的错误会传播到复杂推理中,并且它们表现出对文本线索的严重依赖,这削弱了它们的多模态鲁棒性。