Command Palette
Search for a command to run...
ReVSI: 重建视觉空间智能评估,以实现对VLM 3D推理的准确评估
ReVSI: 重建视觉空间智能评估,以实现对VLM 3D推理的准确评估
Yiming Zhang Jiacheng Chen Jiaqi Tan Yongsen Mao Wenhu Chen Angel X. Chang
摘要
在现代视觉-语言模型(VLM)设置下,空间智能的现有评估方法可能存在系统性失效的问题。首先,许多基准测试中的问答(QA)对源自传统 3D 感知任务中基于点云的 3D 标注数据。当将这些标注视为视频评估的事实标准(ground truth)时,重建和标注过程中的伪影可能导致视频清晰可见的对象被遗漏、对象身份被错误标记,或损害依赖几何结构的回答(如尺寸),从而产生错误或模棱两可的 QA 对。其次,现有评估往往假设模型可以访问完整场景信息,而许多 VLM 仅基于稀疏采样的帧(例如 16 至 64 帧)运行,这使得在实际模型输入条件下,许多问题实际上无法回答。为提升评估的有效性,我们引入了 ReVSI,这是一种确保每个 QA 对在实际模型输入下均可回答且正确的基准测试与协议。为此,我们使用专业 3D 标注工具对来自 5 个数据集中的 381 个场景的对象和几何结构进行了重新标注,以提高数据质量,并通过严格的偏差缓解措施和人工验证重新生成了所有 QA 对。此外,我们通过在多种帧预算(16/32/64/全部)和细粒度对象可见性元数据上提供变体,增强了评估的可控性,从而支持受控的诊断性分析。在 ReVSI 上对通用及领域特定 VLM 的评估揭示了先前的基准测试所掩盖的系统性失效模式,从而提供了对空间智能更可靠且具备诊断意义的评估结果。
一句话总结
作者介绍了 ReVSI,这是一个基准和协议,通过对五个数据集中的 381 个场景的对象和几何结构进行重新标注,并生成可在稀疏帧输入下回答的人机验证问答对,确保视觉语言模型的视觉空间智能评估有效,揭示了系统性失败模式,并能够对 3D 推理能力进行可靠的诊断评估。
核心贡献
- 本文介绍了 ReVSI,这是一个确保问答对在视觉语言模型的实际稀疏帧输入下有效的基准和协议。数据集构建对五个数据集中的 381 个场景的对象和几何结构进行了重新标注,以消除先前 3D 感知标注中发现的伪影。
- 通过提供跨多个帧预算的基准变体以及用于诊断分析的细粒度对象可见性元数据,提高了评估的可控性。这些功能实现了证据缺失的控制,用于测试模型是依赖视觉信息还是非视觉先验。
- ReVSI 上的实证评估揭示了通用模型和特定领域模型中存在的系统性失败模式,这些模式被现有基准所掩盖。结果表明,扩展后训练数据并不能一致地提高性能,且某些模型未能将答案建立在视觉证据之上。
引言
视觉语言模型需要强大的空间推理能力才能在机器人或医学成像等 3D 环境中有效运行。当前的评估标准(如 VSI-Bench)通常依赖于重用的 3D 标注,这些标注偏离了实际视频证据,并假设尽管输入帧稀疏但仍可完全观察场景。作者通过引入 ReVSI 解决了这些有效性差距,这是一个重建的基准,通过专业重新标注和帧感知协议,确保模型输入与真实标注之间的严格一致性。这一严格的框架揭示了先前评估中的显著性能差异,并支持诊断测试以区分真正的空间推理和基于非视觉先验的预测。
数据集
-
数据集组成与来源
- 作者使用源自五个公共数据集的 381 个场景构建了 ReVSI:ScanNetv2、ScanNet++、ARKitScenes、3RScan 和 MultiScan。
- 该基准专注于室内 3D 环境,以测试视觉语言模型中的视觉空间智能。
- 对象标注采用开放词汇设置,包含超过 500 个唯一类别,比先前工作使用的封闭集显著扩展。
-
每个子集的关键细节
- 数据被组织成包括 16、32、64 和全帧设置的帧预算变体,以模拟不同的采样率。
- 具体任务包括对象计数、尺寸估计、绝对和相对距离、相对方向、房间尺寸估计和路径规划。
- 对象出现顺序任务被排除,以专注于空间推理而非时间推理。
- 模糊的对象类别(如鞋子)被过滤掉,以防止定义不当的查询。
-
论文中的用途
- 该数据集用作评估基准而非训练集,以诊断通用和特定领域模型中的空间推理失败。
- 评估协议确保在每个特定的帧采样配置下问题可回答且真实值正确。
- 作者使用数据通过比较不同可见性水平和帧预算下的性能来进行受控诊断分析。
-
处理与元数据构建
- 所有 3D 边界框均使用重力对齐的定向边界框算法进行重新标注,随后进行手动细化。
- 房间边界从正交顶视图手动标注为多边形,以确保准确的面积估计。
- 对象可见性通过检查像素覆盖率是否在最主要帧中超过 5% 来确定,并对边缘案例进行手动验证。
- 团队生成了用于压力测试的虚拟视频,包括 16 帧设置下的查询丢弃、第一帧重复和黑色帧变体。
- 对于对象命名验证,标注人员裁剪包含对象的紧密图像区域,并使用 GPT-5.2 作为辅助检查,最后确定人工标签。
- 问题模板经过细化以减少偏差,例如添加累积计数查询,并移除 1 米以下的短距离问题。
实验
该研究使用 ReVSI 基准评估了多个视觉语言模型,该基准强制执行帧预算感知协议和可见性一致的问题,以解决现有基准中的有效性问题。结果表明,ReVSI 通过惩罚先前在 VSI-Bench 中被掩盖的幻觉,揭示了模型排名的显著差异,显示专有模型在基于证据的空间推理方面始终优于开源对应模型。此外,对虚拟视频的诊断测试表明,专门的微调模型在缺乏视觉证据时往往会灾难性地失败,这表明监督保真度而非训练数据数量是稳健 3D 智能的主要瓶颈。
该表评估了各种专有和开源视觉语言模型在 ReVSI 基准上的数值和多项选择任务的空间推理能力。结果显示,与列出的开源模型相比,专有模型通常实现了更高的总体性能分数。此外,在开源系列中,较大的模型尺寸往往比其较小对应版本产生更好的结果。专有模型在大多数空间推理类别中始终优于开源模型。同一系列内的较大模型变体(如 32B 和 38B 版本)比较小的 8B 版本表现出更高的准确性。房间尺寸估计对于大多数模型来说似乎比对象尺寸估计更具挑战性。
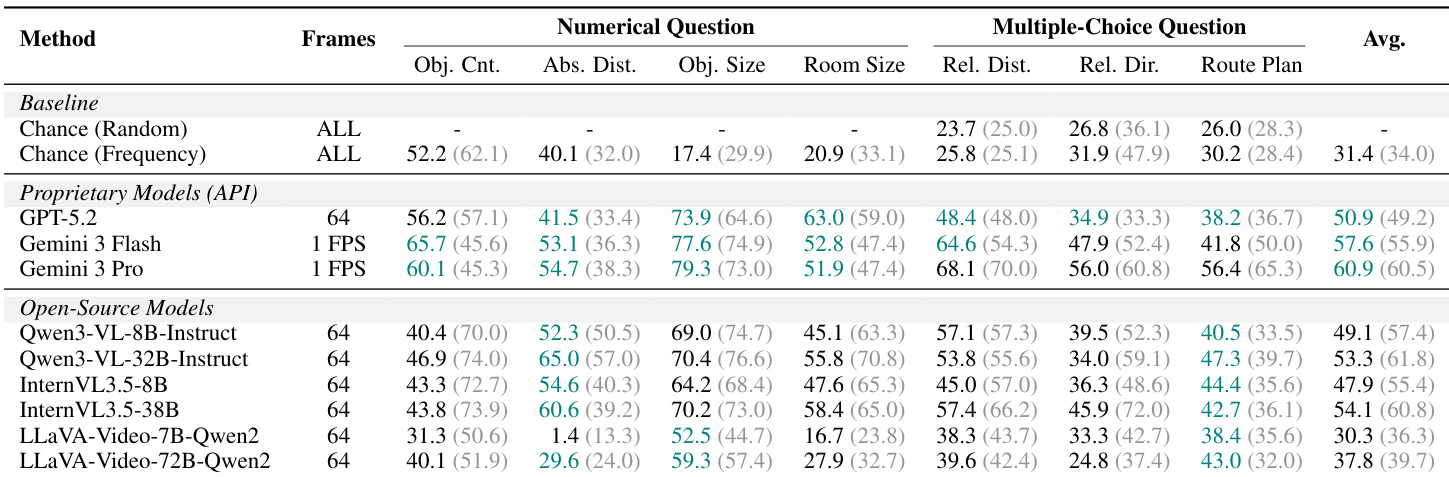
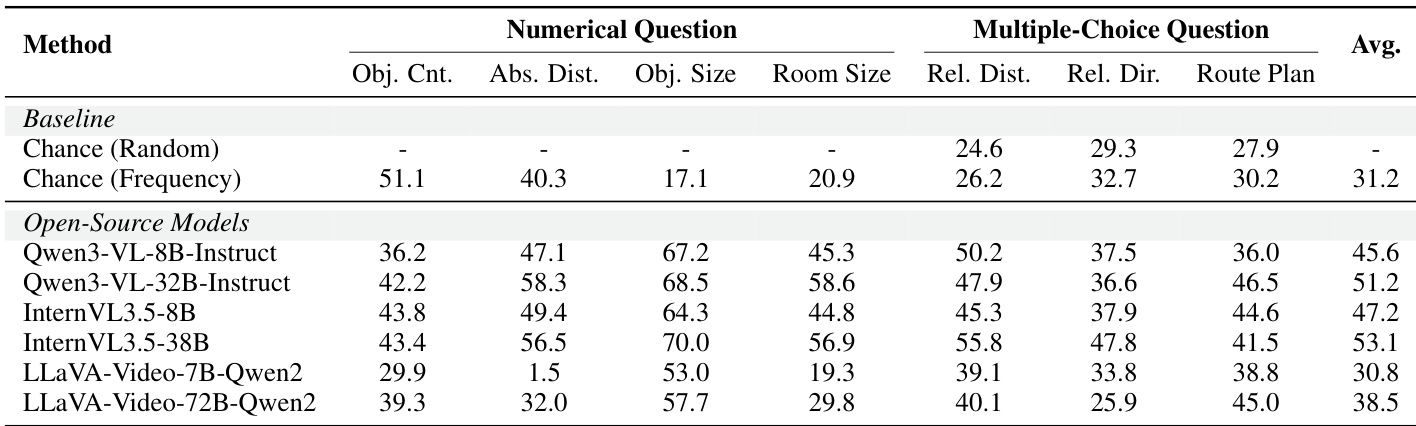
该表展示了开源视频语言模型在数值和多项选择空间推理任务上的评估结果。结果表明,与较小版本和随机基线相比,较大的模型变体通常实现了更高的平均分数。相对于计数和距离估计,对象尺寸估计任务的性能始终最高。在 Qwen 和 InternVL 系列内增加模型尺寸始终导致更高的平均分数。对象尺寸估计产生的性能显著高于对象计数和绝对距离估计。最小的模型变体表现低于基于频率的随机基线,而较大的模型超过了它。
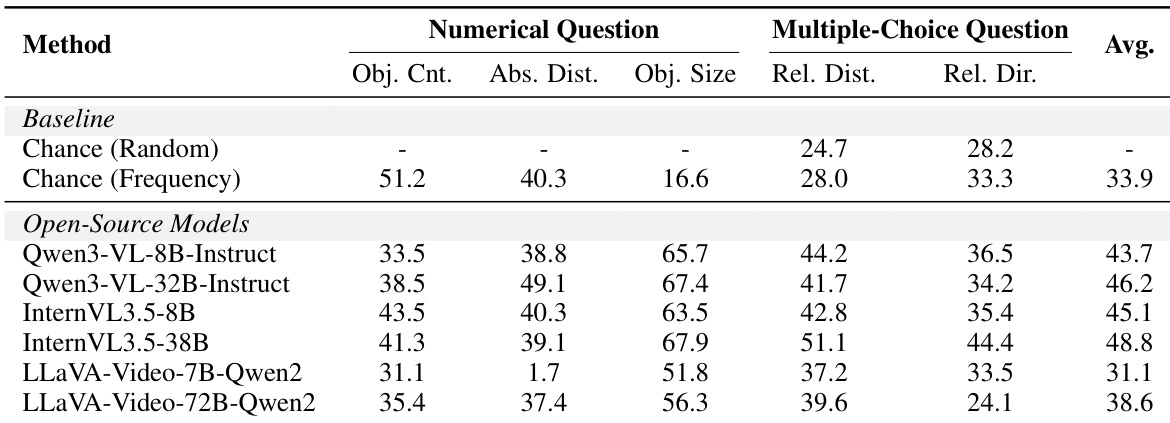
ReVSI 基准上的评估结果显示,专有模型在各种空间推理任务中始终优于开源对应模型。与以前的基准不同,专门的微调模型没有表现出实质性的性能提升,并且通常表现不如其基础版本。此外,数据突出了性能不对称性,即模型处理单个对象计数和最近距离估计比多个对象场景或最远距离查询更有效。专有模型在对象计数和空间估计任务中始终获得比开源模型更高的分数。微调的专门模型显示出相对于基础模型有限的改进,偶尔会遭受性能下降。性能因任务复杂性而异,模型处理单个对象查询的效果优于多个对象查询。
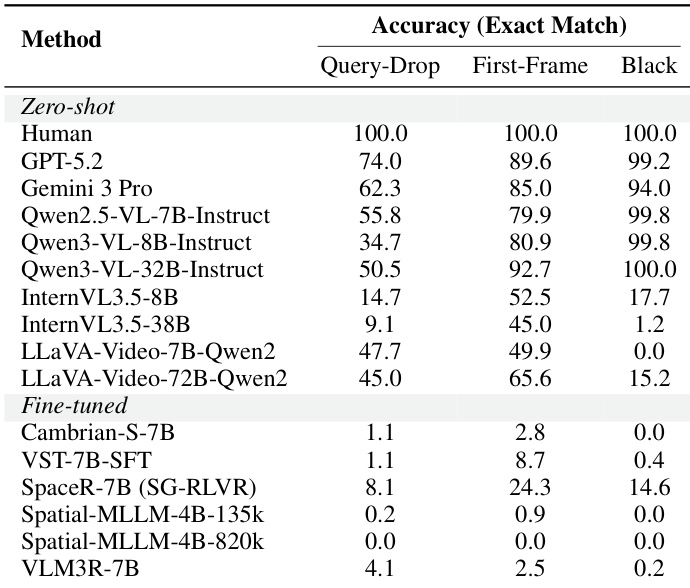
作者使用查询对象缺失的虚拟视频输入评估模型对幻觉的鲁棒性。结果表明,虽然人类评估者和专有模型能够可靠地识别对象的缺失,但专门的微调模型经常失败,预测非零计数。这表明在现有基准上微调可能导致过拟合并忽视实际视觉证据。专门的微调模型在黑色视频输入上表现出接近零的性能,揭示了倾向于幻觉不存在的对象。专有模型在需要检测缺失对象的任务中始终优于开源对应模型。零样本开源模型之间的性能差异显著,有些在虚拟输入上实现了完全准确,而有些则完全失败。
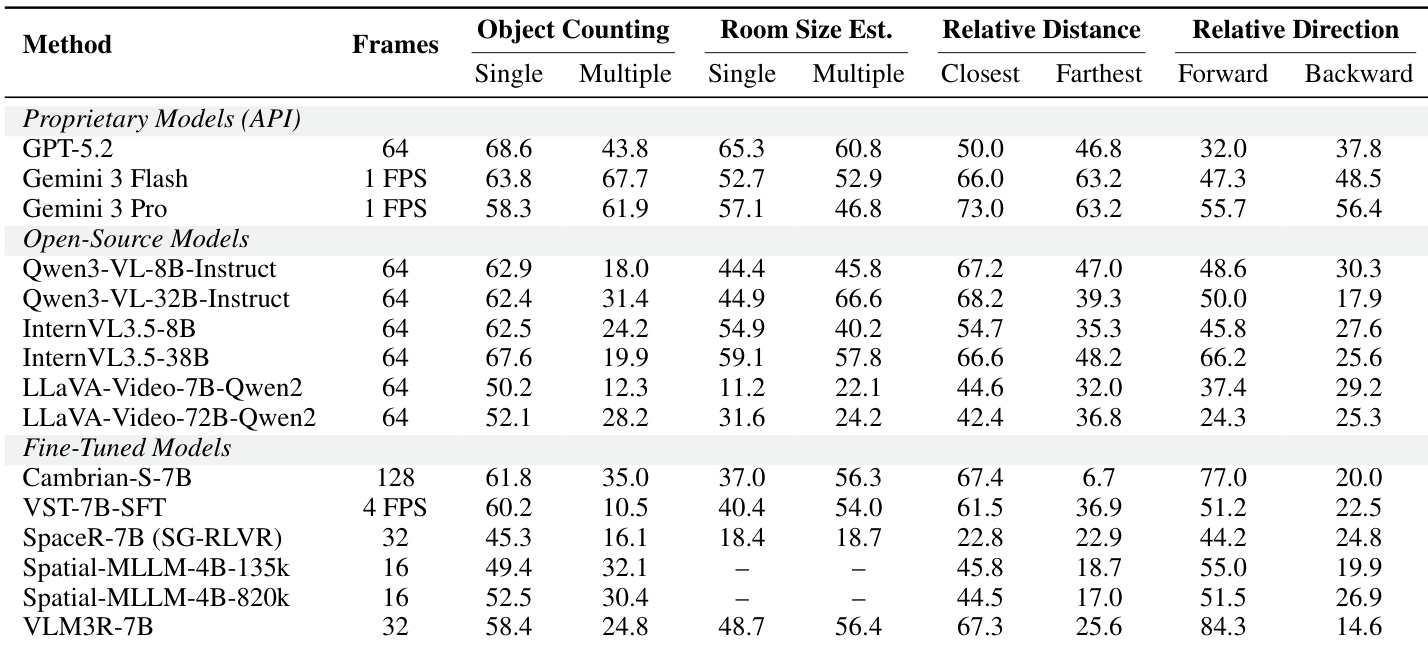
作者使用 ReVSI 基准评估了代表性的开源视觉语言模型在数值和多项选择空间推理任务上的表现。结果显示了一个清晰的趋势,即较大的模型变体(如 Qwen 和 InternVL 的 32B 版本)在大多数指标上优于其较小的 8B 对应版本。虽然顶级模型处理对象尺寸估计相对较好,但绝对距离估计在不同架构之间表现出更大的性能差距。较大的模型规模通常在数值和多项选择空间推理基准上产生更优越的性能。在评估的模型中,对象尺寸估计任务的解决准确率高于绝对距离估计任务。在此比较中,Qwen3-VL 和 InternVL3.5 系列显示出比 LLaVA-Video 变体更强的整体空间推理能力。
该评估评估了专有、开源和微调视觉语言模型在 ReVSI 基准上的空间推理和幻觉鲁棒性。专有模型始终优于开源替代方案,并且较大的参数变体通常在图像和视频任务中比较小版本实现更高的准确性。相反,专门的微调模型通常表现不如基础版本并幻觉不存在的对象,而涉及距离估计和多个对象的任务仍然比对象尺寸估计更困难。