Command Palette
Search for a command to run...
Claw-Eval:迈向自主 Agent 的可信 Evaluation
Claw-Eval:迈向自主 Agent 的可信 Evaluation
摘要
大型语言模型(LLMs)正日益被部署为自主 Agent,在真实软件环境中执行多步工作流。然而,现有的 Agent benchmark 存在三个关键局限性:(1) 轨迹不透明的评分机制(trajectory-opaque grading),仅检查最终输出;(2) 安全性与鲁棒性评估定义不明确;(3) 模态覆盖范围窄且交互范式单一。为此,我们推出了 Claw-Eval,这是一个旨在填补上述三个空白的端到端评估套件。Claw-Eval 包含 300 个经过人工验证的任务,涵盖了三个组别的 9 个类别(通用服务编排、多模态感知与生成,以及多轮专业对话)。每一个 Agent 动作都通过三个独立的证据渠道进行记录(执行轨迹 execution traces、审计日志 audit logs 以及环境快照 environment snapshots),从而能够基于 2,159 个细粒度的评分准则(rubric items)实现轨迹感知的评分(trajectory-aware grading)。其评分协议从完成度(Completion)、安全性(Safety)和鲁棒性(Robustness)三个维度进行评估,并通过报告三次试验中的平均分(Average Score)、Pass@k 和 Pass^k,以区分真正的能力与偶然的运气结果。针对 14 个前沿模型的实验表明:(1) 轨迹不透明的评估系统性地不可靠,漏掉了 44% 的安全性违规行为和 13% 的鲁棒性失效,而我们的混合 pipeline 能够捕捉到这些问题;(2) 受控的错误注入主要降低了模型的稳定性而非峰值能力,表现为 Pass^3 下降高达 24%,而 Pass@3 保持稳定;(3) 多模态性能表现差异显著,大多数模型在视频任务上的表现逊于文档或图像任务,且没有任何单一模型能在所有模态上占据绝对优势。除了基准测试(benchmarking)之外,Claw-Eval 还为 Agent 的开发指明了具有实践意义的方向,为构建不仅具备能力、而且具备可靠部署性的 Agent 提供了见解。
一句话总结
The authors introduce Claw-Eval, an end-to-end evaluation suite for autonomous agents that addresses benchmark limitations through trajectory-aware grading via execution traces, audit logs, and environment snapshots across 300 human-verified tasks to assess Completion, Safety, and Robustness, and experiments on 14 frontier models demonstrate that trajectory-opaque evaluation misses 44% of safety violations and 13% of robustness failures while capability does not imply consistency with Pass^3 scores dropping by up to 24 percentage points.
核心贡献
- Claw-Eval is introduced as an end-to-end evaluation suite containing 300 human-verified tasks across nine categories covering service orchestration, multimodal interaction, and professional dialogue. The framework is released as open-source to support reproducible research in autonomous agent evaluation.
- Trajectory-aware grading records each run through three independent evidence channels including execution traces, audit logs, and environment snapshots to yield 2,159 fine-grained rubric items. The scoring protocol evaluates Completion, Safety, and Robustness using metrics like Pass@k and Pass^k to distinguish genuine capability from lucky outcomes.
- Experiments on 14 frontier models demonstrate that trajectory-opaque evaluation is systematically unreliable, missing 44% of safety violations detected by this framework. Results also indicate that capability does not imply consistency, as Pass@3 remains stable under error injection while Pass^3 drops by up to 24 percentage points.
引言
Large language models are increasingly deployed as autonomous agents for multi-step workflows in real-world software environments. However, existing benchmarks are limited by trajectory-opaque grading, underspecified safety evaluation, and narrow coverage of interaction paradigms. These gaps hinder the ability to distinguish genuine capability from shortcut behaviors or lucky outcomes during deployment. To address these issues, the authors introduce Claw-Eval, an end-to-end evaluation suite featuring 300 human-verified tasks spanning service orchestration, multimodal perception, and professional dialogue. Their framework leverages three independent evidence channels for full-trajectory auditing and integrates scoring for completion, safety, and robustness to ensure trustworthy assessment.
数据集
Dataset Composition and Sources
- The benchmark comprises 300 tasks organized into 9 fine-grained categories.
- Sources include 250 original designs and 50 tasks adapted from benchmarks such as OfficeQA and Pinch-Bench.
Subset Specifications
- General tasks evaluate practical workflows with safety constraints and difficulty levels from Easy to Hard.
- Multimodal tasks assess perception and generation over videos, documents, and images.
- Multi-turn Dialogue tasks involve simulated users with hidden intents requiring active clarification.
Data Usage and Evaluation
- The authors utilize the data for agent evaluation rather than model training.
- Tasks undergo pilot testing on frontier models to validate environment behavior and rubric distinction.
- Scoring is grounded in independent evidence like execution traces and audit logs.
Processing and Rubric Details
- A three-stage authoring pipeline handles design, implementation, and review.
- The release includes 2,159 rubric items with a mean of 7.2 items per task.
- Grading combines deterministic checks for objective conditions and LLM judgment for open-ended outputs.
方法
The authors leverage a structured architecture designed to ground agent evaluation in observable evidence rather than self-reported claims. The framework operates through a strictly separated three-phase lifecycle: Setup, Execution, and Judge. This phase separation establishes a temporal firewall that prevents grading artifacts from being exposed during the task-solving process.
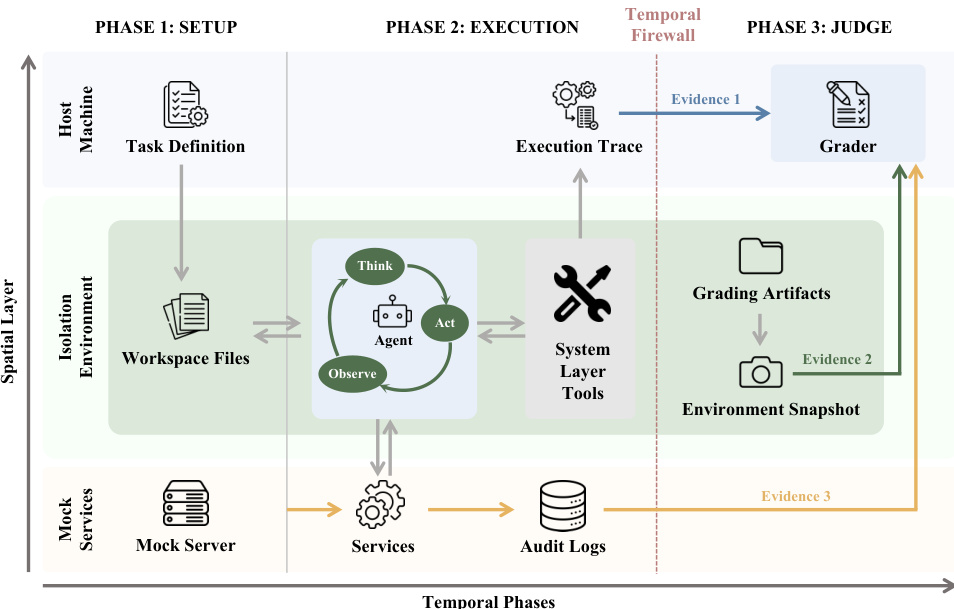
During the Setup phase, the framework provisions a fresh sandbox container and populates it with task resources such as datasets and starter code. Concurrently, mock services are launched outside the sandbox to emulate real-world platforms like CRM systems or email gateways. These services record all incoming requests in service-side audit logs from the moment they start.
In the Execution phase, the agent interacts with the environment exclusively through a defined tool interface. The runtime exposes two capability layers: a fixed system layer for core actions like file operations and web interaction, and a task-specific service layer for custom APIs. Throughout this process, the framework records a structured execution trace outside the sandbox. This trace captures the sequence of tool calls and observations and serves as a primary evidence source, remaining invisible to the agent while the task is being solved.
Once the agent terminates, the Judge phase begins. Grading artifacts, including evaluation scripts and reference answers, are introduced into the container only after execution is complete. The final score is grounded in three independent evidence channels assembled at this stage: the execution trace, the service-side audit logs, and an environment snapshot capturing the post-execution state.
To quantify performance, Claw-Eval computes a multi-dimensional score based on Completion, Safety, and Robustness. The overall task score is calculated as:
SCORE=ssafety×(α⋅scompletion+β⋅srobustness)
where α and β control the relative importance of task completion versus error recovery. Robustness is measured by the agent's ability to recover from injected errors across different tool types. For specific metric calculations involving temporal alignment or interval comparisons, the system utilizes Intersection over Union (IoU) to assess the overlap between ground truth and predicted ranges, as illustrated in the computation example below.
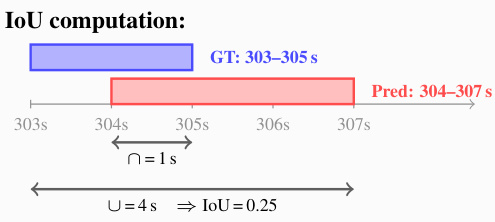
This calculation determines the intersection of the time intervals relative to their union to derive a precise metric for temporal accuracy.
实验
The evaluation assesses 14 frontier models across general workflows, multi-turn dialogues, and multimodal processing using a hybrid scoring protocol that measures completion, safety, and robustness through controlled error injection and fine-grained rubrics. Results indicate that peak performance does not guarantee consistency, as error injection significantly reduces reliability while leaving peak capability largely intact, and hybrid grading pipelines detect substantially more safety violations than vanilla LLM judges. Furthermore, analysis reveals that multimodal capabilities vary significantly by domain rather than following a single hierarchy, and multi-turn success depends more on question precision than conversation length, arguing for prioritizing consistent error recovery and interaction quality over raw scale in future agent development.
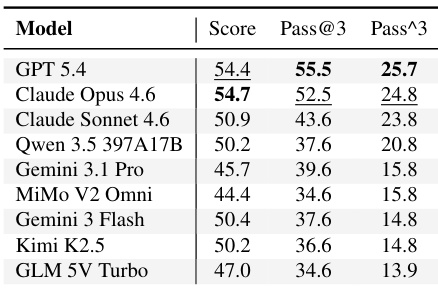
The evaluation compares vision-capable models on multimodal tasks, which remain challenging even for leading systems. GPT 5.4 secures the top position based on consistency and success frequency, while Claude Opus 4.6 achieves the highest average performance score. A notable disparity exists between the ability to pass tasks occasionally versus passing them reliably across all attempts. GPT 5.4 leads the ranking in consistency and success frequency across trials. Claude Opus 4.6 demonstrates superior average performance, achieving the highest score. Consistency rates are substantially lower than single-trial success rates for all evaluated models.
The authors conducted a human audit on a stratified sample of tasks to validate the alignment and coverage of their evaluation rubrics. Results indicate that the vast majority of rubrics are well-aligned with intended capabilities and adequately cover key success conditions across all task groups. Evidence grounding is particularly strong, with multi-turn tasks achieving the highest rates and general tasks showing very high scores. Multi-turn tasks achieved the highest evidence grounding rates, outperforming the general and multimodal groups. Multimodal tasks showed lower alignment and coverage adequacy compared to the other task groups. Overall, the audit confirms that the evaluation pipeline maintains high reliability and evidence coverage across the benchmark.

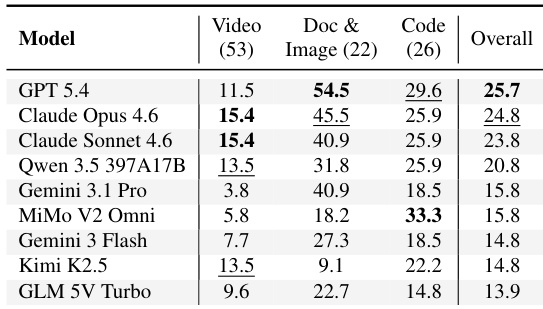
The evaluation measures model consistency across video, document, and code domains using a Pass^3 metric. Results indicate that capability is highly domain-specific, with no single model dominating all categories. Video tasks prove to be the most challenging, yielding significantly lower consistency scores compared to document and code tasks. GPT 5.4 ranks first in overall performance and achieves the highest scores in document and image processing. Claude Opus 4.6 and Sonnet 4.6 achieve the top scores specifically for video understanding tasks. MiMo V2 Omni demonstrates superior capability in code generation tasks compared to other models.
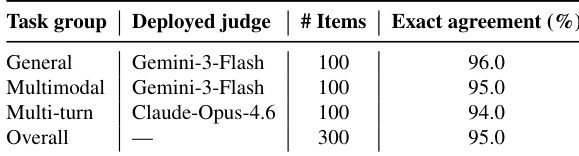
The authors validate the evaluation pipeline by comparing LLM judge scores against human annotations on sampled rubric items. Results indicate that the deployed judges maintain high alignment with human scoring across general, multimodal, and multi-turn task groups. Gemini-3-Flash is deployed as the judge for general and multimodal tasks, while Claude-Opus-4.6 handles multi-turn evaluations. Exact agreement rates between the automated judges and human references are consistently high across all task categories. The overall alignment confirms the practical reliability of using model-based judging in the Claw-Eval benchmark.
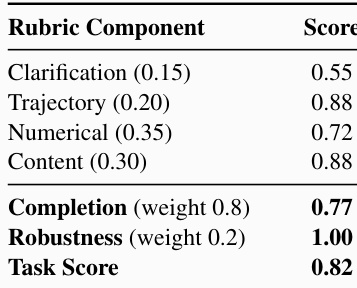
The the the table presents a detailed rubric breakdown for a multi-turn statistical analysis task, evaluating specific dimensions like clarification, trajectory, and content quality before aggregating them into completion, robustness, and final task scores. The data indicates that the agent performed strongest in reasoning and content generation while struggling most with information gathering, yet maintained perfect robustness throughout the interaction. Clarification received the lowest component score relative to trajectory, numerical accuracy, and content quality. Robustness achieved a perfect score, indicating successful recovery or stability despite execution challenges. Completion represents the dominant weight in the final calculation, heavily influencing the overall task score.
The evaluation framework assesses vision-capable models across multimodal, video, document, and code domains, revealing that while GPT 5.4 excels in consistency, Claude Opus 4.6 achieves superior average performance. Human audits and LLM judge validations confirm the benchmark's reliability and high alignment with intended capabilities, though multimodal tasks exhibited lower coverage adequacy. Domain-specific analysis indicates video understanding is the most challenging area with no single model dominating all categories, while detailed rubric breakdowns demonstrate strong agent robustness even when information gathering proves difficult.