Command Palette
Search for a command to run...
切片与切块:配置最优专家混合物
切片与切块:配置最优专家混合物
Margaret Li Sneha Kudugunta Danielle Rothermel Luke Zettlemoyer
摘要
混合专家(Mixture-of-Experts, MoE)架构已成为大语言模型(LLMs)的标准配置,然而,其许多核心设计选择——包括专家数量、粒度、共享专家、负载均衡以及 token 丢弃策略等——以往的研究往往仅在狭窄的配置范围内,一次探究一两个变量。目前尚不清楚这些选择在未考虑相互作用的情况下,是否可以独立优化。我们展示了首个系统性研究,涵盖了超过 2,000 次预训练实验,模型总参数量高达 66 亿。在这些实验中,我们全面变更了总专家数、专家维度、单层内的异构专家大小、共享专家规模以及负载均衡机制。研究发现,在我们研究的所有活跃参数(active-parameter)规模下,即使活跃专家参数比例极高(如 128),性能仍随 MoE 总参数量的增加而持续提升。此外,最优专家大小几乎不受总参数量的影响,仅取决于活跃参数数量。第三,我们发现,相较于专家数量和粒度,其他选择(如共享专家、异构专家和负载均衡设置)的影响较小,尽管“无丢弃路由”(dropless routing)能带来一致的收益。总体而言,我们的结果表明可以采用更简化的配方:重点关注专家数量和粒度,其他选择对最终质量的影响微乎其微。
一句话总结
作者首次对超过 2,000 次预训练运行进行了系统研究,涵盖参数高达 66 亿的模型,以配置最优的专家混合(Mixture of Experts),揭示出性能随着 MoE 总参数的增加而持续改善,而最优专家大小仅取决于活跃参数数量,表明存在一种更简单的配方,专注于专家数量和粒度。
核心贡献
- 该论文通过将专家数量和粒度在固定计算预算下分别变化,解耦了这两者,以测量专家大小和数量的独立影响。超过 2,000 次实验,参数范围从 1000 万到 66 亿,表明性能随 MoE 总参数单调提升。
- 在异构专家池和共享通用专家上的测试表明,这些灵活性选项相比配置良好的同质 MoE 模型提供的改进微乎其微。结果表明,层内混合粒度或通用专家均无法提升性能,且通用专家始终损害质量。
- 对路由设计空间的分析表明,MoE 质量在合理范围内的负载均衡超参数下具有鲁棒性。实验进一步显示,与无丢弃路由(dropless routing)相比,其他路由设置带来的增益较小但一致。
引言
专家混合架构现在已成为大型语言模型的标准,因为它们将计算开销与模型容量解耦,但以往的工作通常孤立地评估核心设计选择,如专家数量和粒度。这种碎片化的分析留下了不确定性,即这些参数是否可以在不考虑其相互作用的情况下独立优化。作者通过进行超过 2,000 次预训练运行的系统研究来解决这一差距,涵盖高达 66 亿参数的模型,以解耦专家数量与粒度的影响。结果表明,性能随 MoE 总参数单调提升,且最优专家大小仅取决于活跃参数数量。因此,作者建议优先考虑专家数量和粒度,同时指出共享专家和复杂的路由调整带来的收益微乎其微。
数据集
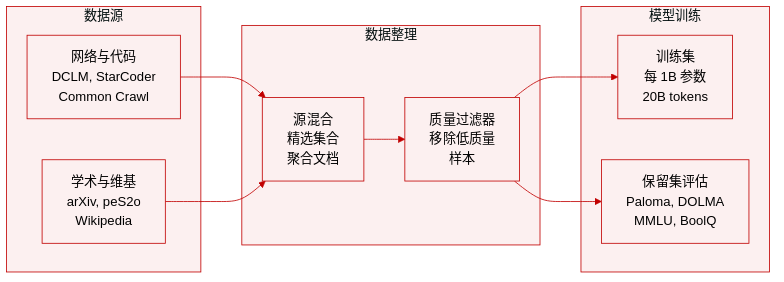
- 训练数据组成: 作者利用 Muennighoff 等人 (2025) 的训练数据,聚合了来自 DCLM-Baseline、StarCoder、peS2o、arXiv、OpenWebMath、Algebraic Stack 和英文维基百科及维基教科书的文档。
- 训练规模: 每个模型遵循大约 20 的 token 与活跃参数比率。这意味着 10 亿活跃参数模型在大约 200 亿 tokens 上训练。
- 评估语言建模: 评估套件包括来自 Paloma 的保留语言建模任务。特定子集包括 C4、THE PILE、WIKITEXT-103、M2D2 S2ORC、ICE 和 DOLMA。
- DOLMA 子域: DOLMA 组件分为六个域:books、common-crawl、pes2o、reddit_uniform、stack_uniform 和 wiki。
- 下游基准: 下游任务包括 BoolQ、HellaSwag 和 MMLU。MMLU 细分为人文、STEM、社会科学和其他领域。
- 指标: 对于语言建模任务,团队计算并报告宏观平均交叉熵损失。
方法
作者利用专家混合(MoE)架构,其中 Transformer 层内的标准前馈网络(FFN)模块被条件激活的子模块取代。在此设计中,每个 token 首先通过共享的自注意力机制。随后,路由器机制根据亲和力分数激活特定专家,这些激活的 FFN 模块的输出通过加权求和组合。
请参阅下方的框架图以获取此 MoE 层结构的视觉表示。
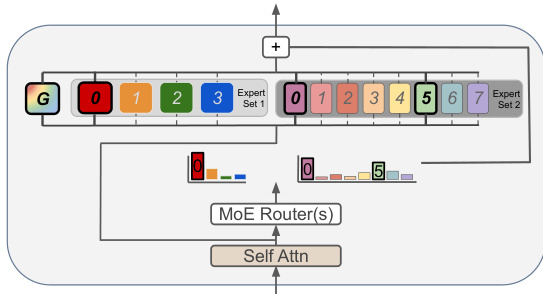
该架构引入了超越同质专家大小的灵活配置。标准的同质 MoE 层通常包括 n 个具有相同粒度 g 的专家,其中 k 个专家被激活。粒度定义为专家 FFN 中间维度与密集 FFN 中间维度的比率。然而,此框架支持由具有不同粒度的专家组成的异构 MoE 层。如图中所示,不同的专家集(标记为专家集 1 和专家集 2)可以包含不同大小的专家,允许模型更有效地分组学习功能。此外,可以包含一个始终激活的通用专家(标记为 'G'),它处理所有输入,其输出与路由专家的输出组合。
为了确保公平的性能比较,活跃专家数量通常受到限制,以固定相对于密集模型的激活参数数量。这种关系得以维持,使得活跃专家数量乘以专家粒度等于 1。这确保了每一步的 FLOPs 在不同配置下保持一致。
路由机制通常采用 token 选择路由,其中路由器为每个 token 选择亲和力值最高的 k 个专家。为了防止路由器过度依赖一小部分专家,采用了负载均衡机制。辅助损失函数可以添加到主交叉熵损失中,以惩罚不平衡的负载。或者,一种无损失机制在训练期间调整每个专家的偏差以鼓励平衡路由。此外,利用无丢弃路由(dropless routing)来处理容量约束。不是丢弃溢出 token 或将它们路由到默认专家,块稀疏性确保所有 token 都被处理,在保持计算效率的同时不丢失信息。
实验
这项研究通过系统地变化专家粒度、总数量和激活稀疏度来评估专家混合架构,同时在多个模型规模上将 FLOP 匹配的活跃参数与密集基线进行对比。发现表明,性能增益源于最大化总非活跃专家参数和利用无丢弃路由,而架构异构性和通用专家没有带来收益或降低性能。该研究进一步确定了计算阈值,低于该阈值时,除非增加数据预算,否则 MoE 的表现不如密集模型,并指出负载均衡超参数需要在高专家数量下进行微调以防止干扰。
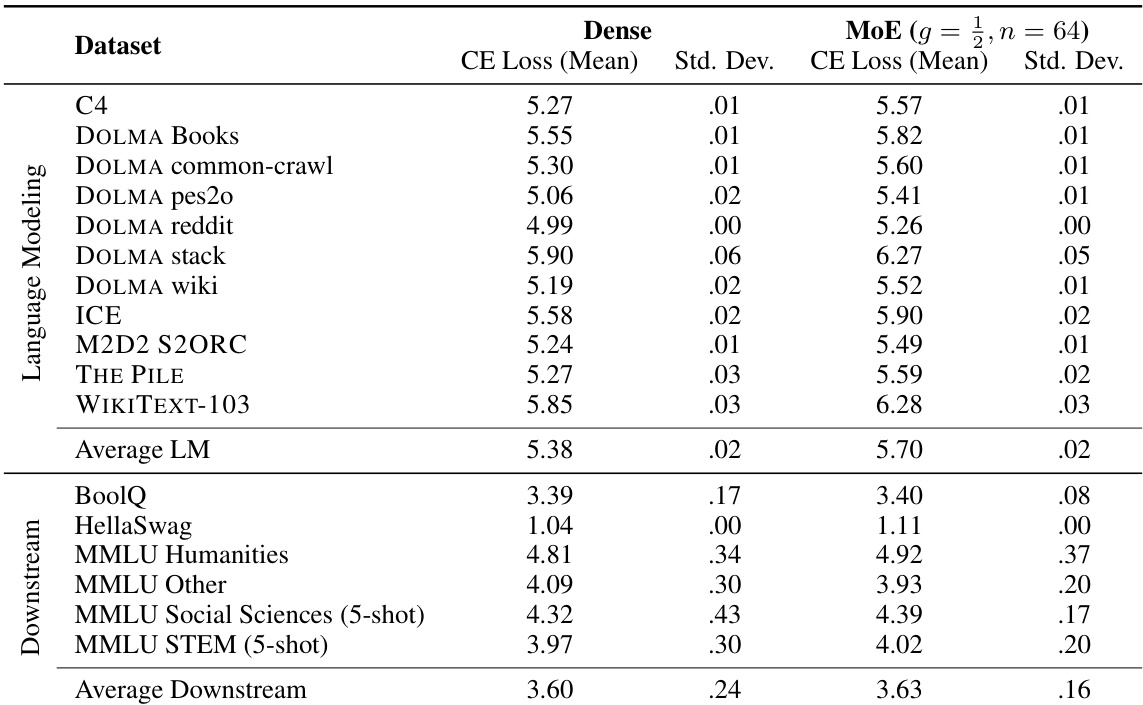
该实验在多个语言建模和下游数据集上评估了专家混合配置与密集基线。在此特定设置中,密集模型表现出更优越的性能,平均交叉熵损失低于 MoE 变体。这些结果与以下发现一致,即 MoE 架构在较小模型规模或特定配置下可能无法超越密集基线。密集模型在语言建模任务上实现了比 MoE 配置更低的平均交叉熵损失。下游任务评估表明,密集模型在平均损失方面优于 MoE 变体。MoE 配置通常在各个数据集上产生较高的损失值,例外情况很少。
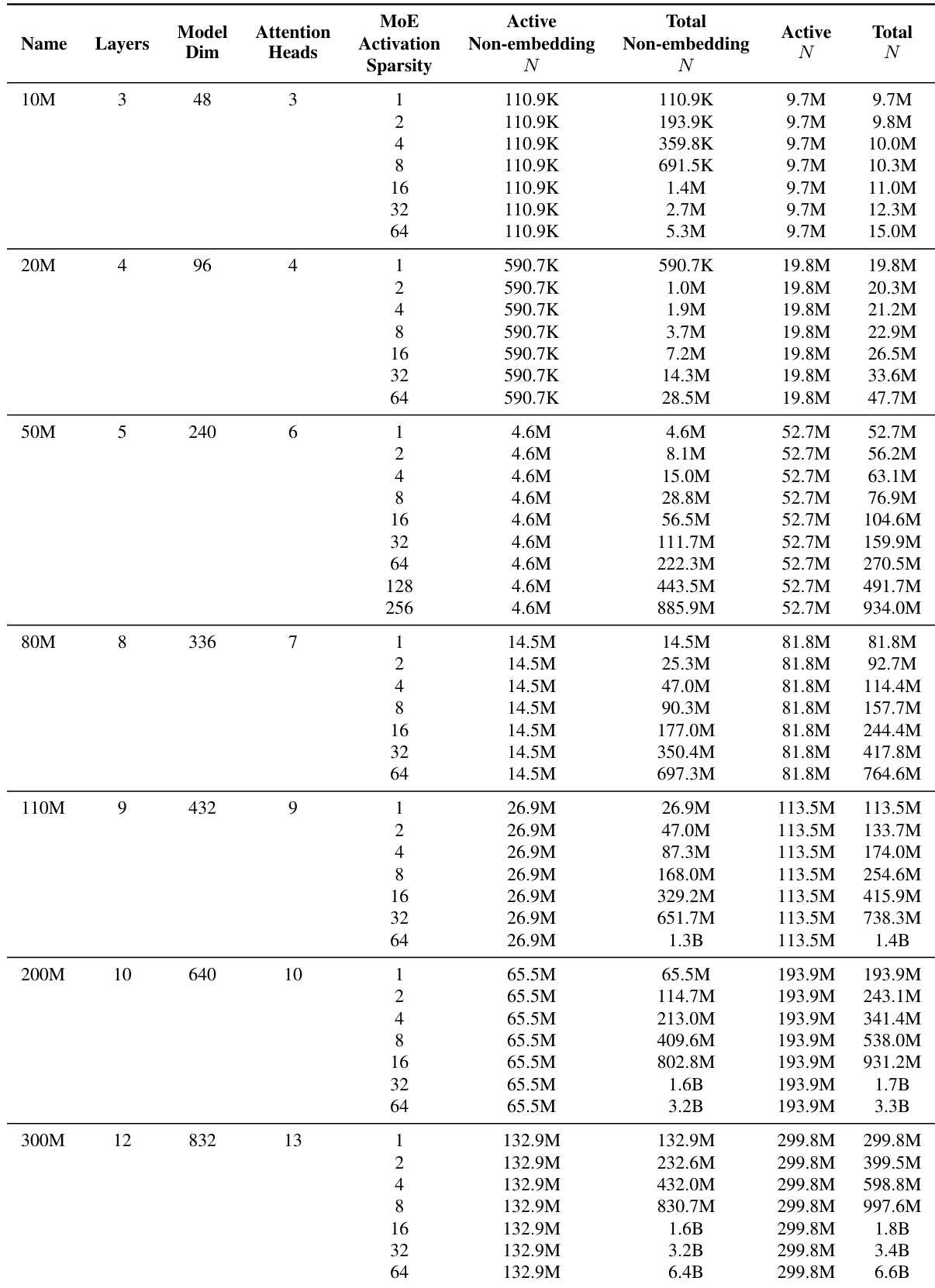
该表详细说明了几个活跃参数规模下专家混合模型的架构规范。它表明,虽然为了 FLOP 匹配活跃参数数量保持不变,但随着 MoE 激活稀疏度的增加,总参数数量会扩展。这种变化允许分析总专家容量如何影响模型性能。无论 MoE 激活稀疏度设置如何,每个模型组内的活跃参数数量保持一致。随着 MoE 激活稀疏度的增加,总参数数量大幅增长,表明非活跃专家池更大。更大的模型规模与增加的模型维度、注意力头和层数相关联。
作者调查了专家混合模型中的负载均衡机制和专家配置。结果表明,对于多达 512 个专家的模型,负载均衡设置影响微乎其微,尽管高偏差值会在更大规模下损害性能。性能随粒度和总专家数量变化,MoE 配置通常匹配或超过密集基线性能。负载均衡超参数对多达 512 个专家的影响微乎其微,但在更大规模下高偏差会损害性能。性能随粒度和总专家数量变化,最优配置取决于模型大小。专家混合配置在测试设置下通常匹配或超过密集基线性能。
作者调查了负载均衡损失权重和无损失偏差对各种专家配置下专家混合性能的影响。他们发现,虽然广泛的超参数设置都能实现接近最优的结果,但涉及高偏差和大量专家的特定组合会显著降低性能。这表明必须仔细调整负载均衡机制,以避免干扰语言建模目标。大多数负载均衡设置对于多达 512 个专家的模型产生可比的性能。当专家总数很大时,高偏差设置会损害性能。无偏差的低损失权重会导致更高的负载不平衡和更差的性能。
该图表显示了专家混合模型在 Dolma ps2o 数据集上不同稀疏度和总专家数量下的性能。结果表明,MoE 配置通常优于密集基线,性能随着稀疏度增加和总专家数量增长而提升。增加专家总数始终导致更好的结果,支持了最大化非活跃专家参数是有益的发现。MoE 模型在较高稀疏度水平下优于密集基线。具有更大总专家数量的配置比专家数量较少的配置实现更好的性能。异构专家设置相比同质配置没有提供显著优势。
该评估在语言建模和下游数据集上比较了专家混合配置与密集基线,以评估架构扩展和稀疏度的影响。结果表明,虽然密集模型在较小规模下表现出更优越的性能,但当通过更高稀疏度和更大专家池增加总参数数量时,MoE 架构匹配或超过基线结果。此外,负载均衡机制对于中等专家数量的模型通常影响微乎其微,尽管高偏差设置可能会在具有大量专家的配置中显著降低性能。