Command Palette
Search for a command to run...
异构科学基础模型协作
异构科学基础模型协作
Zihao Li Jiaru Zou Feihao Fang Xuying Ning Mengting Ai Tianxin Wei Sirui Chen Xiyuan Yang Jingrui He
摘要
智能体大型语言模型系统已展现出强大的能力。然而,其将语言作为通用接口的特性,从根本上限制了其在许多现实问题中的应用,尤其是在科学领域,该领域已开发出针对超越自然语言处理的专门任务而优化的特定领域基础模型。在本工作中,我们推出了 Eywa,这是一个异构智能体框架,旨在将以语言为中心的系统扩展至更广泛的科学基础模型类别。Eywa 的核心思想是利用基于语言模型的推理接口来增强特定领域的基础模型,使语言模型能够引导对非语言数据模态的推理。这种设计使得通常针对特定数据和任务进行优化的预测性基础模型,能够参与到智能体系统中的高层推理和决策过程中。Eywa 既可以作为单智能体管道的即插即用替代方案(EywaAgent),也可以通过用特定智能体替换传统智能体的方式集成到现有的多智能体系统中(EywaMAS)。我们进一步研究了一种基于规划的编排框架,在该框架中,规划器动态协调传统智能体和 Eywa 智能体,以跨异构数据模态解决复杂任务(EywaOrchestra)。我们在涵盖物理、生命和社会科学的广泛科学领域中对 Eywa 进行了评估。实验结果表明,Eywa 提高了涉及结构化数据和特定领域数据的任务性能,同时通过与特定领域基础模型的有效协作,降低了对基于语言推理的依赖。
一句话总结
本工作介绍了 Eywa,一个异构 Agent 框架,该框架通过将基于语言模型的推理接口增强领域特定模型,将以语言为中心的系统扩展到更广泛的科学基础模型类别,使预测性基础模型能够参与物理、生命科学和社会科学中的高级推理和决策,同时提高在结构化数据和领域特定数据上的性能,并减少了对基于语言的推理的依赖。
核心贡献
- 本文介绍了 Eywa,一个异构 Agent 框架,该框架通过基于语言模型的推理接口增强领域特定基础模型,以实现对非语言数据模态的推理。这种设计允许针对特定任务优化的预测性基础模型参与 Agent 系统内的高级推理和决策过程。
- 该框架通过 EywaAgent 作为单 Agent 流水线的即插即用替换,或作为 EywaMAS 集成到现有的多 Agent 系统中。一个名为 EywaOrchestra 的基于规划的编排框架动态协调传统 Agent 和 Eywa Agent 以解决跨异构数据模态的复杂任务。
- 实验结果表明,Eywa 提高了在物理、生命科学和社会科学中涉及结构化数据和领域特定数据的任务性能。评估确认了通过与专用基础模型的有效协作,减少了对基于语言的推理的依赖。
引言
Agent 大型语言模型系统在推理方面表现出色,但严重依赖自然语言,这限制了它们在需要结构化或非语言数据的科学领域中的有效性。虽然存在用于蛋白质折叠或天气预报等任务的领域特定基础模型,但它们通常缺乏原生语言接口,阻碍了其直接集成到 Agent 工作流中。作者介绍了 Eywa,这是一个异构框架,通过基于语言的推理接口增强这些专用模型,以实现跨单 Agent、多 Agent 和编排模式的模态原生协作。在物理、生命科学和社会科学领域的实验表明,与仅语言基线相比,Eywa 提高了任务效用,同时减少了 token 消耗。
数据集
数据集构成与来源
- 作者从四个主要数据集构建了 EywaBench:DeepPrinciple、MMLU-Pro、fev-bench 和 TabArena。
- 这些来源涵盖三种模态,包括自然语言、时间序列和表格数据。
- 分类涵盖三个父领域(物理、生命科学和社会科学)和九个子领域。
- 四个主要基准的背后是 67 个不同的源数据集,以确保高多样性并避免领域坍塌。
子集详情与覆盖范围
- 发布的 EywaBench-V1 划分包含 200 个任务实例,选择用于平衡覆盖。
- DeepPrinciple 在化学、材料、生物和物理领域贡献了 1,125 个问题。
- MMLU-Pro 提供了 6,978 个科学问题,从多项选择转换为开放格式。
- fev-bench 包括 96 个时间序列数据集,每个数据集最多有 30,000 个协变量序列。
- TabArena 提供 51 个表格数据集,用于分类和回归任务,最多有 150,000 行。
- 领域分布近乎均匀,物理、生命科学和社会科学分别占 32.0%、30.0% 和 38.0%。
- 模态分布涵盖自然语言、时间序列和表格数据,分别占 41.0%、39.0% 和 20.0%。
数据使用与评估
- 该基准仅用于评估,而非模型训练。
- 200 样本子集允许在不产生高昂成本的情况下手动配置和验证 Agent 系统。
- 性能使用 0 到 1 之间的统一效用分数进行测量,适用于所有模态。
- 结果被聚合为每个领域及所有任务的未加权平均值。
- 该流水线是参数化且可扩展的,允许通过重采样添加实例而不改变模式。
处理与元数据构建
- 数据存储在带有 Snappy 压缩的字典编码 Parquet 文件中。
- 金融时间序列输入经过时间戳匿名化处理,以防止模型记忆历史趋势。
- MMLU-Pro 问题被重新格式化,要求直接开放答案而不是多项选择。
- 时间序列和表格任务通过采样不同的窗口或数据子集支持可扩展的实例生成。
- 指标包括文本的软匹配分数和数值预测的归一化误差组合(sMAPE 和 MAAPE)。
方法
Eywa 框架解决了大型语言模型(LLMs)和领域特定基础模型(FMs)之间的固有权衡。虽然 LLMs 拥有强大的通用推理能力,但它们通常缺乏科学或领域特定任务所需的专业知识。相反,FMs 提供可靠的领域特定计算,但通常缺乏原生语言接口。作者提出了一种通过模块化设计集成这些组件的统一架构。请参阅下方的框架图,该图说明了源自阿凡达宇宙的概念类比及其在 Hugging Face 生态系统内的技术实现。
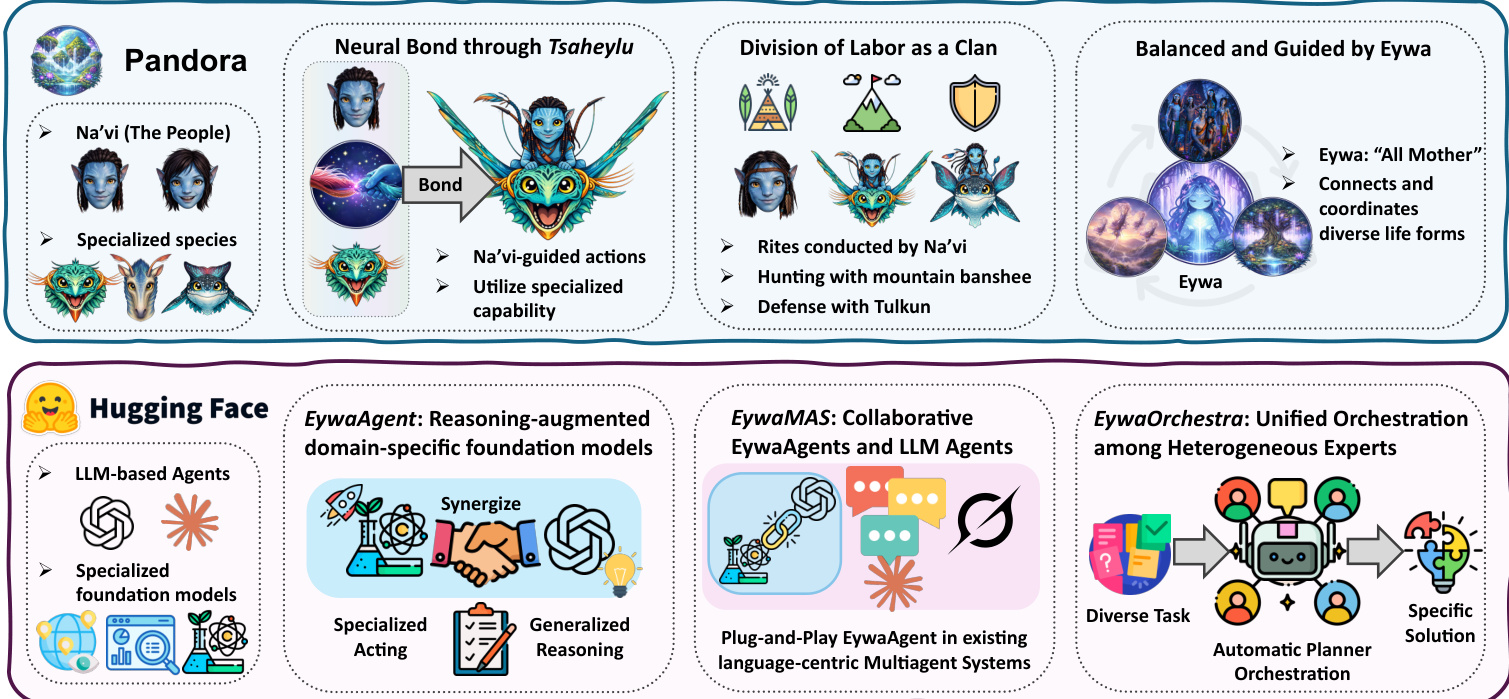
该架构分为三个层级。顶层概念化了 Na'vi(代表 LLM Agent)与通过神经连接连接的特定物种(代表 FMs)之间的关系。底层将其转化为三个技术模块:用于推理增强领域模型的 EywaAgent,用于协作多 Agent 系统的 EywaMAS,以及用于异构专家之间统一编排的 EywaOrchestra。
该框架的核心单元是 EywaAgent,它通过基于语言的推理接口增强基础模型。实现这种集成的机制是"Tsaheylu"连接,旨在在语言模型和专家基础模型之间建立稳健的通信通道。如下图所示,该接口确保 LLM 能够基于任务状态正确配置控制输入,同时将专用计算委托给基础模型。
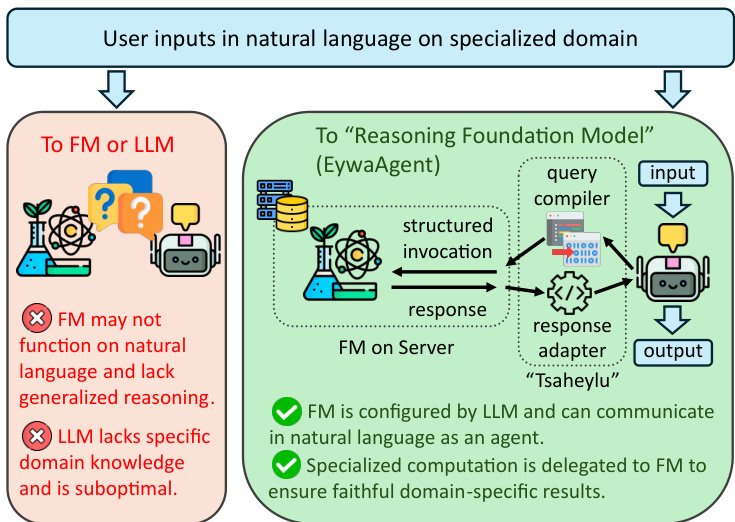
形式上,Tsaheylu 接口被定义为领域 k 的双向通信对 (ϕk,ψk)。查询编译器 ϕk 将 LLM 的任务状态转换为结构化的 FM 调用,而响应适配器 ψk 将专家输出转换为规划器可消费的表示。该流水线允许系统根据任务要求动态决定是否调用基础模型,有效地将仅语言 Agent 作为特例包含在内,同时严格扩展可计算函数的类别。
在单 Agent 单元的基础上,该框架扩展到多 Agent 设置以支持复杂和异构的协作。EywaMAS 将 EywaAgent 泛化为分布式多 Agent 设置,允许多个专用 Agent 进行交互。与仅依赖基于语言的 Agent 的传统多 Agent 系统不同,EywaMAS 实现了仅语言 Agent 和 EywaAgents 在统一框架内的无缝集成。请参阅下方的比较图,查看 EywaMAS 如何泛化现有的多 Agent 拓扑。
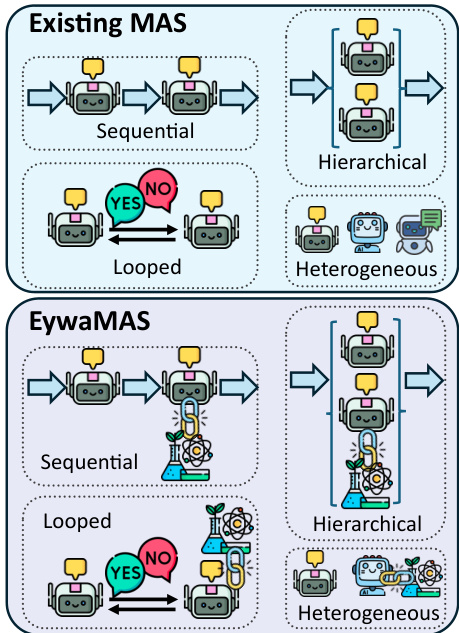
该系统支持跨不同语言模型、跨领域的不同基础模型以及混合 Agent 类型的灵活组合。这种即插即用特性允许在不重新设计通信协议的情况下,将领域特定基础模型纳入现有的 Agent 系统。通信拓扑 G 管理交互,确保 EywaAgents 的专用能力通过网络传播以解决复杂任务。
为了处理现实世界任务的多样性,该框架引入了 EywaOrchestra,一种动态编排机制。一个实例化为大型语言模型的指挥器将输入任务映射到系统配置。这涉及选择每个 Agent 的角色和类型、骨干语言模型、附加的基础模型以及通信拓扑。为了支持这种异构交互,作者采用了一个统一提示模板,指定任务角色、工具上下文、结构化输入字段和预期输出格式。该通用提示的结构在下方图中详细说明。

该模板包含任务身份、模型描述和模态特定指令的占位符。该设计允许不同的任务类型共享相同的高级提示接口,同时通过专用输入标签和输出约束保留模态特定指令。通过将自适应编排与标准化接口相结合,该框架在各种科学领域实现了增强的表达能力和改进的任务性能。
实验
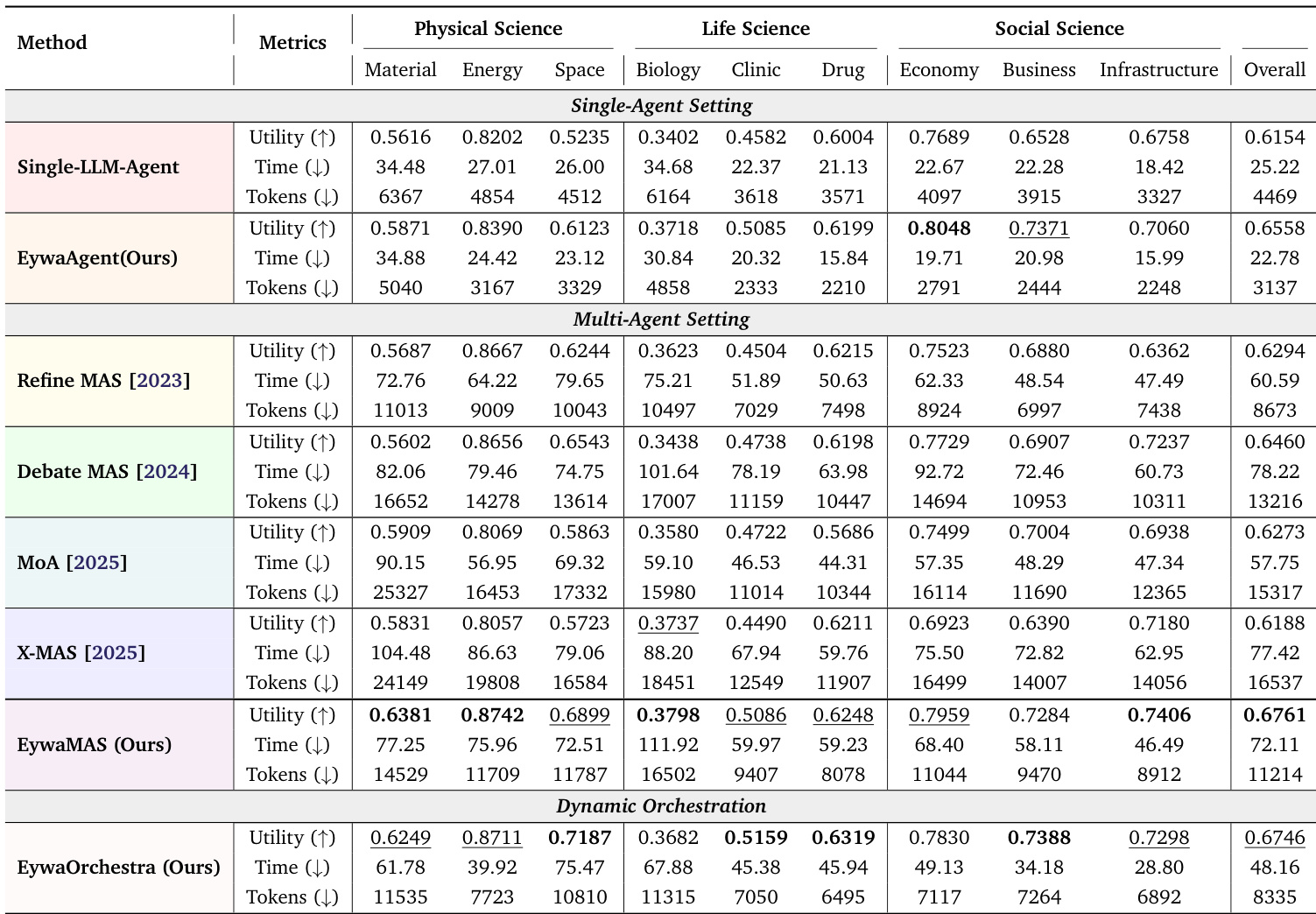
EywaBench 上的实验评估了 Eywa 变体与跨不同科学领域的单 Agent 和多 Agent 语言模型基线。结果表明,集成领域特定基础模型显著提高了效用和效率,因为仅语言 Agent 通常无法在结构化数据上执行准确的数值计算。此外,EywaOrchestra 中的自适应编排实现了与专家设计的系统相当的性能,同时降低了成本,证实了跨模态异构性比单独组合异构语言模型更为关键。
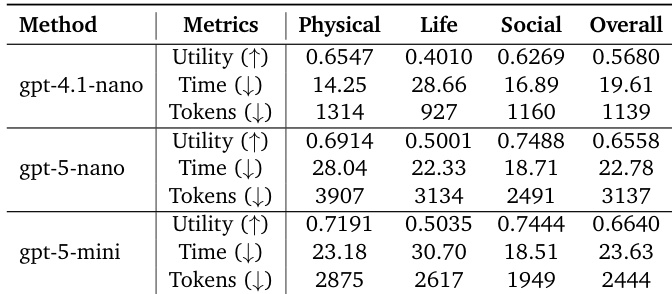
作者使用不同的 LLM 骨干在各种科学领域评估 EywaAgent、EywaMAS 和 EywaOrchestra。结果表明,与仅语言基线相比,集成领域特定基础模型显著提高了效用和效率。EywaMAS 实现了最强的整体性能,而 EywaOrchestra 通过动态调整系统配置提供了具有成本效益的替代方案。与单 Agent 和同质多 Agent 基线相比,EywaMAS 在物理、生命科学和社会科学领域实现了最高的整体效用。EywaOrchestra 匹配了固定多 Agent 系统的性能,同时通过动态配置选择大幅减少了 token 消耗和推理延迟。将 LLM 骨干从 gpt-4.1-nano 升级到 gpt-5-nano 带来了显著的性能提升,而进一步扩展到 gpt-5-mini 则在若干子领域中显示收益递减。
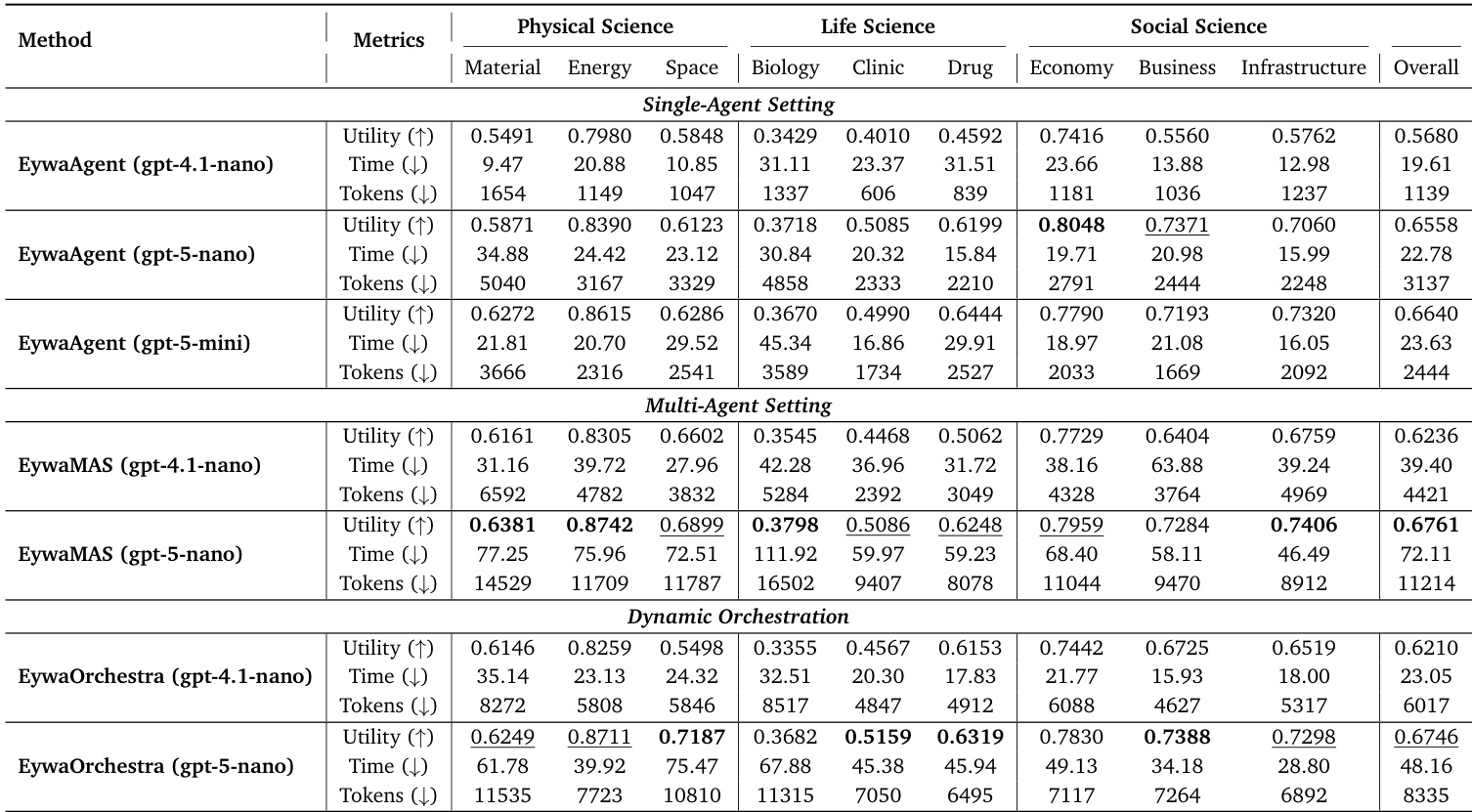
作者使用三个不同的 LLM 后端评估 EywaAgent 系统,以分析模型能力对性能的影响。结果显示,随着骨干强度的增加,整体效用呈现明显的上升趋势,最强的模型取得了最佳分数。虽然最大的模型提供了最高的效用,但它显示了一种权衡,即 token 消耗低于中档模型,但推理时间略高。增加 LLM 骨干的能力导致所有科学领域的整体效用一致提高。最强的模型配置实现了最高的效用,同时比中档配置消耗更少的 token。最小的骨干模型在时间和 token 使用方面最高效,但产生的效用最低。
作者在各种科学领域使用统一协议评估他们提出的方法与各种单 Agent 和多 Agent 基线。结果表明,与仅语言方法相比,集成领域特定基础模型显著提高了任务效用和计算效率。与单 Agent 基线相比,EywaAgent 提高了平均效用并减少了 token 消耗。EywaMAS 实现了最高的整体效用,同时比其他多 Agent 基线使用更少的 token。EywaOrchestra 达到了与专家设计的系统相似的效用水平,但延迟和 token 成本更低。
作者使用各种 LLM 骨干在各种科学领域评估 EywaAgent、EywaMAS 和 EywaOrchestra,以与单 Agent 和仅语言基线比较性能。结果表明,集成领域特定基础模型显著提高了效用和效率,EywaMAS 实现了最高的整体性能,EywaOrchestra 通过动态配置提供了具有成本效益的替代方案。此外,升级 LLM 骨干带来了显著的性能提升,而进一步扩展则在若干子领域中显示收益递减。