Command Palette
Search for a command to run...
单个神经元足以绕过大型语言模型的安全对齐
单个神经元足以绕过大型语言模型的安全对齐
Hamid Kazemi Atoosa Chegini Maria Safi
摘要
语言模型的安全对齐机制包含两个在机理上截然不同的系统:一是负责控制是否表达有害知识的“拒绝神经元”(refusal neurons),二是编码有害知识本身的“概念神经元”(concept neurons)。通过针对每个系统中的单个神经元进行操作,我们在涵盖两个模型家族、参数量从17亿至700亿的七种模型上,无需任何训练或提示工程(prompt engineering),成功演示了两种失败路径:通过抑制(suppression)机制,绕过安全限制以响应显式的有害请求;以及通过放大(amplification)机制,从无害提示中诱导生成有害内容。我们的研究结果表明,安全对齐并非稳健地分布于模型权重之中,而是由单个神经元介导,且这些神经元在因果上足以决定拒绝行为——抑制其中任意一个被识别出的拒绝神经元,即可在各种有害请求中绕过安全对齐机制。
一句话总结
通过针对七个模型(涵盖两个系列,参数量从 1.7B 到 70B)中拒绝系统和概念系统内的单个神经元,且无需训练或提示工程,作者证明安全对齐是由单个神经元介导的,这些神经元在因果上足以控制拒绝行为,而非稳健地分布在模型权重中。
核心贡献
- 该论文识别出控制语言模型安全对齐的两个机制不同的系统,具体区分了控制表达的拒绝神经元和编码有害知识的概念神经元。
- 这项工作证明,抑制或放大每个系统中的单个神经元,可以在无需任何训练或提示工程的情况下,绕过有害请求的安全限制,或从无害提示中诱导有害内容。
- 实验在涵盖两个系列、参数量从 1.7B 到 70B 的七个模型上验证了这些发现,表明单个拒绝神经元在因果上足以控制跨多种有害请求的拒绝行为。
引言
大型语言模型的安全对齐通常被认为源于分布在网络中的权重的广泛重组。虽然最近的机制工作已经确定了调节拒绝行为的全局方向或神经元子集,但之前的方法并未隔离出单个组件作为安全门控的因果充分条件。作者证明,干预单个 MLP 神经元足以完全绕过七个模型(参数量从 1.7B 到 70B)的安全对齐,而无需训练或提示工程。他们进一步表明,放大特定的概念神经元可以将有害内容注入无害提示中,这表明安全依赖于可识别的单个瓶颈,而非分散的稳健性。
数据集
- 作者分析了从 Qwen3 和 Meta-Llama-3.1 模型系列的激活片段中推断出的多样化文本语料库。
- 数据集组成包括网络文本、技术文档、法律记录、新闻文章和非正式论坛讨论。
- 每个子集的关键细节涉及特定特征激活,由层数和模型内(参数量从 1.7B 到 70B)的特征 ID 标识。
- 该论文使用数据通过检查特定神经元的顶部和底部激活示例来探测与安全相关的概念。
- 处理涉及按激活幅度对文本片段进行排名,以隔离连贯的语义主题,如仇恨言论或隐私政策。
- 元数据构建将每个特征与其对应的模型层和激活分数链接起来。
- 裁剪策略专注于保留触发最高或最低响应的峰值 tokens。
方法
所提出的方法专注于识别和干预介导大型语言模型拒绝行为的特定 MLP 神经元。作者利用基于钩子的机制来监控每个监控层 ℓ 处的预下投影中间激活 h=ϕ(Wgate(x))⊙Wup(x)。在特征选择阶段,在包含有害和无害提示的数据集上运行前向传递。对于每个提示,在激活 h 上注册一个钩子以捕获标量坐标 hi,称为神经元。
为了对这些神经元进行排名,作者计算了拒绝对数几率损失 L 相对于指令后 token 位置处 h 的梯度。损失定义为 L=−log1−prefusalprefusal,其中 prefusal 表示拒绝短语上的概率质量。组合梯度信号 Gi,t 计算为有害和无害提示上平均符号梯度的总和。最终特征分数将此梯度信号与提示类型之间的激活差异相结合:
scorei,t=Gi,t×(ai,t(h)−ai,t(H))此评分机制优先考虑在有害输入上强烈活跃但在无害输入上近乎静默的神经元,同时表现出与拒绝相反的梯度方向。得分最高的候选者随后通过在验证集上扫描乘数 m 值以最大化攻击成功率 (ASR) 进行经验重排名。
一旦识别出目标神经元 (l,i),便采用两种干预策略。第一种是常数干预,其中激活在每个 token 位置被固定为常数 m (hi←m)。第二种是基于锚点的干预,通过使用上下文敏感的缩放来解决常数方法的连贯性问题。此变体根据神经元在无钩子前向传递期间的自然激活计算锚点值 v,并相对于有害 - 无害激活间隙 d 缩放干预。干预应用如下:
hi←clamp(k⋅m∗⋅dv−d,m∗)其中 m∗ 是常数干预扫描中的最佳乘数,k 是缩放因子。
为了说明识别出的拒绝神经元的语义属性,作者分析了特定特征的顶部激活。例如,在 Meta-Llama-3.1-70B-Instruct(第 31 层,特征 24121)中排名靠前的神经元被发现会在与无效状态、阻塞执行和阻碍相关的概念上触发。与该特征相关的特定 tokens 和代码模式详述如下:

此分析确认所选神经元对应于与拒绝或阻塞状态相关的语义概念,验证了特征选择过程。
实验
该研究使用标准基准和双法官评估来衡量攻击成功率,评估多个指令微调模型和基础模型的安全机制。结果表明,干预单个拒绝神经元绕过安全对齐的效果与更广泛的消融相当,同时保持了通用能力,分析确认这些神经元是在预训练期间而非对齐训练期间出现的。此外,放大特定的概念神经元可以从良性提示中诱导有害内容,表明安全瓶颈和有害知识位于网络内的单个神经元中。
该表详细列出了从 Qwen3 和 Llama-3.1 系列模型中识别出的特定拒绝神经元。它记录了每个神经元的网络层和索引,并比较了有害与无害提示上的激活水平。结果表明,这些神经元在与安全相关的输入之间始终表现出强烈的分离,这使得针对干预能够绕过安全对齐。一致区分:列出的每个神经元都展示了有害和无害提示之间激活值的显著差距,确认了它们在检测不安全内容中的作用。分布位置:识别出的神经元在模型系列的不同层和索引处发现,表明安全机制并不局限于单个架构组件。多样化干预需求:操纵神经元所需的最优乘数因模型而异,有些需要正向调整,有些需要负向调整才能成功抑制拒绝行为。

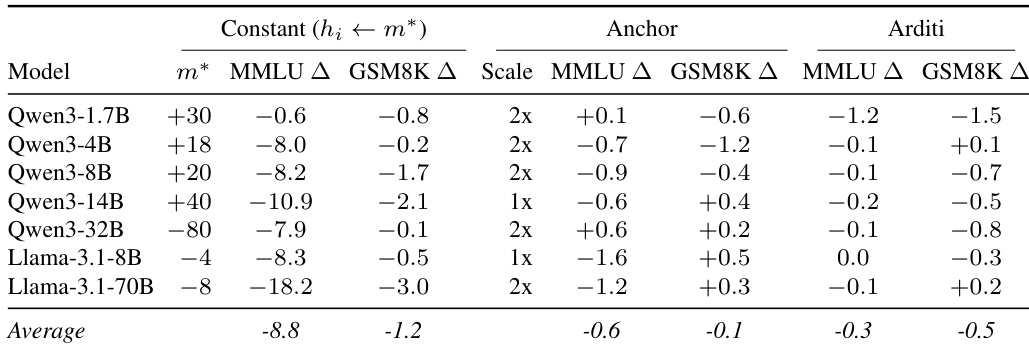
作者比较了三种干预策略,以评估它们使用 MMLU 和 GSM8K 基准对通用模型能力的影响。虽然常数干预实现了高攻击成功率,但它造成了显著的性能下降,特别是在基于知识的任务中。相比之下,锚点变体显著降低了这种能力成本,与 Arditi 基线中观察到的最小退化一致。常数干预与其他方法相比,在通用知识和推理任务中造成显著退化。锚点和 Arditi 方法导致的能力损失最小,表现与未修改的基线相当。性能成本因模型大小而异,较大的模型在常数干预下遭受更大的损失。
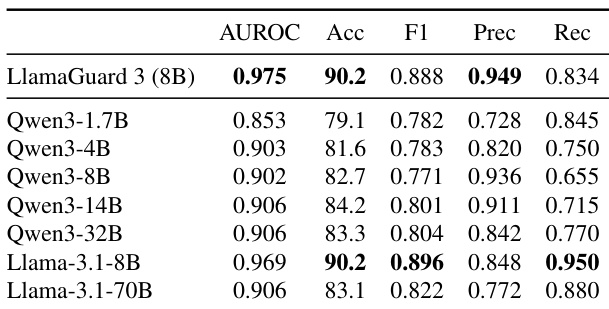
作者针对 LlamaGuard 3 分类器在 XSTest 基准上评估了单神经元激活作为有害提示检测器的表现。结果表明,来自 Llama-3.1-8B 的拒绝神经元在准确率和 AUROC 方面达到了与专用分类器相当的性能,同时在以精度为代价的情况下显著提高了召回率。其他模型,特别是 Qwen3 系列,通常显示出较低的准确率分数,其中最小的 1.7B 变体表现最弱。Llama-3.1-8B 拒绝神经元的准确率与专用分类器匹配,同时实现了更高的召回率。大多数 Qwen3 模型保持强大的检测性能和高 AUROC,除了最小的变体。单神经元检测通过依赖单个激活值,作为全分类器推理的高效替代方案。
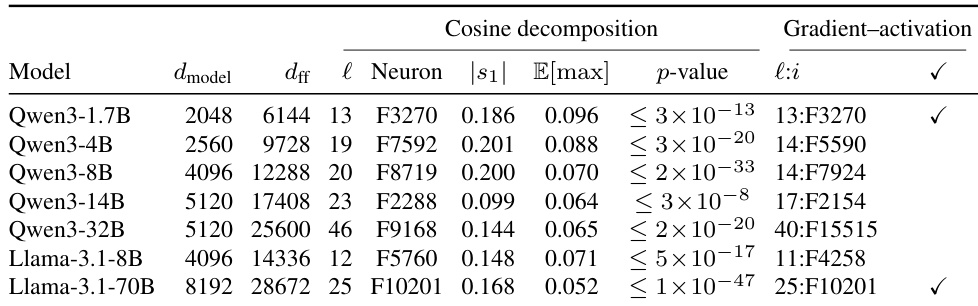
作者比较了两种识别拒绝神经元的独立方法:一种基于梯度 - 激活的方法,另一种基于全局拒绝方向的几何对齐方法。结果表明,对于某些模型,两种策略收敛于完全相同的神经元,并且顶部神经元与拒绝方向之间的对齐在所有模型中均具有统计显著性。两种独立的识别策略在 Qwen3-1.7B 和 Llama-3.1-70B 上收敛于同一个单个神经元。排名靠前的神经元与拒绝方向之间的余弦相似度在所有模型中均具有统计显著性。几何对齐方法仅限于拒绝方向层,而梯度方法搜索所有层,但它们仍然在标记有勾号的两个模型的顶部神经元上达成一致。
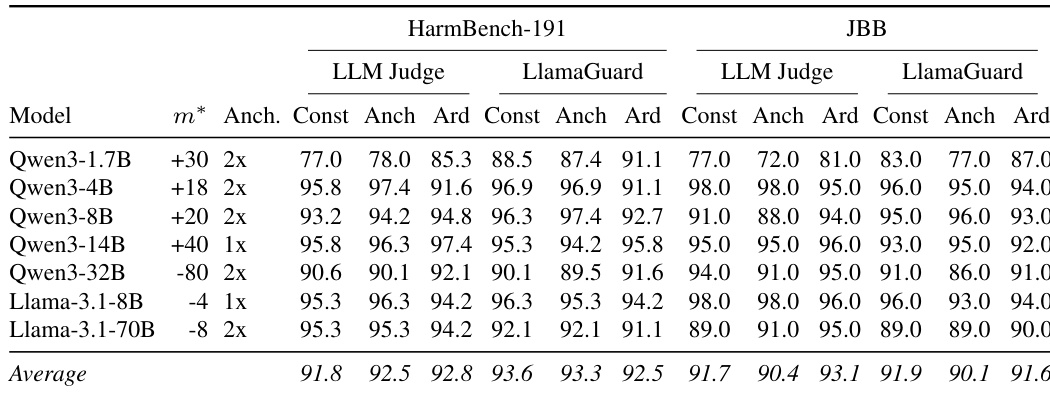
作者使用两个基准和两个独立评估者在七个指令微调模型上评估了三种干预策略。结果表明,单神经元干预方法实现了与跨层消融整个方向的基线方法相当的攻击成功率。性能在不同模型系列和规模上保持一致,在开发集和保留测试集上均观察到高成功率。单神经元干预方法在所有评估模型上实现了与全方向消融基线相当的攻击成功率。在开发集上选择的干预参数有效地转移到保留测试集,无需重新调整。在不同模型系列和参数量规模上保持了高攻击成功率,表明识别出的拒绝神经元具有稳健性。
这项研究评估了 Qwen3 和 Llama-3.1 系列中的拒绝神经元,以验证它们在检测不安全内容和实现针对性安全干预中的作用。实验表明,与更广泛的消融方法相比,操纵特定神经元允许以最小的能力退化绕过安全对齐,同时在不同的模型规模上保持高成功率。此外,单神经元激活作为安全检测器与专用分类器相当,并且独立的识别策略一致收敛于相同的临界神经元。